 如何將Hadoop部署在低廉的硬件上
如何將Hadoop部署在低廉的硬件上
一、概述
Hadoop 是 Apache 軟件基金會下一個開源分布式計算平臺,以 HDFS(Hadoop Distributed File System)、MapReduce(Hadoop2.0 加入了 YARN,Yarn 是資源調度框架,能夠細粒度的管理和調度任務,還能夠支持其他的計算框架,比如 spark)為核心的 Hadoop 為用戶提供了系統底層細節透明的分布式基礎架構。hdfs 的高容錯性、高伸縮性、高效性等優點讓用戶可以將 Hadoop 部署在低廉的硬件上,形成分布式系統。
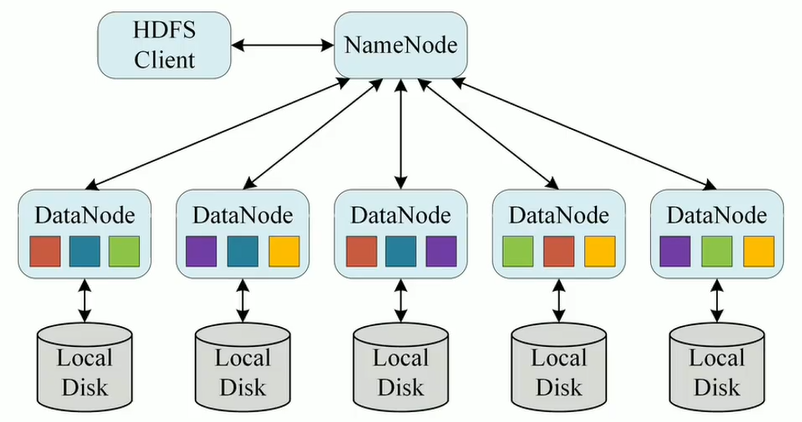 HDFS
HDFS 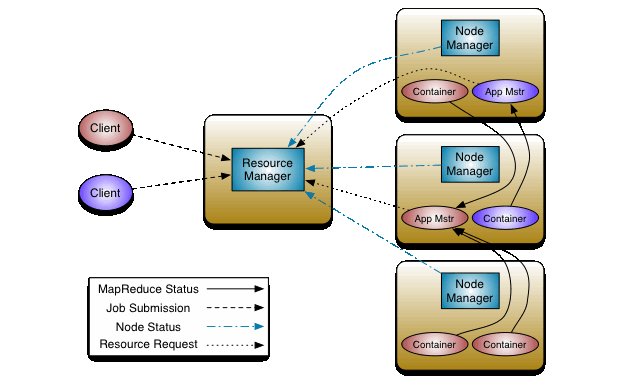 YARN
YARN
二、開始部署
1)添加源
地址:
https://artifacthub.io/packages/helm/apache-hadoop-helm/hadoop
helmrepoaddapache-hadoop-helmhttps://pfisterer.github.io/apache-hadoop-helm/ helmpullapache-hadoop-helm/hadoop--version1.2.0 tar-xfhadoop-1.2.0.tgz
2)構建鏡像 Dockerfile
FROMmyharbor.com/bigdata/centos:7.9.2009 RUNrm-f/etc/localtime&&ln-sv/usr/share/zoneinfo/Asia/Shanghai/etc/localtime&&echo"Asia/Shanghai">/etc/timezone RUNexportLANG=zh_CN.UTF-8 #創建用戶和用戶組,跟yaml編排里的spec.template.spec.containers.securityContext.runAsUser:9999 RUNgroupadd--system--gid=9999admin&&useradd--system--home-dir/home/admin--uid=9999--gid=adminadmin #安裝sudo RUNyum-yinstallsudo;chmod640/etc/sudoers #給admin添加sudo權限 RUNecho"adminALL=(ALL)NOPASSWD:ALL">>/etc/sudoers RUNyum-yinstallinstallnet-toolstelnetwget RUNmkdir/opt/apache/ ADDjdk-8u212-linux-x64.tar.gz/opt/apache/ ENVJAVA_HOME=/opt/apache/jdk1.8.0_212 ENVPATH=$JAVA_HOME/bin:$PATH ENVHADOOP_VERSION3.3.2 ENVHADOOP_HOME=/opt/apache/hadoop ENVHADOOP_COMMON_HOME=${HADOOP_HOME} HADOOP_HDFS_HOME=${HADOOP_HOME} HADOOP_MAPRED_HOME=${HADOOP_HOME} HADOOP_YARN_HOME=${HADOOP_HOME} HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop PATH=${PATH}:${HADOOP_HOME}/bin #RUNcurl--silent--output/tmp/hadoop.tgzhttps://ftp-stud.hs-esslingen.de/pub/Mirrors/ftp.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz&&tar--directory/opt/apache-xzf/tmp/hadoop.tgz&&rm/tmp/hadoop.tgz ADDhadoop-${HADOOP_VERSION}.tar.gz/opt/apache RUNln-s/opt/apache/hadoop-${HADOOP_VERSION}${HADOOP_HOME} RUNchown-Radmin:admin/opt/apache WORKDIR$HADOOP_HOME #Hdfsports EXPOSE500105002050070500755009080209000 #Mapredports EXPOSE19888 #Yarnports EXPOSE8030803180328033804080428088 #Otherports EXPOSE497072122
開始構建鏡像
dockerbuild-tmyharbor.com/bigdata/hadoop:3.3.2.--no-cache ###參數解釋 #-t:指定鏡像名稱 # . :當前目錄Dockerfile #-f:指定Dockerfile路徑 #--no-cache:不緩存
推送到鏡像倉庫
dockerpushmyharbor.com/bigdata/hadoop:3.3.2
調整目錄結構
mkdirhadoop/templates/hdfshadoop/templates/yarn mvhadoop/templates/hdfs-*hadoop/templates/hdfs/ mvhadoop/templates/yarn-*hadoop/templates/yarn/
2)修改配置
hadoop/values.yaml
