 深度學習在各種計算機視覺任務上都取得了重大的突破
深度學習在各種計算機視覺任務上都取得了重大的突破
智源導讀:近年來,深度學習在各種計算機視覺任務上都取得了重大的突破,其中一個重要因素就是其強大的非線性表示能力,能夠理解圖像更深層次的信息。本文針對CV+Deep Learning未來的走向進行了展望,其中包括CV與Learning之間的關系、CV面向不同場景以及Learning面向不同場景等多方面的延展。
01
「Learning-based CV」to 「CV-based Learning」
得益于神經網絡較強的學習能力,很多視覺任務都被丟入一個黑盒中,然而神經網絡直接從像素上對場景進行感知是不夠的。對于具體的任務,我們需要利用CV中的原理和技術點對其進行解剖和建模,然后再利用深度學習中的網絡架構/工具進行相應的特征提取與任務決策。
這里舉個例子,CV中有一個很具有挑戰性的任務是3D from Monocular Vision,即從單目圖像進行三維重建與感知。目前很多方案都是通過強監督學習方式直接對深度信息進行預測或者直接在2D圖像上進行3D任務。 在計算機視覺中,我們知道,從三維世界坐標系到二維相機坐標系是經過了一個透視變換的,因此不同深度的物體才被投影到了同一個平面上(如圖1所示)。如果利用這種變換關系去顯示地指導神經網絡學習或者利用可逆網絡去學習這種變換關系,會更加貼合真實場景中的應用。如Marr Vision所描述的,對于一個圖像/場景的感知需要經過"2D-2.5D-3D"的過程,然而在Learning-based CV中,諸如此類的視覺原理都被簡單粗暴的2D Convolutional Kernel給卷掉了。因此,CV + Deep Learning整個體系的后續發展應該會從Learning-based CV轉到CV-based Learning,對于不同的視覺任務融入相應的CV原理并建模Learning方式。
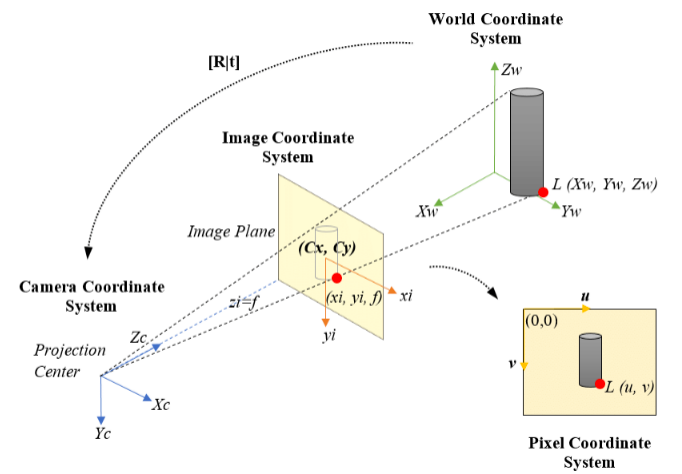
圖1:Ideal Projection of a 3D Object on A 2D Image
02
「Clean CV」to「Wild CV」
目前熱門的視覺任務如目標檢測、語義分割、深度估計等都已被“卷er”們刷爆各大榜單,其中所用到的大多數數據集都是非常干凈的。然而在真實場景中,常見的噪聲如徑向畸變、光照、運動模糊、雨霧等都會通過改變物體的紋理結構而改變其語義特征,因此造成算法的泛化性不強、換個數據集就崩的現象。一個很直接的解決方案是Image Restoration + CV Task,即在做具體CV任務之前直接還原一個干凈的場景。但是有一點需要注意的是目前Image Restoration很多都是基于圖像生成式,在去噪的過程中常常會引入新的圖像信息,這種顧此失彼的操作對很多下游任務是不能接受的。 對人來說,我們的日常視覺任務很少經過Image Restoration這一步,而是直接在存在各種噪聲的情況下進行感知與決策。其中一個最主要的原因是我們已經見過各種場景下的相同物體,即人通過視覺系統所提取到的特征對于噪聲具備較好的不變性。相比之下,目前Clean CV所做的事情可能更多關注的是提取對具體任務有幫助的特征,而這種Feature Bias會影響算法的泛化功能。
