 一個全新的無監督不需要明確物體種類的實例分割算法
一個全新的無監督不需要明確物體種類的實例分割算法
摘要
對于自動駕駛來說,精細化的場景理解至關重要。由于在行駛的過程中,場景周圍信息會發生劇烈的變化,因此很難識別和理解出場景中的不同對象。盡管有很多工作者在語義/全景分割上推動了場景理解的發展,但目前來說,仍然是一個挑戰任務。目前的方法大多依賴于標注數據,對于訓練數據中缺少的類別,我們將其稱為拖尾(長尾)類。
然而,拖尾(長尾)類對于自動駕駛來說缺失至關重要,如嬰兒車和未知動物,都會對自動駕駛的安全性能造成巨大的挑戰。在本篇文章中,我們將集中對這種類無關的實例分割問題進行研究,進一步解決這種拖尾(長尾)類問題。我們提出一個全新的算法和驗證算法用的數據集,并且在真實場景數據中驗證我們算法效果。
算法通過一個已經訓練好的自監督神經網絡抽取出點特征,構建出點云表示對應的圖表征。然后,我們用圖割算法來將前后背景分離出來。結果證明了我們的算法可以實現實例分割,并且相比于其他自監督算法,我們方法具有不錯的競爭力。
主要貢獻
在這篇論文中,我們關注的問題是基于激光點云的實例分割,更確切的來說,我們關注的是不需要明確類別的激光點云實例分割算法。相比于需要把城鎮街道上所有可能出現的物體打上標簽,我們更關注的是如何擺脫區分物體的類別屬性而直接將其打上標簽。因此,我們的問題被簡化為如何能區分出點云中的單個物體,并且將它們分割出來。
這個問題的最大難度是對未知物體的分割,因為本身并不存在于標記數據中,但在推理過程中,該部分數據又特別重要。
這個問題也可以被解讀于:我們如何通過對現實世界中的部分信息來進行訓練學習,實現對激光點云中的實例物體進行推理。目前先進的方法也有通過語義分割的訓練預測器來解決這個問題,這些方法通過不同的啟發式方法和優化過程來對點進行聚類,這些方法依然需要標注數據。
這篇文章的主要貢獻是提出了一個全新的無監督不需要明確物體種類的實例分割算法。鑒于目前表示學習的發展,我們可以使用自監督的方法來抽取出點對特征,并且通過鄰接圖的方式來表示相鄰點對之間的相似性。然后,我們在不需要任何標注的情況下,通過圖割的算法來從背景信息中抽取出實例物體。
我們將Semantic KITTI benchmark進行了擴展,分別在已經物體類別和未知物體類別下評估了我們的算法。實驗結果證明了相比于State-Of-Art算法,我們的算法可以在沒有標簽,沒有語義背景去除的情況下進行實例分割,并有較好的算法性能。
