") 使用RAPIDS加速實現(xiàn)SHAP的模型可解釋性
使用RAPIDS加速實現(xiàn)SHAP的模型可解釋性
機(jī)器學(xué)習(xí)( ML )越來越多地用于醫(yī)療、教育和金融服務(wù)等多個領(lǐng)域的決策。由于 ML 模型被用于對人們有實際影響的情況,因此了解在消除或最小化偏見影響的決策中考慮了哪些特征是至關(guān)重要的。
模型解釋性 幫助開發(fā)人員和其他利益相關(guān)者理解模型特征和決策的根本原因,從而使流程更加透明。能夠解釋模型可以幫助數(shù)據(jù)科學(xué)家解釋他們的模型做出決策的原因,為模型增加價值和信任。在本文中,我們將討論:
對模型可解釋性的需求
使用 SHAP 的可解釋性
GPU – 從 RAPIDS 加速 SHAP 實現(xiàn)
使用 演示筆記本 在 Azure 機(jī)器學(xué)習(xí)上使用 SHAP 進(jìn)行模型解釋。
為什么我們需要解釋性?
有六個主要原因證明機(jī)器學(xué)習(xí)中需要模型互操作性:
理解模型中的公平性問題
對目標(biāo)的準(zhǔn)確理解
創(chuàng)建健壯的模型
調(diào)試模型
解釋結(jié)果
啟用審核
了解模型中的公平性問題: 可解釋模型可以解釋選擇結(jié)果的原因。在社會背景下,這些解釋將不可避免地揭示對代表性不足群體的固有偏見。克服這些偏見的第一步是看看它們是如何表現(xiàn)出來的。
更準(zhǔn)確地理解目標(biāo): 對解釋的需要也源于我們在充分理解問題方面的差距。解釋是確保我們能夠看到差距影響的方法之一。它有助于理解模型的預(yù)測是否符合利益相關(guān)者或?qū)<业哪繕?biāo)。
創(chuàng)建穩(wěn)健的模型: 可解釋模型可以幫助我們理解預(yù)測中為什么會存在一些差異,這有助于使預(yù)測更加穩(wěn)健,并消除預(yù)測中極端和意外的變化;以及為什么會出現(xiàn)錯誤。增強(qiáng)穩(wěn)健性也有助于在模型中建立信任,因為它不會產(chǎn)生顯著不同的結(jié)果。
模型可解釋性還可以幫助調(diào)試模型,解釋 向利益相關(guān)者提供成果,并使 auditing 以滿足法規(guī)遵從性。
需要注意的是,在某些情況下,可解釋性 MIG 不太重要。例如,在某些情況下,添加可解釋模型可以幫助對手欺騙系統(tǒng)。
現(xiàn)在我們了解了什么是可解釋性以及為什么我們需要它,讓我們看看最近非常流行的一種實現(xiàn)方法。
使用 SHAP 和 cuML 的 SHAP 的可解釋性
有不同的方法旨在提高模型的可解釋性;一種模型不可知的方法是 夏普利值 。這是一種從聯(lián)盟博弈論中衍生出來的方法,它提供了一種公平地將“支出”分配給各個功能的方法。在機(jī)器學(xué)習(xí)模型的情況下,支出是模型的預(yù)測/結(jié)果。它的工作原理是計算整個數(shù)據(jù)集的 Shapley 值并將其組合。
cuML 是 RAPIDS 中的機(jī)器學(xué)習(xí)庫,支持單 GPU 和多 GPU 機(jī)器學(xué)習(xí)算法,通過 內(nèi)核解釋程序 和 置換解釋者 提供 GPU 加速模型解釋能力。 核形狀 是 SHAP 最通用和最常用的黑盒解釋程序。它使用加權(quán)線性回歸來估計形狀值,使其成為一種計算效率高的近似值方法。
內(nèi)核 SHAP 的 cuML 實現(xiàn)為快速 GPU 模型提供了加速,就像 cuML 中的那些模型一樣。它們也可用于基于 CPU 的模型,在這些模型中仍然可以實現(xiàn)加速,但由于數(shù)據(jù)傳輸和模型本身的速度,它們 MIG 可能會受到限制。
在下一節(jié)中,我們將討論如何在 Azure 上使用 RAPIDS 內(nèi)核 SHAP 。
