 一文詳細了解高速存儲接口NVMe
一文詳細了解高速存儲接口NVMe
編者按
網絡側現在還沒有形成標準的接口。Virtio-net因為軟件虛擬化的流行所以標準,但其性能較差;AWS有自己的ENA/EFA接口,NVIDIA提供的是NV-SRIOV自定義接口,以及基于此封裝的Virtio-net接口。 在存儲側,業界形成了“偉大”的共識:NVMe標準接口,兼顧了標準化和高性能。與此同時,從Virtio-blk逐步切換到NVMe在業界得到了眾多的認可。
高速存儲接口NVMe
跟網絡接口相比,存儲的接口標準化程度相對較高。NVMe是本地高性能存儲主流的接口標準,同時基于NVMe擴展的NVMeoF是高性能網絡存儲主要的接口及整體解決方案標準。
1 NVMe概述
NVMe(Non-Volatile Memory Express)是經過優化的、高性能的、可擴展的主機控制器接口,專為非易失性存儲器(NVM)技術而設計。NVMe解決了如下一些性能問題:
帶寬:通過支持PCIe和諸如RDMA和光纖之類的通道,NVMe可以支持比SATA或SAS高很多的帶寬。
IOPS:例如,串行ATA可能的最大IOPS為20萬,而NVMe設備已被證明超過100萬IOPS。
延遲:NVM以及未來的存儲技術具有一微秒以內的訪問延遲,需要一種更簡潔的軟件協議,能夠實現包括軟件堆棧在內的不超過10毫秒的端到端延遲。
NVMe協議支持多個深度隊列,這是對傳統SAS和SATA協議的改進。典型的SAS設備在單個隊列中最多支持256個命令,而SATA設備最多支持32個命令。這些隊列深度對于傳統的硬盤驅動器技術已經足夠,但不能充分利用NVM技術的性能。
相比之下,圖1所示的NVMe多隊列,每個隊列支持64K命令,最多支持64K隊列。這些隊列的設計使得IO命令和對命令的處理不僅可以在同一處理器內核上運行,也可以充分利用多核處理器的并行處理能力。每個應用程序或線程可以有自己的獨立隊列,因此不需要IO鎖定。NVMe還支持MSI-X和中斷控制,避免了CPU中斷處理的瓶頸,實現了系統擴展的可伸縮性。NVMe采用簡化的命令集,相比SAS或SATA,NVMe命令集使用的處理IO請求的指令數量減少了一半,從而在單位CPU指令周期內可以提供更高的IOPS,并且降低主機中IO軟件堆棧的處理延遲。
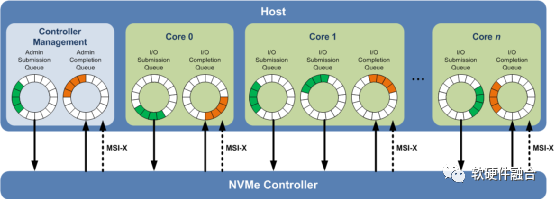
圖1 NVMe多隊列
2 NVMe寄存器
NVMe(Over PCIe)寄存器主要分為兩類,一類是PCIe配置空間寄存器,一類是NVMe控制器相關的寄存器。
a.PCIe配置空間和功能
NVMe PCIe總線寄存器如表1所示,NVMe跟主機CPU的接口主要是基于PCIe總線,使用PCIe的Config和Capability機制。包括PCI/PCIe頭、PCI功能和PCIe擴展功能。
表1 NVMe PCIe配置空間和功能
| 起始 | 結束 | 名稱 | 類型 |
| 00h | 3Fh | PCI/PCIe頭 | |
