
01研究背景及動(dòng)機(jī)
近些年,Transformer[1]逐漸成為了自然語(yǔ)言處理中的主流結(jié)構(gòu)。為了進(jìn)一步提升Transformer的性能,一些工作通過(guò)引入額外的結(jié)構(gòu)或知識(shí)來(lái)提升Transformer在特定任務(wù)上的表現(xiàn)。盡管如此,過(guò)參數(shù)化(over-parameterization)和過(guò)擬合(overfitting)一直是Transformer中的一個(gè)顯著問(wèn)題。作為一種正則化技術(shù),Dropout常被用來(lái)緩解模型的過(guò)擬合問(wèn)題[2]。和引入額外結(jié)構(gòu)或知識(shí)的工作相比,dropout的一個(gè)優(yōu)勢(shì)是不需要額外的計(jì)算開銷和外部資源。因此,本文的出發(fā)點(diǎn)在于,能否通過(guò)融合不同的dropout技術(shù)來(lái)進(jìn)一步提升Transformer的性能甚至達(dá)到state-of-the-art效果?
為此,我們提出UniDrop技術(shù),從細(xì)粒度到粗粒度將三種不同層次的dropout整合到Transformer結(jié)構(gòu)中,它們分別為feature dropout、structure dropout和data dropout 。Feature dropout (FD),即傳統(tǒng)的dropout技術(shù)[2],通常應(yīng)用在網(wǎng)絡(luò)的隱層神經(jīng)元上。Structure dropout (SD)是一種較粗粒度的dropout,旨在隨機(jī)drop模型中的某些子結(jié)構(gòu)或組件。Data dropout (DD)作為一種數(shù)據(jù)增強(qiáng)方法,通常用來(lái)隨機(jī)刪除輸入sequence的某些tokens。在UniDrop中,我們從理論上分析了這三層dropout技術(shù)在Transformer正則化過(guò)程中起到了不同的作用,并在8個(gè)機(jī)器翻譯任務(wù)上和8個(gè)文本分類任務(wù)上驗(yàn)證了UniDrop的有效性。
02UniDrop
2.1Transformer結(jié)構(gòu)
UniDrop旨在提升Transformer的性能。在UniDrop中,feature dropout和structure dropout的使用與網(wǎng)絡(luò)結(jié)構(gòu)密切相關(guān)。因此,我們簡(jiǎn)單回顧Transformer的網(wǎng)絡(luò)結(jié)構(gòu)。
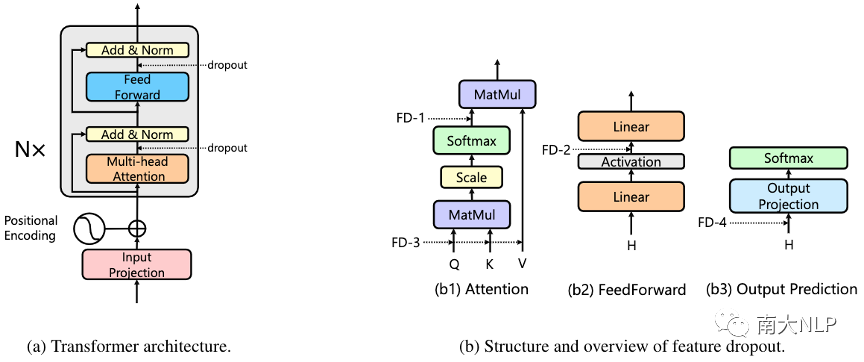
圖1:標(biāo)準(zhǔn)Transformer結(jié)構(gòu)和Feature Dropout
如圖1(a)所示,Transformer由多個(gè)相同的block堆疊而成,每個(gè)block包含兩個(gè)sub-layer,分別為multi-head self-attention layer和position-wise fully connected feed-forward layer,每個(gè)sub-layer后都使用了殘差連接和層正則(Add&Norm)。
