") 一鍵的TensorRT加速方式,極大的提升了部署的效率
一鍵的TensorRT加速方式,極大的提升了部署的效率
在深度學(xué)習(xí)產(chǎn)業(yè)落地過程中,我們經(jīng)常能聽到一種說法——模型部署是打通AI應(yīng)用的最后一公里!想要走通這一公里,看似簡單,但是真正實踐起來卻困難重重:顯卡利用率低、內(nèi)存溢出、多線程調(diào)度奔潰、TensorRT加速算子不支持等等問題一直是深度學(xué)習(xí)模型最后部署的老大難問題。
在工業(yè)制造環(huán)境中,Windows系統(tǒng)有著廣泛的應(yīng)用。為了更好的幫助工業(yè)用戶解決落地最后的一公里問題,飛槳聯(lián)合產(chǎn)業(yè)用戶,基于Windows系統(tǒng),提供了工業(yè)級的部署Demo,支持圖像分類、目標(biāo)檢測、實例分割和語義分割模型的部署,并提供了一鍵的TensorRT加速方式,極大的提升了部署的效率,同時支持多線程推理的方式,滿足了用戶多視頻輸入預(yù)測的需求!
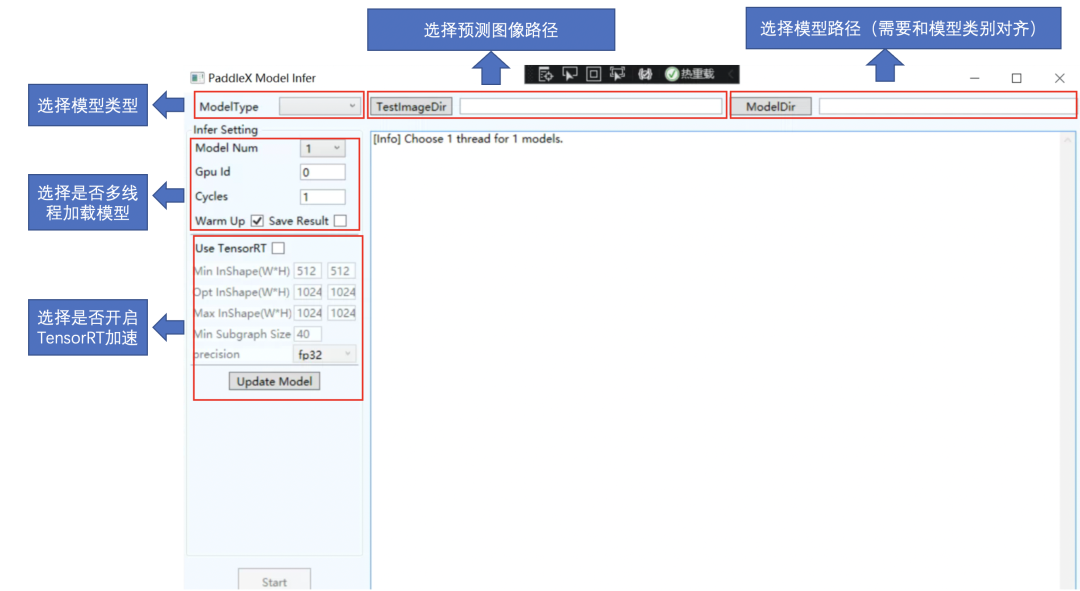
圖1部署開發(fā)示例說明
部署Demo地址,歡迎大家star收藏。
https://github.com/PaddlePaddle/PaddleX/tree/develop/deploy/cpp/docs/csharp_deploy

支持多種類別模型部署
滿足多種場景需求
為了更好的滿足用戶多種視覺任務(wù)場景,部署Demo基于PaddleX的Deployment模塊進行二次開發(fā),不僅僅支持對PaddleX自身訓(xùn)練的模型進行推理,同時支持PaddleClas、PaddleDetection、PaddleSeg視覺開發(fā)套件的模型,滿足多種場景需求。
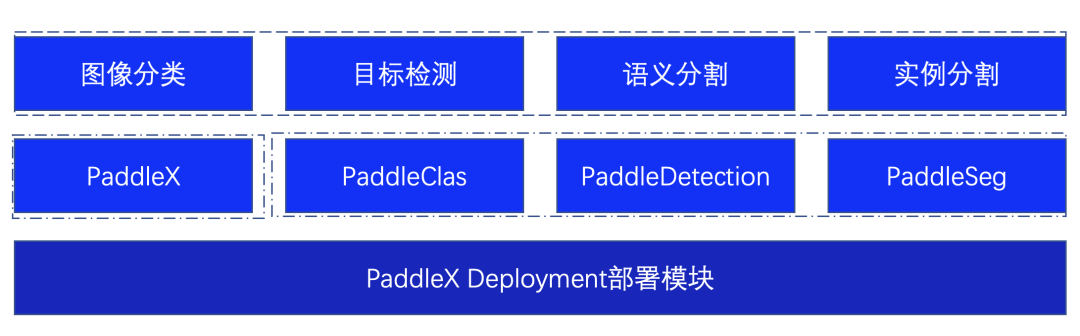
圖2 部署Demo支持模型說明
一鍵TensorRT加速
部署效率顯著提升
NVIDIA TensorRT 是一個高性能的深度學(xué)習(xí)預(yù)測庫,可為深度學(xué)習(xí)推理應(yīng)用程序提供低延遲和高吞吐量。在部署Demo中集成了TensorRT預(yù)測庫,用戶只需一鍵啟動,即可進行高性能的部署。

