 計算機視覺中的傳統特征提取方法
計算機視覺中的傳統特征提取方法
前言本文對計算機視覺傳統方法中的一些特征提取方法進行了總結,主要包括有:SIFT(尺度不變特征變換)、HOG(方向梯度直方圖)、SURF、ORB、LBP、HAAR
先對幾個概念和問題做一個解釋:
圖像為什么要灰度化?
識別物體,最關鍵的因素是梯度(SIFT/HOG),梯度意味著邊緣,這是最本質的部分,而計算梯度,自然就用到灰度圖像了,可以把灰度理解為圖像的強度。
顏色,易受光照影響,難以提供關鍵信息,故將圖像進行灰度化,同時也可以加快特征提取的速度。
仿射不變性
平面上任意兩條線,經過仿射變換后,仍保持原來的狀態(比如平行的線還是平行,相交的線夾角不變等)
什么是局部特征?局部特征應該具有的特點?
局部特征從總體上說是圖像或在視覺領域中一些有別于其周圍的地方;局部特征通常是描述一塊區域,使其能具有高可區分度;局部特征的好壞直接會決定著后面分類、識別是否會得到一個好的結果。
局部特征應該具有的特點:可重復性、可區分性、準確性、有效性(特征的數量、特征提取的效率)、魯棒性(穩定性、不變性)。
1、SIFT(尺度不變特征變換)
1.1 SIFT特征提取的實質
在不同的尺度空間上查找關鍵點(特征點),并計算出關鍵點的方向。SIFT所查找到的關鍵點是一些十分突出、不會因光照、仿射變換和噪音等因素而變化的點,如角點、邊緣點、暗區的亮點及亮區的暗點等。
1.2 SIFT特征提取的方法
1. 構建DOG尺度空間:
模擬圖像數據的多尺度特征,大尺度抓住概貌特征,小尺度注重細節特征。通過構建高斯金字塔(每一層用不同的參數σ做高斯模糊(加權)),保證圖像在任何尺度都能有對應的特征點,即保證尺度不變性。
2. 關鍵點搜索和定位:
確定是否為關鍵點,需要將該點與同尺度空間不同σ值的圖像中的相鄰點比較,如果該點為max或min,則為一個特征點。找到所有特征點后,要去除低對比度和不穩定的邊緣效應的點,留下具有代表性的關鍵點(比如,正方形旋轉后變為菱形,如果用邊緣做識別,4條邊就完全不一樣,就會錯誤;如果用角點識別,則穩定一些)。去除這些點的好處是增強匹配的抗噪能力和穩定性。最后,對離散的點做曲線擬合,得到精確的關鍵點的位置和尺度信息。
3. 方向賦值:
為了實現旋轉不變性,需要根據檢測到的關鍵點的局部圖像結構為特征點賦值。具體做法是用梯度方向直方圖。在計算直方圖時,每個加入直方圖的采樣點都使用圓形高斯函數進行加權處理,也就是進行高斯平滑。這主要是因為SIFT算法只考慮了尺度和旋轉不變形,沒有考慮仿射不變性。通過高斯平滑,可以使關鍵點附近的梯度幅值有較大權重,從而部分彌補沒考慮仿射不變形產生的特征點不穩定。注意,一個關鍵點可能具有多個關鍵方向,這有利于增強圖像匹配的魯棒性。
4. 關鍵點描述子的生成:
關鍵點描述子不但包括關鍵點,還包括關鍵點周圍對其有貢獻的像素點。這樣可使關鍵點有更多的不變特性,提高目標匹配效率。在描述子采樣區域時,需要考慮旋轉后進行雙線性插值,防止因旋轉圖像出現白點。同時,為了保證旋轉不變性,要以特征點為中心,在附近領域內旋轉θ角,然后計算采樣區域的梯度直方圖,形成n維SIFT特征矢量(如128-SIFT)。最后,為了去除光照變化的影響,需要對特征矢量進行歸一化處理。
如果對上述純文字理解困難,可以參考文章:
SIFT特征提取算法
1.3 SIFT特征提取的優點
SIFT特征是圖像的局部特征,其對旋轉、尺度縮放、亮度變化保持不變性,對視角變化、仿射變換、噪聲也保持一定程度的穩定性;
獨特性(Distinctiveness)好,信息量豐富,適用于在海量特征數據庫中進行快速、準確的匹配;
多量性,即使少數的幾個物體也可以產生大量的SIFT特征向量;
高速性,經優化的SIFT匹配算法甚至可以達到實時的要求;