| PMCAP | PMCAP+7h | PCI功耗管理(Power Management)功能 | PCI功能 |
| MSICAP | MSICAP+9h | MSI(Message Signaled Interrupt)功能 | PCI功能 |
| MSIXCAP | MSIXCAP+Bh | MSI-X(MSI eXtension,MSI擴展)功能 | PCI功能 |
| PXCAP | PXCAP+29h | PCIe功能 | PCI功能 |
| AERCAP | AERCAP+47h | AER(Advanced Error Reporting)功能 | PCIe擴展功能 |
b.NVMe控制器寄存器
NVMe控制器寄存器位于MLBAR/MUBAR寄存器(PCI BAR0和BAR1)中,這些寄存器應映射到支持順序訪問和可變訪問寬度的內存空間。NVMe 1.3d版本的控制器寄存器列表如表2所示。
表2 NVMe 1.3d版本的控制器寄存器列表
| 起始 | 結束 | 縮寫 | 描述 |
| 0h | 7h | CAP | 控制功能 |
| 8h | Bh | VS | 版本 |
| Ch | Fh | INTMS | 中斷屏蔽設置 |
| 10h | 13h | INTMC | 中斷屏蔽清楚 |
| 14h | 17h | CC | 控制器配置 |
| 18h | 1Bh | Reserved | 保留 |
| 1Ch | 1Fh | CSTS | 控制器狀態 |
| 20h | 23h | NSSR | NVM子系統重置(可選) |
| 24h | 27h | AQA | 管理隊列屬性 |
| 28h | 2Fh | ASQ | 管理提交隊列基地址 |
| 30h | 37h | ACQ | 管理完成隊列基地址 |
| 38h | 3Bh | CMBLOC | 控制器存儲緩沖位置(可選) |
| 3Ch | 3Fh | CMBSZ | 控制器存儲緩沖大小(可選) |
| 40h | 43h | BPINFO | 引導分區信息(可選) |
| 44h | 47h | BPRSEL | 引導分區讀選擇(可選) |
| 48h | 4Fh | BPMBL | 引導分區存儲緩沖位置(可選) |
| 50h | EFFh | Reserved | 保留 |
| F00h | FFFh | Reserved | 命令設置具體的寄存器 |
| 1000h | 1003h | SQ0TDBL | 管理SQ0尾Db |
| 1000h + (1 * (4 << CAP.DSTRD)) | 1003h + (1 * (4 << CAP.DSTRD)) | CQ0HDBL | 管理CQ0頭Db |
| 1000h + (2 * (4 << CAP.DSTRD)) | 1003h + (2 * (4 << CAP.DSTRD)) | SQ1TDBL | SQ1尾Db |
| 1000h + (3 * (4 << CAP.DSTRD)) | 1003h + (3 * (4 << CAP.DSTRD)) | CQ1HDBL | CQ1頭Db |
