 一文詳解C++中的移動語義
一文詳解C++中的移動語義
一直以來,C++中基于值語義的拷貝和賦值嚴重影響了程序性能。尤其是對于資源密集型對象,如果進行大量的拷貝,勢必會對程序性能造成很大的影響。
為了盡可能的減小因為對象拷貝對程序的影響,開發人員使出了萬般招式:盡可能的使用指針、引用。而編譯器也沒閑著,通過使用RVO、NRVO以及復制省略技術,來減小拷貝次數來提升代碼的運行效率。
但是,對于開發人員來說,使用指針和引用不能概括所有的場景,也就是說仍然存在拷貝賦值等行為;對于編譯器來說,而對于RVO、NRVO等編譯器行為的優化需要滿足特定的條件(具體可以參考文章編譯器之返回值優化)。
為了解決上述問題,自C++11起,引入了移動語義,更進一步對程序性能進行優化 。
C++11新標準重新定義了lvalue和rvalue,并允許函數依照這兩種不同的類型進行重載。通過對于右值(rvalue)的重新定義,語言實現了移動語義(move semantics)和完美轉發(perfect forwarding),通過這種方法,C++實現了在保留原有的語法并不改動已存在的代碼的基礎上提升代碼性能的目的。
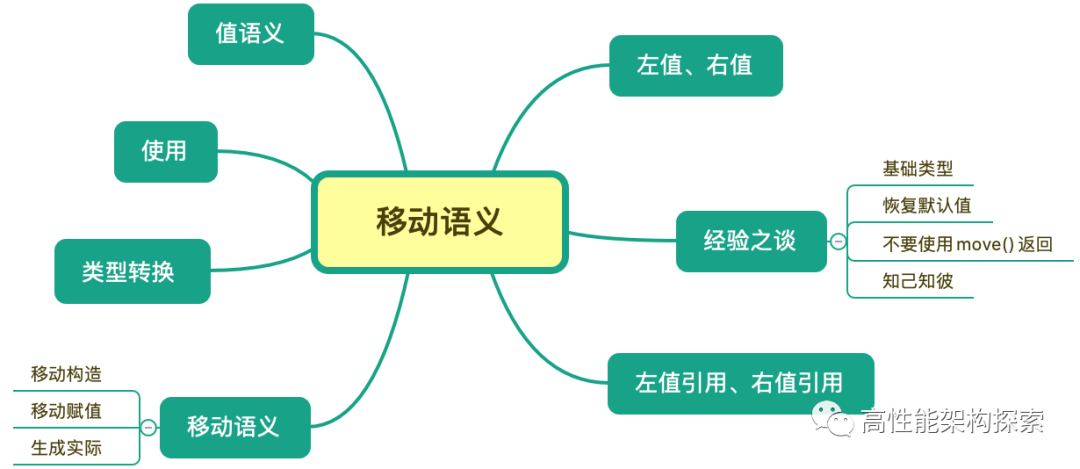
本文的主要內容如下圖所示:
值語義
值語義(value semantics)指目標對象由源對象拷貝生成,且生成后與源對象完全無關,彼此獨立存在,改變互不影響,就像int類型互相拷貝一樣。C++的內置類型(bool/int/double/char)都是值語義,標準庫里的complex<> 、pair<>、vector<>、map<>、string等等類型也都是值語意,拷貝之后就與原對象脫離關系。
C++中基于值語義的拷貝構造和賦值拷貝,會招致對資源密集型對象不必要拷貝,大量的拷貝很可能成為程序的性能瓶頸。
首先,我們看一段例子:
BigObjfun(BigObjobj){
BigObjo;
//dosth
returno;
}
intmain(){
fun(BigObj());
return0;
}
在上述代碼中,我們定義了一個函數fun()其參數是一個BigObj對象,當調用fun()函數時候,會通過調用BigObj的拷貝構造函數,將obj變量傳遞給fun()的參數。
編譯器知道何時調用拷貝構造函數或者賦值運算符進行值傳遞。如果涉及到底層資源,比如內存、socket等,開發人在定義類的時候,需要實現自己的拷貝構造和賦值運算符以實現深拷貝。然而拷貝的代價很大,當我們使用STL容器的時候,都會涉及到大量的拷貝操作,而這些會浪費CPU和內存等資源。
正如上述代碼中所示的那樣,當我們將一個臨時變量(BigObj(),也稱為右值)傳遞給一個函數的時候,就會導致拷貝操作,那么我們該如何避免此種拷貝行為呢?這就是我們本文的主題:移動語義。
左值、右值
關于左值、右值,我們在之前的文章中已經有過詳細的分享,有興趣的同學可以移步【Modern C++】深入理解左值、右值,在本節,我們簡單介紹下左值和右值的概念,以方便理解下面的內容。
