 基于深度學習構造DL-SR網絡結構和實現方法
基于深度學習構造DL-SR網絡結構和實現方法
縮放算法,尤其是放大算法,將原先沒有的像素,通過一定的算法計算出來。這些算法常用的有最近鄰域算法,雙線性插值算法,雙三線性插值算法等。基于插值的算法可以有效考慮插值范圍內的信息,易于硬件實現,通過合理設計定點化可以實現充分的硬件并行。但是領域信息,同樣限制了大部分插值算法不能充分考慮原始圖像的“高層語義”信息,這里的語義信息是指圖像含有的紋理模式,例如交疊、彎曲等。
本節將介紹基于深度學習(Deep learning,DL)的縮放算法(DL-SR),可以借助模型更大的參數映射能力、感知野與反向傳播,實現對低分辨率和高分辨率的關聯強化。同時,考慮訓練目標和結構差異,DL-SR還可以實現在分辨率提升的同時轉換顯示效果。但是基于深度學習的方法也存在存儲與硬件資源消耗都比插值方法更大的趨勢,該趨勢在對效果的不懈追求中越發明顯。 雖然DL呈現模塊化和集成化的趨勢,但是DL-SR與其他基于DL的CV任務還是有明顯的區分。DL-SR一方面在效果上展現了比經典插值算法更大的改進,另一方面也拓展了SR的應用領域,目前DL-SR仍然是一個開放課題,諸多大型科技公司投入了資源進行研究。
1.基于深度學習的縮放算法基礎
考慮到圖像紋理和變化的多樣性,基于插值的縮放算法多采用基于歐氏距離生成的權重,其模板仍有提升的空間。在DL模塊化之后,Dong等人通過建模發現深度學習的算子通過組合,可以形成對經典方法的近似[1]。通過通道擴展實現對淺層特征的提取,利用卷積與非線性算子(relu,leaky relu等)實現對特征的重映射,最后疊加上采樣層實現對特征的融合重構,如下圖所示。
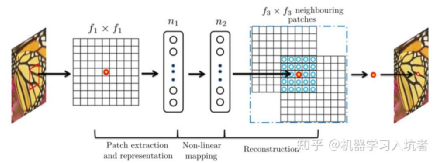
圖1
這其中前兩者正是DL擅長的領域,DL的通道數可以簡單擴展到256通道,在壓縮feature size的情況下,部分可以達到1024。特征重映射在DL模塊化的之后通過重復實現,并且在前期DL任務中已經展現了正相關的能力。經過前兩步的充分“膨脹”與“扭曲”,重構過程在DL-SR中通過特征折疊或者反卷積等操作即可實現。
構造DL-SR網絡結構完成了DL-SR算法的第一步,下一步是確定訓練數據集。前期基于SRCNN/FSRCNN/VDSR等算法都是基于通用數據集的實現方案,比如采用BSD10。如何確定DL-SR的目標,DL是一種基于學習的模式識別方法。最直接的方法是引入有監督學習,通過構建低分辨率與高分辨率對DL-SR網絡進行訓練,通過不同目標函數使得網絡具備不同的重建特性。例如公式1基于范數的重建目標函數,意在構建和目標高分辨率一致的輸出。目標在于獲取映射網絡結構f,使得f處理低分辨率輸入x得到的結果與高分辨率源具有最小的誤差。
同時,也出現了基于重建主觀質量的網絡結構[2],例如公式2。公式2包含兩個模塊。第一部分為內容損失,詳細描述如公式3,類似于公式1為了實現像素級的對齊(區別在于公式3采用了MSE損失)。

第二部分采用特征對齊,即對抗損失,通過要求重構圖像與源高分辨率圖像通過同一深度網絡映射之后,獲取的特征仍具有一致性,一方面這種映射可以強化處理圖像的高層語義特征,例如圖像的紋理豐富程度而非單點的紋理高低,另一方面弱化單點對應關系,因為這種對應在多數據集的情況下網絡訓練通常會收斂到各類失真的均值處,這點在弱紋理情況下尤為明顯。如下圖所示,可以看出相比SRResNet(第一列,采用基于公式1的目標函數訓練結果)與基于對抗訓練的網絡(第2-4列)在紋理清晰程度上有顯著提升。