算法流程
 ?
? 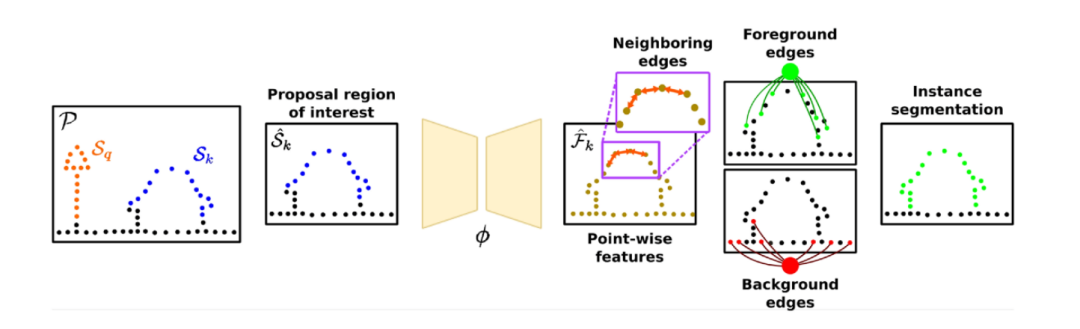
圖2:算法整體流程圖
算法整體流程可以用上圖來表示。我們通過Graph-Cut和自監督學習特征的方法來講場景中的實例區分開。我們將點云整體表示成圖,通過自監督網絡計算出點顯著性分布圖,來對前景圖和后景圖進行采樣,實現實例分割。因為點云中可能存在多個物體實例,這也給前后背景分離增加了難度。
因此,我們改變策略,先對點云中的地面進行分割,區分出地面點和非地面點,并對非地面點進行聚類。然后我們迭代地遍歷每個地方,并對每個興趣點附近規劃出一個立方體區域。對于這個區域,我們將立方體中的實例作為前景對象,地面點和其他實例點作為背景區域。然后我們可以通過該區域來構建圖,并依據圖分割成前景和背景。
A. 實例提案
為了更好地分割出實例,我們的算法依賴于初始猜測(也被稱為提案),隨后可以被精細化為更好地分割。為了和之前的工作(SegContrast)的符號保持統一,我們定義實例如下:對于一組N個點的點云P={p1,p2,...,pN},我們通過地面分割的算法將它分為地面點G和非地面點P′,然后通過HDBSCAN聚類算法來將非地面點聚類成m個類,被定義成m個類的過程我們則稱為提案。其中I={S1,...Sm},這里Sk∈P′并且對于不屬于同類來說,Sk∩Sl=?,l≠k。
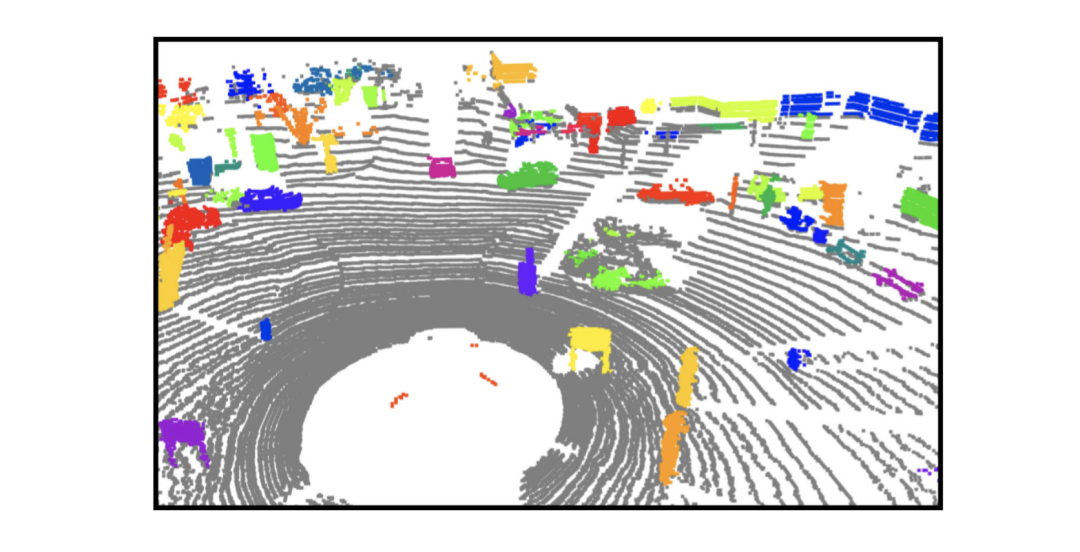
圖3:點云中實例分割提案
如圖3所示,這些分割是實例表示的起點,并不是實例表示的最后結果。我們的算法之后將其映射到特征圖中來計算相同提案中不同點之間的相似性。之后,我們將從這個背景圖中分割出這些物體來做為實例分割。
B.自監督特征
我們的方法充分運用了自監督表征學習來抽取出點對特征。我們使用MinkUNet來作為特征抽取模型。該方法是一種自監督方法,依賴于對場景中的地面點進行去除,并對剩余點進行聚類。它的對比損失函數逐段運用,通過判別的方式學習出特征空間。
對于每一個學習出的提案Sk∈I,我們定義興趣區域S^∈P,然后用SegContrast預訓練模型抽取出點對特征F^k,之后我們通過這些特征來計算出點對相似性,而不是直接計算出其測量的特征。到此,我們有描述性特征可以用來識別實例段和背景之間的差異。
