") 計(jì)算機(jī)視覺(jué)的網(wǎng)絡(luò)結(jié)構(gòu)又要迎來(lái)革新了?
計(jì)算機(jī)視覺(jué)的網(wǎng)絡(luò)結(jié)構(gòu)又要迎來(lái)革新了?
【導(dǎo)讀】最近,中科院軟件所等四個(gè)機(jī)構(gòu)的研究團(tuán)隊(duì)將CV與圖神經(jīng)網(wǎng)絡(luò)結(jié)合起來(lái),提出全新模型ViG,在等量參數(shù)情況下,性能超越ViT,可解釋性也有所提升。
計(jì)算機(jī)視覺(jué)的網(wǎng)絡(luò)結(jié)構(gòu)又要迎來(lái)革新了?
從卷積神經(jīng)網(wǎng)絡(luò)到帶注意力機(jī)制的視覺(jué)Transformer,神經(jīng)網(wǎng)絡(luò)模型都是把輸入圖像視為一個(gè)網(wǎng)格或是patch序列,但這種方式無(wú)法捕捉到變化的或是復(fù)雜的物體。
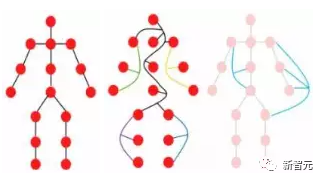
比如人在觀察圖片的時(shí)候,就會(huì)很自然地就將整個(gè)圖片分為多個(gè)物體,并在物體間建立空間等位置關(guān)系,也就是說(shuō)整張圖片對(duì)于人腦來(lái)說(shuō)實(shí)際上是一張graph,物體則是graph上的節(jié)點(diǎn)。
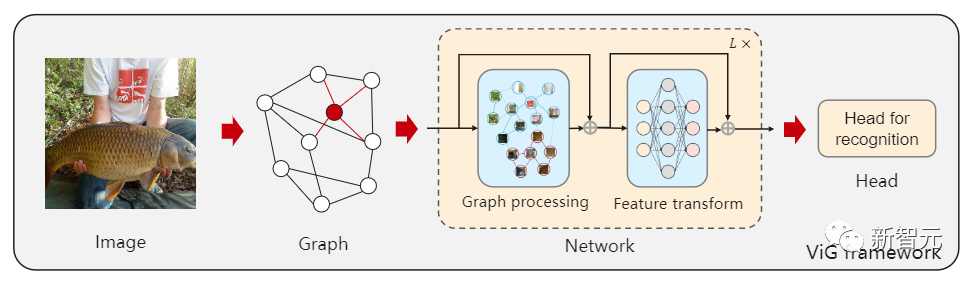
最近中科院軟件研究所、華為諾亞方舟實(shí)驗(yàn)室、北京大學(xué)、澳門大學(xué)的研究人員聯(lián)合提出了一個(gè)全新的模型架構(gòu)Vision GNN (ViG),能夠從圖像中抽取graph-level的特征用于視覺(jué)任務(wù)。

論文鏈接:https://arxiv.org/pdf/2206.00272.pdf
首先需要將圖像分割成若干個(gè)patch作為圖中的節(jié)點(diǎn),并通過(guò)連接最近的鄰居patch構(gòu)建一個(gè)graph,然后使用ViG模型對(duì)整個(gè)圖中所有節(jié)點(diǎn)的信息進(jìn)行變換(transform)和交換(exchange)。
ViG 由兩個(gè)基本模塊組成,Grapher模塊用graph卷積來(lái)聚合和更新圖形信息,F(xiàn)FN模塊用兩個(gè)線性層來(lái)變換節(jié)點(diǎn)特征。
在圖像識(shí)別和物體檢測(cè)任務(wù)上進(jìn)行的實(shí)驗(yàn)也證明了ViG架構(gòu)的優(yōu)越性,GNN在一般視覺(jué)任務(wù)上的開(kāi)創(chuàng)性研究將為未來(lái)的研究提供有益的啟發(fā)和經(jīng)驗(yàn)。