Multi-head Attention:Multi-head attention sub-layer包含多個(gè)并行的attention head,每個(gè)head通過(guò)帶縮放的點(diǎn)乘attention將query Q和鍵值對(duì)K、V映射乘輸出,如下式所示:
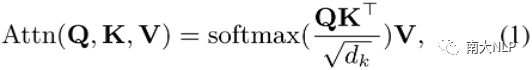
多個(gè)head的輸出最終被拼接在一起并做線性映射作為最終的multi-head attention輸出。
Position-wise Feed-Forward:這一層主要包含兩個(gè)線性映射和一個(gè)ReLU激活函數(shù):
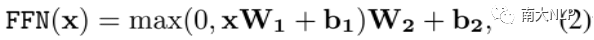
2.2Feature Dropout
如前所述,F(xiàn)eature Dropout (FD)即傳統(tǒng)的dropout技術(shù)[2],可以以一定的概率隨機(jī)抑制網(wǎng)絡(luò)中的某些神經(jīng)元。實(shí)際上,在標(biāo)準(zhǔn)的Transformer實(shí)現(xiàn)中,每個(gè)sub-layer后都默認(rèn)配置了dropout。除此之外,Transformer也在multi-head attention和feed-forward network的激活函數(shù)層添加了dropout,本文將探索它們對(duì)Transformer性能的影響:
FD-1 (attention dropout):根據(jù)公式(1),在multi-head attention中,我們可以獲得attention權(quán)重A=QKT,feature dropout FD-1被應(yīng)用在attention權(quán)重A上。
FD-2 (activation dropout):FD-2被應(yīng)用在feed-forward network sub-layer兩層線性變換間的激活函數(shù)上。
除了上面已有的feature dropout,我們?cè)陬A(yù)實(shí)驗(yàn)中發(fā)現(xiàn)Transformer仍有過(guò)擬合的風(fēng)險(xiǎn)。因此,我們額外提出兩種feature dropout添加到Transformer結(jié)構(gòu)中:
FD-3 (query, key, value dropout):FD-1直接應(yīng)用在attention權(quán)重A上,表示token i和token j之間的connection有可能被drop,一個(gè)更大的FD-1值意味著更大的概率失去sequence中一些關(guān)鍵的connection。為了緩解這種風(fēng)險(xiǎn),我們?cè)赼ttention之前的query Q、key K和value V上分別添加了dropout。
FD-4 (output dropout):我們?cè)趕oftmax分類的線性映射前也添加了dropout。具體而言,對(duì)sequence2sequence任務(wù),我們將FD-4添加到Transformer decoder中,對(duì)于文本分類任務(wù)我們將FD-4添加到Transformer encoder中。
2.3Structure Dropout