C. Saliency Maps.
Saliency Map通常是分析網絡學習到的特征空間。為了計算顯著性地圖,我們通常計算它的梯度并可視化對它影響更大的區域。這些年也有人通過transformer來提取和制作對應的可視化,即使在沒有標簽的情況下也可以很好的計算出對應的對象邊界。盡管在SegContrast中使用的是稀疏卷積神經網絡,我們觀察到它也可以在顯著性圖中找到實例注意力的地方。這種顯著性的值可以更好地解釋為哪里是前景,哪里是背景,是后面用于GraphCut的隨機初始種子。
對于前面的實例提案,我們計算出每個特征向量中的均值δ。
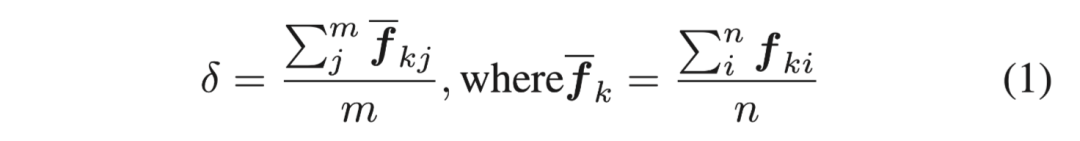
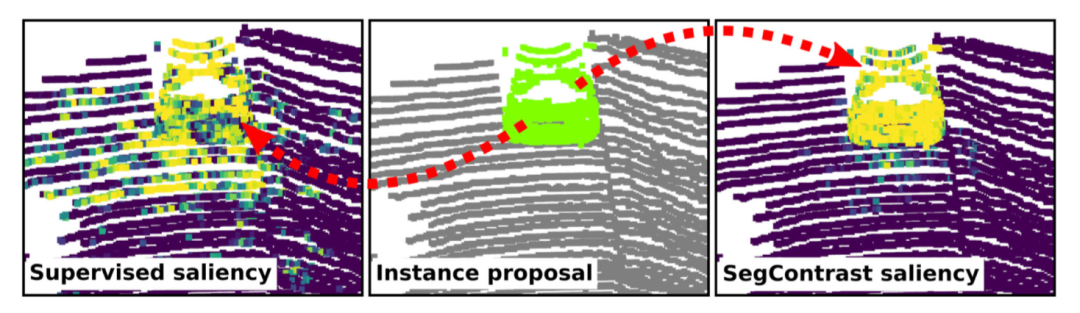
圖4. 受監督的語義分割網絡與用SegContrast進行自我監督的網絡,兩個網絡得到的顯著性圖(saliency map,左圖與右圖)與該算法得到的proposal實例點特征圖(中間)進行對比。該圖用不同顏色區分不同物體,因此最好查看原本彩圖
通過計算δ的梯度變化,我們得到每個提案附近的顯著性圖。如上圖所示,通過該方法得到的顯著性地圖可以更精細地區分出場景中的實例對象。
D. Seeds Sampling.
我們采用實例提案Sk和他們對應的顯著性值來做前景和背景信息的采樣。由于實例信息中對應的是不同的物體,所以固定數量的采樣方式并不一定合適。因此,我們依據提案Sk和他們對應的興趣區域大小來定義具體的采樣點數量。這里我們選取τ_f=nf/γf作為前景種子,選取τ_b=nb/γb作為背景種子,這里γf和γb都是預先定義的參數。
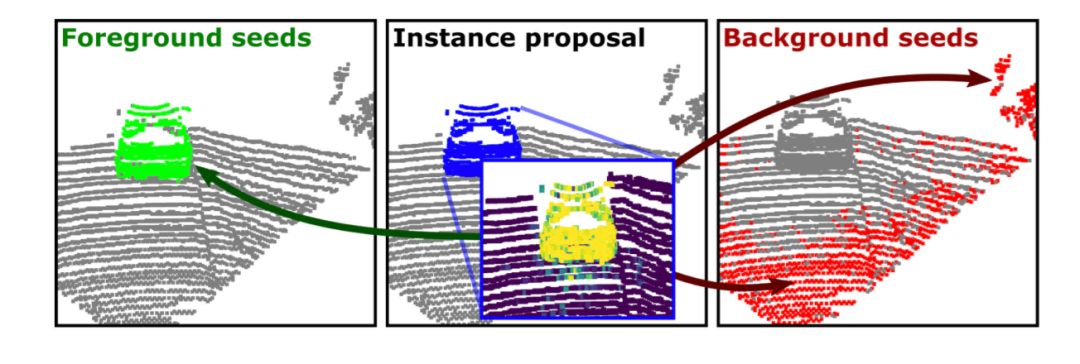
圖5.我們基于藍色點的提議下,將前景點和背景點計算出來,分辨用綠色和紅色來表示.