| … | … | … | … |
| 1000h+ (2y * (4 << CAP.DSTRD)) | 1003h + (2y * (4 << CAP.DSTRD)) | SQyTDBL | SQy尾Db |
| 1000h + ((2y + 1) * (4 << CAP.DSTRD)) | 1003h + ((2y + 1) * (4 << CAP.DSTRD)) | CQyHDBL | CQy頭Db |
| 供應商定制寄存器(可選) | |||
| SQ:Submission Queue,提交隊列;CQ:Completion Queue,完成隊列;Db:Doorbell,門鈴。 |
3 NVMe隊列
NVMe的隊列是經典的環形隊列結構,通過提交/完成隊列對來實現隊列的傳輸交互。
a.隊列概述
NVMe使用的是經典的循環隊列結構來傳遞消息(例如,傳遞命令和命令完成通知)。隊列可以映射到任何PCIe可訪問的內存中,通常是放在主機內存。
如圖2,隊列是固定大小的,通過Tail和Head來分別指向寫入和讀取的指針。像通常的隊列數據結構一樣,隊列實際可使用的大小是隊列大小減1,并且用Head等于Tail指示隊列空,用Head等于(Tail+1)除以隊列大小的余數來指示隊列滿。
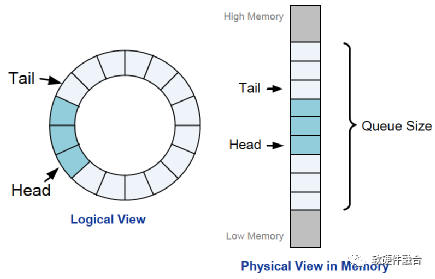
圖2 NVMe隊列結構
如上一節的圖1,根據用途,NVMe隊列有兩類:管理隊列和IO隊列;根據傳輸方向有兩類:提交隊列和完成隊列。具體介紹見表3。
表3 NVMe隊列類型
| 管理 | IO | |
| 提交 |
用于提交管理命令,最大4K項; 用于配置控制器和IO隊列等; 從主機側到控制器側。 |
用于傳輸IO命令,最大64K項; 用于提交IO操作命令; 從主機側到控制器側。 |
| 完成 |
管理命令的完成確認,最大4K項; 從控制器側到主機側; 獨立的MSI-X中斷處理。 |
IO命令的完成確認,最大64K項; 從控制器側到主機側; 獨立的MSI-X中斷處理。 |
b.隊列處理流程
NVMe的驅動和設備交互跟Virtio不同:Virtio是在通過一個隊列完成雙向通知交互;而NVMe則采用提交隊列和完成隊列配合完成雙向交互的方式。
如圖3,NVMe隊列處理流程如下(其中主機為軟件驅動,控制器為硬件設備):
(1)主機寫命令到提交隊列項中。
(2)主機寫DB(Doorbell)寄存器,通知控制器有新命令待處理。
(3)控制器從內存中的提交隊列中讀取命令。
(4)控制器執行命令。
(5)控制器更新完成隊列,表示當前的SQ項已經處理。
(6)控制器發MSI-x中斷到主機CPU。
(7)主機處理完成隊列,同步更新提交隊列中的已處理項。
(8)主機寫完成隊列Db到控制器,告知完成隊列項已釋放。
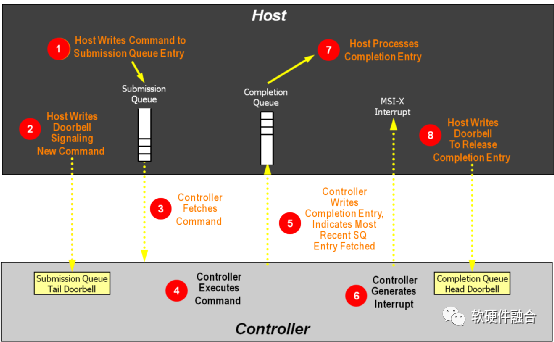
圖3 NVMe隊列處理流程
4 NVMe命令結構
我們通過如下一些概念來理解NVMe命令結構:
隊列項的數據格式。NVMe的提交命令固定64字節,完成命令固定16字節。
命令。NVMe命令分為Admin和IO兩類。
NVMe的數據塊組織方式有PRP和SGL兩種。
a.隊列項的數據格式
提交隊列和完成隊列,組成隊列對,協作完成NVMe驅動和設備之間的命令傳輸。提交隊列每一項64字節固定大小,完成隊列每一項16字節固定大小。
提交隊列的數據格式如圖4所示。NVMe提交隊列項的數據格式屬性如下:
Opcode:命令操作碼
FUSE:熔合兩個命令為一條命令
PSDT:PRP或SGL數據傳輸
Command Identifier:命令ID
Namespace Identifier:命名空間ID
Metadata Pointer:元數據指針
PRP entry 1/2:物理區域頁項,對應的由PRP和PRP列表
SGL:散列聚合列表

圖4 提交隊列項的數據格式
完成隊列的數據格式如圖5所示。

圖5 完成隊列項的數據格式
NVMe完成隊列的數據格式屬性如下:
SQ Header pointer:SQ頭指針
SQ Identifier:SQ ID
Command Identifier:命令ID
P:相位標志phase tag,完成隊列沒有head/tail交互,通過相位標志實現完成隊列項的釋放
Status Field:狀態域
b.NVMe命令
NVMe管理類的命令如表4所示。
表4 NVMe管理命令列表
| 命令 | 必選或可選 | 類別 |
| 創建IO SQ | 必選 | 隊列管理 |
| 刪除IO SQ | 必選 | |
| 創建IO CQ | 必選 | |
| 刪除IO CQ | 必選 | |
| 鑒別 | 必選 | 配置 |
| 獲取特征 | 必選 | |
| 設置特征 | 必選 | |
| 獲取日志頁 | 必選 | 狀態報告 |
| 異步事件請求 | 必選 | |
| 中止 | 必選 | 中止命令 |
| 固件鏡像下載 | 可選 | 固件更新和管理 |
| 固件可用 | 可選 | |
| IO命令集定制命令 | 可選 | IO命令集定制 |
| 供應商定制命令 | 可選 | 供應商定制 |
NVMe IO類命令如表5所示。
表5 NVMe IO類命令列表
| 命令 | 必選或可選 | 類別 |
| 讀 | 必選 | 必選的數據命令 |
| 寫 | 必選 | |
| 清洗 | 必選 | |
| 不可改正的寫 | 可選 | 可選的數據命令 |
| 寫0 | 可選 | |
| 比較 | 可選 | |
| 數據集管理 | 可選 | 數據提示 |
| 預約獲取 | 可選 | 預約命令 |
| 預約寄存器 | 可選 | |
| 預約釋放 | 可選 | |
| 預約報告 | 可選 | |
| 供應商專用命令 | 可選 | 供應商專用 |
c.物理區域頁PRP
PRP本質是一個鏈表,鏈表中的每一個指針都指向一個不超過頁大小的數據塊。PRP為8字節(64bits)固定大小,PRPList則最多可以占滿一整個頁。