為了提升Transformer的泛化性,之前的工作已經(jīng)提出了兩種Structure Dropout (SD),分別是LayerDrop[3]和DropHead[4]。DropHead通過(guò)隨機(jī)舍棄一些attention head,從而防止multi-head attention機(jī)制被某些head主導(dǎo),最終提升multi-head attention的泛化性。相比之下,LayerDrop是一種更高級(jí)別的結(jié)構(gòu)dropout,它能隨機(jī)舍棄Transformer的某些層,從而直接降低Transformer中的模型大小。通過(guò)預(yù)實(shí)驗(yàn)分析,我們將LayerDrop添加到我們的UniDrop中。
2.4Data Dropout
Data Dropout (DD)以一定的概率p隨機(jī)刪除輸入序列中tokens。然而,直接應(yīng)用data dropout很難保留原始高質(zhì)量的樣本,對(duì)于一個(gè)長(zhǎng)度為n的sequence,我們保留住原始sequence的概率為(1-p)n,當(dāng)n較大時(shí),這個(gè)概率將會(huì)非常低。失去原始高質(zhì)量樣本對(duì)很多任務(wù)都是不利的。為了保留原始高質(zhì)量的樣本,同時(shí)又能利用data dropout進(jìn)行數(shù)據(jù)增強(qiáng),我們?cè)赨niDrop中提出了一個(gè)2-stage data dropout方案。對(duì)于給定的sequence,我們以一定的概率 pk保留原始的樣本,當(dāng)data dropout被應(yīng)用時(shí)(概率為1- pk),我們以預(yù)定的概率p來(lái)隨機(jī)刪除序列中的tokens。
2.5UniDrop整合
最終,我們將上面三種不同粒度的dropout技術(shù)集成到我們的UniDrop中,并從理論上分析了feature dropout、structure dropout、data dropout能夠正則Transformer的不同項(xiàng)并且不能相互取代,具體分析可參考論文。Figure 2是UniDrop的簡(jiǎn)單示例。
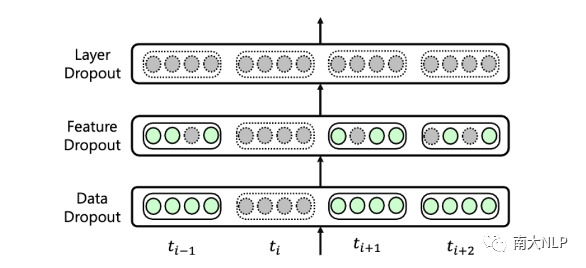
圖2:UniDrop示例
03實(shí)驗(yàn)與分析
我們?cè)谛蛄猩桑C(jī)器翻譯)和文本分類兩個(gè)任務(wù)上來(lái)驗(yàn)證UniDrop的性能。
3.1神經(jīng)機(jī)器翻譯
我們?cè)贗WSLT14數(shù)據(jù)集上進(jìn)行了機(jī)器翻譯實(shí)驗(yàn),共4個(gè)語(yǔ)言對(duì),8個(gè)翻譯任務(wù),baseline為標(biāo)準(zhǔn)的Transformer結(jié)構(gòu),實(shí)驗(yàn)結(jié)果如表1所示:
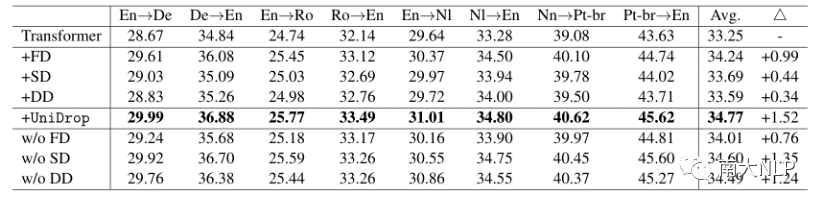
表1:不同模型在IWSLT14翻譯任務(wù)上的結(jié)果
可以看到,相比于標(biāo)準(zhǔn)的Transformer,我們的UniDrop在所有任務(wù)翻譯任務(wù)上都取得了一致且顯著的提升。為了驗(yàn)證UniDrop中每種dropout的作用,我們進(jìn)行了ablation study實(shí)驗(yàn),也在標(biāo)準(zhǔn)Transformer添加單一的dropout去驗(yàn)證它們的性能。從結(jié)果看,F(xiàn)D、SD和DD都能在一定程度上提升Transformer的性能,并能夠協(xié)同工作,最終進(jìn)一步提升Transformer的泛化性。