論文作者為吳恩華教授,中國(guó)科學(xué)院軟件研究所博士生導(dǎo)師、澳門大學(xué)名譽(yù)教授,1970年本科畢業(yè)于清華大學(xué)工程力學(xué)數(shù)學(xué)系,1980年博士畢業(yè)于英國(guó)曼徹斯特大學(xué)計(jì)算機(jī)科學(xué)系。主要研究領(lǐng)域?yàn)橛?jì)算機(jī)圖形學(xué)與虛擬現(xiàn)實(shí), 包括:虛擬現(xiàn)實(shí) 、真實(shí)感圖形生成、基于物理的仿真與實(shí)時(shí)計(jì)算、基于物理的建模與繪制、圖像與視頻的處理與建模、視覺(jué)計(jì)算與機(jī)器學(xué)習(xí)。
視覺(jué)GNN
網(wǎng)絡(luò)結(jié)構(gòu)往往是提升性能最關(guān)鍵的要素,只要能保證數(shù)據(jù)量的數(shù)量和質(zhì)量,把模型從CNN換到ViT,就能得到一個(gè)性能更佳的模型。
但不同的網(wǎng)絡(luò)對(duì)待輸入圖像的處理方式也不同,CNN在圖像上滑動(dòng)窗口,引入平移不變性和局部特征。
而ViT和多層感知機(jī)(MLP)則是將圖像轉(zhuǎn)換為一個(gè)patch序列,比如把224×224的圖像分成若干個(gè)16×16的patch,最后形成一個(gè)長(zhǎng)度為196的輸入序列。
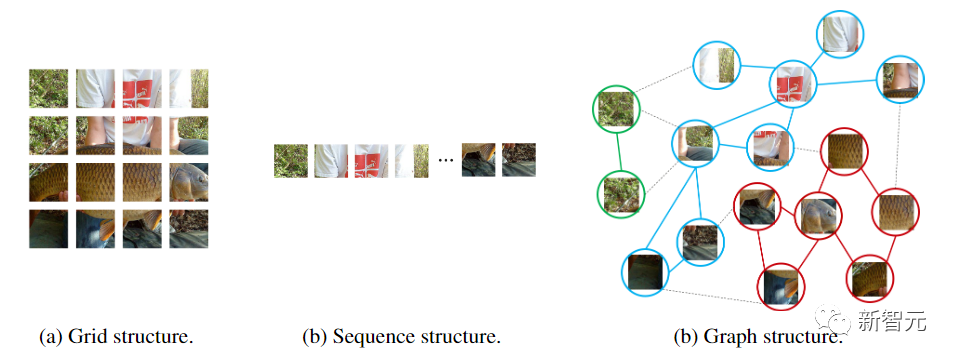
圖神經(jīng)網(wǎng)絡(luò)則更加靈活,比如在計(jì)算機(jī)視覺(jué)中,一個(gè)基本任務(wù)是識(shí)別圖像中的物體。由于物體通常不是四邊形的,可能是不規(guī)則的形狀,所以之前的網(wǎng)絡(luò)如ResNet和ViT中常用的網(wǎng)格或序列結(jié)構(gòu)是多余的,處理起來(lái)不靈活。
一個(gè)物體可以被看作是由多個(gè)部分組成的,例如,一個(gè)人可以大致分為頭部、上半身、胳膊和腿。
這些由關(guān)節(jié)連接的部分很自然地形成了一個(gè)圖形結(jié)構(gòu),通過(guò)分析圖,我們最后才能夠識(shí)別出這個(gè)物體可能是個(gè)人類。
此外,圖是一種通用的數(shù)據(jù)結(jié)構(gòu),網(wǎng)格和序列可以被看作是圖的一個(gè)特例。將圖像看作是一個(gè)圖,對(duì)于視覺(jué)感知來(lái)說(shuō)更加靈活和有效。
