 通過Tensai架構簡化AI邊緣計算
通過Tensai架構簡化AI邊緣計算
隨著物聯網開發人員解決在邊緣部署設備所面臨的連接性、可管理性和安全性挑戰,現在的需求轉向使這些系統更智能。工程師現在的任務是將人工智能 (AI) 集成到網絡遠端的嵌入式系統中,這必須最大限度地減少功耗、通信延遲和成本,同時還要變得更加智能。
不幸的是,許多可用于嵌入式 AI 的處理解決方案太耗電,太難編程,或者對于邊緣應用來說太昂貴。
為了在更高的性能、功耗、成本和易用性之間取得平衡,無晶圓廠 SoC 供應商 Eta Compute 的 Tensai 芯片在 55 nm ULP 中結合了異步 Arm Cortex-M3 CPU、NXP CoolFlux DSP16 內核和低功耗模擬模塊過程(圖 1)。Tensai 解決方案還包含一個神經網絡軟件堆棧,用于實現在 DSP 的雙 16x16 MAC 上本地執行的卷積神經網絡 (CNN) 和尖峰神經網絡 (SNN)。
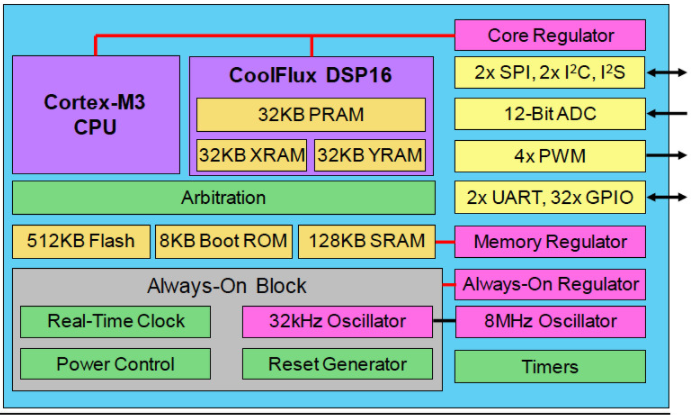
圖 1. Tensai 架構提供超低功耗和確定性以及 AI 邊緣計算所需的性能。
《 2mW 的邊緣 AI
Tensai 架構采用多個穩壓器來支持以小于 2 mW 的超低功耗、始終在線的處理,適用于紐扣電池或太陽能電池供電的 AI 系統。其中包括一個用于芯片實時時鐘和復位電路的專用穩壓器,另一個用于存儲塊,第三個用于 MCU 和 DSP 內核。
該設備僅消耗 600 納安電流,只需開啟常開模塊即可。在內存塊通電的睡眠模式下,這個數字增加到 10 微安。
然而,Tensai 的超低功耗配置并沒有限制 SoC 在 AI 工作負載中的應用。CoolFlux DSP16 內核的運行頻率高達 100 MHz,每秒可提供 2 億個 16 位 MAC 的性能。Tensai 對來自 CIFAR-10 數據集的 32x32 像素圖像進行推理,每秒可以處理 5 張圖像,每張圖像消耗 0.4 毫焦耳。
對于非 DSP 工程師,Tensai 的神經網絡軟件堆棧允許開發人員通過 Cortex-M3 上的解釋器傳遞量化的 TensorFlow Lite 模型,從而抽象出硬件編程的復雜性。然后 Cortex-M3 生成代碼,這些代碼被翻譯成可以在 DSP 上執行的功能。
四通道 DMA 引擎在 I/O 和 32 KB PRAM 以及為 DSP 保留的 64 KB 聯合 XRAM 和 YRAM 之間傳輸數據。除了 16 位分辨率外,CoolFlux 內核還可以處理兩個 8x8 MAC。
在人工智能的邊緣
超低功耗和易于編程將有助于將人工智能帶入普通嵌入式和物聯網工程師,因為他們將智能添加到邊緣。嵌入式和物聯網開發人員熟悉的 Tensai 芯片的其他高級特性包括:
512 KB 閃存(足夠約 450,000 個神經網絡權重)
Cortex-M3 和 DSP 共享 128 KB SRAM
4 個 ADC 通道(12 位 ADC 在 200,000 個樣本/秒時消耗 uW)
4x PWM 通道
審核編輯:郭婷
-
dsp
+關注
關注
554文章
8059瀏覽量
349849 -
芯片
+關注
關注
456文章
51150瀏覽量
426177 -
嵌入式
+關注
關注
5090文章
19175瀏覽量
306856
發布評論請先 登錄
相關推薦
【新品體驗】幸狐Omni3576邊緣計算套件免費試用
研華科技邊緣AI平臺榮獲2024年IoT邊緣計算卓越獎
Orin芯片與邊緣計算結合
邊緣計算的未來發展趨勢
邊緣計算AI算法盒子在停放充電區域AI智慧監控的應用

邊緣AI需求爆發,邊緣計算網關亟待革新
邊緣AI網關,將具備更強大的計算和學習能力
基于RK3588核心板的AI邊緣計算網關設計方案

ai邊緣盒子有哪些用途?ai視頻分析邊緣計算盒子詳解

英特爾發布全新邊緣計算平臺,解決AI邊緣落地難題

Supermicro全新系統產品組合將前沿AI性能推向邊緣計算環境

Supermicro通過業界領先的全新系統產品組合,將前沿AI性能推向邊緣計算環境






 工商網監
工商網監
評論