使用解釋社區(qū)和 RAPIDS 實現(xiàn)可解釋性
InterpretML 是一個開源軟件包,將最先進(jìn)的機(jī)器學(xué)習(xí)可解釋性技術(shù)集成在一起。雖然本產(chǎn)品的解釋包中涵蓋了主要的解釋技術(shù)和玻璃盒解釋模型, Interpret-Community 擴(kuò)展了解釋存儲庫,并進(jìn)一步整合了社區(qū)開發(fā)的和實驗性的解釋性技術(shù)和功能,這些技術(shù)和功能旨在實現(xiàn)現(xiàn)實場景的解釋性。
我們可以將其擴(kuò)展到 解釋 Microsoft Azure 上的模型 ,稍后將對其進(jìn)行更詳細(xì)的討論。解釋社區(qū)提供各種解釋模型的技術(shù),包括:
Tree 、 Deep 、 Linear 和 Kernel Explainers 基于形狀,
模擬解釋者 基于訓(xùn)練 全局代理模型 (訓(xùn)練模型以近似黑盒模型的預(yù)測),以及
排列特征重要性( PFI )解釋者 基于 布雷曼關(guān)于蘭德森林的論文 ,其工作原理是對整個數(shù)據(jù)集一次一個特征的數(shù)據(jù)進(jìn)行洗牌,并估計其對性能指標(biāo)的影響;變化越大,功能越重要。它可以解釋整體行為,而不是個人預(yù)測。
在社區(qū)中集成 GPU 加速 SHAP
為了使 GPU – 加速 SHAP 易于最終用戶訪問,我們將 integrated 從 cuML 的 GPU 內(nèi)核解釋者 添加到 interpret-community 包中。有權(quán)訪問 Azure 上具有 GPU s 的虛擬機(jī) ( NVIDIA Pascal 或更高版本)的用戶可以安裝 RAPIDS (》= 0.20 )并通過將 use _ ZFK5]標(biāo)志設(shè)置為 True 來啟用 GPU 解釋程序。
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes, use_gpu=True)
新添加的 GPUKernelExplainer 還使用 cuML K- 均值 來復(fù)制 shap.kmeans 的行為。 KMeans 減少了解釋者要處理的背景數(shù)據(jù)的大小。它總結(jié)了通過 K 個平均樣本傳遞的數(shù)據(jù)集,這些樣本由數(shù)據(jù)點的數(shù)量加權(quán)。將 sklearn K-Means 替換為 cuML 使我們能夠利用 GPU 的速度提升,即使在 SHAP 之前的數(shù)據(jù)預(yù)處理過程中也是如此。
基于我們的實驗,我們發(fā)現(xiàn),當(dāng)與 cuML KerneleExplainer 一起使用時, cuML 模型在某些情況下會產(chǎn)生最高可達(dá) 270 倍的速度提升的最佳結(jié)果。我們還看到了具有優(yōu)化和快速預(yù)測調(diào)用的模型的最佳加速,如優(yōu)化的 sklearn 。 svm 。 LinearSVR 和 cuml 。 svm 。 SVR ( kernel =’ linear ‘) 所示。
Azure 中的模型解釋
Azure 機(jī)器學(xué)習(xí)提供了一種通過 azureml-interpret SDK 包獲取常規(guī)和自動化 ML 培訓(xùn)說明的方法。它使用戶能夠在訓(xùn)練和推理期間,在真實世界數(shù)據(jù)集上實現(xiàn)大規(guī)模的模型可解釋性[2]。我們還可以使用交互式可視化來進(jìn)一步探索整體和單個模型預(yù)測,并進(jìn)一步了解我們的模型和數(shù)據(jù)集。 Azure 解釋使用解釋社區(qū)包中的技術(shù),這意味著它現(xiàn)在支持 RAPIDS 形狀。我們將瀏覽一個演示 Azure 上使用 cuML 形狀的模型可解釋性 的示例筆記本。