使用圖結(jié)構(gòu)需要將輸入的圖像劃分為若干個(gè)patch,并將每個(gè)patch視為一個(gè)節(jié)點(diǎn),如果將每個(gè)像素視為一個(gè)節(jié)點(diǎn)的話就會(huì)導(dǎo)致圖中節(jié)點(diǎn)數(shù)量過(guò)多(>10K)。
建立graph后,首先通過(guò)一個(gè)圖卷積神經(jīng)網(wǎng)絡(luò)(GCN)聚合相鄰節(jié)點(diǎn)間的特征,并抽取圖像的表征。
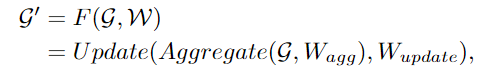
為了讓GCN獲取更多樣性的特征,作者將圖卷積應(yīng)用multi-head操作,聚合的特征由不同權(quán)重的head進(jìn)行更新,最后級(jí)聯(lián)為圖像表征。
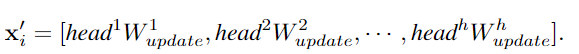
以前的GCN通常重復(fù)使用幾個(gè)圖卷積層來(lái)提取圖數(shù)據(jù)的聚合特征,而深度GCN中的過(guò)度平滑現(xiàn)象則會(huì)降低節(jié)點(diǎn)特征的獨(dú)特性,導(dǎo)致視覺(jué)識(shí)別的性能下降。
為了緩解這個(gè)問(wèn)題,研究人員在ViG塊中引入了更多的特征轉(zhuǎn)換和非線性激活函數(shù)。
首先在圖卷積的前后應(yīng)用一個(gè)線性層,將節(jié)點(diǎn)特征投射到同一域中,增加特征多樣性。在圖形卷積之后插入一個(gè)非線性激活函數(shù)以避免層崩潰。
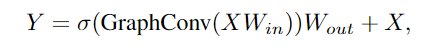
為了進(jìn)一步提高特征轉(zhuǎn)換能力,緩解過(guò)度平滑現(xiàn)象,還需要在每個(gè)節(jié)點(diǎn)上利用前饋網(wǎng)絡(luò)(FFN)。FFN模塊是一個(gè)簡(jiǎn)單的多層感知機(jī),有兩個(gè)全連接的層。
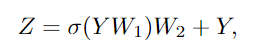
在Grapher和FFN模塊中,每一個(gè)全連接層或圖卷積層之后都要進(jìn)行batch normalization,Grapher模塊和FFN模塊的堆疊構(gòu)成了一個(gè)ViG塊,也是構(gòu)建大網(wǎng)絡(luò)的基本單元。
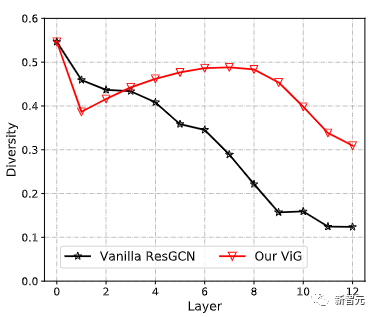
與原始的ResGCN相比,新提出的ViG可以保持特征的多樣性,隨著加入更多的層,網(wǎng)絡(luò)也可以學(xué)習(xí)到更強(qiáng)的表征。
在計(jì)算機(jī)視覺(jué)的網(wǎng)絡(luò)架構(gòu)中,常用的Transformer模型通常有一個(gè)等向性(Isotropic)的結(jié)構(gòu)(如ViT),而CNN更傾向于使用金字塔結(jié)構(gòu)(如ResNet)。
