 基于FFmpeg的硬件加速轉碼
基于FFmpeg的硬件加速轉碼
所有從 Kepler 一代開始的 NVIDIA GPUs 都支持完全加速的硬件視頻編碼,而從費米一代開始的所有 GPUs 都支持完全加速的硬件視頻解碼。截至 2019 年 7 月,Kepler、Maxwell、Pascal、Volta 和 Turing 一代 GPUs 支持硬件編碼,Fermi、Kepler、Maxwell、Pascal、Volta 和 Turing 一代 GPUs 支持硬件解碼。
高質量視頻應用的處理需求對廣播和電信網絡提出了限制。消費者行為已經發生了變化,這在 OTT 視頻訂閱和實時流媒體迅速普及的趨勢中表現得很明顯。現在所有的社交媒體應用程序都在各自的平臺上加入了這一功能。隨著消費者從觀看點播視頻轉向觀看直播視頻,直播將推動手機和 Wi-Fi 的整體視頻數據流量增長。
分發給觀眾的視頻內容通常被轉換成幾個自適應比特率( ABR )配置文件以進行傳輸。生產中的內容可能以大量編解碼器格式之一到達,這些格式需要轉換為另一種格式以供分發或存檔。
這使得視頻轉碼成為高效視頻管道中的一個關鍵部分——無論是 1 : N 還是 M : N 配置文件。理想的轉碼解決方案需要在成本(美元/流)和能效(瓦特/流)方面具有成本效益,同時為數據中心提供具有最大吞吐量的高質量內容。視頻提供商希望降低向更多屏幕提供更多高質量內容的成本。
在各個方面生成的大量視頻內容需要對視頻編碼、解碼和轉碼進行健壯的硬件加速。讓我們看看 NVIDIA GPUs 是如何整合專用視頻處理硬件的,以及如何利用它。
NVIDIA 編解碼硬件
NVIDIA GPUs 船上配備了片上硬件編碼器和解碼器單元,通常稱為 NVENC 和 NVDEC 。與 CUDA 核心分開, NVENC / NVDEC 運行編碼或解碼工作負載,而不會減慢同時運行的圖形或 CUDA 工作負載的執行。
NVENC 和 NVDEC 支持許多重要的編解碼編解碼器。 NVIDIA 。最新的支持矩陣可以在 GPU 上找到。

圖 1 : GPU 硬件功能
基于 FFmpeg 的硬件加速轉碼
在對視頻數據進行轉碼時,通常使用 FFmpeg 庫 。硬件加速極大地提高了工作流的性能。圖 2 顯示了 FFmpeg 轉換過程的不同元素。