PRP1和PRP2的格式如圖6(a)所示。如果是首個PRP,則Offset(偏移量)可能是非零的數據,另外,偏移量是32bits對齊的(即末尾兩位為0)。如圖6(b)所示,在PRP列表中的所有PRP項的偏移量都為0,也即是PRP指針指向頁面起始地址。

圖6 PRP和PRP列表的格式
如圖7(a)所示,當數據只有一個或兩個頁面的時候,就不需要使用PRP列表數據結構,直接PRP1和PRP2指向內存頁面。當一個命令指向的數據超過兩個內存頁面的時候,就需要使用PRP列表,圖7(b)所顯式的為使用PRP列表的數據結構。
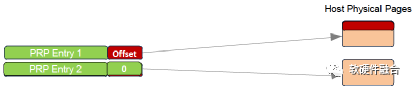
(a) 范例1:PRP直接指向內存頁面
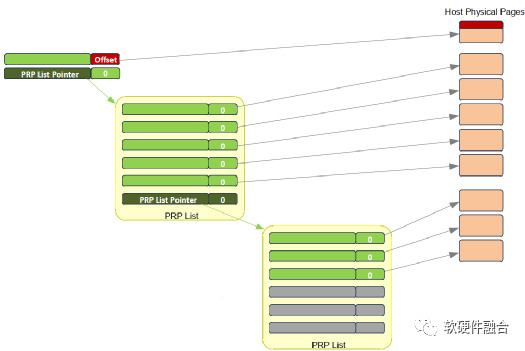
(b) 范例2:PRP列表指針,指向PRP列表,再指向內存頁面
圖7 PRP數據結構范例
d.散列聚合列表SGL
PRP每個鏈表指針最多指向一個頁大小的數據塊,即使若干個頁在內存連續放置,PRP也需要對應的多個PRP項。為了減少元數據規模,SGL不限制指針指向數據塊的大小,這樣連續的若干個頁的數據,只需要一個SGL項就可以標識。
NVMe中SGL的長度為16字節固定長度,其格式如圖8(a)所示,在最高的第15字節SGL描述符類型域和子類型域標識不同類型的SGL描述符,根據不同的描述符,字節14-0的格式各有不同。SGL描述符類型如圖8(b)所示。
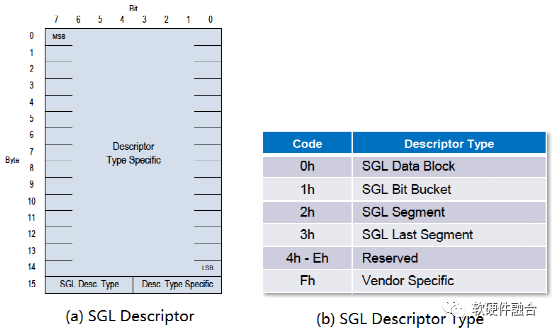
圖8 NVMe SGL數據格式
如圖9,NVMe SGL的數據結構是鏈表形式,SQ中的首個SGL段只有1項,為指向下一個SGL段的指針。下一個SGL段包含若干SGL數據塊描述符,SGL段的最后的一個SGL描述符為另一個SGL段指針,指向下一個SGL段。根據傳輸數據大小,在最后一個SGL 段中,所有的SGL描述符都是SGL數據塊描述符。
PRP只能指向單個內存頁,這樣,當要傳輸的數據塊非常大的時候,就需要非常多的PRP項。而SGL可以指向不同大小的數據塊,處于連續內存區域的多個數據塊只需要一個SGL描述符就可以標識。因此,一般情況下,SGL比PRP更高效,更節省描述符資源。
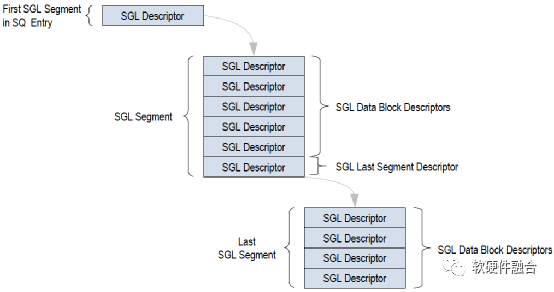
圖9 NVMe SGL數據結構范例
5 網絡存儲接口NVMeoF
NVMeoF(NVMe over Fabrics)定義了一種通用架構,該架構支持一系列基于NVMe塊存儲協議的存儲網絡系統。包括從前端存儲接口到后端擴展的大量NVMe設備或NVMe子系統,也包括訪問遠程NVMe設備和NVMe子系統所需的網絡傳輸系統。
如圖10所示,NVMeoF支持以太網、光纖和InfiniBand等不同的網絡傳輸介質。基于RDMA的NVMeoF,使用的是InfiniBand、RoCEv1/v2或iWARP。NVMeoF的主要目標是提供與NVMe設備的低延遲遠程連接,與服務器本地NVMe設備相比,增加的延遲不超過10μs。
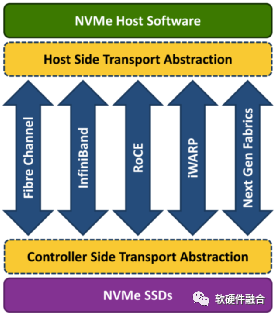