為了與其他類型的神經(jīng)網(wǎng)絡(luò)進(jìn)行比較,研究人員為ViG同時(shí)建立了等向性和金字塔的兩種網(wǎng)絡(luò)架構(gòu)。
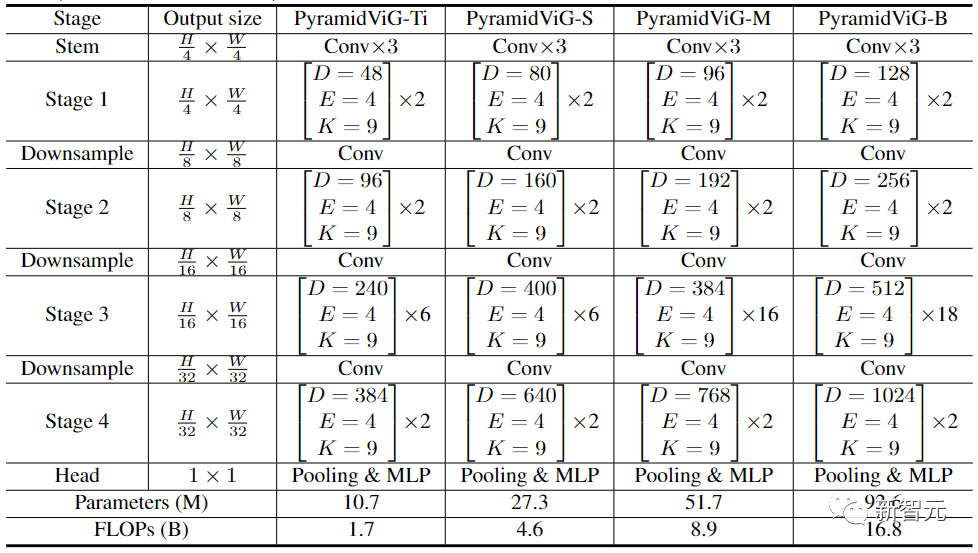
在實(shí)驗(yàn)對(duì)比階段,研究人員選擇了圖像分類任務(wù)中的ImageNet ILSVRC 2012數(shù)據(jù)集,包含1000個(gè)類別,120M的訓(xùn)練圖像和50K的驗(yàn)證圖像。
目標(biāo)檢測(cè)任務(wù)中,選擇了有80個(gè)目標(biāo)類別的COCO 2017數(shù)據(jù)集,包含118k個(gè)訓(xùn)練圖片和5000個(gè)驗(yàn)證集圖片。

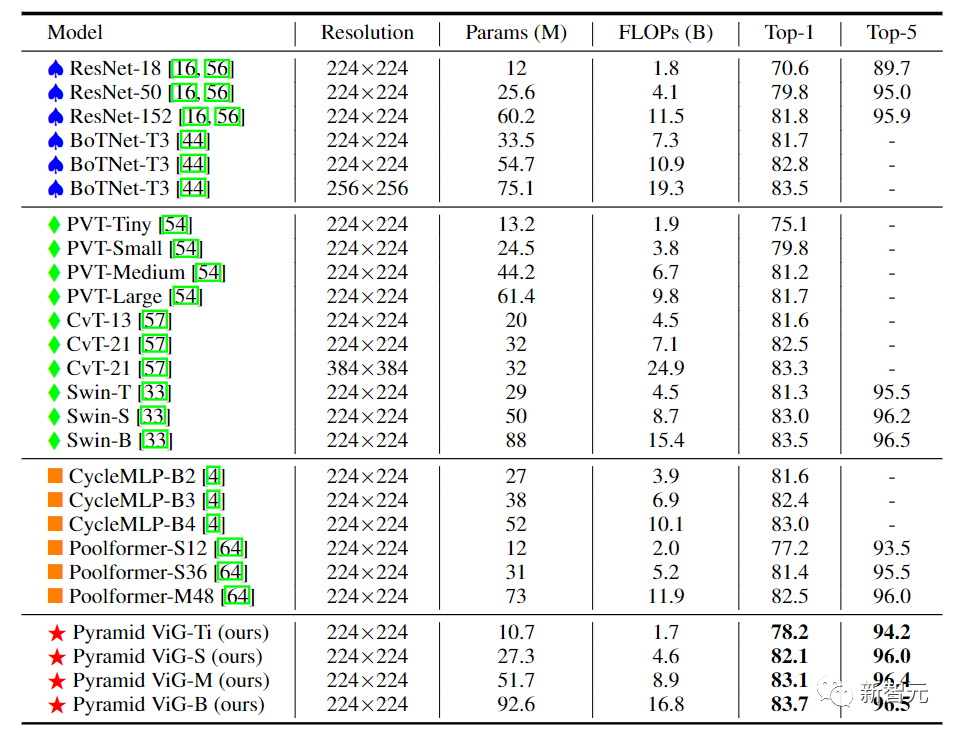
在等向性的ViG架構(gòu)中,其主要計(jì)算過(guò)程中可以保持特征大小不變,易于擴(kuò)展,對(duì)硬件加速友好。在將其與現(xiàn)有的等向性的CNN、Transformer和MLP進(jìn)行比較后可以看到,ViG比其他類型的網(wǎng)絡(luò)表現(xiàn)得更好。其中ViG-Ti實(shí)現(xiàn)了73.9%的top-1準(zhǔn)確率,比DeiT-Ti模型高1.7%,而計(jì)算成本相似。
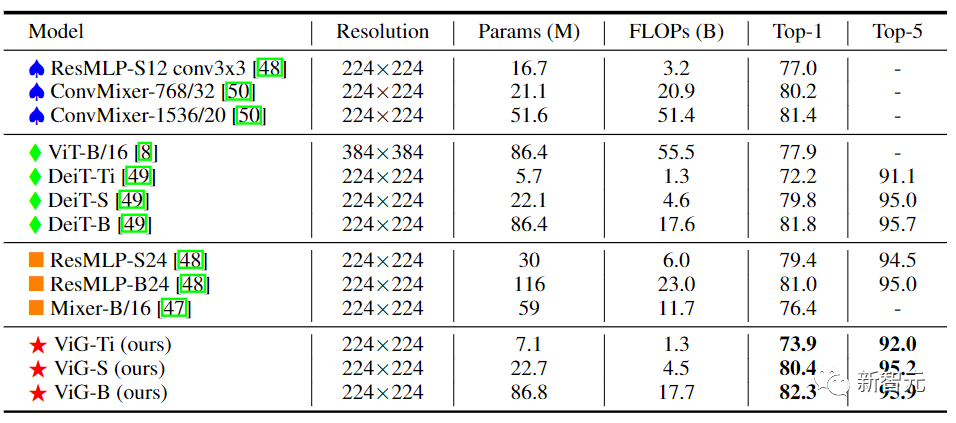
金字塔結(jié)構(gòu)的ViG中,隨著網(wǎng)絡(luò)的加深逐漸縮小了特征圖的空間大小,利用圖像的尺度不變量特性,同時(shí)產(chǎn)生多尺度的特征。
高性能的網(wǎng)絡(luò)大多采用金字塔結(jié)構(gòu),如ResNet、Swin Transformer和CycleMLP。在將Pyramid ViG與這些有代表性的金字塔網(wǎng)絡(luò)進(jìn)行比較后,可以看到Pyramid ViG系列可以超越或媲美最先進(jìn)的金字塔網(wǎng)絡(luò)包括CNN、MLP和Transfomer。
結(jié)果表明,圖神經(jīng)網(wǎng)絡(luò)可以很好地完成視覺(jué)任務(wù),并有可能成為計(jì)算機(jī)視覺(jué)系統(tǒng)中的一個(gè)基本組成部分。
為了更好地理解ViG模型的工作流程,研究人員將ViG-S中構(gòu)建的圖結(jié)構(gòu)可視化。在兩個(gè)不同深度的樣本(第1和第12塊)的圖。五角星是中心節(jié)點(diǎn),具有相同顏色的節(jié)點(diǎn)是其鄰居。只有兩個(gè)中心節(jié)點(diǎn)是可視化的,因?yàn)槿绻L制所有的邊會(huì)顯得很亂。