圖片 2 :使用 NVIDIA 硬件加速的 FFmpeg 流水線轉碼
FFmpeg 通過 h264_cuvid 、 hevc_cuvid 和 h264_nvenc 、 hevc_nvenc 模塊支持硬件加速解碼和編碼。從源代碼構建時激活對硬件加速的支持需要一些額外的步驟:
克隆 FFmpeg git 存儲庫 https://git.ffmpeg.org/ffmpeg.git
從 NVIDIA 網站 下載并安裝兼容的驅動程序
下載并安裝 CUDA 工具箱
克隆 nv-codec-headers 存儲庫 并僅使用此存儲庫作為頭進行安裝: make install
使用以下命令配置 FFmpeg (使用正確的 CUDA 庫路徑):
./configure --enable-cuda --enable-cuvid --enable-nvenc --enable-nonfree --enable-libnpp --extra-cflags=-I/usr/local/cuda/include --extra-ldflags=-L/usr/local/cuda/lib64
-
使用多個進程進行構建,以提高構建速度并抑制過度輸出:
make -j-s
使用 FFmpeg 進行軟件 1 : 1 轉碼非常簡單:
ffmpeg -i input.mp4 -c:a copy -c:v h264 -b:v 5M output.mp4
但這將是緩慢的,因為它只使用基于 CPU 的軟件編碼器和解碼器。使用硬件編碼器 NVENC 和解碼器 NVDEC 需要添加更多參數來告訴 ffmpeg 使用哪個編碼器和解碼器。最大化轉碼速度還意味著確保解碼后的圖像保存在 GPU 存儲器中,以便編碼器能夠有效地訪問它。
ffmpeg -vsync 0 -hwaccel cuvid -c:v h264_cuvid -i input.mp4 -c:a copy -c:v h264_nvenc -b:v 5M output.mp4
如果沒有 -hwaccel-cuvid 選項,解碼后的原始幀將通過 PCIe 總線復制回系統內存,如圖 3 所示。稍后,相同的圖像將通過 PCIe 復制回 GPU 內存,以便在 GPU 上進行編碼。這兩個額外的傳輸由于傳輸時間而造成延遲,并將增加 PCIe 帶寬占用。
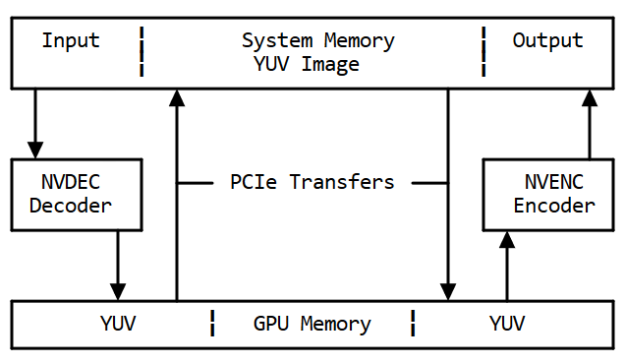
圖3 :沒有 hAccel 的內存流(& M )
添加 -hwaccel-cuvid 選項意味著原始解碼幀將不會被復制,轉碼將更快、使用更少的系統資源,如圖 4 所示。
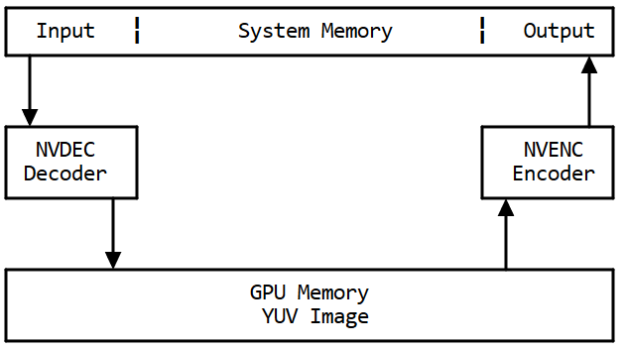
hwaccel 的內存流
給定 PCIe 帶寬限制,復制未壓縮的圖像數據會使 PCIe 總線迅速飽和。防止系統和 GPU 內存之間不必要的復制,使用 -hwaccel-cuvid 的吞吐量比不使用 -hwccel-cuvid 的未優化調用高出 2 倍。
處理篩選器
代碼轉換通常不僅涉及到更改輸入流的格式或比特率,還包括調整其大小。有兩個選項可用于調整 GPU 上的大小:使用 npp_scale 過濾器或 nvcuvid resize 選項。當從一個輸入到一個具有不同分辨率( 1 : 1 轉碼)的輸出流轉碼時,可以使用 nvcuvid resize 選項。請參見下一行的示例。
ffmpeg -vsync 0 –hwaccel cuvid -c:v h264_cuvid –resize 1280x720-i input.mp4 -c:a copy -c:v h264_nvenc -b:v 5M output.mp4
如果需要多個輸出分辨率( 1 : N 轉碼),則scale_npp濾波器可以調整 GPU 上解碼幀的大小。通過這種方式,我們可以生成具有多個不同分辨率的多個輸出流,但對所有流只使用一個調整大小的步驟。關于 1 : 2 轉碼的示例,請參見下一行。
