 利用 Python 和 PyTorch 處理面向對象的數據集(2)) :創建數據集對象
利用 Python 和 PyTorch 處理面向對象的數據集(2)) :創建數據集對象
本篇是利用 Python 和 PyTorch 處理面向對象的數據集系列博客的第 2 篇。
我們在第 1 部分中已定義 MyDataset 類,現在,讓我們來例化 MyDataset 對象
此可迭代對象是與原始數據交互的接口,在整個訓練過程中都有巨大作用。
第 2 部分:創建數據集對象
輸入 [9]:
mydataset = MyDataset(isValSet_bool = None, raw_data_path = raw_data_path, norm = False, resize = True, newsize = (64, 64))
以下是該對象的一些使用示例:
輸入 [10]:
# 對象操作示例。 # 此操作用于調用 method __getitem__ 并從第 6 個樣本獲取標簽 mydataset[6][1]
輸出 [10]:
0
輸入 [11]:
# 此操作用于在類聲明后打印注釋 MyDataset.__doc__
輸出 [11]:
'Interface class to raw data, providing the total number of samples in the dataset and a preprocessed item'
輸入 [12]:
# 此操作用于調用 method __len__ len(mydataset)
輸出 [12]:
49100
輸入 [13]:
# 此操作用于觸發 method __str__ print(mydataset)
原始數據路徑為 ./raw_data/data_images/
可迭代對象的重要性
訓練期間,將向模型提供多批次樣本。可迭代的 mydataset 是獲得高級輕量代碼的關鍵。
以下提供了可迭代對象的 2 個使用示例。
示例 1:
我們可以直接獲取第 3 個樣本張量:
輸入 [14]:
mydataset.__getitem__(3)[0].shape
輸出 [14]:
torch.Size([3, 64, 64])
與以下操作作用相同
輸入 [15]:
mydataset[3][0].shape
輸出 [15]:
torch.Size([3, 64, 64])
示例 2:
我們可以對文件夾中的圖像進行解析,并移除黑白圖像:
輸入 [ ]:
# 數據集訪問示例:創建 1 個包含標簽的新文件,移除黑白圖像
if os.path.exists(raw_data_path + '/'+ "labels_new.txt"):
os.remove(raw_data_path + '/'+ "labels_new.txt")
with open(raw_data_path + '/'+ "labels_new.txt", "a") as myfile:
for item, info in mydataset:
if item != None:
if item.shape[0]==1:
# os.remove(raw_data_path + '/' + info.SampleName)
print('C = {}; H = {}; W = {}; info = {}'.format(item.shape[0], item.shape[1], item.shape[2], info))
else:
#print(info.SampleName + ' ' + str(info.SampleLabel))
myfile.write(info.SampleName + ' ' + str(info.SampleLabel) + '\n')
輸入 [ ]:
# 查找具有非期望格式的樣本
with open(raw_data_path + '/'+ "labels.txt", "a") as myfile:
for item, info in mydataset:
if item != None:
if item.shape[0]!=3:
# os.remove(raw_data_path + '/' + info.SampleName)
print('C = {}; H = {}; W = {}; info = {}'.format(item.shape[0], item.shape[1], item.shape[2], info))
修改標簽文件后,請務必更新緩存:
輸入 [ ]:
if os.path.exists(raw_data_path + '/'+ "labels_new.txt"):
os.rename(raw_data_path + '/'+ "labels.txt", raw_data_path + '/'+ "labels_orig.txt")
os.rename(raw_data_path + '/'+ "labels_new.txt", raw_data_path + '/'+ "labels.txt")
@functools.lru_cache(1)
def getSampleInfoList(raw_data_path):
sample_list = []
with open(str(raw_data_path) + '/labels.txt', "r") as f:
reader = csv.reader(f, delimiter = ' ')
for i, row in enumerate(reader):
imgname = row[0]
label = int(row[1])
sample_list.append(DataInfoTuple(imgname, label))
sample_list.sort(reverse=False, key=myFunc)
return sample_list
del mydataset