為了進(jìn)一步驗(yàn)證UniDrop的優(yōu)越性,我們也在廣泛被認(rèn)可的benchmarkIWSLT14 De→En翻譯任務(wù)上和其他系統(tǒng)進(jìn)行了對(duì)比。這些系統(tǒng)從不同的方面提升機(jī)器翻譯,如訓(xùn)練算法設(shè)計(jì)(Adversarial MLE)、模型結(jié)構(gòu)設(shè)計(jì)(DynamicConv)、引入外部知識(shí)(BERT-fused NMT)等。可以看到,我們的Transformer+UniDrop仍然顯著超過(guò)了其他系統(tǒng)。
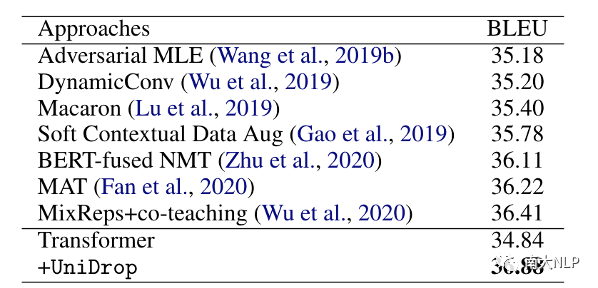
表2:不同系統(tǒng)在IWSLT14 De→En翻譯任務(wù)上的表現(xiàn)
3.2文本分類
對(duì)于文本分類任務(wù),我們以RoBERTaBASE作為backbone,在4個(gè)GLUE數(shù)據(jù)集上和4個(gè)傳統(tǒng)的文本分類數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),結(jié)果如表3和表4所示:
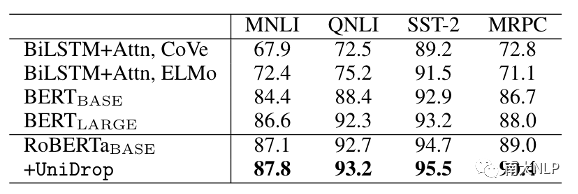
表3:不同模型在GLUE tasks (dev set)上的準(zhǔn)確率
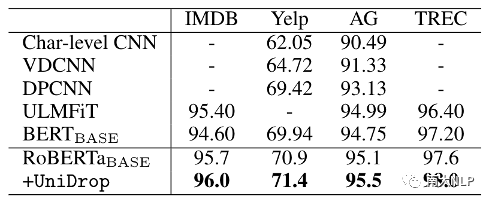
表4:不同模型在傳統(tǒng)文本分類任務(wù)上的準(zhǔn)確率
可以看到,作為一個(gè)強(qiáng)大的預(yù)訓(xùn)練模型,RoBERTaBASE顯著超過(guò)了其他方法。即使如此,UniDrop仍然能夠進(jìn)一步提升RoBERTaBASE的性能,這進(jìn)一步驗(yàn)證了UniDrop對(duì)Transformer模型的有效性。
3.3分析
為了展現(xiàn)UniDrop能夠有效防止Transformer過(guò)擬合,我們畫出了不同模型在IWSLT14 De→En翻譯驗(yàn)證集上的loss曲線,如圖3所示:
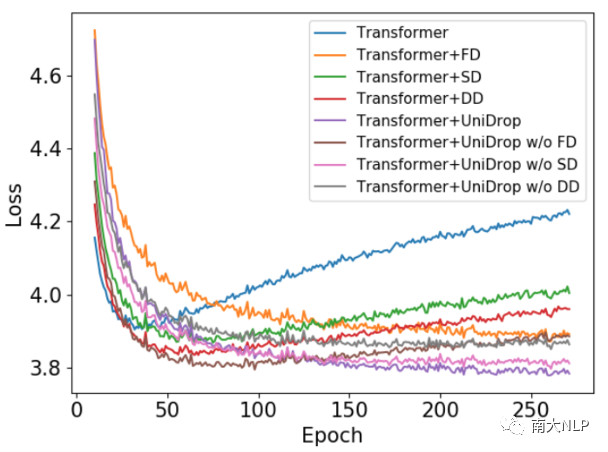
圖3:不同模型在IWSLT14 De→En翻譯上的dev loss
可以看到,標(biāo)準(zhǔn)的Transformer結(jié)構(gòu)隨著訓(xùn)練輪數(shù)的增加,很容易出現(xiàn)過(guò)擬合現(xiàn)象。相比之下,F(xiàn)D、SD、DD都在一定程度上緩解了Transformer的過(guò)擬合問(wèn)題。在所有對(duì)比模型中,我們的UniDrop取得了最低的dev loss,并且dev loss能持續(xù)下降,直到訓(xùn)練結(jié)束。綜合來(lái)看,UniDrop在預(yù)防Transformer過(guò)擬合問(wèn)題上取得了最好的表現(xiàn)。