左值(lvalue,left value),顧名思義就是賦值符號左邊的值。準確來說,左值是表達式結束(不一定是賦值表達式)后依然存在的對象。
可以將左值看作是一個關聯了名稱的內存位置,允許程序的其他部分來訪問它。在這里,我們將 "名稱" 解釋為任何可用于訪問內存位置的表達式。所以,如果 arr 是一個數組,那么 arr[1] 和 *(arr+1) 都將被視為相同內存位置的“名稱”。
左值具有以下特征:
- 可通過取地址運算符獲取其地址
- 可修改的左值可用作內建賦值和內建符合賦值運算符的左操作數
- 可以用來初始化左值引用(后面有講)
C++11將右值分為純右值和將亡值兩種。純右值就是C++98標準中右值的概念,如非引用返回的函數返回的臨時變量值;一些運算表達式,如1+2產生的臨時變量;不跟對象關聯的字面量值,如2,'c',true,"hello";這些值都不能夠被取地址。
而將亡值則是C++11新增的和右值引用相關的表達式,這樣的表達式通常是將要移動的對象、T&&函數返回值、std::move()函數的返回值等。
左值引用、右值引用
在明確了左值和右值的概念之后,我們將在本節簡單介紹下左值引用和右值引用。
按照概念,對左值的引用稱為左值引用,而對右值的引用稱為右值引用。既然有了左值引用和右值引用,那么在C++11之前,我們通常所說的引用又是什么呢?其實就是左值引用,比如:
inta=1;
int&b=a;
在C++11之前,我們通過會說b是對a的一個引用(當然,在C++11及以后也可以這么說,大家潛移默化的認識就是引用==左值引用),但是在C++11中,更為精確的說法是b是一個左值引用。
在C++11中,為了區分左值引用,右值引用用&&來表示,如下:
int&&a=1;//a是一個左值引用
intb=1;
int&&c=b;//錯誤,右值引用不能綁定左值
跟左值引用一樣,右值引用不會發生拷貝,并且右值引用等號右邊必須是右值,如果是左值則會編譯出錯,當然這里也可以進行強制轉換,這將在后面提到。
在這里,有一個大家都經常容易犯的一個錯誤,就是綁定右值的右值引用,其變量本身是個左值。為了便于理解,代碼如下:
intfun(int&a){
std::cout<"infun(int&)"<std::endl;
}
intfun(int&&a){
std::cout<"infun(int&)"<std::endl;
}
intmain(){
inta=1;
int&&b=1;
fun(b);
return0;
}
代碼輸出如下:
infun(int&)
左值引用和右值引用的規則如下:
- 左值引用,使用T&,只能綁定左值
- 右值引用,使用T&&,只能綁定右值
- 常量左值,使用const T&,既可以綁定左值,又可以綁定右值,但是不能對其進行修改
- 具名右值引用,編譯器會認為是個左值
- 編譯器的優化需要滿足特定條件,不能過度依賴
好了,截止到目前,相信你對左值引用和右值引用的概念有了初步的認識,那么,現在我們介紹下為什么要有右值引用呢?我們看下述代碼:
BigObjfun(){
returnBigObj();
}
BigObjobj=fun();//C++11以前
