 英特爾架構的軟硬件協作的優勢
英特爾架構的軟硬件協作的優勢
概述
由 DeepMind 在 2021 年發布的 AlphaFold2,憑借自身在蛋白質結構預測上的高可信度,以及遠優于傳統實驗方法的效率和成本表現,樹起了一座“AI for Science”的全新里程碑。它不僅在生命科學領域掀起了顛覆式的革新,也成為了 AI 在生物學、醫學和藥學等領域落地的核心發力點。
隨著各類 AlphaFold2 項目在產、學、研各細分領域中的啟動與落地,其技術管線對于推理的高通量和高性能的需求也是與日劇增。一直活躍在“AI for Science”創新前沿的英特爾結合自身優勢,以內置 AI 加速能力的產品技術,特別是至強 可擴展平臺為硬件基座,對 AlphaFold2 實施了端到端的高通量優化,并在實踐中實現了比專用 AI 加速芯片更為出色的表現—累計通量提升可達優化前的 23.11 倍1。
如此顯著的優化成效,基于英特爾 架構的軟硬件協作功不可沒:
●硬件支撐:英特爾 至強 可擴展平臺的核心產品和技術特性,例如第三代英特爾 至強 可擴展處理器在算力輸出上的出色表現,及其內置的 AI 加速技術,如英特爾 高級矢量擴展 512(英特爾 AVX-512)等技術帶來的并行計算優化,還有英特爾 傲騰 持久內存對“內存墻”障礙的突破,及這一突破對長序列高通量的并行推理優化的強力支持;
●軟件加成:軟件是充分利用或釋放硬件加速潛能的“鑰匙”,例如在模型推理階段,序列長度為 n 的情況下,推理時間復雜度為 O (n2),此時原始 AlphaFold2 在 CPU 上的推理時長是難以接受的。英特爾為此采取了一系列軟件調優舉措,包括對注意力模塊(attention unit)開展大張量切分(tensor slicing),以及使用英特爾 oneAPI 工具套件實施算子融合等優化方法,解決了 AlphaFold2 在 CPU 平臺上面臨的計算效率低和處理器利用率不足等難題,同時也緩解了調優方案執行各環節中面臨的內存瓶頸等問題。

圖一 基于英特爾 至強 可擴展平臺的
AlphaFold2推理優化路線圖及其實現的性能提升2
本文的核心任務,就是要介紹上述基于英特爾 架構、致力于在 CPU 平臺上加速 AI 應用的軟硬件產品技術組合在 AlphaFold2 端到端優化中扮演的關鍵角色,并詳細分享對它們進行配置、調優以求持續提升 AlphaFold2 應用性能表現的核心經驗和技巧,從而為所有計劃開展或正在推進類似探索、實踐的合作伙伴及最終用戶們提供一些關鍵的參考和建議,讓整個產業界能夠進一步加速相關應用的落地并盡可能提升其收益。
