") 一個(gè)定量分析系統(tǒng)瓶頸的方法
一個(gè)定量分析系統(tǒng)瓶頸的方法
目前在系統(tǒng)里面, 我們可以通過(guò)perf 或者 pt-pmp 匯總堆棧的方式來(lái)查看系統(tǒng)存在的熱點(diǎn), 但是我們僅僅能夠知道哪些地方是熱點(diǎn), 卻無(wú)法定量的說(shuō)這個(gè)熱點(diǎn)到底有多熱, 這個(gè)熱點(diǎn)占整個(gè)訪(fǎng)問(wèn)請(qǐng)求的百分比是多少? 是10%, 還是40%, 還是80%?
所以我們需要一個(gè)定量分析系統(tǒng)瓶頸的方法以便于我們進(jìn)行系統(tǒng)優(yōu)化.
本文通過(guò)Performance_schema 來(lái)進(jìn)行定量的分析系統(tǒng)性能瓶頸.
原理如下:
performance_schema.events_waits_summary_global_by_event_name 這里event_name 值得是具體的mutex/sx lock, 比如trx_sys->mutex, lock_sys->mutex 等等, 這個(gè)table 保存的是匯總信息.
具體performance_schema 信息在這里 https://dev.mysql.com/doc/mysql-perfschema-excerpt/8.0/en/performance-schema-wait-summary-tables.html
通過(guò)兩次調(diào)用具體的timer wait 可以算出具體某一個(gè)mutex/sx lock 等待的時(shí)間.
如果這個(gè)時(shí)間再除以每一個(gè)線(xiàn)程就可以算出每一個(gè)線(xiàn)程在這個(gè)Lock 上大概的等待時(shí)間, 然后就可以算出平均1s 內(nèi)等在該mutex/sx lock 的占比.
比如我們知道在sysbench oltp_read_write 的小表測(cè)試中, 通過(guò)pstack 可以看到主要卡在page latch 上, 那么我們需要分析等待patch latch 占用了整個(gè)路徑的時(shí)間大概是多長(zhǎng).
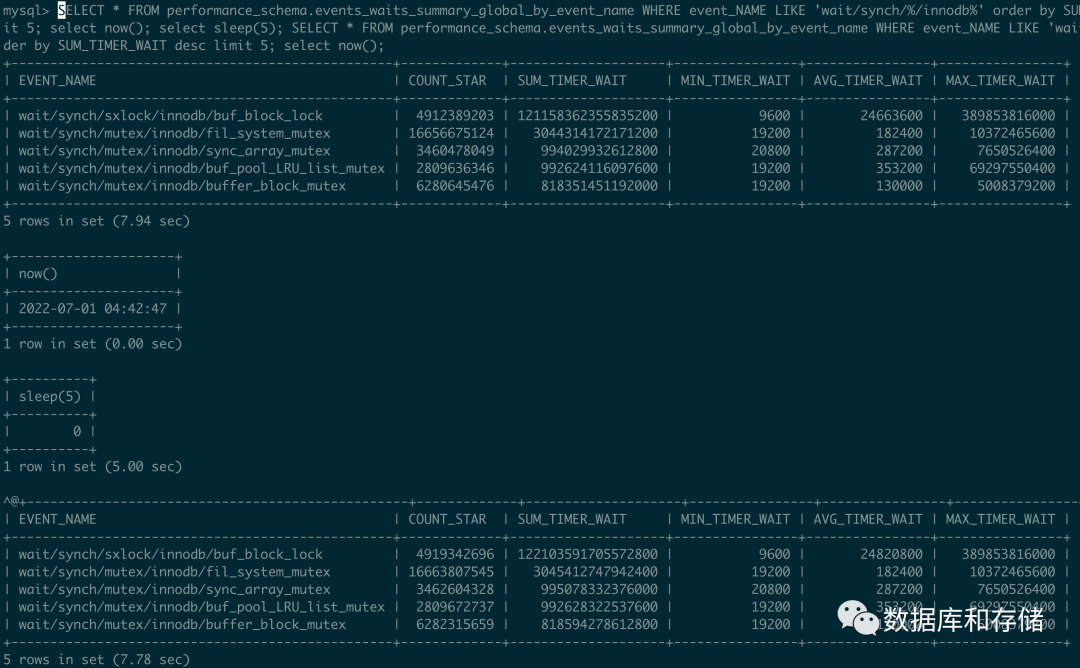
這里使用256 thread 進(jìn)行壓測(cè), 計(jì)算出來(lái)等待的時(shí)間大概是
buf_block_lock = (122103591705572800-121158362355835200)/5/207/1000000000 = 913ms
也就是平均 1s 里面, 每一個(gè)thread 有913ms 等待在page lock 上, 占比90%. 這個(gè)信息和多次pstack 的信息也基本吻合.