上圖是種子信息選取的過程。我們對每個前景種子周圍的k個鄰居點進行采樣,來計算前景信息的相似性。同時我們在提案之內刪除任何背景種子,在提案之外刪除任何前景種子來避免顯著性圖中產生異常值。通過這樣的方式,我們可以避免錯誤的種子采樣從而影響到圖割算法的性能。
E.圖割算法
為了更好地從點云中分割出實例對象,我們采用圖割算法,一種用于圖像分割的經典算法,現在用在點云數據上。這種方法主要通過一種圖的表示來描述各個節點中和他們鄰節點之間的關系,從而找出前景和背景數據。然后,我們再對圖用最小切歌方法,切除當中最弱的關系數據。我們采用SegContrast算法來計算每個點上的特征,然后計算相鄰點之間的相似性作為非終端邊緣。最后我們計算顯著性圖以對種子進行采樣并確定點和終端節點之間的邊。
在我們的定義下,一個圖包含一系列的節點Z={z1,...,zn+2},其中每個節點表示的一個點信息在提出的區域Sk中,對應著n個點和2個虛擬的節點,分別代表著前景信息和背景信息。
(1)終端邊緣
每一個點都有兩個虛擬的邊緣節點,我們根據這些節點的歸類方式對這些變進行加權。每一個邊緣的初始概率我們設置成0,然后選擇的節點和對應的終端邊緣節點我們設置為1.0。最后,節點i和一個終端節點t的權重可以定義為:
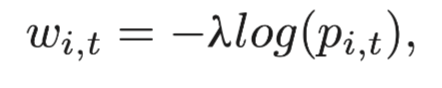
其中λ是預先定義的參數,pi,t的定義表示節點i屬于終端節點t的概率值的大小。
(2)非終端邊緣
對于非終端節點,我們通過坐標選取每個點和它周圍的k歌鄰居點來確定變。為了對邊進行加權,我們計算每個點的特征并計算它與相鄰點之間的差異。我們使用L1范數來定義fi和fj之間的特征區別。
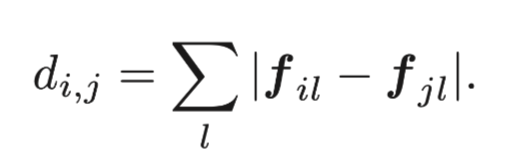
兩點之間的權重也是依據給定出的dij計算出來:
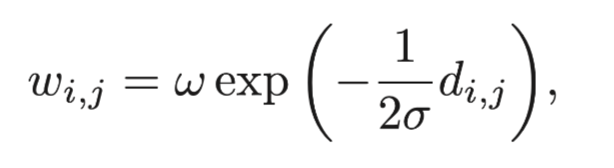
其中σ和w都是預先定義的參數。按照以上的定義,我們可以將點和邊構建清楚,然后通過最小圖割算法來將實例從背景信息中分割出來。我們迭代地重復以上過程,最后將物體從背景信息中分割出來。
實驗分析
在這一節中,我們主要介紹我們基于SemanticKITTI的擴展。
A. 問題定義
現有的實例分割模型假設在推理過程中出現的所有對象類都被手動標記并在訓練時出現。我們將這些對象類稱為已知類。在本文中,我們還想關注那些可能只在推理過程中出現的對象實例分割,我們把它們表示為未知類。
更正式地說,所有對象類的集合X有可能很大,并且許多實例會很少出現。在實踐中,我們無法記錄、標記和評估在所有可能的對象類別上的算法性能,因為這些會出現在對象類別分布中的拖尾類。因此,實際上只有對這些類別的固定子集進行標記才是可行的。