03
「Single-Frame CV」to「Sequence CV」
Video Understanding是一個未來可期的方向,近些年興起的“小視頻”等新消遣方式大大增加了該方向的人才需求,一些大廠如阿里、騰訊等也在悄然布局。先拋開工業界需求不說,來聊一些具體的技術點。 視頻相較于圖像而言具有一個絕佳的優勢——時序性。這一優勢產生的前后幀相關性能夠促使弱監督學習和自監督學習等得以更好地應用,人類也是在這樣一個動態的世界里利用僅有的標簽信息不斷地學習與認知。同時,在Sequence CV中,Frame之間的“遷移學習”也是值得探索的,即如何利用少量前序幀中學習到的知識去啟發大量的后序幀。對于視頻的海量數據對顯卡資源產生的負擔,視頻濃縮(Video Synopsis)等技術可能會帶來新的突破。
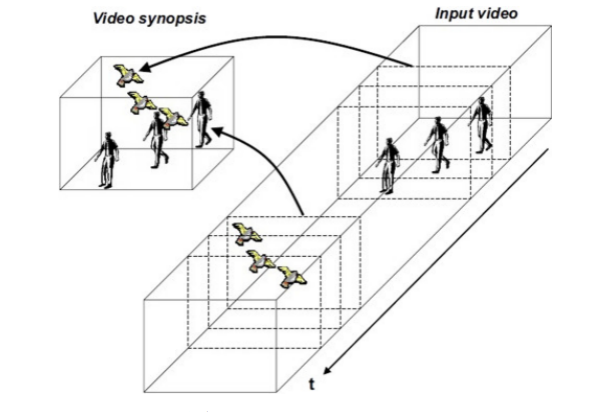
圖2:Video Synopsis
04
「General Pre-training CV」to「Specific Pre-training CV」
眾所周知,Pre-training on ImageNet在CV中是一個通用且有效的策略。但是,一些工作表明這種策略對不同CV任務的作用是不同的,原因大致有兩點:Data Gap和Task Gap。首先在ImageNet數據集中,大多數圖片都是無噪聲的,并且場景較為單一,前景、背景易于剝離,這與其他不同的數據集存在數據上的差異;其次,ImageNet所面向的主要任務是圖像分類,所以預載入模型中的參數大多與益于分類的特征相關,對于一些位置信息要求更加精細的任務卻啟發有限。 那么我們如何學習一個更好的Prior去啟發后續視覺任務呢?再來聯系一下人類的學習過程,對于不同的任務/課程,我們是有特定的Warm-up階段。比如在學習乒乓球和籃球的過程中,對于乒乓球一開始我們需要練習的是簡單的推擋和發球動作,而對于籃球,我們則是在一開始練習基礎的運球和投籃動作,這兩個Pre-training顯然是不同的。回到CV中,對于不同任務比如深度估計和語義分割,也應該給予不同且更加精細的預學習課程:深度估計——三維成像先驗,語義分割——場景類別先驗等。
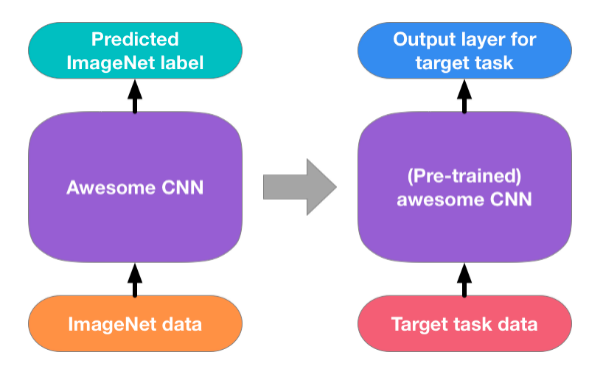
圖3:Pre-training on ImageNet
05
「Learning-ImplicitCV」to「Learning-Friendly CV」
如何評價一個任務是否易于網絡學習,或者說這個任務是否對神經網絡學習友好?很直觀的一點就是去看圖像特征與學習目標之間有無顯示關聯。例如在目標檢測中,圖像特征與Bounding Box之間的關聯是肉眼可見的。而對于另一些任務,例如從一幅圖像中直接預測對應拍攝相機的相機參數,那么圖像特征與相機參數之間的關聯就顯得格外隱式了。此外,學習目標的同質性(Homogeneity)和異質性(Heterogeneity)也會影響神經網絡的學習。