蛋白質結構解析任務繁重,
AlphaFold2 生逢其時
如生物學中心法則(Central Dogma)所揭示的,脫氧核糖核酸(DNA)、核糖核酸(RNA)和蛋白質(包括多肽、氨基酸)之間“轉錄-翻譯”的關系,清晰呈現了有機體內的信息傳遞路徑,也讓人們認識到:對蛋白質三維結構開展有效解析與預測,就能對有機體的構成,及其運行和變化的規律實施更深層次的詮釋和探究,進而可為生物學、醫學、藥學乃至農業、畜牧業等行業和領域的未來研究與發展提供高質量的生物學假設。
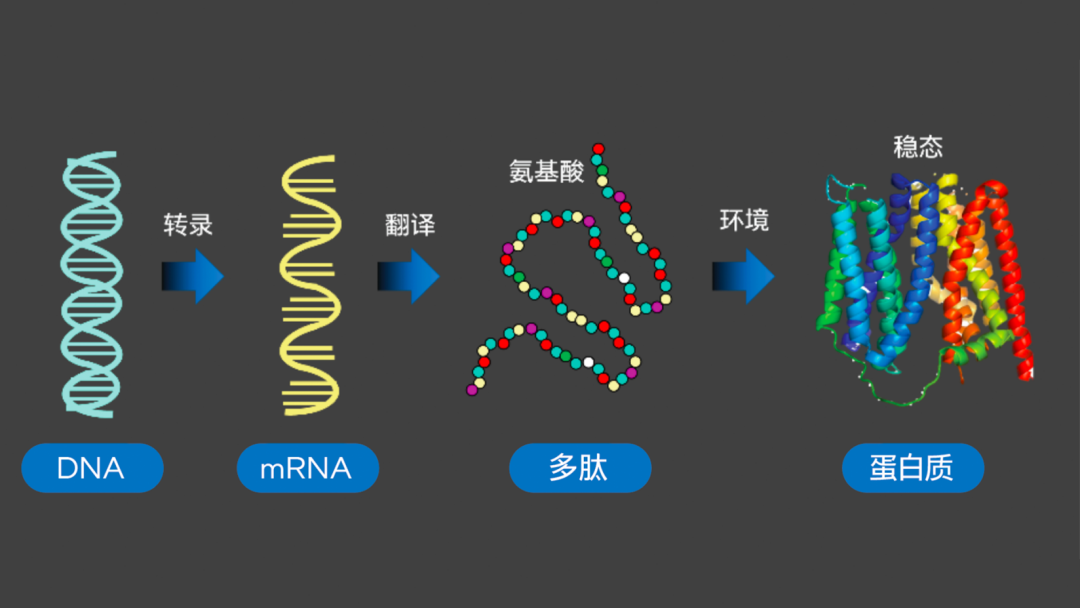
圖二 生物學中心法則
雖然許多基于傳統實驗方法的蛋白質結構解析工具,包括 X-射線晶體衍射、冷凍電鏡、核磁共振等已獲普遍運用,但通過傳統實驗方法進行結構解析的速度,遠趕不上氨基酸序列的增加速度,這就造成海量待測樣品/序列可能會在實驗室中等待數月乃至數年才能得到解析。以UniProtKB/Swiss-Prot 數據庫搜集和整理的數據為例,單從實驗獲得的已知蛋白序列就已高達 57 萬條之多4。
AI 技術的高速發展,則為破解上述效率問題提供了新的思路--人們開始將深度學習等方法運用于蛋白質結構預測,其中由 DeepMind 在 2020 年 CASP 145上提出的 AlphaFold2 方案尤其令人矚目,它以驚人的 92.4 分(GDT_TS 分數)的表現實現了原子級別的預測精度,被認為“已可替代傳統實驗方法”6。
AlphaFold2 端到端預測:
三個階段協作增效
與以往多是間接預測蛋白質結構的 AI 方法不同,AlphaFold2 提供了完整的端到端蛋白質三維結構預測流程。如圖三所示,其工作流程大致可分為預處理(Preprocessing)、深度學習模型推理(DL Model Inference)以及后處理(Postprocessing)三個階段,各階段執行的功能如下:
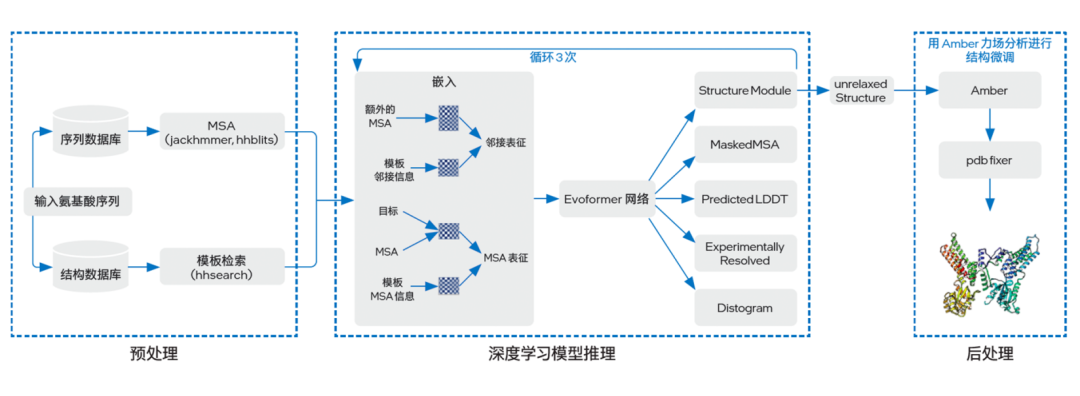
圖三 AlphaFold2 基本架構
●預處理:由于初始輸入的氨基酸序列所含信息往往較少,因此 AlphaFold2 在預處理階段會先利用已知信息(包括蛋白質序列、結構模板)來提升預測精度。包括借助一些蛋白質搜索工具在特定序列數據庫中使用多序列比對(MSA)方法,以及在特定結構數據庫中進行模板搜索,從而獲得不同蛋白質之間的共有進化信息;
