 關于HDFS的概述及組成與架構詳解
關于HDFS的概述及組成與架構詳解
一、 HDFS簡介
1.1 HDFS的概述
HDFS是基于 流數據 訪問模式的 分布式文件系統 ,其設計建立在 “一次寫入、多次讀取” 的基礎上,提供高吞吐量、高容錯性的數據訪問,能很好地解決海量數據的存儲問題。
流數據 是指數千個數據源 持續生成 的數據,可以理解為隨時間延續而 無限增長 的動態數據集合。
通俗點說,如果把數據比如成一個水庫,那么流進去的水,就是流數據(就像我們聽的音樂,屬于音樂流;而看到的文字、圖片這些較為固定的,一次性下載的,形成不了流)。
在Hadoop生態圈中,HDFS屬于底層基礎,負責存儲文件。
1.2 HDFS的優點
HDFS的優點:
高容錯性。提供了容錯和恢復機制,副本丟失后,自動恢復。
高可靠性。數據自動保存多個副本,通過多副本提高可靠性。
適合大數據處理。可以處理超大文件,比如 TB級甚至PB級 的文件。
適合批處理。移動計算而非移動數據;數據位置暴露給計算框架。
支持流式數據訪問。一次性寫入,多次讀取(一個數據集一旦生成,就會被復制分發到不同的存儲節點,各節點可以進行讀取/訪問);保證數據一致性。
低成本運行。可以運行在低成本的硬件之上。
…
HDFS 默認保存 3 份副本。
第一個副本:放置在 上傳文件 的數據節點(第一個副本如果是在 集群外 提交,則隨機挑選一個 CPU 比較空閑 、 磁盤不太滿 的節點);
第二個副本:放置在與 第一個副本 不同 的機架的節點上;
第三個副本:放在與 第二個副本 相同 的機架的其他節點上。
1.3 HDFS的缺點
HDFS的缺點:
不適合處理 低延遲 的數據訪問。比如用戶 要求時間比較短 的低延遲應用(主要處理高數據吞吐量的應用)。
不適合處理 大量的小 文件。會造成尋址時間超過讀取時間;會占用NameNode大量內存,因為NameNode把文件系統的元數據存放在內存中(文件系統的容量由NameNode的大小決定),小文件太多會消耗NameNode的內存。
不適合 并發寫入。一個文件只能有一個寫入者,HDFS暫不支持多個用戶對同一個文件的寫操作。
不適合 任意修改 文件。僅支持append(附加),不支持在文件的任意位置進行修改。
…
二、 HDFS的組成與架構
HDFS的組成架構圖及各部分功能如下所示:
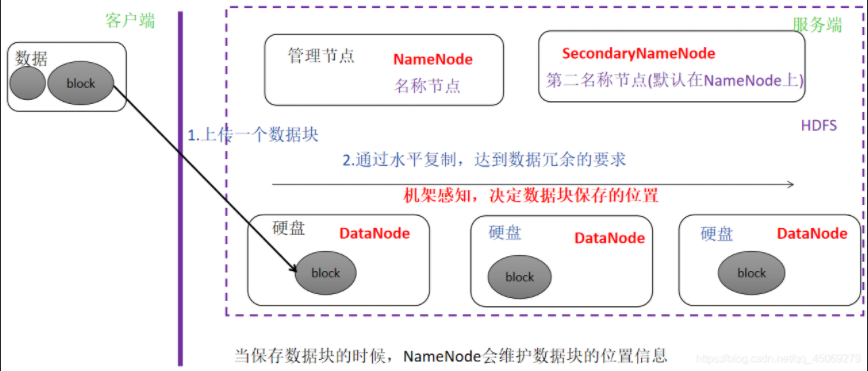
2.1 NameNode節點
當用戶訪問數據文件時,為了保證能夠讀取到每一個數據塊, HDFS有一個專門 負責保存文件屬性信息的節點,這個節點就是 NameNode 節點(即 名稱節點 )。
2.1.1 節點職責
NameNode節點 是HDFS的管理者,負責保存和管理HDFS的元數據。
其職責有以下三個方面:
① 管理維護HDFS的命名空間
NameNode管理HDFS系統的命名空間,維護文件系統樹以及文件系統樹中所有文件的元數據。管理這些信息的的文件分別是 edits(操作日志文件) 和 fsimage(命名空間鏡像文件) 。
editlog(操作日志):在NameNode啟動的情況下,對HDFS進行的各種操作進行記錄。(HDFS客戶端執行的所有操作都會被記錄到editlog文件中,這些文件由edits文件保存)
fsimage:包含HDFS中的元信息(比如修改時間、訪問時間、數據塊信息等)。
② 管理DataNode上的數據塊
負責管理數據塊上所有的元數據信息(管理DataNode上數據塊的均衡,維持副本數量)。
③ 接收客戶端的請求
接收客戶端文件上傳、下載、創建目錄等的請求。
2.2 DataNode節點
HDFS首先把大文件切分成若干個小的數據塊,再把這些數據塊寫入不同的節點,這個 負責保存文件數據的節點就是 DataNode 節點(即 數據節點 )。
2.2.1 節點職責
DataNode節點 負責存儲數據,把Block(數據塊)以Linux文件的形式保存在磁盤上,并根據Block標識和字節范圍來讀寫塊數據。
其職責有以下三個方面:
① 保存數據塊
一個數據塊會在多個DataNode進行冗余備份(在某一個DataNode最多只有一個備份)。
② 負責客戶端對數據塊的IO請求
在客戶端執行寫操作時,DataNode之間會相互通信,保證寫操作的一致性。
③ 定期和NameNode進行心跳通信,接受NameNode的指令
如果NameNode節點10分鐘沒有收到DataNode的心跳信息,就會將其上的數據塊復制到其他DataNode節點。
因此,NameNode節點上并不會永久保存DataNode節點上的數據塊信息,而是通過與DataNode節點心跳聯系的方式,來更新節點上的映射表,以此減輕負擔。
問題:HDFS數據塊默認大小為128M(Hadoop2.2之前為64M),將HDFS的數據塊設置得很大的目的是什么?(傳統數據塊只有512個字節)
答:為了減少尋址開銷,讓HDFS的文件傳輸時間由傳輸速率決定(如果塊設置得足夠大,從磁盤 傳輸數據的時間 會明顯大于 定位這個塊開始位置 所需的時間)。
2.3 SecondaryNameNode節點
HDFS有一個定期創建命名空間的檢查點(CheckPoint)操作的節點,也就是SecondaryNameNode節點(即 第二名稱節點)。
出于可靠性考慮,SecondaryNameNode節點與NameNode節點通常運行在不同的機器上,且SecondaryNameNode節點與NameNode節點的內存要一樣大。
(如果想了解 SecondaryNameNode 的工作流程,可以參考這篇文章:淺析 SecondaryNameNode 的工作流程 )
問題:一般情況下,一個集群中的SecondaryNameNode節點也是只有一個的原因是什么?
答:因為如果多的話,會增加NameNode的壓力,使其忙于元數據的傳輸/接收、日志的傳輸/切換,從而導致性能下降;同時,NameNode節點也不支持做并發檢查點。
2.3.1 節點職責
SecondaryNameNode節點 定期把NameNode的 fsimage 和 edits 下載到本地,再將它們加載到內存并進行合并,最后把合并后新的 fsimage 返回NameNode (這個過程稱為檢查點)。
經典問題:NameNode與SecondaryNameNode有沒有關系?