BigObj&&obj=fun();//C++11
上述代碼中,在C++11之前,我們只能通過編譯器優化(N)RVO的方式來提升性能,如果不滿足編譯器的優化條件,則只能通過拷貝等方式進行操作。自C++11引入右值引用后,對于不滿足(N)RVO條件,也可以通過避免拷貝延長臨時變量的生命周期,進而達到優化的目的。
但是僅僅使用右值引用還不足以完全達到優化目的,畢竟右值引用只能綁定右值。那么,對于左值,我們又該如何優化呢?是否可以通過左值轉成右值,然后進行優化呢?等等
為了解決上述問題,標準引入了移動語義。通移動語義,可以在必要的時候避免拷貝;標準提供了move()函數,可以將左值轉換成右值。接下來,就開始我們本文的重點-移動語義。
移動語義
移動語義是Howard Hinnant在2002年向C++標準委員會提議的,引用其在移動語義提案上的一句話:
移動語義不是試圖取代復制語義,也不是以任何方式破壞它。相反,該提議旨在增強復制語義
對于剛剛接觸移動語義的開發人員來說,很難理解為什么有了值語義還需要有移動語義。
我們可以想象一下,有一輛汽車,在內置發動機的情況下運行平穩,有一天,在這輛車上安裝了一個額外的V8發動機。當有足夠燃料的時候,V8發動機就能進行加速。所以,汽車是值語義,而V8引擎則是移動語義。在車上安裝引擎不需要一輛新車,它仍然是同一輛車,就像移動語義不會放棄值語義一樣。
所以,如果可以,使用移動語義,否則使用值語義,換句話說就是,如果燃料充足,則使用V8引擎,否則使用原始默認引擎。
好了,截止到現在,我們對移動語義有一個感官上的認識,它屬于一種優化,或者說屬于錦上添花。再次引用Howard Hinnant在移動語義提案上的一句話:
移動語義主要是性能優化:將昂貴的對象從內存中的一個地址移動到另外一個地址的能力,同時竊取源資源以便以最小的代價構建目標
在C++11之前,當進行值傳遞時,編譯器會隱式調用拷貝構造函數;自C++11起,通過右值引用來避免由于拷貝調用而導致的性能損失。
右值引用的主要用途是創建移動構造函數和移動賦值運算符。移動構造函數和拷貝構造函數一樣,將對象的實例作為其參數,并從原始對象創建一個新的實例。
但是,移動構造函數可以避免內存重新分配,這是因為移動構造函數的參數是一個右值引用,也可以說是一個臨時對象,而臨時對象在調用之后就被銷毀不再被使用,因此,在移動構造函數中對參數進行移動而不是拷貝。換句話說,右值引用和移動語義允許我們在使用臨時對象時避免不必要的拷貝。
移動語義通過移動構造函數和移動賦值操作符實現,其與拷貝構造函數類似,區別如下:
- 參數的符號必須為右值引用符號,即為&&
- 參數不可以是常量,因為函數內需要修改參數的值
- 參數的成員轉移后需要修改(如改為nullptr),避免臨時對象的析構函數將資源釋放掉
為了方便我們理解,下面代碼包含了完整的移動構造和移動運算符,如下:
classBigObj{
public:
explicitBigObj(size_tlength)
:length_(length),data_(newint[length]){
}
//Destructor.