為此,我們進行了如下劃分。我們將SemanticKITTI提供的標簽用于整個數據集(訓練集、驗證集和測試集)的已知類集。這個集合包含經常出現的物體類別,如汽車、人、卡車和類似的物體。我們只在驗證集和測試集中標注一個額外的、不相交的對象實例集,即未知的對象實例U?X, 且U∩K=?。
因此,我們的測試集提供了一個“代理”,用于評估算法在只在很少情況下出現的未知物體上的性能。我們注意到,這些實例的例子可能出現在訓練集和驗證集中,但沒有被標記為實例。
由于我們解決了實例分割的問題,我們只標記了事物(thing)類:在文獻[21]中,東西(stuff)類被認為是不可計數的類,例如,植被或道路。而事物類,如汽車和行人,通常有明確的邊界,在單個掃描中是可見的,并且是可計算的。
B. 評價
對于開放世界的實例分割,我們評估了 算法能將LiDAR點云分解為單獨一組物體實例的能力。為了量化性能,一種可能性是采用基于召回(recall)的變體:泛光質量(Panoptic Quality, PQ)的,未知質量(Unknown Quality, UQ),他們基于召回(recall)用的方法代替了識別質量(recognition quality,RQ)項(F1-Score)。
然而,這種度量將點云的東西(stuff)區域作為一個單一的實例,這并不可取[29]。例如,植被類可以被分解成幾個實例(樹干、小灌木)--這些沒有被手工注釋者標記,但可以依據任務的不同,被認為是有效的實例,例如, segment-based LiDAR odometry或SLAM[16]。
我們轉而采用LiDAR分段和跟蹤質量( LiDAR Segmentation and Tracking Quality,LSTQ)指標。它由兩個術語組成,一個分類Scls和一個分割Sassoc。然而,由于我們任務與類別無關,我們刪除了Scls,只依靠Sassoc來評估實例段的質量如何。
關聯項Sassoc衡量我們將點分配給它們的實例的程度,與語義無關:
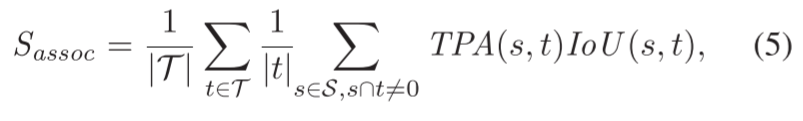
其中,IoU輸入是真值物體t∈T和預測s∈S對、這個對通過真陽性關聯(TPA)、假陰性關聯(FNA)和假陽性關聯(FPA)的集合來計算的。這些集合是以class-agnostic的方式評估的,但與Aygün等人[1]的工作不同,因為這些集合由每個掃描都進行計算得來而不是按整個序列計算的。
直觀地說,TPA集量化了有多少個點被正確地分配給它們相應的實例,TPA和FPA集表面兩種不同類型的“點到實例”關聯錯誤。更確切地說,TPA集包含所有相互重疊的點。FPA集表示s中所有與t不重疊的點,最后,FNA代表屬于t中但不包含在s中的點(Aygün等)。
關聯項是class-agnostic的,并且只表征將點分配給標記的物體實例的表現如何。這使我們能夠評估區別于語義的實例分割,使這個指標獨特地適用于開放世界LiDAR實例分割的評估。