可擴展性,可以很方便的與其他形式的特征向量進行聯合;
需要較少的經驗主義知識,易于開發。
1.4 SIFT特征提取的缺點
實時性不高,因為要不斷地要進行下采樣和插值等操作;
有時特征點較少(比如模糊圖像);
對邊緣光滑的目標無法準確提取特征(比如邊緣平滑的圖像,檢測出的特征點過少,對圓更是無能為力)。
1.5 SIFT特征提取可以解決的問題:
目標的自身狀態、場景所處的環境和成像器材的成像特性等因素影響圖像配準/目標識別跟蹤的性能。而SIFT算法在一定程度上可解決:
目標的旋轉、縮放、平移(RST)
圖像仿射/投影變換(視點viewpoint)
光照影響(illumination)
目標遮擋(occlusion)
雜物場景(clutter)
噪聲
近來不斷有人改進,其中最著名的有 SURF(計算量小,運算速度快,提取的特征點幾乎與SIFT相同)和 CSIFT(彩色尺度特征不變變換,顧名思義,可以解決基于彩色圖像的SIFT問題)。
2、HOG(方向梯度直方圖)
2.1 HOG特征提取的實質
通過計算和統計圖像局部區域的梯度方向直方圖來構成特征。Hog特征結合SVM分類器已經被廣泛應用于圖像識別中,尤其在行人檢測中獲得了極大的成功。
2.2 HOG特征提取的方法
灰度化;
采用Gamma校正法對輸入圖像進行顏色空間的標準化(歸一化),目的是調節圖像的對比度,降低圖像局部的陰影和光照變化所造成的影響,同時可以抑制噪音的干擾;
計算圖像每個像素的梯度(包括大小和方向),主要是為了捕獲輪廓信息,同時進一步弱化光照的干擾;
將圖像劃分成小cells(例如6*6像素/cell);
統計每個cell的梯度直方圖(不同梯度的個數),即可形成每個cell的descriptor;
將每幾個cell組成一個block(例如3*3個cell/block),一個block內所有cell的特征descriptor串聯起來便得到該block的HOG特征descriptor。
將圖像image內的所有block的HOG特征descriptor串聯起來就可以得到該image(你要檢測的目標)的HOG特征descriptor了。這個就是最終的可供分類使用的特征向量了。
如果對上述純文字理解困難,可以參考文章:
目標檢測的圖像特征提取之(一)HOG特征
2.3 HOG特征提取特點
由于HOG是在圖像的局部方格單元上操作,所以它對圖像幾何的和光學的形變都能保持很好的不變性,這兩種形變只會出現在更大的空間領域上。
在粗的空域抽樣、精細的方向抽樣以及較強的局部光學歸一化等條件下,只要行人大體上能夠保持直立的姿勢,可以容許行人有一些細微的肢體動作,這些細微的動作可以被忽略而不影響檢測效果。因此HOG特征是特別適合于做圖像中的人體檢測的。
3、SIFT和HOG的比較
共同點:都是基于圖像中梯度方向直方圖的特征提取方法
不同點:
SIFT 特征通常與使用SIFT檢測器得到的興趣點一起使用。這些興趣點與一個特定的方向和尺度相關聯。通常是在對一個圖像中的方形區域通過相應的方向和尺度變換后,再計算該區域的SIFT特征。
HOG特征的單元大小較小,故可以保留一定的空間分辨率,同時歸一化操作使該特征對局部對比度變化不敏感。
結合SIFT和HOG方法,可以發現SIFT對于復雜環境下物體的特征提取具有良好的特性;而HOG對于剛性物體的特征提取具有良好的特性。
筆者曾做過一個自然場景分類的實驗,發現SIFT的準確率比HOG高,而如果檢測像人這種剛性的object,HOG的表現要比SIFT好。
4、SIFT/HOG與神經網絡特征提取的比較
眾所周知,隨著深度學習的發展,通過神經網絡提取特征得到了廣泛的應用,那么,神經網絡提取的特征與傳統的SIFT/HOG等特征提取方法有什么不同呢?