~BigObj(){
if(data_!=NULL){
delete[]data_;
length_=0;
}
}
//拷貝構造函數
BigObj(constBigObj&other)
:length_(other.length_),data(newint[other.length_]){
std::copy(other.mData,other.mData+mLength,mData);
}
//賦值運算符
BigObj&operator=(constBigObj&other){
if(this!=&other;){
delete[]data_;
length_=other.length_;
data_=newint[length_];
std::copy(other.data_,other.data_+length_,data_);
}
return*this;
}
//移動構造函數
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
other.data_=nullptr;
other.length_=0;
}
//移動賦值運算符
BigObj&operator=(BigObj&&other){
if(this!=&other;){
delete[]data_;
data_=other.data_;
length_=other.length_;
other.data_=NULL;
other.length_=0;
}
return*this;
}
private:
size_tlength_;
int*data_;
};
intmain(){
std::vectorv;
v.push_back(BigObj(25));
v.push_back(BigObj(75));
v.insert(v.begin()+1,BigObj(50));
return0;
}
移動構造
移動構造函數的定義如下:
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
other.data_=nullptr;
other.length_=0;
}
從上述代碼可以看出,它不分配任何新資源,也不會復制其它資源:other中的內存被移動到新成員后,other中原有的內容則消失了。換句話說,它竊取了other的資源,然后將other設置為其默認構造的狀態。
在移動構造函數中,最最關鍵的一點是,它沒有額外的資源分配,僅僅是將其它對象的資源進行了移動,占為己用。
在此,我們假設data_很大,包含了數百萬個元素。如果使用原來拷貝構造函數的話,就需要將該數百萬元素挨個進行復制,性能可想而知。而如果使用該移動構造函數,因為不涉及到新資源的創建,不僅可以節省很多資源,而且性能也有很大的提升。
移動賦值運算符
代碼如下:
BigObj&operator=(constBigObj&other){
if(this!=&other;){
delete[]data_;
length_=other.length_;
data_=newint[length_];
std::copy(other.data_,other.data_+length_,data_);
}
return*this;
}
移動賦值運算符的寫法類似于拷貝賦值運算符,所不同點在于:移動賦值預算法會破壞被操作的對象(上述代碼中的參數other)。
移動賦值運算符的操作步驟如下:
- 釋放當前擁有的資源
- 竊取他人資源
- 將他人資源設置為默認狀態
- 返回*this
在定義移動賦值運算符的時候,需要進行判斷,即被移動的對象是否跟目標對象一致,如果一致,則會出問題,如下代碼:
data=std::move(data);
在上述代碼中,源和目標是同一個對象,這可能會導致一個嚴重的問題:它最終可能會釋放它試圖移動的資源。為了避免此問題,我們需要通過判斷來進行,比如可以如下操作:
if(this==&other){
return*this
}
生成時機
眾所周知,在C++中有四個特殊的成員函數:默認構造函數、析構函數,拷貝構造函數,拷貝賦值運算符。