●深度學習模型推理:在該階段中,AlphaFold2 首先會借助嵌入(Embedding)過程,將來自預處理階段的模板 MSA 信息、MSA 和目標構成 MSA 表征(MSA representation)的三維張量,同時也將模板鄰接信息和額外的 MSA 構成鄰接表征(pair representation)的三維張量,隨后兩種表征信息會通過一個由 48 個塊(Block)組成的 Evoformer 網絡進行表征融合。在這一進程中,模型將通過一種 Self-Attention 機制來學習蛋白質的三角幾何約束信息,并讓兩種表征信息相互影響來使模型推理出相應的三維結構,且循環三次;
●后處理:這一階段,AlphaFold2 將使用 Amber 力場分析方法對獲得的三維結構參數優化,并輸出最終的蛋白質三維結構。
AlphaFold2 在預測精度上取得的優勢,源于四點全新的設計思路:
●在預處理階段通過 MSA 方法等,將模板蛋白質結構和序列保守性信息融入預測特征;
● 在特征嵌入階段,將保守性最高的 MSA 特征單獨取出,壓縮其余的 Extra MSA,并與模板特征交互;
●在模型推理階段,采用獨特的雙軌注意力模塊和深層 Transformer 架構,并引入循環回收機制;
●在結構網絡層引入不變點注意力(Invariant Point Attention)機制。但這也意味著 AlphaFold2 從執行之初,直至整個推理過程都需要面對高通量的計算壓力。
五大步驟:至強 可擴展平臺
助 AlphaFold2 實現端到端優化
隨著越來越多的科研機構、實驗室和企業開始借助 AlphaFold2 進行蛋白質結構預測,各行業和領域內的使用者也開始遇到越來越多、也漸趨嚴峻的挑戰。例如結構預測各環節面臨著龐大的計算量,使用者需要更加充分地挖掘硬件的計算潛力來提升執行效率;為縮短結構預測時間,他們還需要利用更多計算節點來構建效率更高的并行計算方案等。
基于第三代英特爾至強可擴展平臺提供的內置 AI 加速能力,對于運算和存儲性能的均衡設計,以及對硬件和軟件協同優化能力的兼顧,英特爾著手對 AlphaFold2 進行了端到端的全面優化,以幫助生物學等領域的使用者們應對以上挑戰。針對 AlphaFold2 的設計特點,該優化方案主要聚焦在預處理和模型推理兩個層面,并可基本劃分為以下五個步驟。
第一步:預處理階段-高通量優化
預處理階段的高通量計算需求,使方案在執行時面臨非常明顯的并行計算壓力。借助第三代英特爾 至強 可擴展處理器的多核優勢及其內置的英特爾 AVX-512 技術,方案能夠實現針對預處理階段的高通量優化。