在 GPU 虛擬機(jī)上使用自定義 Docker 映像設(shè)置 RAPIDS 環(huán)境(本例中為標(biāo)準(zhǔn)的_ NC6s _ v3 )。
| from azureml.core import Environment | |
| environment_name = "rapids" | |
| env = Environment(environment_name) | |
| env.docker.enabled = True | |
| env.docker.base_image = None | |
| env.docker.base_dockerfile = """ | |
| FROM rapidsai/rapidsai:0.19-cuda11.0-runtime-ubuntu18.04-py3.8 | |
| RUN apt-get update && \ | |
| apt-get install -y fuse && \ | |
| apt-get install -y build-essential && \ | |
| apt-get install -y python3-dev && \ | |
| source activate rapids && \ | |
| pip install azureml-defaults && \ | |
| pip install azureml-interpret && \ | |
| pip install interpret-community==0.18 && \ | |
| pip install azureml-telemetry | |
| """ | |
| env.python.user_managed_dependencies = True |
 ?by?
?by?我們提供了一個腳本( train_explain.py ),它使用 cuML SVM 模型訓(xùn)練和解釋了一個二進(jìn)制分類問題。在這個例子中,我們使用 希格斯數(shù)據(jù)集 來預(yù)測一個過程是否產(chǎn)生希格斯玻色子。它有 21 個由加速器中的粒子探測器測量的運動學(xué)特性。
然后,該腳本使用 GPU SHAP KerneleExplainer 生成模型解釋。
生成的解釋使用我們的 ExplanationClient 上傳到 Azure 機(jī)器學(xué)習(xí),這是上傳和下載解釋的客戶端。這可以在您的計算機(jī)上本地運行,也可以在 Azure 機(jī)器學(xué)習(xí)計算機(jī)上遠(yuǎn)程運行。
生成的解釋上傳到 Azure 機(jī)器學(xué)習(xí)運行歷史記錄后,您可以在 Azure 機(jī)器學(xué)習(xí)工作室 中的解釋儀表板上查看可視化。
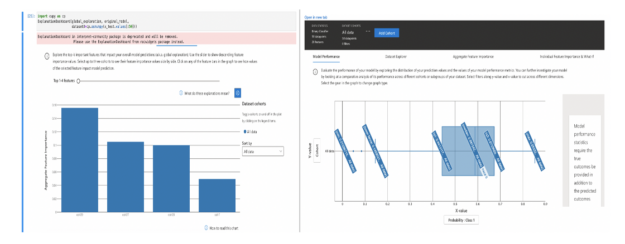
圖 1 :顯示模型性能和特性重要性的解釋儀表板。
我們在 Azure 中的單個 explain _全局調(diào)用上對 CPU 和 GPU 實現(xiàn)進(jìn)行了基準(zhǔn)測試。 explain _ global 函數(shù)在使用 explain _ local 時返回聚合特征重要性值,而不是實例級特征重要性值。我們比較了 cuml 。 svm 。 SVR ( kernel =’ rbf ‘)與 sklearn 。 svm 。 SVR ( kernel =’ rbf ‘)對形狀為( 10000 , 40 )的合成數(shù)據(jù)的影響。