之所以稱之為特殊的成員函數,這是因為如何開發人員沒有定義這四個成員函數,那么編譯器則在滿足某些特定條件(僅在需要的時候才生成,比如某個代碼使用它們但是它們沒有在類中明確聲明)下,自動生成。這些由編譯器生成的特殊成員函數是public且inline。
自C++11起,引入了另外兩只特殊的成員函數:移動構造函數和移動賦值運算符。如果開發人員沒有顯示定義移動構造函數和移動賦值運算符,那么編譯器也會生成默認。
與其他四個特殊成員函數不同,編譯器生成默認的移動構造函數和移動賦值運算符需要,滿足以下條件:
- 如果一個類定義了自己的拷貝構造函數,拷貝賦值運算符或者析構函數(這三者之一,表示程序員要自己處理對象的復制或釋放問題),編譯器就不會為它生成默認的移動構造函數或者移動賦值運算符,這樣做的目的是防止編譯器生成的默認移動構造函數或者移動賦值運算符不是開發人員想要的
- 如果類中沒有提供移動構造函數和移動賦值運算符,且編譯器不會生成默認的,那么我們在代碼中通過std::move()調用的移動構造或者移動賦值的行為將被轉換為調用拷貝構造或者賦值運算符
- 只有一個類沒有顯示定義拷貝構造函數、賦值運算符以及析構函數,且類的每個非靜態成員都可以移動時,編譯器才會生成默認的移動構造函數或者移動賦值運算符
- 如果顯式聲明了移動構造函數或移動賦值運算符,則拷貝構造函數和拷貝賦值運算符將被隱式刪除(因此程開發人員必須在需要時實現拷貝構造函數和拷貝賦值運算符)
與拷貝操作一樣,如果開發人員定義了移動操作,那么編譯器就不會生成默認的移動操作,但是編譯器生成移動操作的行為和生成拷貝操作的行為有些許不同,如下:
-
兩個拷貝操作是獨立的:聲明一個不會限制編譯器生成另一個。所以如果你聲明一個拷貝構造函數,但是沒有聲明拷貝賦值運算符,如果寫的代碼用到了拷貝賦值,編譯器會幫助你生成拷貝賦值運算符。
同樣的,如果你聲明拷貝賦值運算符但是沒有拷貝構造函數,代碼用到拷貝構造函數時編譯器就會生成它。上述規則在C++98和C++11中都成立。
-
兩個移動操作不是相互獨立的。如果你聲明了其中一個,編譯器就不再生成另一個。如果你給類聲明了,比如,一個移動構造函數,就表明對于移動操作應怎樣實現,與編譯器應生成的默認逐成員移動有些區別。
如果逐成員移動構造有些問題,那么逐成員移動賦值同樣也可能有問題。所以聲明移動構造函數阻止編譯器生成移動賦值運算符,聲明移動賦值運算符同樣阻止編譯器生成移動構造函數。
類型轉換-move()函數
在前面的文章中,我們提到,如果需要調用移動構造函數和移動賦值運算符,就需要用到右值。那么,對于一個左值,又如何使用移動語義呢?自C++11起,標準庫提供了一個函數move()用于將左值轉換成右值。
首先,我們看下cppreference中對move語義的定義:
std::move is used to indicate that an object t may be "moved from", i.e. allowing the efficient transfer of resources from t to another object.
In particular, std::move produces an xvalue expression that identifies its argument t. It is exactly equivalent to a static_cast to an rvalue reference type.
從上述描述,我們可以理解為std::move()并沒有移動任何東西,它只是進行類型轉換而已,真正進行資源轉移的是開發人員實現的移動操作。
該函數在STL中定義如下:
template<typename_Tp>
constexprtypenamestd::remove_reference<_Tp>::type&&
move(_Tp&&__t)noexcept
{returnstatic_cast<typenamestd::remove_reference<_Tp>::type&&>(__t);}
從上面定義可以看出,std::move()并不是什么黑魔法,而只是進行了簡單的類型轉換:
- 如果傳遞的是左值,則推導為左值引用,然后由static_cast轉換為右值引用
- 如果傳遞的是右值,則推導為右值引用,然后static_cast轉換為右值引用
使用move之后,就意味著兩點:
- 原對象不再被使用,如果對其使用會造成不可預知的后果
- 所有權轉移,資源的所有權被轉移給新的對象
使用
在某些情況下,編譯器會嘗試隱式移動,這意味著您不必使用std::move()。只有當一個非常量的可移動對象被傳遞、返回或賦值,并且即將被自動銷毀時,才會發生這種情況。
自c++11起,開始支持右值引用。標準庫中很多容器都支持移動語義,以std::vector<>為例,**vector::push_back()**定義了兩個重載版本,一個像以前一樣將const T&用于左值參數,另一個將T&&類型的參數用于右值參數。如下代碼:
intmain(){
std::vectorv;
v.push_back(BigObj(10));
v.push_back(BigObj(20));
return0;
}
兩個push_back()調用都將解析為push_back(T&&),因為它們的參數是右值。push_back(T&&)使用BigObj的移動構造函數將資源從參數移動到vector的內部BigObj對象中。而在C++11之前,上述代碼則生成參數的拷貝,然后調用BigObj的拷貝構造函數。
如果參數是左值,則將調用push_back(T&):
intmain(){
std::vectorv;
BigObjobj(10);
v.push_back(obj);//此處調用push_back(T&)
return0;
}
對于左值對象,如果我們想要避免拷貝操作,則可以使用標準庫提供的move()函數來實現(前提是類定義中實現了移動語義),代碼如下:
intmain(){
std::vectorv;
BigObjobj(10);
v.push_back(std::move(obj));//此處調用push_back(T&&)
return0;
}
我們再看一個常用的函數swap(),在使用移動構造之前,我們定義如下:
template
voidswap(T&a,T&b) {
Ttemp=a;//調用拷貝構造函數
a=b;//調用operator=
b=temp;//調用operator=
}
如果T是簡單類型,則上述轉換沒有問題。但如果T是含有指針的復合數據類型,則上述轉換中會調用一次復制構造函數,兩次賦值運算符重載。
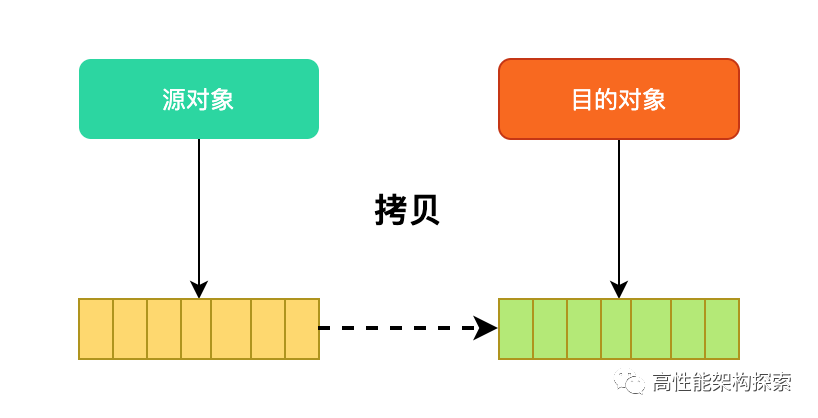
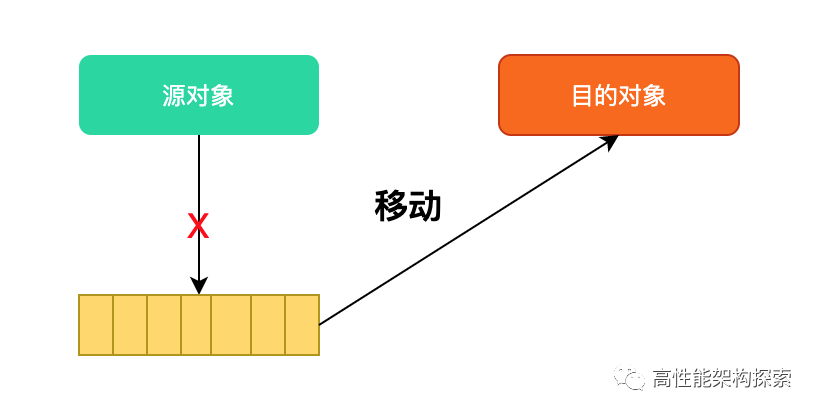
而如果使用move()函數后,則代碼如下:
template
voidswap(T&a,T&b) {
Ttemp=std::move(a);
a=std::move(b);
b=std::move(temp);
}
與傳統的swap實現相比,使用move()函數的swap()版本減少了拷貝等操作。如果T是可移動的,那么整個操作將非常高效。如果它是不可移動的,那么它和普通的swap函數一樣,調用拷貝和賦值操作,不會出錯,且是安全可靠的。
經驗之談
對int等基礎類型進行move()操作,不會改變其原值
對于所有的基礎類型-int、double、指針以及其它類型,它們本身不支持移動操作(也可以說本身沒有實現移動語義,畢竟不屬于我們通常理解的對象嘛),所以,對于這些基礎類型進行move()操作,最終還是會調用拷貝行為,代碼如下:
intmain()
{
inta=1;
int&&b=std::move(a);
std::cout<"a="<std::endl;
std::cout<"b="<std::endl;
return0;
}
最終結果輸出如下:
a=1
b=1
move構造或者賦值函數中,請將原對象恢復默認值
我們看如下代碼:
classBigObj{
public:
explicitBigObj(size_tlength)
:length_(length),data_(newint[length]){
}
//Destructor.