4.1 神經網絡提取到的特征
我們知道,對于一副圖像,像素級的特征沒有任何價值,而如果特征是一個具有結構性(或者說有含義)的時候,比如摩托車是否具有車把手,是否具有車輪,就很容易把摩托車和非摩托車區分,學習算法才能發揮作用。
早期,兩個科學家Bruno Olshausen和 David Field通過實驗研究了這個問題,發現一個復雜圖像往往由一些基本結構組成。比如下圖:一個圖可通過用64種正交的edges(可以理解成正交的基本結構)來線性表示。比如樣例的x可以用1-64個edges中的三個按照0.8,0.3,0.5的權重調和而成。而其他基本edges沒有貢獻,均為0 。
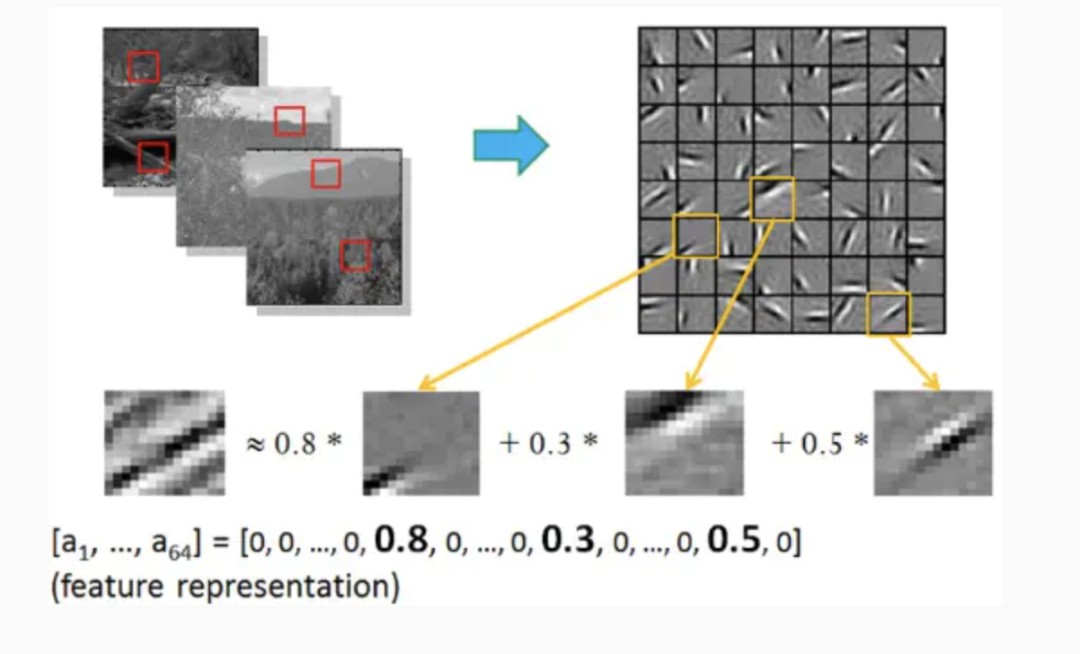
這就是神經網絡每層提取到的特征。由于是通過神經網絡自動學習到了,因此也是無監督的特征學習過程(Unsupervised Feature Learning) 。直觀上說,就是找到make sense的小patch再將其進行combine,就得到了上一層的feature,遞歸地向上learning feature。在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就會completely different了。
4.2 傳統特征提取方法與神經網絡特征提取的比較
觀點1:傳統特征提取方法的研究過程和思路是非常有用的,因為這些方法具有較強的可解釋性,它們對設計機器學習方法解決此類問題提供啟發和類比。有部分人認為(也有部分人反對)現有的卷積神經網絡與這些特征提取方法有一定類似性,因為每個濾波權重實際上是一個線性的識別模式,與這些特征提取過程的邊界與梯度檢測類似。同時,池化(Pooling)的作用是統籌一個區域的信息,這與這些特征提取后進行的特征整合(如直方圖等)類似。通過實驗發現卷積網絡開始幾層實際上確實是在做邊緣和梯度檢測。不過事實上卷積網絡發明的時候,還沒有這些特征提取方法。