mydataset = MyDataset(isValSet_bool = None, raw_data_path = '../../raw_data/data_images', norm = False)
len(mydataset)
您可通過以下鏈接閱讀了解有關 PyTorch 中的可迭代數據庫的更多信息: https://pytorch.org/docs/stable/data.html
歸一化
應對所有樣本張量計算平均值和標準差。
如果數據集較小,可以嘗試在內存中對其進行直接操作:使用 torch.stack 即可創建 1 個包含所有樣本張量的棧。
可迭代對象 mydataset 支持簡潔精美的代碼。
使用“view”即可保留 R、G 和 B 這 3 個通道,并將其余所有維度合并為 1 個維度。
使用“mean”即可計算維度 1 的每個通道的平均值。
請參閱附件中有關 dim 使用的說明。
輸入 [16]:
imgs = torch.stack([img_t for img_t, _ in mydataset], dim = 3)
輸入 [17]:
#im_mean = imgs.view(3, -1).mean(dim=1).tolist() im_mean = imgs.view(3, -1).mean(dim=1) im_mean
輸出 [17]:
tensor([0.4735, 0.4502, 0.4002])
輸入 [18]:
im_std = imgs.view(3, -1).std(dim=1).tolist() im_std
輸出 [18]:
[0.28131285309791565, 0.27447444200515747, 0.2874436378479004]
輸入 [19]:
normalize = transforms.Normalize(mean=[0.4735, 0.4502, 0.4002], std=[0.28131, 0.27447, 0.28744]) # free memory del imgs
下面,我們將再次構建數據集對象,但這次將對此對象進行歸一化:
輸入 [21]:
mydataset = MyDataset(isValSet_bool = None, raw_data_path = raw_data_path, norm = True, resize = True, newsize = (64, 64))
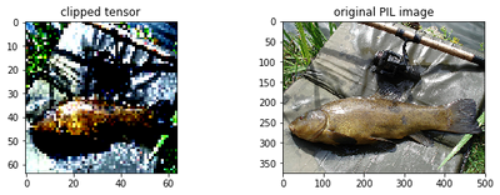
由于采用了歸一化,因此張量值被轉換至范圍 0..1 之內,并進行剪切操作。
輸入 [22]:
original = Image.open('../../raw_data/data_images/img_00009111.JPEG')
fig, axs = plt.subplots(1, 2, figsize=(10, 3))
axs[0].set_title('clipped tensor')
axs[0].imshow(mydataset[5][0].permute(1,2,0))
axs[1].set_title('original PIL image')
axs[1].imshow(original)
plt.show()
將輸入數據剪切到含 RGB 數據的 imshow 的有效范圍內,以 [0..1] 表示浮點值,或者以 [0..255] 表示整數值。
使用 torchvision.transforms 進行預處理
現在,我們已經創建了自己的變換函數或對象(原本用作為加速學習曲線的練習),我建議使用 Torch 模塊 torchvision.transforms:
“此模塊定義了一組可組合式類函數對象,這些對象可作為實參傳遞到數據集(如 torchvision.CIFAR10),并在加載數據后 __getitem__ 返回數據之前,對數據執行變換”。
以下列出了可能的變換:
輸入 [23]:
from torchvision import transforms dir(transforms)
輸出 [23]:
['CenterCrop', 'ColorJitter', 'Compose', 'FiveCrop', 'Grayscale', 'Lambda', 'LinearTransformation', 'Normalize', 'Pad', 'RandomAffine', 'RandomApply', 'RandomChoice', 'RandomCrop', 'RandomErasing', 'RandomGrayscale', 'RandomHorizontalFlip', 'RandomOrder', 'RandomPerspective', 'RandomResizedCrop', 'RandomRotation', 'RandomSizedCrop', 'RandomVerticalFlip', 'Resize', 'Scale', 'TenCrop', 'ToPILImage', 'ToTensor', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'functional', 'transforms']
在此示例中,我們使用變換來執行了以下操作:
1) ToTensor - 從 PIL 圖像轉換為張量,并將輸出格式定義為 CxHxW
2) Normalize - 將張量歸一化
如需了解后續步驟,敬請期待本系列的第 3 部分。
審核編輯 黃昊宇
-
python
+關注
關注
56文章
4807瀏覽量
84959 -
數據集
+關注
關注
4文章
1209瀏覽量
24793 -
pytorch
+關注
關注
2文章
808瀏覽量
13331
發布評論請先 登錄
相關推薦

LabVIEW面向對象的ActorFramework(1)
基于面向對象概念格的卸掉集判定定理
利用Python和PyTorch處理面向對象的數據集(1)
如何利用Dataloder來處理加載數據集

PyTorch教程-14.6. 對象檢測數據集






 工商網監
工商網監
評論