可以觀察到,ViG模型可以選擇與內(nèi)容相關(guān)的節(jié)點(diǎn)作為第一階鄰居。在淺層,鄰居節(jié)點(diǎn)往往是根據(jù)低層次和局部特征來(lái)選擇的,如顏色和紋理。在深層,中心節(jié)點(diǎn)的鄰居更具語(yǔ)義性,屬于同一類別。 ViG網(wǎng)絡(luò)可以通過(guò)其內(nèi)容和語(yǔ)義表征逐漸將節(jié)點(diǎn)聯(lián)系起來(lái),幫助更好地識(shí)別物體。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101063 -
模型
+關(guān)注
關(guān)注
1文章
3298瀏覽量
49091 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46085
原文標(biāo)題:CV的未來(lái)是圖神經(jīng)網(wǎng)絡(luò)?中科院軟件所發(fā)布全新CV模型ViG,性能超越ViT
文章出處:【微信號(hào):CVSCHOOL,微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
計(jì)算機(jī)視覺(jué)有哪些優(yōu)缺點(diǎn)
計(jì)算機(jī)視覺(jué)技術(shù)的AI算法模型
機(jī)器視覺(jué)和計(jì)算機(jī)視覺(jué)有什么區(qū)別
計(jì)算機(jī)視覺(jué)的五大技術(shù)
計(jì)算機(jī)視覺(jué)的工作原理和應(yīng)用
計(jì)算機(jī)視覺(jué)與人工智能的關(guān)系是什么
計(jì)算機(jī)視覺(jué)與智能感知是干嘛的
計(jì)算機(jī)視覺(jué)和機(jī)器視覺(jué)區(qū)別在哪
計(jì)算機(jī)視覺(jué)和圖像處理的區(qū)別和聯(lián)系
計(jì)算機(jī)視覺(jué)屬于人工智能嗎
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的應(yīng)用
機(jī)器視覺(jué)與計(jì)算機(jī)視覺(jué)的區(qū)別
計(jì)算機(jī)視覺(jué)的主要研究方向
計(jì)算機(jī)視覺(jué)的十大算法

什么是計(jì)算機(jī)網(wǎng)絡(luò)的拓?fù)?b class='flag-5'>結(jié)構(gòu)?主要的拓?fù)?b class='flag-5'>結(jié)構(gòu)有哪些?
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論