如前文所述,AlphaFold2 會在預處理階段對特定序列數據庫和結構數據庫中的已知序列/模板信息進行搜索,包括使用 jackhammer 等蛋白質搜索工具來執行 MSA 方法,即從數據庫中抽取和輸入與氨基酸序列相近的序列并進行對齊的過程,其目的是找出同源的序列/模板組成表征信息來為后續推理過程提供輸入,由此提高預測精度。
這一過程中,計算平臺需要執行大量的向量/矩陣運算。以模板搜索為例,其本質為計算兩個隱馬爾可夫模型(Hidden Markov Model,HMM)間的距離。當輸入的氨基酸序列很長(例如執行中輸入長度達數百的氨基酸序列)且需并行執行大量實例時,如果無法讓處理器的算力“火力全開”去提升平臺的并行計算效率,那么整個預處理過程的效率就會變得乏善可陳。
在實踐中,第三代英特爾 至強 可擴展處理器一方面能憑借出色的微架構設計,尤其是多核心、多線程和大容量高速緩存,來保證 AlphaFold2 獲得充足的總體算力,以滿足整個結構預測過程所需;另一方面,其內置的英特爾 AVX-512 及其支持的 NUMA (Non-Uniform Memory Access,非一致存儲訪問) 架構等技術,也為方案提供了更進一步的性能調優空間。
針對序列/模板搜索所需的大量向量/矩陣運算需求,英特爾 AVX-512 技術,能以顯著的高位寬優勢(最大可提供 512 位向量計算能力)來提升計算過程中的向量化并行程度,從而有效提升向量/矩陣運算效率。這一步在需要配備上述硬件平臺的同時,在 icc 編譯器中做如下設置(該設定支持所有英特爾 至強 可擴展處理器,不僅限于代號為 Ice Lake 的第三代英特爾 至強 可擴展處理器):

第二步:模型推理階段-將深度學習模型
遷移至面向英特爾 架構優化的 PyTorch
原始版本的 AlphaFold2 是基于 DeepMind 的 JAX 和 haiku-API 做的網絡實現,但目前 JAX 上還沒有面向英特爾 架構平臺的優化工具。而 PyTorch 擁有良好的動態圖糾錯方法,與 haiku-API 有著相似的風格,并可以采用面向 PyTorch 的英特爾 擴展優化框架(Intel Extensions for PyTorch,IPEX,可由英特爾 oneAPI AI 工具套件提供)。為實現更好的優化效果,方案選擇將深度學習模型遷移至面向英特爾 架構優化的PyTorch,并最終逐模塊地從 JAX/haiku 上完成了代碼遷移。
第三步:模型推理階段-PyTorch JIT