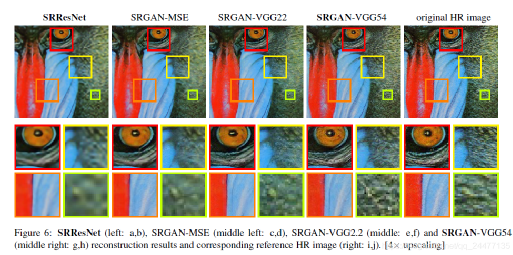
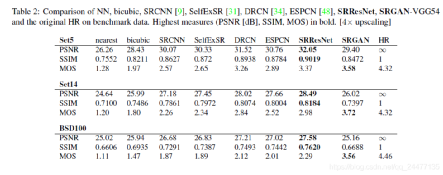
通過不同訓練目標的引導,通常DL-SR會產生不同的效果,如上圖所示,展示了幾種不同算法的測試效果,可以看出在采用了更深層語義特征之后,圖像的細膩程度得到提升,尤其在弱紋理區域的主觀質量更好。額外需要注意的是,此類紋理性能提升并非基于點對點的逼近。實際上,在采用基于逐點匹配的指標中,添加特征一致性通常會導致PSNR的下降。這個結論在下表中也可以得到證實。
DL-SR在性能上的提升是有代價的,主要體現在兩個方面。一方面是模型訓練和數據獲取對應的隱形資源,另一方面是部署資源需求,包括計算資源和存儲資源。經典插值算法易經確定抽頭系數m*n和插值范圍,m*n的乘加資源與m行的存儲資源即可實現流水處理,但是DL-SR通常需要GFlops的算力,同時考慮帶寬需求,還需要匹配MB級別的存儲資源。
2.DL-SR的性能提升
雖然DL-SR有著對經典方法在主客觀性能上的優勢,但這些優勢還未能滿足用戶需求,目前尚存相當的提升空間,尤其是面對超高清視頻處理和實際應用的情況。
首先是關于如何分析數據集與網絡結構是否有偏的問題。自然圖像,尤其是超高分辨率圖片,通常包含大面積的平滑區域,導致紋理信息的分布不均勻,此外,考慮深層圖像在提升感知野的同時會壓縮相鄰像素空間的關聯性,這些均會導致圖像恢復效果的退化。(**)提出了均衡網絡,嘗試從訓練數據提取、網絡結構設計等方面提升DL-SR性能,在降低算力需求的同時提升了主客觀質量。但是關于DL-SR的訓練Patch獲取與網絡結構的設計,在學界仍不斷有新思路迸發。
在處理實際應用過程中,通常無法要求確定放大倍率的情況,尤其涉及當前短視頻和異形屏的處理顯示需求中,需要完成非整數倍率的方法。另外考慮目前的強交互趨勢,也出現了連續放大的場景,例如在拍攝圖像預覽過程中,需要實現對局部信息的放大。如下圖所示,目前常用的上采樣算法有兩種,一種是采用空間深度轉換,另一種是用反卷積。這兩種方法都使用相同卷積核處理全部圖像,通常只能實現整數倍率方法。
(**)提出采用基于輸出的像素卷積核生成方法以處理無極放大問題,這種方法雖然解決了高倍率像素生成問題,但是面臨感知野和算力需求,有著與輸出分辨率強相關的缺陷。有效地實現基于無極放大的DL-SR是充分釋放其性能的重要課題。
另外,對特征融合方法的改進也是眾多學者關注的核心要素,從最初的級聯型卷積疊加到后續引入殘差塊,以及近期的多重殘差塊和多尺度殘差模型,都為寄希望于提出可以滿足所有場景的特征映射模型。但是在優化提升過程中,部署過程需要關注的信息必須包括算力因素,超過100個卷積層的深度網絡,幾乎難以在移動端實現實時2.5K視頻的SR處理。
最后,提升DL-SR的性能還涉及對評估方式的改進。比較明顯的是對主客觀質量的差異分析,通常以PSNR或MSE為導向的主觀指標,在處理弱紋理區域難以獲得理想的效果。而引入主觀質量的方式包括引入GAN網絡或者主觀指標,例如LPIPS等算子。另外,近期引DL進行無參考圖像質量評價也為重建目標提供了思路,但是考慮其通用性,在本書就不再過度引申了。
3.DL-SR與High-level CV的區別