圖3 部署Demo性能對比說明
為了更好的幫助用戶了解在工業(yè)制造場景部署的問題,飛槳邀請產(chǎn)業(yè)用戶現(xiàn)場coding,一步步帶著大家現(xiàn)場演示如何搭建部署開發(fā)示例,如何更高性能的應(yīng)用在自己的產(chǎn)業(yè)落地中。
審核編輯 :李倩
-
多線程
+關(guān)注
關(guān)注
0文章
278瀏覽量
20047 -
工業(yè)制造
+關(guān)注
關(guān)注
0文章
405瀏覽量
28105
原文標(biāo)題:TensorRT加速、多線程部署,打通工業(yè)高性能部署最后一公里
文章出處:【微信號:mcugeek,微信公眾號:MCU開發(fā)加油站】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
開關(guān)柜一鍵順控在智慧交通領(lǐng)域的應(yīng)用
開關(guān)柜一鍵順控在化工領(lǐng)域的應(yīng)用
人機界面在開關(guān)柜一鍵順控中起到什么作用?
配電室開關(guān)柜打造一鍵順控系統(tǒng)的必要性?

一鍵斷電開關(guān)的種類有哪些
一鍵斷電開關(guān)的控制原理是什么
魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
開關(guān)柜一鍵順控比傳統(tǒng)方式時間效率上提升多少

變電站一鍵順控系統(tǒng)和開關(guān)柜一鍵順控有區(qū)別嗎?
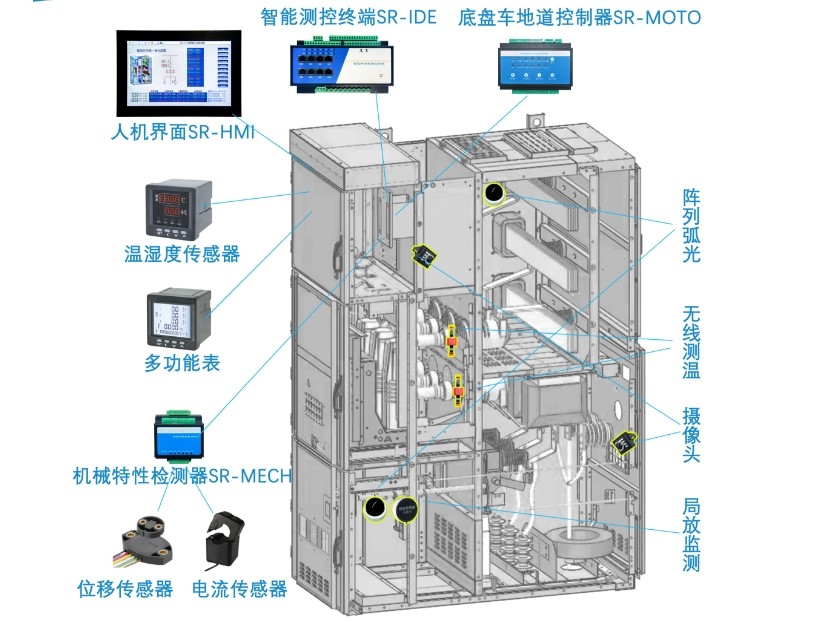
智慧礦山為什么要配電室智慧化、智能開關(guān)柜一鍵順控?
寶塔面板Docker一鍵安裝:部署GPTAcademic,開發(fā)私有GPT學(xué)術(shù)優(yōu)化工具
寶塔面板一鍵免費部署LobeChat聊天機器人開發(fā)自己私有的ChatGPT
簡析智慧燈桿一鍵告警功能的實用場景

智慧桿一鍵報警連入網(wǎng)關(guān)后無法對講是什么原因?

華為云 Serverless 應(yīng)用中心嶄新上線,一鍵部署 AI 文生圖應(yīng)用引領(lǐng)創(chuàng)新潮流





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論