如果對相機參數進一步細化的話,我們可以發現其中還包含了相機光心、焦距、畸變參數等不同的參數,這些參數之間的異質性以及相差甚遠的取值范圍會很容易導致回歸的不平衡問題。 相比之下,Bounding Box中均為描述位置信息的頂點且取值范圍相近,那么我們就可以說學習Bounding Box對神經網絡是友好的。后續的Center-based目標檢測又進一步優化了所學習的目標表示。從顯示性與同質性這兩點出發,我個人在學習相機參數這一個小點上提出了一個Learning-Friendly Representation(如下圖所示),去代替傳統的隱式和異質的相機參數,具體細節可參考論文A Deep Ordinal Distortion Estimation Approach for Distortion Rectification (IEEE TIP 2021)。除了相機參數,CV中還存在很多對神經網絡并不是很友好的學習目標,相信后續工作會做好CV與神經網絡之間的Trade-off,不會讓神經網絡太過為難。
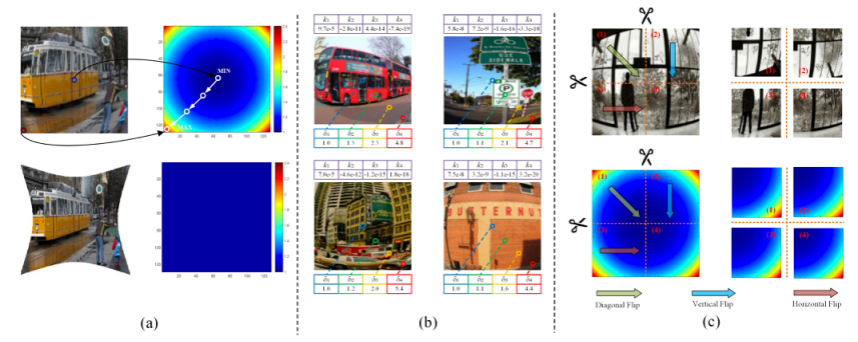
圖4:A Learning-friendly Representation for the Camera Intrinsic Parameters 綜上,近年CV + Deep Learning雖在眾多任務上得以革新,但二者相互作用的關系仍需要根據不同任務進行省視,而且面向Wild、Dynamic、Specific、Learning-Friendly等場景的進階之路道阻且長。 作者簡介:廖康,北京交通大學信息科學研究所2018級博士生,師從林春雨教授,讀博期間主要從事圖像生成、圖像修復、3D視覺等研究,相關成果發表至IEEE Transactions on Image Processing (TIP), IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Transactions on Intelligent Transportation Systems (TITS), IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)等會議及期刊。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101075 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46086 -
深度學習
+關注
關注
73文章
5512瀏覽量
121436
原文標題:計算機視覺未來走向:視頻理解等5大趨勢詳解
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Anthropic在人工智能領域取得重大突破
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺在人工智能領域有哪些主要應用?
深度學習在工業機器視覺檢測中的應用
深度學習在視覺檢測中的應用
計算機視覺的主要研究方向

機器視覺網卡:連接攝像頭和計算設備之間的橋梁

計算機視覺的十大算法






 工商網監
工商網監
評論