fil_system_mutex = (3045412747942400-3044314172171200)/5/207 = 1ms
也就是平均1s 里面等待在fil_system_mutex 只有1ms, 占比0.1%
比如我們最常見(jiàn)的 oltp_insert 非 auto_inc insert 的場(chǎng)景中, 通過(guò)pstack 可以看到主要卡在trx_sys->mutex, 那么這個(gè)trx_sys->mutex 具體有多熱呢?
以下是perf 相關(guān)信息.
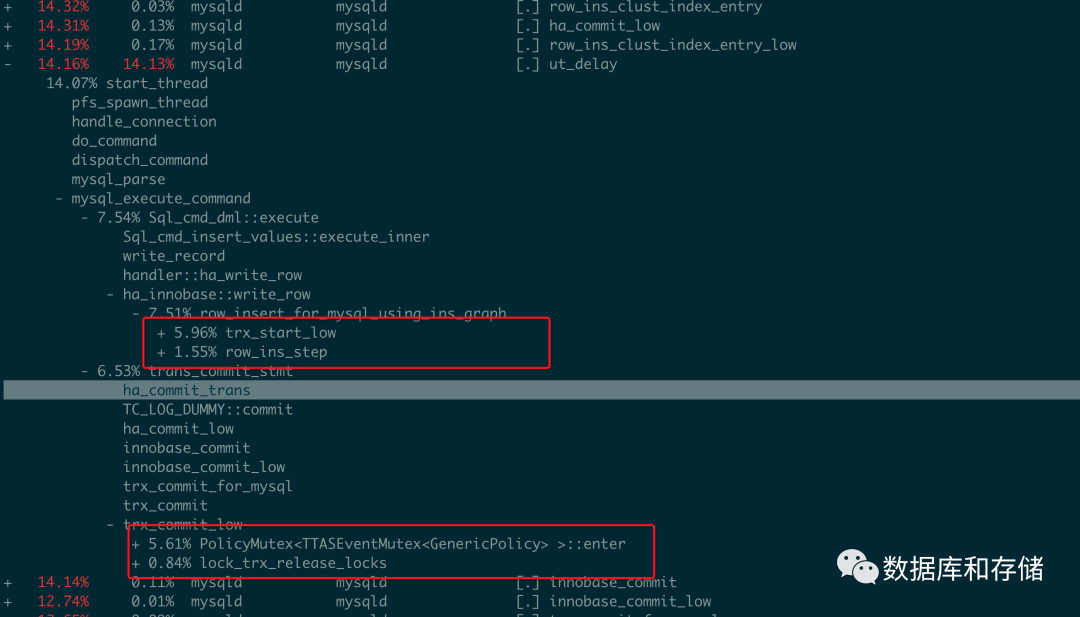
上面紅框下主要的熱點(diǎn)都是需要去獲得trx_sys->mutex, 從而可以操作全局活躍事務(wù)數(shù)組.