C. 開放世界的SemanticKITTI數據集和基準
為了合理評價將出現在對象分布中拖尾類物體分割出來的算法,其對應數據集應該為最常見的物體(如交通參與者)提供實例標簽,并為東西(stuff)類提供語義標簽。SemanticKITTI[3]或nuScenes-lidarseg[7]提供了這樣的標簽,與之相反的是對象檢測數據集,只提供三維邊界框。
我們選擇了SemanticKITTI數據集,該數據集擴展了KITTI數據集,對每個LiDAR掃描都進行了密集的逐點語義和實例標簽。它包含訓練中的23,000個標記掃描和測試集中的20,000個標記掃描,為6,315個屬于幾個已知物體類別的物體實例,總共418,649個邊界框,提供語義和物體實例標簽。
我們建立了開放世界的SemanticKITTI基準,該基準適合于評估開放世界環境中的算法性能。我們用3,587個實例擴展了SemanticKITTI的隱藏測試集,總共有292,871個額外的對象實例標簽,這些對象類別不一定屬于原來的對象類別中語義類別--未知對象。
參見Tab. I以了解關于類別分布的統計數據。我們還在驗證集中為未知類的實例貼上標簽,但是只提供了一種用服務端(server-side)評估的方式來評估性能,以便在訓練時保持實例的未知。

V. 試驗評估
我們工作的主要重點是一個與類別無關的實例分割。與以前的方法不同,我們的工作不需要實例或語義標簽來去除背景。我們展示了我們的實驗,以顯示我們的方法它能夠在不去除語義背景的情況下分割實例的能力,并且與最先進的監督方法相比,性能不弱下風。
在我們所有的實驗中,我們使用相同的參數,這些參數根據經驗來定義。對于實例,我們使用預先定義的大小為實例周圍1米的余量來定義感興趣的區域。對于種子采樣,我們使用γf=2, γb=2。對于GraphCut,我們使用σ=1,ω=10和λ=0.1,我們選擇k=8個最近的鄰居來定義非終端的邊緣,并建立圖形。對于自我監督的預訓練模型,我們使用SegContrast[28]中描述的相同預訓練。訓練了200個epochs。
我們在兩種設置中比較了我們的方法:只使用來自GraphCut的分割,命名為Ours;以及使用后處理步驟,即從用于生成proposals的地面分割中過濾點,命名為Ors?。我們將我們的結果與不同的無監督聚類方法和基于監督學習的方法進行比較。
對于聚類方法,我們使用與我們的方法相同的實例proposals過程,即去除地面,然后對剩余的點進行聚類。我們評估了HDBSCAN[8]和Euclidean聚類[30]。此外,我們還比較了一種在點云的鳥瞰圖上操作的技術、帶有快速移動算法的聚類以及一種基于快速范圍圖像的建議生成方法。