image: repository:myharbor.com/bigdata/hadoop tag:3.3.2 pullPolicy:IfNotPresent ... persistence: nameNode: enabled:true storageClass:"hadoop-nn-local-storage" accessMode:ReadWriteOnce size:10Gi local: -name:hadoop-nn-0 host:"local-168-182-110" path:"/opt/bigdata/servers/hadoop/nn/data/data1" dataNode: enabled:true storageClass:"hadoop-dn-local-storage" accessMode:ReadWriteOnce size:20Gi local: -name:hadoop-dn-0 host:"local-168-182-110" path:"/opt/bigdata/servers/hadoop/dn/data/data1" -name:hadoop-dn-1 host:"local-168-182-110" path:"/opt/bigdata/servers/hadoop/dn/data/data2" -name:hadoop-dn-2 host:"local-168-182-110" path:"/opt/bigdata/servers/hadoop/dn/data/data3" -name:hadoop-dn-3 host:"local-168-182-111" path:"/opt/bigdata/servers/hadoop/dn/data/data1" -name:hadoop-dn-4 host:"local-168-182-111" path:"/opt/bigdata/servers/hadoop/dn/data/data2" -name:hadoop-dn-5 host:"local-168-182-111" path:"/opt/bigdata/servers/hadoop/dn/data/data3" -name:hadoop-dn-6 host:"local-168-182-112" path:"/opt/bigdata/servers/hadoop/dn/data/data1" -name:hadoop-dn-7 host:"local-168-182-112" path:"/opt/bigdata/servers/hadoop/dn/data/data2" -name:hadoop-dn-8 host:"local-168-182-112" path:"/opt/bigdata/servers/hadoop/dn/data/data3" ... service: nameNode: type:NodePort ports: dfs:9000 webhdfs:9870 nodePorts: dfs:30900 webhdfs:30870 dataNode: type:NodePort ports: dfs:9000 webhdfs:9864 nodePorts: dfs:30901 webhdfs:30864 resourceManager: type:NodePort ports: web:8088 nodePorts: web:30088 ... securityContext: runAsUser:9999 privileged:true
hadoop/templates/hdfs/hdfs-nn-pv.yaml
{{-range.Values.persistence.nameNode.local}}
---
apiVersion:v1
kind:PersistentVolume
metadata:
name:{{.name}}
labels:
name:{{.name}}
spec:
storageClassName:{{$.Values.persistence.nameNode.storageClass}}
capacity:
storage:{{$.Values.persistence.nameNode.size}}
accessModes:
-ReadWriteOnce
local:
path:{{.path}}
nodeAffinity:
required:
nodeSelectorTerms:
-matchExpressions:
-key:kubernetes.io/hostname
operator:In
values:
-{{.host}}
---
{{-end}}
hadoop/templates/hdfs/hdfs-dn-pv.yaml
{{-range.Values.persistence.dataNode.local}}
---
apiVersion:v1
kind:PersistentVolume
metadata:
name:{{.name}}
labels:
name:{{.name}}
spec:
storageClassName:{{$.Values.persistence.dataNode.storageClass}}
capacity:
storage:{{$.Values.persistence.dataNode.size}}
accessModes:
-ReadWriteOnce
local:
path:{{.path}}
nodeAffinity:
required:
nodeSelectorTerms:
-matchExpressions:
-key:kubernetes.io/hostname
operator:In
values:
-{{.host}}
---
{{-end}}
修改 hdfs service