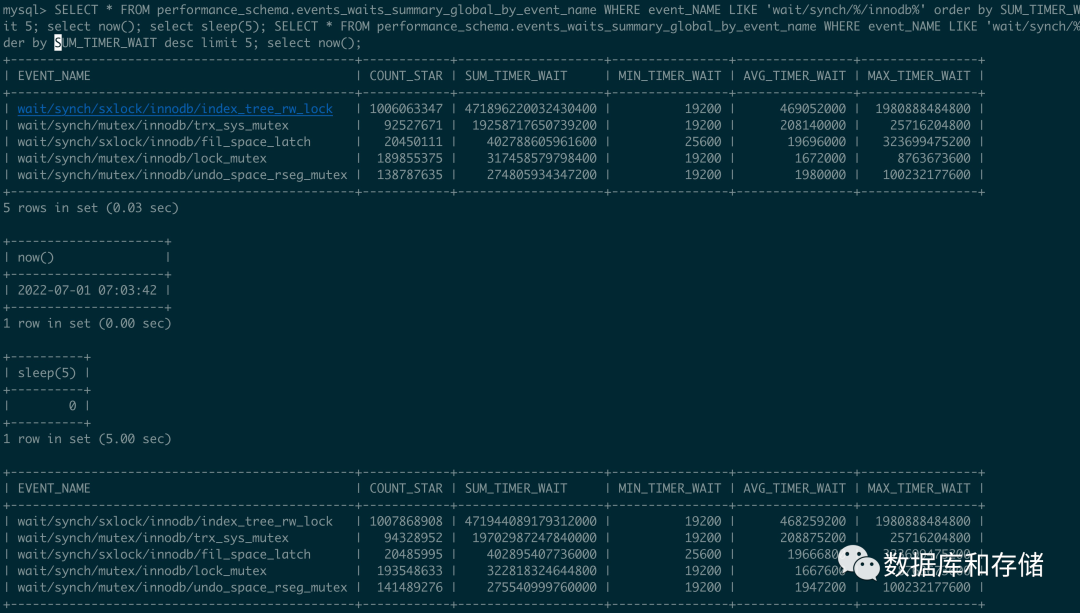
這里使用256 thread 進(jìn)行壓測(cè), 計(jì)算出來(lái)等待的時(shí)間大概是
trx_sys_mutex =(19702987247840000-19258717650739200)/5/250/1000000000 = 355 ms
那么等待trx_sys->mutex 上占比大概是35%.
上面還有一個(gè)看過(guò)去大頭的btree 上面的 index_tree_rw_lock 占比呢
index_tree_rw_lock = (471944089179312000-471896220032430400)/5/250/1000000000 = 38ms
雖然數(shù)據(jù)大, 因?yàn)榕艿木? 但是其實(shí)這里只有3% 的占比
tips:
對(duì)比來(lái)說(shuō) perf 看到的信息是on-cpu 信息, 但是因?yàn)镸ySQL 的mutex/sxlock 都是通過(guò)backoff 機(jī)制進(jìn)行, 在每一次線(xiàn)程切換出去之前都進(jìn)行一段時(shí)間的spin, 所以mysql 的on-cpu 信息可以一定程度反應(yīng)off-cpu 的結(jié)果.
pstack 更體現(xiàn)的是某一時(shí)刻off-cpu 的信息
performance_schame wait_event 也體現(xiàn)的是off-cpu 的信息.
-
分析系統(tǒng)
+關(guān)注
關(guān)注
0文章
56瀏覽量
8080 -
Performance
+關(guān)注
關(guān)注
0文章
9瀏覽量
8771
原文標(biāo)題:通過(guò)performance_schema 定量分析系統(tǒng)瓶頸
文章出處:【微信號(hào):inf_storage,微信公眾號(hào):數(shù)據(jù)庫(kù)和存儲(chǔ)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
大型軟件研發(fā)項(xiàng)目安全性風(fēng)險(xiǎn)定量分析理論模型
嵌入式定量分析系統(tǒng)的原理是什么?
怎么設(shè)計(jì)基于ARM7芯片S3C44BOX的嵌入式定量分析系統(tǒng)?
MATLAB圖像處理在鑄鐵材料定量金相分析中的應(yīng)用
基于氣體傳感器陣列的混合氣體定量分析
鐵磁性鋼絲繩電磁檢測(cè)校準(zhǔn)和定量分析
定量分析中怎樣選擇內(nèi)標(biāo)法或外標(biāo)法
車(chē)站序列瓶頸系統(tǒng)優(yōu)化分析
關(guān)于真菌毒素?zé)晒?b class='flag-5'>定量分析儀的詳細(xì)介紹
熒光層析定量分析儀的原理與性能的介紹
關(guān)于非洲豬瘟熒光層析定量分析儀的原理及性能

基于LIBS的土壤中銅元素和鉛元素定量分析

基于LIBS的馬鈴薯中鉻元素定量分析方法研究
透射電鏡中的EDS定性與定量分析
基于LIBS技術(shù)的銀合金分類(lèi)及定量分析研究





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論