SecondaryNameNode節點的工作流程可以參考這篇文章:
其職責有以下兩個方面:
① 防止edits過大
定期合并 fsimage 和 edits 文件,使 edits 大小保持在限制范圍內。這樣做減少了重新啟動NameNode時合并 fsimage 和 edits 耗費的時間,從而減少了NameNode啟動的時間。
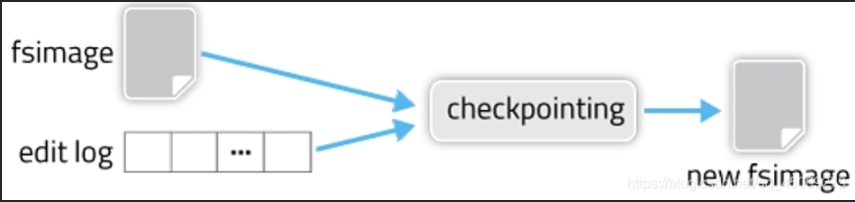
② 做冷備份
對一定范圍內數據做快照性備份,在NameNode失效時能恢復部分 fsimage 。
好了,HDFS 及其組成框架介紹完成。
如果想進一步了解 HDFS 的工作機制,可以參考這篇文章:圖文詳解 HDFS 工作機制及其原理 。
編輯:lyn
-
HDFS
+關注
關注
1文章
30瀏覽量
9626
發布評論請先 登錄
相關推薦
百問MQTT協議分析 - MQTT簡述及協議報文格式組成
buck電路的組成元件詳解 buck電路與線性穩壓器的區別
主流芯片架構包括哪些類型
溫度振動變送器的概述及功能介紹
行程開關概述及應用介紹
SSD架構與功能模塊詳解
深度神經網絡概述及其應用

信號源的組成以及應用方案詳解





 工商網監
工商網監
評論