為提高模型的推理速度,便于利用 IPEX 的算子融合等加速手段,優化方案中還對遷移后的代碼進行了一系列的 API 改造,在不改變網絡拓撲的前提下,引入 PyTorch Just-In-Time (JIT) 圖編譯技術,將網絡最終轉化為靜態圖。
第四步:模型推理階段-
切分 Attention 模塊和算子融合
AlphaFold2 的嵌入過程是構成 MSA 表征張量和鄰接表征張量來作為 Evoformer 網絡輸入的關鍵步驟。從其算法設計可以獲知,其注意力模塊中包含了大量的偏移量(bias)計算。
這種偏移量計算是通過張量間的矩陣運算來完成的,因此運算過程中會伴隨張量的擴張。當張量達到一定規模后,擴張過程對內存容量的需求就會變得巨大。以一個“5120 x 1 x 1 x 64”的張量為例,其初始內存需求為 1.25MB,但在擴張過程中,對內存容量的需求卻可達 930MB。
這就使 AlphaFold2 在嵌入過程中面臨兩個問題:一方面是巨大的內存峰值壓力,其需求量會使內存資源在短時間耗盡,尤其是內存峰值在相互疊加之后,進而可能造成推理任務的失敗;另一方面,大張量運算所需的海量內存也會帶來不可忽略的內存分配過程,從而增加執行耗時。
為此,英特爾提出了”對注意力模塊進行大張量切分”的優化思路,即,將大張量切分為多個較小的張量,來降低擴張中的內存需求。例如將上述“5120 x 1 x 1 x 64”的張量切分為“320 x 1 x 1 x 64”后,其擴張所需的內存就由 930MB 降至 59.69MB,僅為未進行張量切分時的 6.4% 左右,有效消減了內存峰值壓力。相關代碼示例如下:

英特爾發現,利用 PyTorch 自帶的 Profiler 對 AlphaFold2 的 Evoformer 網絡進行算子跟蹤分析時, Einsum 和 Add 這兩種算子占用了大部分的算力資源。因此,英特爾就考慮使用 IPEX(建議版本為 IPEX-1.10.100 或更高)提供的算子融合能力來實現上述兩種計算過程的融合。
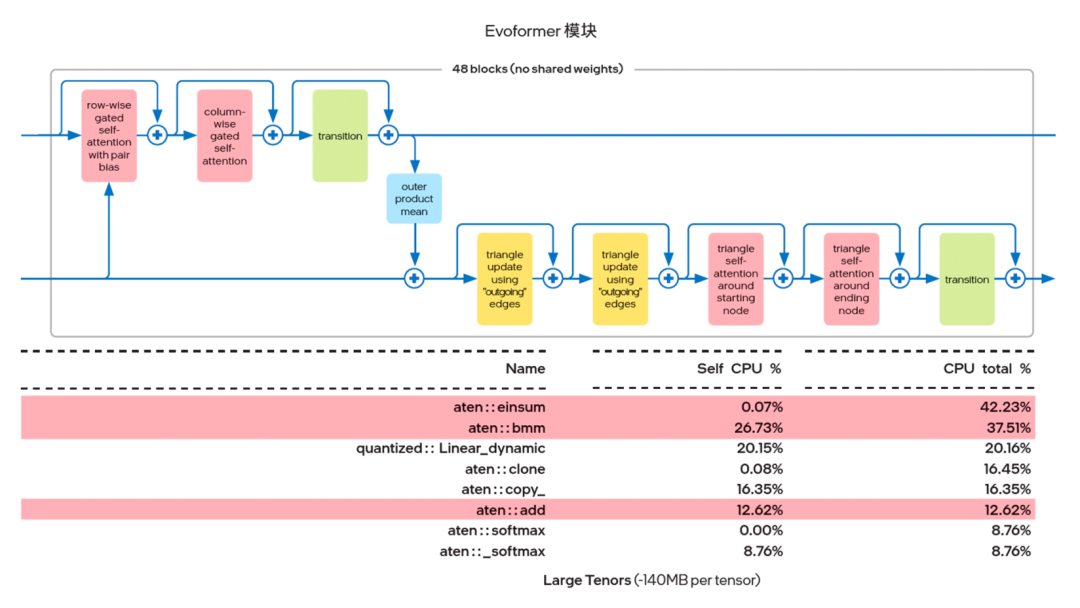
圖四 Evoformer 模塊的熱點算子
傳統的深度學習計算過程都是逐一操作:例如 Einsum 計算過程結束后,函數返回值需要在 Python 進程中建立一個臨時緩存,然后通過調用 Add 算子,再次進入 oneDNN 完成第二個函數的運算,這中間來回折返的過程時間消耗不可忽略。如圖五所示,算子融合帶來的優勢就在于,在前一操作結束后可以馬上執行后一操作,節省了中間建立臨時緩存數據結構的時間。同時從時間軸上不難看出,經過融合后,兩個連續的算子合并為一個,用時也顯著縮短。