圖10 NVMe over Fabrics支持的網絡傳輸介質
利用NVMeoF技術,可以輕松構建由許多NVMe設備組成的存儲系統,它通過基于RDMA或光纖網絡實現的NVMeoF,構成了完整的NVMe端到端存儲解決方案。NVMeoF系統可以提供非常高的訪問性能,同時保持非常低的訪問延遲。
為了遠距離傳輸NVMe協議,理想的基礎網絡結構應具有以下特征:
可靠的基于信用的流量控制和傳輸機制。需要網絡能支持自動流量調節,從而提供可靠的網絡連接。基于信用的流量控制是光纖、InfiniBand和PCIe原生支持的功能。
優化的NVMe客戶端。客戶端軟件能夠直接與傳輸網絡之間發送和接收NVMe命令,不需要使用諸如SCSI之類比較低效的轉換層。
低延遲的網絡。網絡應該是針對低延遲優化過的,網絡路徑(包括交換機)端到端延遲不能超過10 μs。
能夠減少延遲和CPU使用率的硬件接口卡。接口卡支持直接內存注冊給用戶模式的應用程序使用,以便數據傳輸可以直接從應用程序傳遞到接口卡。
網絡擴展。網絡能夠支持擴展到成千上萬個設備,甚至更多。
多主機支持。該網絡應能夠支持多個主機同時發送和接收命令。這也適用于多個存儲子系統。
多端口支持。主機服務器和存儲系統應能夠同時支持多個端口。
多路徑支持。該網絡應能夠同時支持任何NVMe主機發起端和任何NVMe存儲目標端之間的多個路徑。
最多可達64K的獨立IO隊列以及IO隊列固有的并行性可以很好地與上述特征一起使用。每個IO隊列可同時支持64K個命令。另外,NVMe命令數量非常少,因此在各種不同的網絡環境中實現起來也非常的簡單高效。
NVMeoF協議大約90%與NVMe協議相同。這包括NVMe命名空間、IO和管理命令、寄存器和屬性、電源狀態、異步事件等。兩者的差異對比如表6所示。
表6 NVMe和NVMeoF對比
| 差異性 | NVMe(PCIe) | NVMeoF |
| 識別碼 | BDF信息 | NVMe合格名稱(NQN) |
| 設備發現 | 總線枚舉 | 發現和連接命令 |
| 排隊 | 基于內存 | 基于消息 |
| 數據傳輸 | PRP或SGL | 僅SGL,添加了密鑰 |
NVMe基于分層的設計:如果把NVMe傳輸映射到內存訪問和PCIe總線,則是通常所理解的NVMe;如果把NVMe傳輸映射到RoCE等網絡接口,基于消息傳輸和內存訪問,則是NVMeoF。
如圖11,在本地NVMe中,NVMe命令和響應映射到主機中的共享內存,可以通過PCIe接口訪問。但是,NVMeoF是基于節點之間發送和接收消息的概念構建的。NVMeoF通過把NVMe命令和響應封裝到消息,每個消息包含一個或多個NVMe命令或響應。
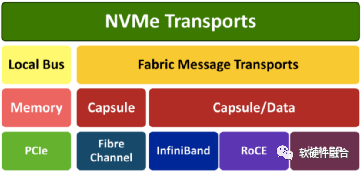
圖11 NVMeoF堆棧
對于NVMeoF來說,多隊列特征是支持的。通過使用類似NVMe的提交隊列和完成隊列機制來支持NVMe多隊列模型,但是將命令封裝在基于消息的傳輸中。NVMe IO隊列對(提交和完成)是為多核CPU設計的,這種低延遲的設計在NVMeoF也同樣支持。
