 嵌入式系統的開發分析和規范控制
嵌入式系統的開發分析和規范控制
在第 1 部分中,我們通過BuildingIQ智能氣候控制系統和Scania緊急卡車制動系統等示例,推動了在嵌入式系統中使用分析。我們涵蓋了數據訪問、數據預處理和最具預測性特征的識別。現在讓我們轉向開發預測分析算法本身。
開發分析算法
重要的是要考慮分析算法是否是您的最佳方法。在系統行為可以通過已知的科學方程很好地表征的情況下,經過驗證的數學建模可以是一種簡單而有效的方式來滿足設計目標。這種方法使用數據擬合、統計建模、ode 和 pde 求解以及參數估計等技術。以這種方式構建的模型具有通過歷史數據或基于第一原理預先確定的優勢,可以在嵌入式系統上實現內存和計算效率,并且可以更簡單地開發和維護。因此,在考慮以數據為中心的機器學習技術之前,首先要謹慎考慮“主力”建模方法是否可以滿足您的設計目標。然而,對于越來越多的設計挑戰,例如在 BuildingIQ 示例中動態設置氣候控制點或在斯堪尼亞制動應用中進行對象識別,機器學習是最好的方法。
機器學習
機器學習算法使用計算方法直接從數據中“學習”信息,而不依賴于預定方程作為模型。事實證明,這種使用數據本身訓練模型的能力為預測建模開辟了廣泛的用例——例如金融信用評分和電影、歌曲和零售購買的在線推薦。在嵌入式系統中,機器學習用于快速增長的應用范圍,包括人臉識別、腫瘤檢測、電力負荷預測以及前面提到的 BuildingIQ 和 Scania 應用。“大數據”、計算能力和軟件工具的可用性提高,使得在工程應用程序中使用機器學習比以往任何時候都更容易。
機器學習大致分為兩種類型的學習方法,監督學習和無監督學習,每一種都包含針對不同問題量身定制的幾種算法。
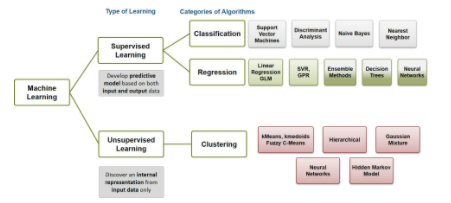
監督學習是一種使用已知數據集(稱為訓練數據集)進行預測的 機器學習。 訓練數據集包括輸入數據和標記的響應值。監督學習算法從中尋求建立一個模型,該模型可以預測新數據集的響應值。測試數據集通常用于驗證模型。使用更大的訓練數據集通常會產生具有更高預測能力的模型,可以很好地泛化新數據集。
監督學習包括兩類算法:
分類:用于分類響應值,其中數據可以分為特定的“類別”。常見的分類算法包括支持向量機 (SVM)、神經網絡、樸素貝葉斯分類器、決策樹、判別分析和最近鄰 ( k NN)。
回歸:用于預測何時需要連續響應值。常見的回歸算法包括線性回歸、非線性回歸、廣義線性模型、決策樹和神經網絡。
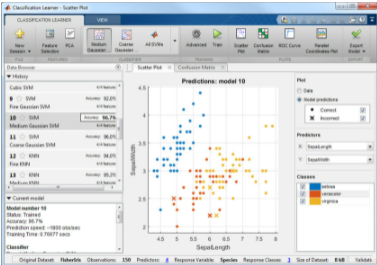
選擇算法取決于許多設計因素,例如內存使用情況、預測速度和模型的可解釋性。其他考慮因素包括是否需要單類或多類響應,以及預測變量是連續的還是分類的。由于模型僅與使用的標記訓練數據一樣好,因此在使用具有代表性的訓練數據集時要小心。機器學習工作流程從選擇特征開始,然后指定訓練和驗證集,使用多種算法進行訓練,最后評估結果。圖 2 所示的交互式應用程序使機器學習工作流程易于學習和使用。
無監督學習是一種機器學習,用于從由沒有標記響應的輸入數據組成的數據集中進行推斷。
聚類分析是最常見的無監督學習方法,用于探索性數據分析,以發現數據中的隱藏模式或分組。k-means 是一種流行的集群建模算法,它根據到集群質心的測量距離將數據劃分為 k 個不同的集群。
層次聚類使用了一種不同的方法來構建多層次的層次聚類樹,它提供了視覺解釋,但計算要求更高,因此不太適合大量數據。
其他算法包括高斯混合模型、隱馬爾可夫模型和自組織神經網絡圖。
BuildingIQ 團隊使用聚類分析作為其模型創建過程的一部分。他們使用 k-means 聚類和高斯混合模型來分割數據,并確定燃氣、電力、蒸汽和太陽能對加熱和冷卻過程的相對貢獻。
對于涉及圖像、文本和信號的分類問題,深度學習已成為一種新的高級分析類別。當在大型標記訓練數據集上進行訓練時(通常需要使用圖形處理單元 (GPU) 進行硬件加速以及強化訓練和評估),深度學習模型可以達到最先進的精度,有時在對象分類方面的表現甚至超過人類水平。對于圖像分類,卷積神經網絡 (CNN) 變得流行,因為它們通過直接從原始圖像中提取特征來消除手動特征提取的需要。這種自動特征提取使 CNN 模型對于諸如對象分類等計算機視覺任務具有高度的準確性。
系統工程師可以更容易地使用上面列出的方法和算法,以便在他們的嵌入式系統中結合有效的分析。在這個由三部分組成的系列的最后一篇文章中,我們將介紹實時執行分析和預測控制并將它們集成到一個整體解決方案中,包括傳感器和嵌入式系統以及企業 IT 系統和云基礎設施。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101046 -
gpu
+關注
關注
28文章
4768瀏覽量
129223 -
機器學習
+關注
關注
66文章
8438瀏覽量
132928
發布評論請先 登錄
相關推薦
哪些專業適合學習嵌入式開發?
嵌入式linux開發板怎么操作
嵌入式軟件開發與AI整合

專家力薦|《嵌入式系統原理與開發——基于RISC-V和Linux系統》新書發售

嵌入式開發前景怎么樣?

嵌入式系統怎么學?
嵌入式開發者的未來

再談嵌入式實時操作系統





 工商網監
工商網監
評論