此外,我們評估了兩種基于監督學習的方法:Hu等人提出的方法[20]用語義分割網絡去除背景,并給定一個學習的對象性值對剩余的點進行聚類,還有一種完全數據驅動的方法4D-PLS[1]用于封閉世界的實例分割。
A. 關聯質量
這個實驗評估了測試集上的預測實例和基礎真值實例之間的關聯。結果表明,我們的方法,即使不使用標簽,也達到了非常先進的性能。
表二顯示了用度量對不同方法,在已知和未知實例以及class-agnostic的情況(即已知和未知)三種情況下的性能評估。通過比較不同的聚類方法,我們發現,HDBSCAN呈現出最好的性能,這也側面說明了我們選擇使用它來進行實例proposal的理由。
4D-PLS方法在已知實例方面取得了最好的性能,而我們的方法在無監督的情況下具有最好的性能。我們的方法在很大程度上改善了HDBSCAN的實例建議,甚至超過了Hu的方法。對于未知實例,有監督的方法的性能下降。我們的方法在去除地面點后,對未知實例取得了最好的性能。
當看class-agnostic的情況時,我們的方法在去除地面的情況下比無監督方法好,不去除地面也比有監督方法好。
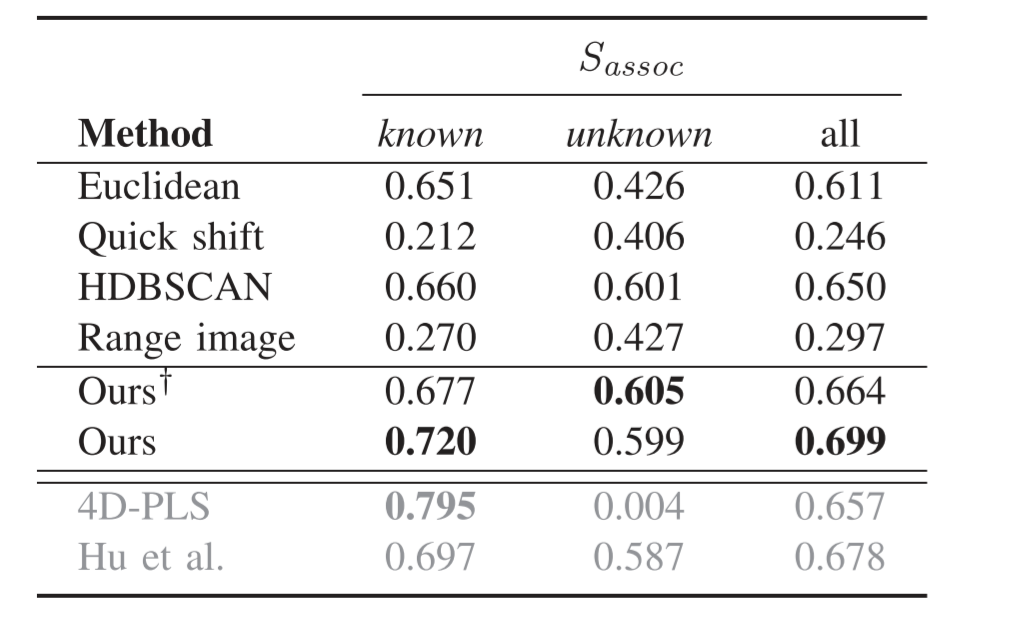
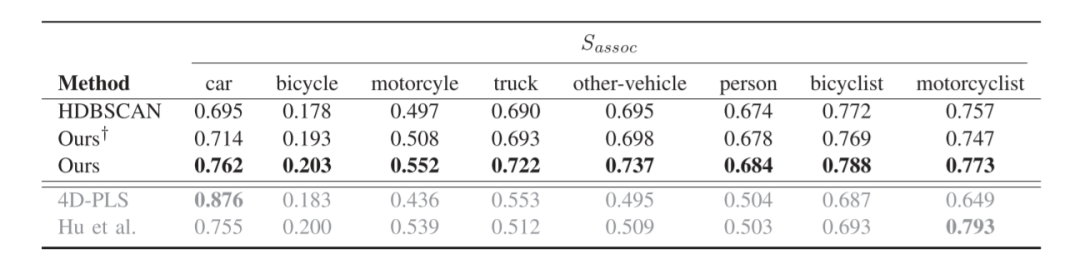
表三顯示了每個已知類別的Sassoc。監督方法的性能在最有代表性的類別,即汽車上呈現出最佳性能。對于其他類別,它們的性能會下降,因為這些類別在訓練集中的樣本較少。我們的方法在大多數類別上超過了HDBSCAN實例proposal和監督方法。通過使用無監督學習的特征,我們的方法對經常出現的類的過擬合程度較低,更適合于對class-agnostic的實例分割。
B. 實例分割質量
本實驗評估了預測實例和地面實況之間的交叉聯合(intersection-over-union, IoU)和召回率。我們通過不同的IoU閾值來計算IoU和召回率,并計算不同閾值的平均值來評估方法的整體性能。
表四顯示了不同閾值的IoU和召回率的結果。在高閾值下,即IoU90,有監督的方法比其他方法表現更好。由于4D-PLS是一種全景分割方法,其在所有的閾值上對已知實例取得了最好的性能。然而,它在分割未知實例時失敗了。隨著閾值的降低,我們的方法性能越來越接近監督方法,并在未知實例中超過了它們。在整體評估中,我們的方法與監督方法不相上下,并且在召回率方面表現最好。
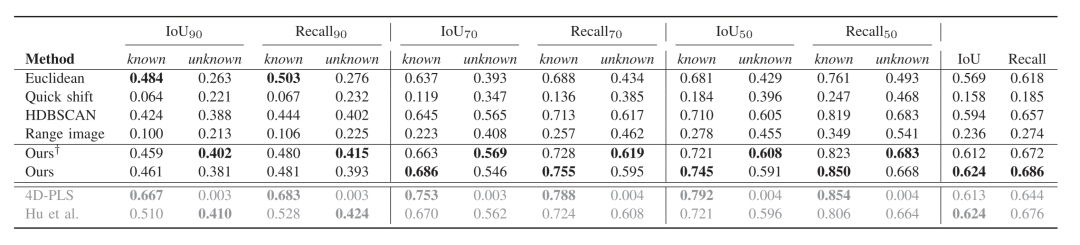
C. 限制條件
此外,我們還比較了我們的方法在有和沒有去除地面后處理的情況下,討論了其局限性。從上一節中可以看出,在沒有去除地面后處理的情況下,我們的方法取得了最好的整體性能,特別是對已知實例。然而,在去除地面的情況下,它在未知實例上的表現更好。
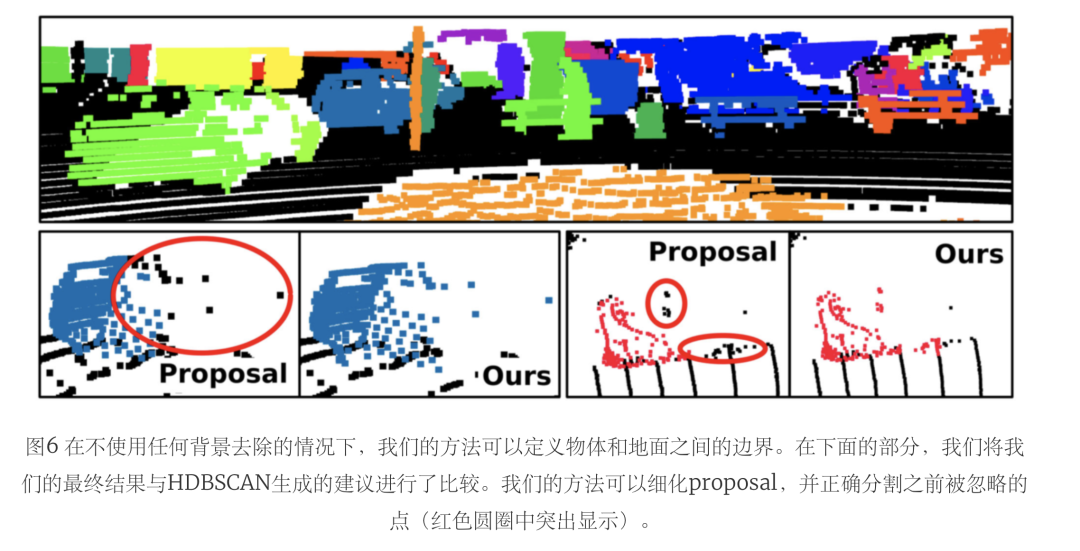