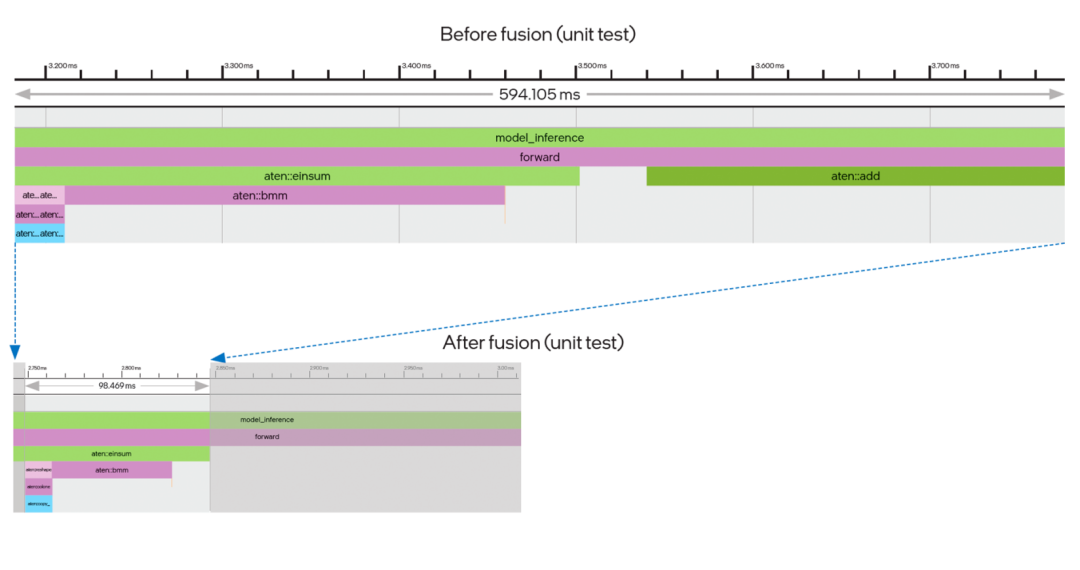
圖五 算子 Einsum+Add 融合效果圖
第五步:模型推理階段-
破解多實例運算過程中的計算和內存瓶頸
為了讓推理性能在多實例進程中獲得更接近線性的增長表現,優化方案也借助英特爾 至強 可擴展平臺提供的高效且更為均衡的計算和存儲優勢實施了有針對性的優化。
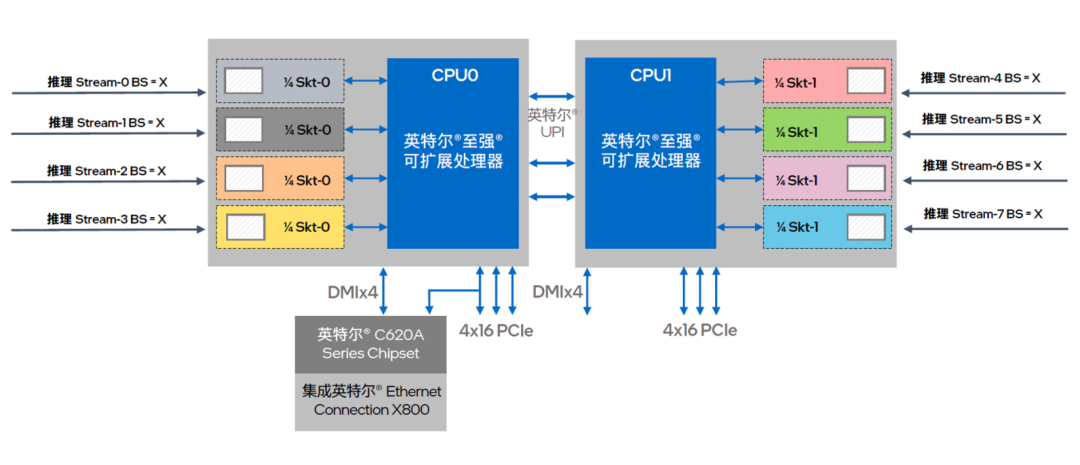
圖六 英特爾 至強 可擴展處理器提供多核并行算力輸出
方案首先是借助基于 NUMA 架構的核心綁定技術,來充分挖掘至強 可擴展處理器的多核心優勢。如圖六所示,這一技術可對處理器節點以及訪問本地內存進程予以精確控制,讓每個推理工作負載都能穩定地在同一組核心上執行,并優先訪問對應的近端內存,從而提供更優、也更穩定的并行算力輸出。在執行中可使用以下 numactl 指令:

得益于英特爾 至強 可擴展處理器在微架構設計上的優勢,物理核與物理核之間的數據通信平均延時較短,每個 NUMA 在并行計算中的工作效率也會更高。
同時,在大規模服務器集群上開展多實例并行推理計算時,節點間的數據交互量會呈平方增長,導致大量占用通信帶寬并損失計算效率。英特爾 MPI 庫的引入,能針對并行計算的需求進行自動調整,幫助方案實現更優的時延、帶寬和可擴展性。方案中可以加入以下優化指令:

在開展并行多實例計算優化之外,英特爾還注意到,內存的容量限制,或者說瓶頸是限制 AlphaFold2 發揮潛能的另一個重要因素。通過對算法架構的解析可知,AlphaFold2 中大量的矩陣運算過程都需要大容量內存予以支撐。其最大輸入序列長度越長,計算中所需的內存也就越大。而在并行計算能力得到有效優化后,更多計算實例的加入也會進一步突顯內存瓶頸問題。
受限于產品規格、主板架構和成本,僅使用傳統 DRAM(Dynamic Random Access Memory,動態隨機存取存儲器)內存很難實現 TB 級的大容量部署。英特爾傲騰持久內存方案則是破解這一難題的有效途徑,基于創新的存儲介質,這一產品能為方案提供大容量和高性價比的內存支撐。
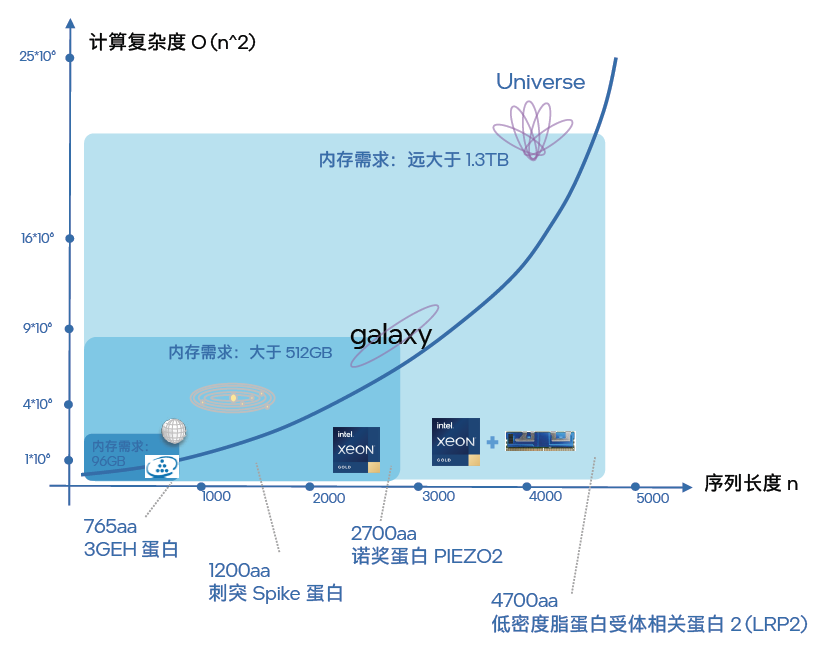
如圖七所描繪的,在面向不同蛋白質的結構預測工作中,序列長度越長,推理計算復雜度就越大。結合更多的并行計算,所需的內存容量也就越高。如果用“星際探索”來比喻這種趨勢,那么:
●對 3GEH 蛋白的結構預測就相當于探索地球
●而對某病毒相關的刺突(Spike)蛋白的結構預測就相當于將探索擴大到了整個太陽系;
●對諾貝爾生理學或醫學獎發現的 PIEZO2 蛋白結構進行預測則是進一步將探索擴展到了銀河系;
●對低密度脂蛋白受體相關蛋白 2(LRP2) 的結構預測,就好比是宇宙級的探索。
可見,不同的探索范圍,所需耗費的資源(內存)也全然不同。在實踐中,進行 3GEH 蛋白(長度為 765aa)的結構預測,內存大小在 100GB 就足以。而對 Spike 蛋白和 PIEZO2 蛋白進行預測時,由于序列長度分別達到了 1200aa 和 2700aa,就需要部署 512GB 范圍的內存。而當人們對 LRP2 蛋白進行結構預測時,其 4700aa 的序列長度要求的內存容量就遠大于 1.3TB。如果 64 個實例并行執行,內存容量的需求就會沖到一個令人驚嘆的量級,如果無法滿足這個需求,就會形成阻礙應用工作效能發揮的“內存墻”。
圖七 大量長序列結構預測都會遇到“內存墻”問題
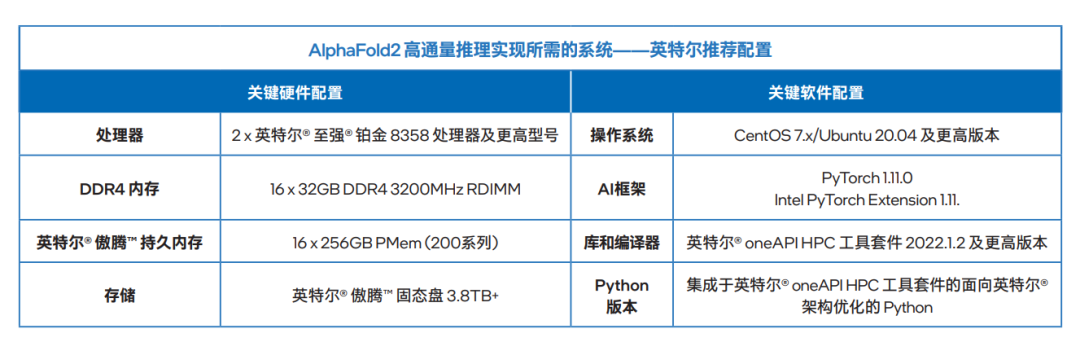
以英特爾 傲騰 持久內存 200 系列為例,其最高可提供 512GB 的單模組容量,在與雙路平臺的第三代英特爾 至強 可擴展處理器搭配后,在提供 3200MT/S 內存帶寬的基礎上,理論上可實現每路高達 4TB 的英特爾 傲騰 持久內存容量配置,以及每路高達 6TB 的內存總容量(與 DRAM 內存組合使用),足以支撐 AlphaFold2 高密度部署方案。值得一提的是,在提供更大容量的同時,英特爾 傲騰 持久內存還能輸出接近 DRAM 內存的性能表現。
多個優化步驟實施后的總體性能表現
基于英特爾至強可擴展平臺開展的 AlphaFold2 端到端優化,包括一系列并行計算能力優化舉措和英特爾傲騰持久內存產品的引入,使得整個 AlphaFold2 端到端處理過程的性能獲得了質的提升。如圖八所示,通過以上的優化流程,每個優化步驟獲得的提升累積后,最后相比優化前通量提升可達 23.11 倍7。
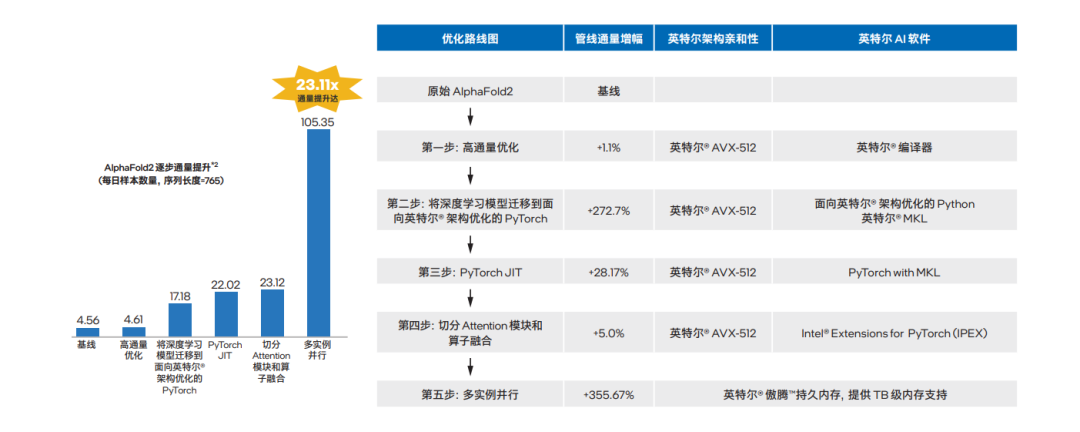
圖八 推理過程中多種優化措施帶來的累計性能提升8
在探索和驗證上述端到端 AlphaFold2 優化方案、步驟和經驗的過程中,英特爾扮演的角色并非“獨行俠”,而是與同在尋求相關解決方案的,專攻醫藥和生命科學研究和創新的產、學、研領域用戶及合作伙伴們積極開展了廣泛及深入的協作,這些協作起到了博采眾長的效果,也為方案的普適性帶來了助益。