從表 1 中我們可以觀察到,當(dāng)我們使用 GPU 虛擬機(jī)( Standard _ NC6S _ v3 )時,與具有 16 個內(nèi)核的 CPU 虛擬機(jī)( Standard _ DS5 _ v2 )相比, 2000 行解釋的速度提高了 420 倍。我們注意到,在 16 核 CPU 虛擬機(jī)上使用 64 核 CPU 虛擬機(jī)(標(biāo)準(zhǔn)_ D64S _ v3 )可以產(chǎn)生更快的 CPU 運行時間(大約 1 。 3 倍)。這種更快的 CPU 運行仍然比 GPU 運行慢得多,而且更昂貴。 GPU 運行速度快了 380 倍,成本為 0 。 52 美元,而 64 核 CPU 虛擬機(jī)的成本為 23 美元。我們在 Azure 的美國東部地區(qū)進(jìn)行了實驗。
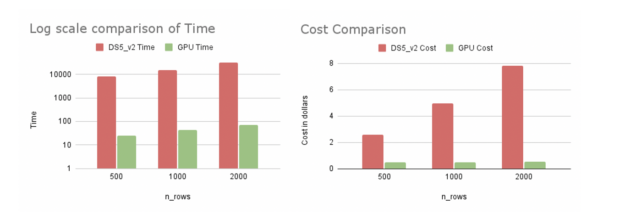
圖 2 : Azure 上 CPU 和 GPU 虛擬機(jī)的比較。
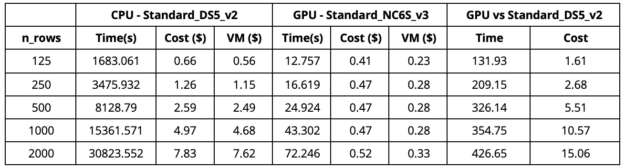
表 1 :標(biāo)準(zhǔn) DS5 和標(biāo)準(zhǔn) NC6s _ v3 的比較。
從我們的實驗來看,在 Azure 上使用 cuML 的 KernelExplainer 被證明更具成本和時間效率。隨著行數(shù)的增加,速度會更好。 GPU SHAP 不僅解釋了更多的數(shù)據(jù),而且還節(jié)省了更多的資金和時間。這會對時間敏感的企業(yè)產(chǎn)生巨大影響。
這是一個簡單的例子,說明如何在 Azure 上使用 cuML 的 SHAP 進(jìn)行解釋。這可以擴(kuò)展到具有更有趣的模型和數(shù)據(jù)集的更大示例。
關(guān)于作者
Nanthini 是 NVIDIA 的數(shù)據(jù)科學(xué)家和軟件開發(fā)人員。她在 RAPIDS 團(tuán)隊工作,該團(tuán)隊專注于使用 GPU 加速數(shù)據(jù)科學(xué)管道。她的工作包括進(jìn)行概念驗證、開發(fā)和維護(hù)功能、將 RAPIDS 與外部框架集成,以及通過示例用例演示這些工具的使用。最近,她一直致力于 RAPIDS 框架和微軟解釋之間的集成。 2019 ,她獲得了賓夕法尼亞大學(xué)計算機(jī)科學(xué)碩士學(xué)位。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4768瀏覽量
129227 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
132935
發(fā)布評論請先 登錄
相關(guān)推薦
中國電提出大模型推理加速新范式Falcon

《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
基于LIBS技術(shù)的煤炭灰分、揮發(fā)分和熱值定量分析及特征工程研究

RAPIDS cuDF將pandas提速近150倍

一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)

FPGA加速深度學(xué)習(xí)模型的案例
常見AI大模型的比較與選擇指南
LLM大模型推理加速的關(guān)鍵技術(shù)
基于FPGA的脈沖神經(jīng)網(wǎng)絡(luò)模型應(yīng)用探索
【大規(guī)模語言模型:從理論到實踐】- 閱讀體驗
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】核心技術(shù)綜述
Meta發(fā)布SceneScript視覺模型,高效構(gòu)建室內(nèi)3D模型
AI算法在礦山智能化中的應(yīng)用全解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論