此外,我們也進(jìn)行了細(xì)粒度的ablation study實(shí)驗(yàn)來(lái)探究不同的feature dropout以及我們2-stage data dropout對(duì)Transformer性能的影響,結(jié)果如表5所示:
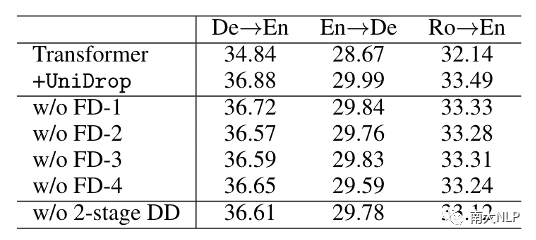
表5:Ablation Study
可以看到,F(xiàn)D-3比FD-1帶來(lái)更多的提升,這也驗(yàn)證了我們之前的分析,僅使用FD-1對(duì)提升multi-head attention的泛化性來(lái)說(shuō)是不夠的。另外,表5表明我們提出的2-stage data dropout策略對(duì)提升性能是有幫助的,這體現(xiàn)了保留原始高質(zhì)量樣本的必要性。
04總結(jié)與展望
過(guò)擬合是Transformer結(jié)構(gòu)中一個(gè)常見的問(wèn)題,dropout技術(shù)常被用來(lái)防止模型過(guò)擬合。本文中,我們提出了一種集成的dropout技術(shù)UniDrop,它由細(xì)粒度到粗粒度,將三種不同類型的dropout(FD、SD、DD)融合到Transformer結(jié)構(gòu)中。我們從理論上分析UniDrop中的三種dropout技術(shù)能夠從不同的方面防止Transformer過(guò)擬合,在機(jī)器翻譯和文本分類任務(wù)上的實(shí)驗(yàn)結(jié)果也體現(xiàn)了UniDrop的有效性和優(yōu)越性,更重要的,它不需要額外的計(jì)算開銷和外部資源。更多的細(xì)節(jié)、結(jié)果以及分析請(qǐng)參考原論文。
編輯:lyn
-
Dropout
+關(guān)注
關(guān)注
0文章
13瀏覽量
10151 -
Transformer
+關(guān)注
關(guān)注
0文章
147瀏覽量
6313 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
625瀏覽量
13907
原文標(biāo)題:UniDrop:一種簡(jiǎn)單而有效的Transformer提升技術(shù)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
提升技術(shù)實(shí)力,突破職業(yè)瓶頸

港大提出SparX:強(qiáng)化Vision Mamba和Transformer的稀疏跳躍連接機(jī)制

一種使用LDO簡(jiǎn)單電源電路解決方案
Transformer模型的具體應(yīng)用

自動(dòng)駕駛中一直說(shuō)的BEV+Transformer到底是個(gè)啥?

一種提升無(wú)人機(jī)小物體跟蹤精度的方法

一種簡(jiǎn)單高效配置FPGA的方法
英偉達(dá)推出歸一化Transformer,革命性提升LLM訓(xùn)練速度
重啟解決PLC故障的具體表現(xiàn)
一種供電總線技術(shù)POWERBUS二總線
Transformer能代替圖神經(jīng)網(wǎng)絡(luò)嗎
Transformer語(yǔ)言模型簡(jiǎn)介與實(shí)現(xiàn)過(guò)程
rup是一種什么模型
一種擺脫有線束縛的通信技術(shù)--無(wú)線傳輸






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論