基于DL-SR的提出落后于High-level的CV任務,這一方面可以讓基于識別或者分類的DL骨干網絡可以快速進入DL-SR研究,極大提升了DL-SR的性能,但是另一方面在前期也導致了對二者差異性的忽略,最直接的差異體現在High level任務中起作用的方法,在DL-SR中效果并不十分明顯。例如疊加深度映射與效果提升并無直接對應關系,BN層對特征空間充分映射和效果出現負相關等。這些差異一方面體現在超解析輸出更關注圖像的區域信息,深度網絡必須引入更多的跳連層,以保證淺層語義的有效性,同時為保證訓練穩定性,目前主流算法開始從直接訓練輸出變為訓練SR輸出與bicubic等的插值。BN層可以映射為對特征空間的歸一化,等效為對特征空間的自適應尺度與偏移,這與SR的像素一致性發生背離,所以簡單套用High-level的經驗在DL-SR中并不可行。
另外,隨著如何實現像素級的精確,而非使用FC層對信息進行融合也是一種典型差異,這體現為對SR任務而言,整體相似性并不能滿足用戶需求,而對大部分分類任務,保證分類概率超出同類,并達到一定置信度即可實現目標。所以,并非low-level任務可以等價為易實現。
4.DL-SR的幾點思考與未來
從SRCNN提出,到現在DL-SR已經成為淺層CV任務的典型代表,在CVPR和ECCV都提出了對應的競賽單元,包括NTIRE和PIRM。二者具有不同的側重,但都為DL-SR性能提升和落地加速。目前DL-SR的發展方興未艾,對未來趨勢,此處做一些推測,以饗讀者。
首先是,如何獲取實際關聯的有監督訓練數據。目前基于DL-SR的有監督數據集基本來自于NTIRE,該數據集的低分辨率來自于Bicubic下采樣,雖然Bicubic類似于點擴散函數(PSF)可以模擬部分低分辨率數據生成方式,但是實際低分辨率數據的質量退化,通常包含更多退化因素,例如CCD響應缺陷,電子噪聲和圖像前后處理等。后期也提出了real-SR采用變焦獲取實拍數據集,但是此類數據集一方面僅限于室內,難以處理室外運動場景,另外考慮SR任務需要像素級對齊,所以LR與HR的對齊問題仍限制了其推廣。
其次是,效率與效果的平衡,如前面三節多次提到的算力問題一致困擾了DL-SR算法的落地,目前已有的高效算法通常伴隨了性能的明顯退化,使得當前在終端僅能部署有限的處理能力。
另外,還需要指出的是,隨著DL-SR的性能提升,其對多媒體處理也起到了明顯的正面效果。此處舉兩個例子,第一是將SR引入codec,在相同碼率下,低分辨率視頻質量明顯優于直接編碼高分辨率源。采用基于SR+codec的處理思路,可以在數據供給端編碼低分辨率視頻,在解碼端或者使用端疊加DL-SR 以提供更好的視覺體驗。這種基于SR-Codec的變化,帶來編解碼思路的優化。第二是基于視覺SR的提升,優化了SoC的負載。Nvidia通過采用DLSS實現了基于DL的SR算法,使得高分辨率需求遷移至CuDa側,降低Shader的負載,實現更高幀率。
審核編輯:郭婷
-
分辨率
+關注
關注
2文章
1071瀏覽量
42001 -
深度學習
+關注
關注
73文章
5512瀏覽量
121410
原文標題:淺談基于深度學習的縮放算法
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡結構搜索有什么優勢?
labview實現深度學習,還在用python?
TVM整體結構,TVM代碼的基本構成
什么是深度學習?使用FPGA進行深度學習的好處?
環形網絡,環形網絡結構是什么?
基于神經網絡結構在命名實體識別中應用的分析與總結

概率模型的大規模網絡結構發現方法

卷積神經網絡結構
如何優化PLC的網絡結構?






 工商網監
工商網監
評論