mvhadoop/templates/hdfs/hdfs-nn-svc.yamlhadoop/templates/hdfs/hdfs-nn-svc-headless.yaml mvhadoop/templates/hdfs/hdfs-dn-svc.yamlhadoop/templates/hdfs/hdfs-dn-svc-headless.yaml #注意修改名稱,不要重復
hadoop/templates/hdfs/hdfs-nn-svc.yaml
#AheadlessservicetocreateDNSrecords
apiVersion:v1
kind:Service
metadata:
name:{{include"hadoop.fullname".}}-hdfs-nn
labels:
app.kubernetes.io/name:{{include"hadoop.name".}}
helm.sh/chart:{{include"hadoop.chart".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:hdfs-nn
spec:
ports:
-name:dfs
port:{{.Values.service.nameNode.ports.dfs}}
protocol:TCP
nodePort:{{.Values.service.nameNode.nodePorts.dfs}}
-name:webhdfs
port:{{.Values.service.nameNode.ports.webhdfs}}
nodePort:{{.Values.service.nameNode.nodePorts.webhdfs}}
type:{{.Values.service.nameNode.type}}
selector:
app.kubernetes.io/name:{{include"hadoop.name".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:hdfs-nn
hadoop/templates/hdfs/hdfs-dn-svc.yaml
#AheadlessservicetocreateDNSrecords
apiVersion:v1
kind:Service
metadata:
name:{{include"hadoop.fullname".}}-hdfs-dn
labels:
app.kubernetes.io/name:{{include"hadoop.name".}}
helm.sh/chart:{{include"hadoop.chart".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:hdfs-nn
spec:
ports:
-name:dfs
port:{{.Values.service.dataNode.ports.dfs}}
protocol:TCP
nodePort:{{.Values.service.dataNode.nodePorts.dfs}}
-name:webhdfs
port:{{.Values.service.dataNode.ports.webhdfs}}
nodePort:{{.Values.service.dataNode.nodePorts.webhdfs}}
type:{{.Values.service.dataNode.type}}
selector:
app.kubernetes.io/name:{{include"hadoop.name".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:hdfs-dn
修改 yarn service
mvhadoop/templates/yarn/yarn-nm-svc.yamlhadoop/templates/yarn/yarn-nm-svc-headless.yaml mvhadoop/templates/yarn/yarn-rm-svc.yamlhadoop/templates/yarn/yarn-rm-svc-headless.yaml mvhadoop/templates/yarn/yarn-ui-svc.yamlhadoop/templates/yarn/yarn-rm-svc.yaml #注意修改名稱,不要重復
hadoop/templates/yarn/yarn-rm-svc.yaml
#Servicetoaccesstheyarnwebui
apiVersion:v1
kind:Service
metadata:
name:{{include"hadoop.fullname".}}-yarn-rm
labels:
app.kubernetes.io/name:{{include"hadoop.name".}}
helm.sh/chart:{{include"hadoop.chart".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:yarn-rm
spec:
ports:
-port:{{.Values.service.resourceManager.ports.web}}
name:web
nodePort:{{.Values.service.resourceManager.nodePorts.web}}
type:{{.Values.service.resourceManager.type}}
selector:
app.kubernetes.io/name:{{include"hadoop.name".}}
app.kubernetes.io/instance:{{.Release.Name}}
app.kubernetes.io/component:yarn-rm
修改控制器
在所有控制中新增如下內容:
containers:
...