ffmpeg -vsync 0 –hwaccel cuvid -c:v h264_cuvid -i input.mp4 \-c:a copy –vf scale_npp=1280:720-c:v h264_nvenc -b:v 5M output_720.mp4 \-c:a copy -vfscale_npp=640:320-c:v h264_nvenc -b:v 3M output_360.mp4
使用-vf "scale_npp=1280:720"將設置scale_npp作為解碼圖像的過濾器
插值算法可以作為附加參數為scale_npp定義。默認情況下使用三次插值,但其他算法 MIG ht 會根據比例因子和圖像提供更好的結果。建議在縮小尺度時使用超級采樣算法以獲得最佳質量。示例如下:
ffmpeg -vsync 0 –hwaccel cuvid -c:v h264_cuvid -i input.mp4-c:a copy –vf scale_npp=1280:720:interp_algo=super-c:v h264_nvenc -b:v 5M output_720.mp4
混合 CPU 和 GPU 處理
有時 MIG 需要混合使用 CPU 和 hwupload_cuda 處理。例如,您可能需要在 CPU 上解碼,因為 -hwaccel cuvid 解碼器不支持該格式,或者 GPU 上沒有濾波器。在這種情況下,不能使用 GPU 標志。相反,您需要使用 GPU 過濾器將數據從系統上傳到 GPU 內存。在下面的示例中,由于未設置 -hwaccel cuvid ,因此在 GPU 上解碼 H 。 264 流并將其下載到系統內存中。淡入濾波器應用于系統存儲器中,并使用 hwupload_cuda 濾波器將處理后的圖像上傳到 GPU 存儲器。最后,使用 scale_npp 縮放圖像并在 GPU 上編碼。
ffmpeg -vsync 0 -c:v h264_cuvid -i input.264-vf "fade,hwupload_cuda,scale_npp=1280:720"-c:v h264_nvenc output.264
多 -GPU
當在一個系統中使用多個 GPUs 時,編碼和解碼工作必須顯式地分配給 GPU 。 GPUs 由其索引號標識;默認情況下,所有工作都在索引為 0 的 GPU 上執行。使用以下命令獲取系統中所有 NVIDIA GPUs 及其相應的 ID 號的列表:
ffmpeg -vsync 0 -i input.mp4 -c:v h264_nvenc -gpu list -f null –
一旦知道了索引,就可以使用-hwaccel_device索引標志來設置解碼和編碼的活動 GPU 。在下面的例子中,工作將在索引為 1 的 GPU 上執行。
ffmpeg -vsync 0 -hwaccel cuvid -hwaccel_device 1 -c:v h264_cuvid -i input.mp4-c:a copy -c:v h264_nvenc -b:v 5M output.mp4
優化
為了獲得最佳的吞吐量,所有的編碼器和解碼器單元都應該被盡可能地利用。 nvidia-smi 可用于生成有關 NVENC 、 NVDEC 和一般 GPU 利用率的實時信息。
nvidia-smi dmon nvidia-smi -q -d UTILIZATION
根據這些結果可以采取多種措施。如果編碼器利用率低, MIG 可以引入另一個轉碼管道,該管道使用 CPU 解碼和 NVENC 編碼來為硬件編碼器生成額外的工作負載。
使用 CPU 篩選器時, PCIe 帶寬 MIG ht 成為瓶頸。如果可能,篩選器應在 GPU 上運行。 FFmpeg 中有幾個 CUDA 過濾器,可以用作模板來實現您自己的高性能 CUDA 過濾器。