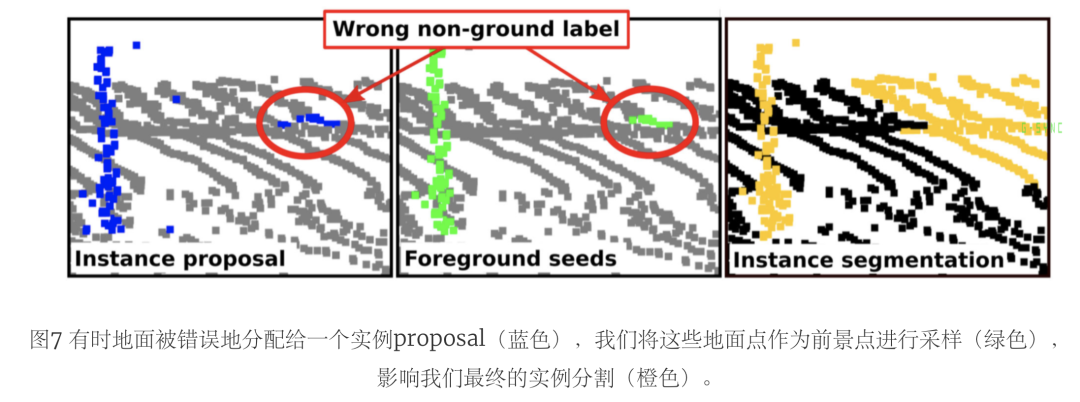
表五將這兩種設置與HDBSCAN proposal進行了比較。盡管去除地面點會導致對未知實例的更好分割,但它對已知實例的影響更大,使性能下降了很多。在圖7中,我們舉了一個例子來解釋這種行為。由于地面分割是由一個無監督的方法完成的,它可能會有點被錯誤分配為地面和非地面。
因此,我們的方法可以通過正確分配以前被錯誤地認為是地面的實例點來改善分割。然而,由于地面分割的不完善,一些proposal可能會將地面視為實例點。在這種情況下,我們的方法可能會將地面點作為前景種子進行采樣,導致會將更廣泛的地面區域分割做為實例的一部分。
通過后處理去除地面,我們過濾了被采樣為前景的地面區域,同時也過濾了被正確分配為實例的點,這些點之前被錯誤地標記為地面。因此,我們的方法的主要局限性依賴于用于采樣前景和背景種子的初始proposal。

結論
在本文中,我們提出了一種新的無監督的、class-agnostic的實例分割方法。我們的方法使用無監督聚類來定義實例proposal,并使用圖形優化算法來完善這些建議,以便更恰當地進行實例分割。我們的方法將點云表示為一個圖,并利用自我監督的表示學習法來提取點的特征,從而映射圖中的點鄰域相似性。
這使我們能夠從背景點中分離出前景實例,而不需要標簽。此外,我們還提出了一個新的開放世界數據集,以評估已知和未知實例類的class-agnostic實例分割,并提出了該基準的評估程序。實驗表明,我們的方法更適合于class-agnostic的實例分割,因為它取得了與最先進的監督方法相競爭的性能,甚至在未知類中超過了它。我們希望我們的工作能激勵對自監督實例分割的進一步研究,并且希望我們的基準對研究界能有所貢獻。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100802 -
圖像分割
+關注
關注
4文章
182瀏覽量
18003 -
LIDAR
+關注
關注
10文章
327瀏覽量
29437
原文標題:3DUIS-基于激光點云的無監督類無關實例分割算法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
不需要點表的工業網關應用案例:如何提升工業企業生產效率與質量?

深控技術 “不需要點表的工業網關” 在機械加工中的解決方案及實施案例
C語言為什么不需要包含stdio.h
基于 “不需要點表的工業網關” 的工業自動化設備遠程監控解決方案

SMT 產線數據采集方案 —— 不需要點表的工業網關
選擇ths4631后需不需要用jfet呀?
網線那幾根線不需要
神經網絡如何用無監督算法訓練
馬斯克稱特斯拉的FSD系統不需要激光雷達





 工商網監
工商網監
評論