securityContext:
runAsUser:{{.Values.securityContext.runAsUser}}
privileged:{{.Values.securityContext.privileged}}
hadoop/templates/hadoop-configmap.yaml
###1、將/root換成/opt/apache
###2、TMP_URL="http://{{include"hadoop.fullname".}}-yarn-rm-headless:8088/ws/v1/cluster/info"
3)開始安裝
#創建存儲目錄
mkdir-p/opt/bigdata/servers/hadoop/{nn,dn}/data/data{1..3}
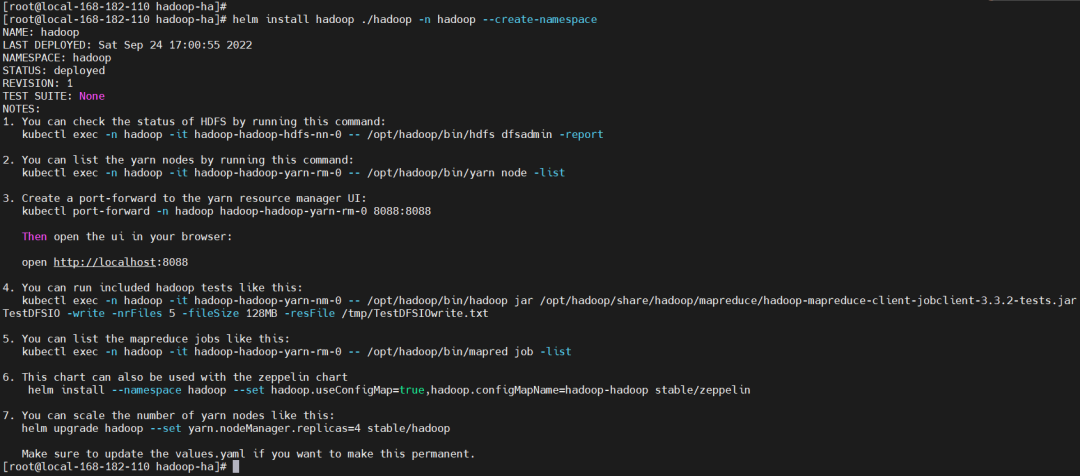
helminstallhadoop./hadoop-nhadoop--create-namespace
NOTES
NAME:hadoop LASTDEPLOYED:SatSep2417552022 NAMESPACE:hadoop STATUS:deployed REVISION:1 TESTSUITE:None NOTES: 1.YoucancheckthestatusofHDFSbyrunningthiscommand: kubectlexec-nhadoop-ithadoop-hadoop-hdfs-nn-0--/opt/hadoop/bin/hdfsdfsadmin-report 2.Youcanlisttheyarnnodesbyrunningthiscommand: kubectlexec-nhadoop-ithadoop-hadoop-yarn-rm-0--/opt/hadoop/bin/yarnnode-list 3.Createaport-forwardtotheyarnresourcemanagerUI: kubectlport-forward-nhadoophadoop-hadoop-yarn-rm-08088:8088 Thenopentheuiinyourbrowser: openhttp://localhost:8088 4.Youcanrunincludedhadooptestslikethis: kubectlexec-nhadoop-ithadoop-hadoop-yarn-nm-0--/opt/hadoop/bin/hadoopjar/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.2-tests.jarTestDFSIO-write-nrFiles5-fileSize128MB-resFile/tmp/TestDFSIOwrite.txt 5.Youcanlistthemapreducejobslikethis: kubectlexec-nhadoop-ithadoop-hadoop-yarn-rm-0--/opt/hadoop/bin/mapredjob-list 6.Thischartcanalsobeusedwiththezeppelinchart helminstall--namespacehadoop--sethadoop.useConfigMap=true,hadoop.configMapName=hadoop-hadoopstable/zeppelin 7.Youcanscalethenumberofyarnnodeslikethis: helmupgradehadoop--setyarn.nodeManager.replicas=4stable/hadoop Makesuretoupdatethevalues.yamlifyouwanttomakethispermanent.