同樣,在優化方案基本定型,并展現了顯著的通量提升效果以及能夠擔起更長序列蛋白質結構預測重任的能力后,眾多合作伙伴與用戶也第一時間參考和借鑒了方案中的方法、經驗與技巧,并結合自身特定的環境、應用現狀和需求,開展了實戰驗證和更進一步的探索。
總結與展望
得益于 AI 技術的高速發展和演進,它與科學前沿研究的結合正在快速地改變世界并造福人們的生活。以 AlphaFold2 為例,雖然其問世時間不長,但已經有生物學家將其應用到對抗新型傳染病和其他疾病的研究中,并取得了一定的成果9。
始終走在 AI 應用創新與落地一線的英特爾,也在這一過程中借助至強可擴展平臺,包括其硬件層面的第三代英特爾至強可擴展處理器和英特爾傲騰持久內存,以及其軟件層面的英特爾 oneAPI 工具套件等,基于這些軟硬件之間的無縫組合與高效協作,以及多樣化的 AI 優化方法,為 AlphaFold2 提供了端到端的高通量計算優化方案。
面向未來,英特爾還將繼續攜手科學前沿領域的合作伙伴,推進更多英特爾產品、技術與 AlphaFold2 等新技術開展交互與融合,在更多層面助力和加速“AI +Science”的技術創新,讓 AI 應用為各類前沿科學研究和探索帶來更多加速、助力與收獲。
-
英特爾
+關注
關注
61文章
10007瀏覽量
172149 -
軟硬件
+關注
關注
1文章
303瀏覽量
19241 -
模型
+關注
關注
1文章
3298瀏覽量
49064
原文標題:至強? 平臺上五步優化 AlphaFold2 端到端推理,通量提升達 23.11倍!
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
智能駕駛領域,英特爾有何優勢?

英特爾將在2014年推出14納米處理器芯片
英特爾多款平板電腦CPU將于明年推出
產業風暴,英特爾能否扳倒ARM?
為什么選擇加入英特爾?
蘋果Mac棄用英特爾芯片的原因
英特爾重點發布oneAPI v1.0,異構編程器到底是什么
超越英偉達Pascal五倍?揭秘英特爾深度學習芯片架構 精選資料推薦
英特爾Optane DC PMM硬件的相關資料分享
決戰AI芯片!英特爾押寶Nervana NNP
軟硬件結合,英特爾助推計算力指數級提升
英特爾推嵌入式3D攝像頭 將虛擬場景變為現實
英特爾軟硬件構建模塊如何幫助優化RAG應用

英特爾2024產品年鑒:AI與軟硬件的融合發展






 工商網監
工商網監
評論