當通過網絡將復雜的消息發送到遠端NVMe設備時,允許將多個小消息合并成一條消息發送,從而提高傳輸效率并減少延遲。如圖12,一條消息封裝了提交隊列項或完成隊列項、多個SGL、多組數據以及元數據等。每一項的內容與本地NVMe協議相同,但是封裝是將它們打包在一起,用以提高傳輸效率。
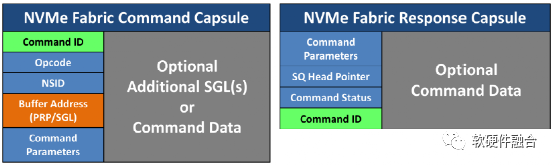
圖12 NVMeoF的命令和響應封裝
6 NVMe及NVMeoF總結
NVMe是為了高速非易失性存儲定制的存儲接口訪問協議,定向優化了存儲的主要性能指標:帶寬、延遲和IOPS。NVMe最重要的特征體現在:
面向高速存儲場景定制:NVMe是專門面向高速存儲場景定制的協議,因此充分考慮了塊存儲的特點,重點解決存儲性能的關鍵問題。
多隊列支持:多隊列不僅僅充分利用了硬件的并行處理能力,同時,也充分的利用了多核系統多線程并行的特點,最大化的優化了NVMe的性能。
標準化:NVMe是得到廣泛應用的PCIe SSD接口標準,各大主流操作系統支持統一的標準NVMe驅動。
NVMeoF集成現有的NVMe和高速低延遲傳輸網絡的技術,提供一整套整合的遠程高速存儲系統解決方案,非常適應于大規模存儲集群的應用場景。
原文標題:高速的、標準化的存儲接口NVMe
文章出處:【微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
存儲器
+關注
關注
38文章
7527瀏覽量
164169 -
接口
+關注
關注
33文章
8687瀏覽量
151674 -
設備
+關注
關注
2文章
4539瀏覽量
70798
原文標題:高速的、標準化的存儲接口NVMe
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳細了解JTAG接口
Xilinx FPGA NVMe Host Controller IP,NVMe主機控制器
在Xilinx ZCU102評估套件上啟用NVMe SSD接口
詳細了解下ups的相關計算
詳細了解一下STM32F1的具體電路參數
基于 NVMe 接口的帶 exFAT 文件系統的高速存儲 FPGA IP 核演示
通過 iftop、 nethogs 和 vnstat 詳細了解你的網絡連接狀態
NVMe標準更新定義了一個軟件接口

一文詳細了解OpenHarmony新圖形框架
新品推薦|40G光纖接入的NVME存儲模塊

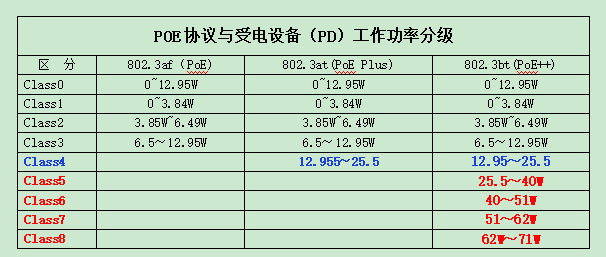
帶您一起詳細了解IEEE802.3bt(PoE++)的有關特點
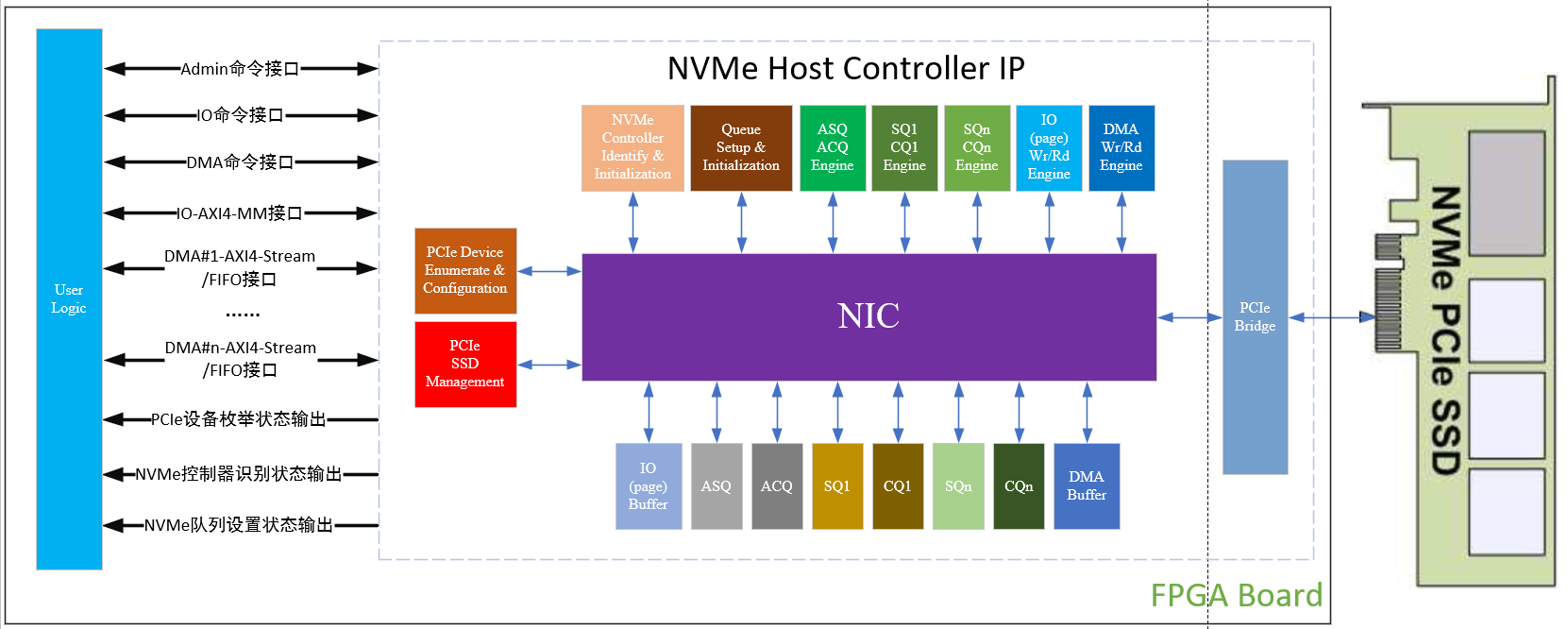
Xilinx FPGA NVMe控制器,NVMe Host Controller IP
一文帶你詳細了解工業電腦

m2接口sata和nvme怎么區分
一文詳解 ALINX NVMe IP 特性





 工商網監
工商網監
評論