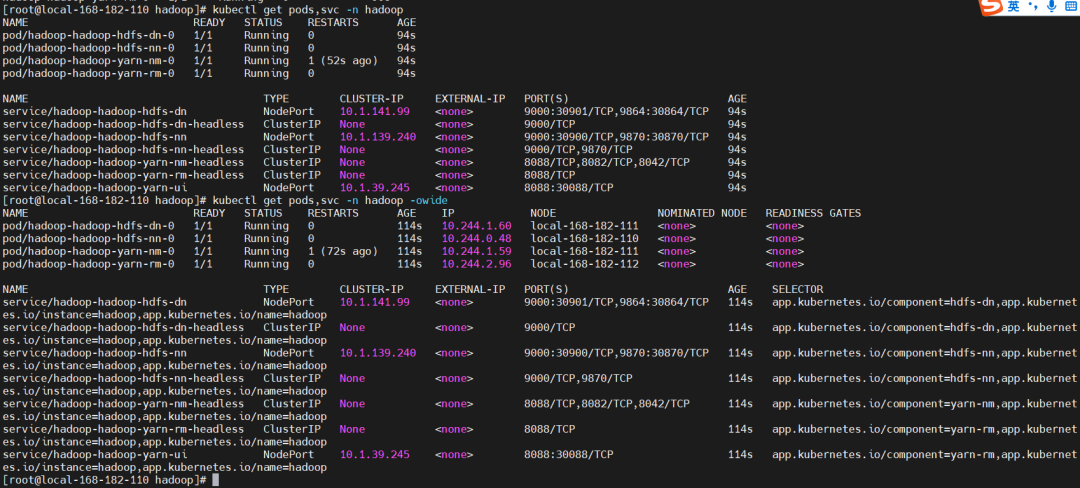
 查看
查看
kubectlgetpods,svc-nhadoop-owide
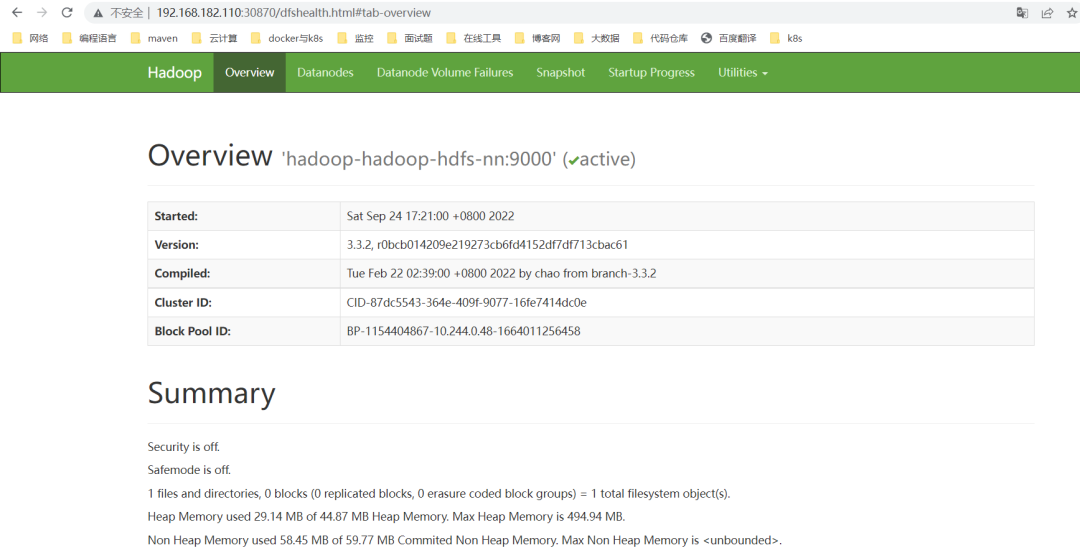
hdfs web:
http://192.168.182.110:30870/
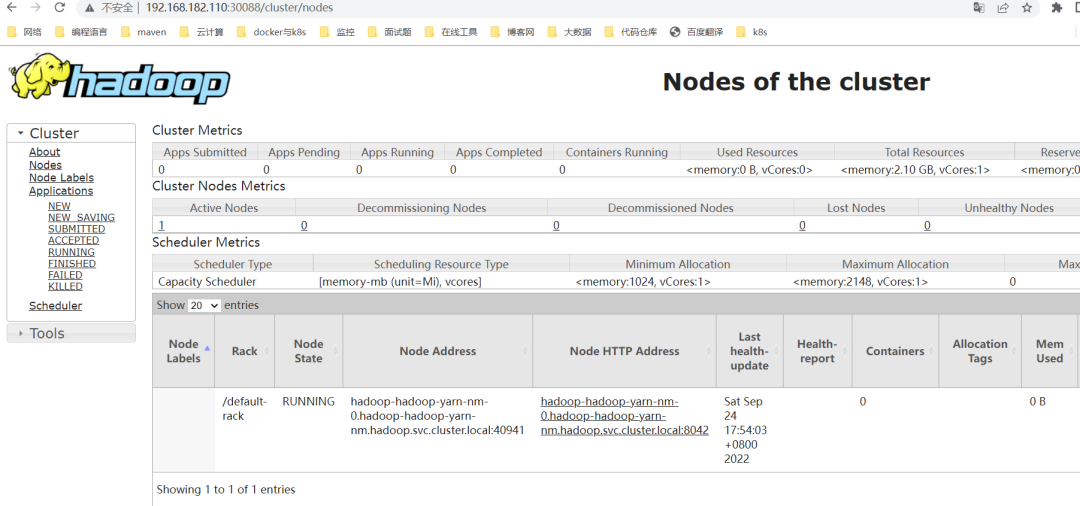
yarn web:
http://192.168.182.110:30088/
5)測試驗證
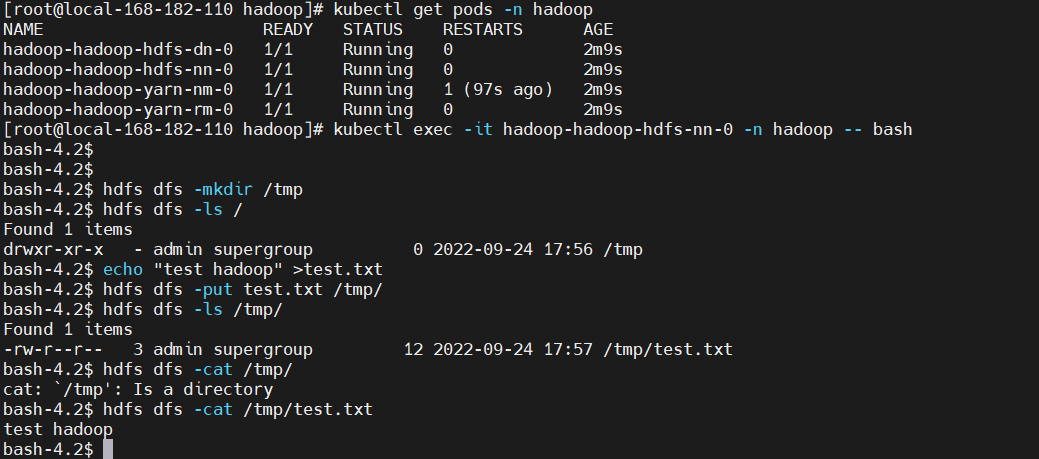
HDFS 測試驗證
kubectlexec-ithadoop-hadoop-hdfs-nn-0-nhadoop--bash [root@local-168-182-110hadoop]#kubectlexec-ithadoop-hadoop-hdfs-nn-0-nhadoop--bash bash-4.2$ bash-4.2$ bash-4.2$hdfsdfs-mkdir/tmp bash-4.2$hdfsdfs-ls/ Found1items drwxr-xr-x-adminsupergroup02022-09-2417:56/tmp bash-4.2$echo"testhadoop">test.txt bash-4.2$hdfsdfs-puttest.txt/tmp/ bash-4.2$hdfsdfs-ls/tmp/ Found1items -rw-r--r--3adminsupergroup122022-09-2417:57/tmp/test.txt bash-4.2$hdfsdfs-cat/tmp/ cat:`/tmp':Isadirectory bash-4.2$hdfsdfs-cat/tmp/test.txt testhadoop bash-4.2$