觀點2:深度學習的數據需求量大對于視覺來說是個偽命題。許多研究成果已經表明深度學習訓練得到的模型具有很強的遷移能力,因此在大數據集上訓練完成的模型只要拿過來在小數據集上用就可以,不需要完全重新訓練。這種方式在小數據集上的結果往往也比傳統方法好。
觀點3:還是需要重新訓練的,只能說大數據集訓練好的模型提供了一個比較好的參數初始化。而且卷積前幾層提取特征僅僅是對分類問題是對的,但是對于一些dense prediction還是不一樣,畢竟提取特征不一定有用,還是task dependent。
觀點4:深度學習是一種自學習的特征表達方法,比SIFT/HOG這些依靠先驗知識設計的feature的表達效果高。早在13年大家都發現神經網絡的最后一層的local特征和SIFT性質差不多,但是表達能力強太多。SIFT能做的事情CNN都能做,表達效果也強,那深度學習取代SIFT是遲早的事情(或者說已經發生的事情)。深度神經網絡識別率的提高不需要建立在需求大量訓練樣本的基礎上,拿pre-train好的模型直接用就可以了。在一些沒有訓練樣本的應用(圖像分割(image stithing)/ 立體匹配(stereo mathing)) ,可以把卷積層的activation提取出來做stitching的local feature(感覺是一個可以探索的方向)。未來還有SIFT/SURF這種固定特征提取算法的生存空間嗎?除非是嵌入式這種計算資源極端受限的情況,但是現在大家都在試著implement CNN FPGA甚至ASIC了。
觀點5:2016年ECCV上舉辦的一個local feature的工作會,發現在核心匹配問題上,CNN并沒有什么突破性的進展。在Oxford大學的VGG組提供的Hpatch數據集上,發現rootsiftpca效果最好,如圖:
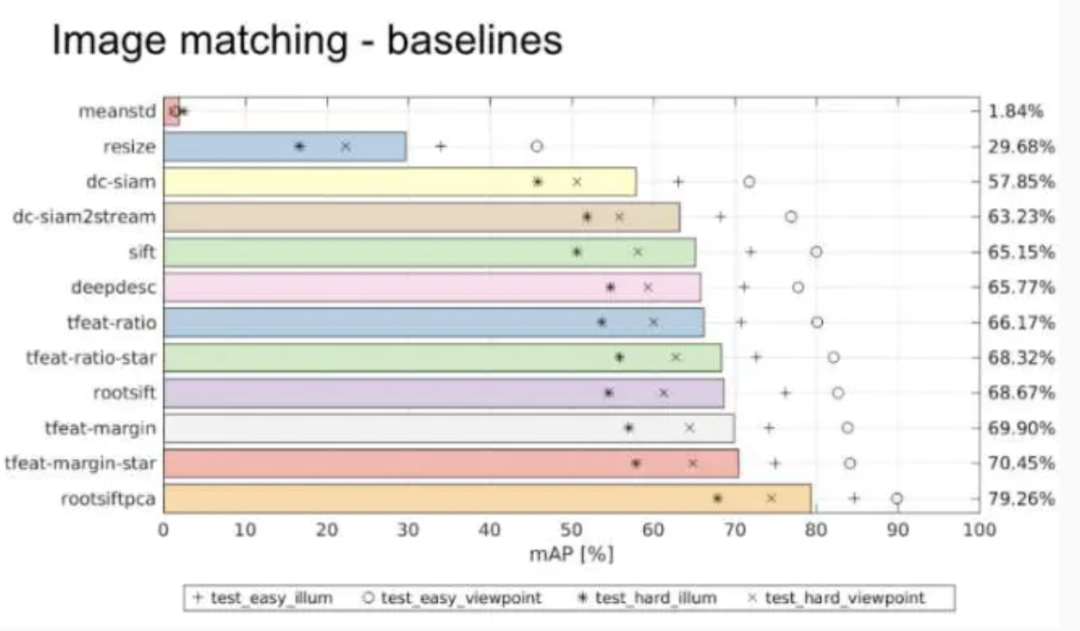
那么提出兩個問題:(1)現在流行的特征學習方法siamese或triplet等結構是否缺失了什么?(2)雖然CNN可以挖掘patch里面包含的信息并建立對于復雜幾何和光照變化的不變性,但是這種學習到的不變性是否過度依賴于數據而無法有效泛化到真實匹配場景中所遇到的影像之間的復雜變化呢?