通過使用 GPU SDK 的 NVIDIA 可視化分析器分析 ffmpeg 應用程序,您可以始終跟蹤主機和設備之間的 GPU 利用率和內存傳輸。只需啟動“ Run application to generateCPU andGPU timeline ”,然后選擇帶有相關 CLI 選項的 ffmpeg 應用程序。圖 5 說明了應用程序
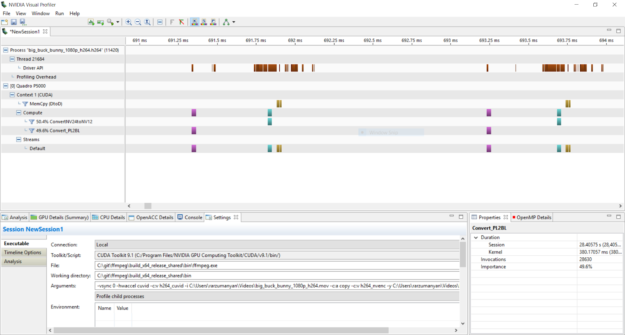
圖 5 :
綠松石塊顯示 CUDA 內核完成的顏色空間轉換,而黃色塊顯示主機和設備之間的內存傳輸。使用 visualprofiler ,用戶可以輕松地跟蹤在 GPU 上執行的操作,例如 CUDA 加速的過濾器和數據傳輸,以確保不會執行過多的內存拷貝。
通過使用 --disable-stripping CLI 選項編譯 ffmpeg 來收集 CPU – 端性能統計信息,以啟用性能分析。
這可以防止編譯器剝離函數名,以便像 Gprof 或 visualstudioprofiler 這樣的商品探查器可以收集性能統計信息。 CPU 在硬件加速開啟的情況下,負載水平應較低,并且大部分時間應花費在視頻代碼 SDK API 調用中,這些調用標記為“外部代碼因為函數名從驅動程序庫中被刪除。圖 6 顯示了一個示例屏幕截圖。
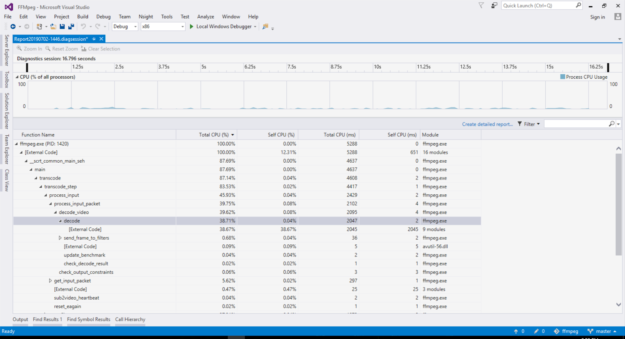
圖 6 : visualstudio 的 ffmpeg 性能評測
進一步閱讀
有關如何使用 FFmpeg 的更多示例以及可用的高級質量設置,請查看“ 使用 FFmpeg 和 NVIDIA GPU 硬件加速 “向導。
結論
FFmpeg 是一個強大而靈活的開源視頻處理庫,具有硬件加速的解碼和編碼后端。它允許快速的視頻處理和完整的 NVIDIA GPU 硬件支持,只需幾分鐘。 Gprof 、 visualprofiler 和 microsoftvisualstudio 等商品開發工具可以用于精細的性能分析和調優。看看 ffmpeg 源 試試吧!
關于作者
俄羅斯南部羅曼大學( Rostov-on-Don , 2012 )和羅曼大學應用數學碩士學位。之后,他在俄羅斯三星研發院( 2012-2015 )、英特爾公司( 2015-2017 )工作。目前,他在莫斯科擔任開發技術工程師。他的研究興趣包括視頻編碼、高性能和 GPGPU 。
Stefan Schoenefeld 是 DevTech Engeniner 和 NVIDIA 專業解決方案組的經理,他和他的團隊致力于幫助媒體和娛樂、電信和其他行業的開發人員開發和改進視頻和圖像處理、機器學習和視頻轉碼的高速應用程序。他擁有烏爾姆大學工程、計算機科學和心理學系的計算機科學文憑。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5075瀏覽量
103542 -
gpu
+關注
關注
28文章
4768瀏覽量
129227 -
CUDA
+關注
關注
0文章
121瀏覽量
13656
發布評論請先 登錄
相關推薦
數據中心中的FPGA硬件加速器
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

適用于數據中心應用中的硬件加速器的直流/直流轉換器解決方案

如何移植FFmpeg

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解決方案技術日在成都和西安站成功舉辦
《深入理解FFmpeg閱讀體驗》FFmpeg攝像頭測試
Elektrobit利用其首創的硬件加速軟件優化汽車通信網絡的性能

330-基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡 圖形圖像硬件加速器
【國產FPGA+OMAPL138開發板體驗】(原創)7.硬件加速Sora文生視頻源代碼
音視頻解碼器硬件加速:實現更流暢的播放效果






 工商網監
工商網監
評論