~BigObj(){
if(data_!=NULL){
delete[]data_;
length_=0;
}
}
//拷貝構造函數
BigObj(constBigObj&other)=default;
//賦值運算符
BigObj&operator=(constBigObj&other)=default;
//移動構造函數
BigObj(BigObj&&other):data_(nullptr),length_(0){
data_=other.data_;
length_=other.length_;
}
private:
size_tlength_;
int*data_;
};
intmain(){
BigObjobj(1000);
BigObjo;
{
o=std::move(obj);
}
//useobj;
return0;
}
在上述代碼中,調用移動構造函數后,沒有將原對象回復默認值,導致目標對象和原對象的底層資源(data_)執行同一個內存塊,這樣就導致退出main()函數的時候,原對象和目標對象均調用析構函數釋放同一個內存塊,進而導致程序崩潰。
不要在函數中使用std::move()進行返回
我們仍然以Obj進行舉例,代碼如下:
Objfun(){
Objobj;
returnstd::move(obj);
}
intmain(){
Objo1=fun();
return0;
}
程序輸出:
inObj()0x7ffe600d79e0
inObj(constObj&&obj)
in~Obj()0x7ffe600d79e0
如果把fun()函數中的std::move(obj)換成return obj,則輸出如下:
inObj()0x7ffcfefaa750
通過上述示例的輸出,是不是有點超出我們的預期。從輸出可以看出來,第二種方式(直接return obj)比第一種方式少了一次move構造和析構。這是因為編譯器做了NRVO優化。
所以,我們需要切記:如果編譯器能夠對某個函數做(N)RVO優化,就使用(N)RVO,而不是自作聰明使用std::move()。
知己知彼
STL中大部分已經實現移動語義,比如std::vector<>,std::map<>等,同時std::unique_ptr<>等不能被拷貝的類也支持移動語義。
我們看下如下代碼:
classBigObj
{
public:
BigObj(){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
~BigObj(){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
BigObj(constBigObj&b){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
BigObj(BigObj&&b){
std::cout<<__PRETTY_FUNCTION__<<std::endl;
}
};
intmain(){
std::arrayv;
autov1=std::move(v);
return0;
}
上述代碼輸出如下:
BigObj::BigObj()
BigObj::BigObj()
BigObj::BigObj(BigObj&&)
BigObj::BigObj(BigObj&&)
BigObj::~BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
而如果把main()函數中的std::array<>換成std::vector<>后,如下:
intmain(){
std::vectorv;
v.resize(2);
autov1=std::move(v);
return0;
}
則輸出如下:
BigObj::BigObj()
BigObj::BigObj()
BigObj::~BigObj()
BigObj::~BigObj()
從上述兩處輸出可以看出,std::vector<>對應的移動構造不會生成多余的構造,且原本的element都移動到v1中;而相比std::array<>中對應的移動構造卻有很大的區別,基本上會對每個element都調用移動構造函數而不是對std::array<>本身。
因此,在使用std::move()的時候,最好要知道底層的基本實現原理,否則往往會得到我們意想不到的結果。
原文標題:【Modern C++】深入理解移動語義
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
-
C++
+關注
關注
22文章
2114瀏覽量
73795 -
代碼
+關注
關注
30文章
4823瀏覽量
68904 -
語義
+關注
關注
0文章
21瀏覽量
8675
原文標題:【Modern C++】深入理解移動語義
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解Linux C++內存管理
一文初識C++







 工商網監
工商網監
評論