Yarn 的測試驗證等后面講到 hive on k8s 再來測試驗證。
6)卸載
helmuninstallhadoop-nhadoop
kubectldeletepod-nhadoop`kubectlgetpod-nhadoop|awk'NR>1{print$1}'`--force
kubectlpatchnshadoop-p'{"metadata":{"finalizers":null}}'
kubectldeletenshadoop--force
這里也提供 git 下載地址,有需要的小伙伴可以下載部署玩玩:
https://gitee.com/hadoop-bigdata/hadoop-on-k8s
在 k8s 集群中 yarn 會慢慢被弱化,直接使用 k8s 資源調度,而不再使用 yarn 去調度資源了,這里只是部署了單點,僅限于測試環境使用,下一篇文章會講 Hadoop 高可用 on k8s 實現,請小伙伴耐心等待,有任何疑問歡迎給我留言~
-
硬件
+關注
關注
11文章
3380瀏覽量
66388 -
Hadoop
+關注
關注
1文章
90瀏覽量
16011 -
計算框架
+關注
關注
0文章
4瀏覽量
1944
原文標題:7 張圖入門 Hadoop 在 K8S 環境中部署
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
hadoop無法訪問50070端口解決方案
Hadoop的集群環境部署說明
hadoop和spark的區別
大數據hadoop入門之hadoop家族產品詳解
Hadoop新手篇:hadoop入門基礎教程
如何將程序很好的部署
如何將AI模型部署到嵌入式系統中
淺析Hadoop集群硬件選擇
基于Hadoop的I/O硬件壓縮加速器





 工商網監
工商網監
評論