可以參考以下知乎話題,查看更多觀點:
https://www.zhihu.com/question/48315686
5、其他傳統特征提取的方法(SURF、ORB、LBP、HAAR)
SURF、ORB、LBP可以參考文章:
圖像特征檢測描述(一):SIFT、SURF、ORB、HOG、LBP特征的原理概述及OpenCV代碼實現
https://link.jianshu.com/?t=http://lib.csdn.net/article/opencv/41913
5.1 SURF
前面提到SITF的缺點是如果不借助硬件加速或專門的圖像處理器很難達到實現,所以人們就要想辦法對SITF算子進行改進,SURF算子便是對SIFT的改進,不過改進之后在算法的運行時間上還是沒有質的飛躍。后面要介紹的ORB特征描述算子在運行時間上才是一種質的飛躍。
SURF主要是把SIFT中的某些運算作了簡化。SURF把SIFT中的高斯二階微分的模板進行了簡化,使得卷積平滑操作僅需要轉換成加減運算,這樣使得SURF算法的魯棒性好且時間復雜度低。SURF最終生成的特征點的特征向量維度為64維。
5.2 ORB
ORB特征描述算法的運行時間遠優于SIFT與SURF,可用于實時性特征檢測。ORB特征基于FAST角點的特征點檢測與描述技術,具有尺度與旋轉不變性,同時對噪聲及透視仿射也具有不變性,良好的性能使得用ORB在進行特征描述時的應用場景十分廣泛。
ORB特征檢測主要分為以下兩個步驟:
①方向FAST特征點檢測:FAST角點檢測是一種基于機器學習的快速角點特征檢測算法,具有方向的FAST特征點檢測是對興趣點所在圓周上的16個像素點進行判斷,若判斷后的當前中心像素點為暗或亮,將候定其是否為角點。FAST角點檢測計算的時間復雜度小,檢測效果突出。FAST角點檢測為加速算法實現,通常先對回周上的點集進行排序,排序使得其計算過程大大得到了優化。FAST對多尺度特性的描述是還是通過建立圖像金字塔實現的,而對于旋轉不變性即方向的特征則引入灰度質心法用于描述特征點的方向。
②BRIEF特征描述:BRIEF描述子主要是通過隨機選取興趣點周圍區域的若干點來組成小興趣區域,將這些小興趣區域的灰度二值化并解析成二進制碼串,將串特征作為該特征點的描述子,BRIEF描述子選取關鍵點附近的區域并對每一位比較其強度大小,然后根據圖像塊中兩個二進制點來判斷當前關鍵點編碼是0還是1.因為BRIEF描述子的所有編碼都是二進制數的,這樣就節省了計算機存儲空間。
5.3 LBP
LBP(Local Binary Pattern),局部二值模式是一種描述圖像局部紋理的特征算子,具有旋轉不變性與灰度不變性等顯著優點。LBP特征描述的是一種灰度范圍內的圖像處理操作技術,針對的是輸入源為8位或16位的灰度圖像。LBP特征是高效的圖像特征分析方法,經過改進與發展已經應用于多個領域之中,特別是人臉識別、表情識別、行人檢測領域已經取得了成功。LBP特征將窗口中心點與鄰域點的關系進行比較,重新編碼形成新特征以消除對外界場景對圖像的影響,因此一定程度上解決了復雜場景下(光照變換)特征描述問題。
LBP算法根據窗口領域的不同分為經曲LBP和圓形LBP兩種。下面分別介紹:
①經典LBP:經典LBP算子窗口為3×3的正方形窗口,以窗口中心像素為閾值,將其相鄰8領域像素灰度與中心像素值比較,若中心像素值小于周圍像素值,則該中心像素位置被標記為1,否則為0(顯然這種規則下,對于中心點大于或等于這兩種情況,算法無法區分,后續經過改進引入LBP+與LBP-因子用來區分這兩種情況)。圖像經過這種遍歷操作后,圖像就被二值化了,每一個窗口中心的8鄰域點都可以由8位二進制數來表示,即可產生256種LBP碼,這個LBP碼值可以用來反映窗口的區域紋理信息。LBP具體在生成的過程中,先將圖像劃分為若干個子區域,子區域窗口可根據原圖像的尺寸進行調整,而不一定非得為3×3的正方形窗口。一般對于512×640的圖像,子區域窗口區域選取大小為16×16。
②圓形LBP:經典LBP用正方形來描述圖像的紋理特征,其缺點是難以滿足不同尺寸和頻率的需求。Ojala等人對經典LBP進行了改進,提出了將3×3的正方形窗口領域擴展到任意圓形領域。由于圓形LBP采樣點在圓形邊界上,那么必然會導致部分計算出來的采樣點坐標不是整數,因此這里就需要對得到的坐標像素點值進行處理,常用的處理方法是最近鄰插值或雙線性插值。
放一張SIFT/HOG/LBP優缺點、適用范圍對比圖:

5.4 HAAR
人臉檢測最為經典的算法Haar-like特征+Adaboost。這是最為常用的物體檢測的方法(最初用于人臉檢測),也是用的最多的方法。
訓練過程:輸入圖像->圖像預處理->提取特征->訓練分類器(二分類)->得到訓練好的模型;
測試過程:輸入圖像->圖像預處理->提取特征->導入模型->二分類(是不是所要檢測的物體)。
Haar-like特征是很簡單的,無非就是那么幾種,如兩矩形特征、三矩形特征、對角特征。后來,還加入了邊緣特征、線特征、中心環繞特征等。使用積分圖可以加速計算特征。最后,使用集成的方法Adaboost進行訓練。
具體細節可以參考文章:
特征提取之Haar特征
https://link.jianshu.com/?t=http://blog.csdn.net/xizero00/article/details/46929261
再附一個Haar和HOG比較的問題:
為什么在行人檢測中,HOG特征比Haar特征更精確?
https://link.jianshu.com/?t=http://blog.csdn.net/DuinoDu/article/details/51981327
Conclusion
SIFT / HOG 不同點:SIFT提取的關鍵點是角點,HOG提取的是邊緣特征。
傳統特征提取 / CNN特征提取不同點:傳統特征提取方法的檢測算子一般是人為設計好的,是經過大量的先驗知識總結得到的;CNN特征提取相當于在訓練一個個filter(過濾器、卷積核),這些filter相當于傳統特征提取方法中的檢測算子。因此,CNN特征提取是利用神經網絡的自主學習得到的。

審核編輯 :李倩
-
圖像
+關注
關注
2文章
1089瀏覽量
40540 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46085
原文標題:計算機視覺中的傳統特征提取方法總結
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用機器學習改善庫特征提取的質量和運行時間
計算機視覺有哪些優缺點
圖像識別算法的核心技術是什么
計算機視覺的工作原理和應用
機器人視覺與計算機視覺的區別與聯系
計算機視覺與人工智能的關系是什么
計算機視覺怎么給圖像分類
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論