") 基于人工智能技術(shù)對(duì)疾病的判斷與預(yù)測(cè)及醫(yī)治
基于人工智能技術(shù)對(duì)疾病的判斷與預(yù)測(cè)及醫(yī)治
1.介紹
在人工智能技術(shù)飛速發(fā)展的當(dāng)下,基于人工智能方法的智慧醫(yī)療系統(tǒng)也逐漸吸引了大量研究人員的目光,計(jì)算機(jī)輔助的分診、診斷等應(yīng)用可以一定程度地緩解部分地區(qū)的醫(yī)療條件緊張問題,同樣可以為醫(yī)生的決策提供輔助參考。在數(shù)字化醫(yī)療系統(tǒng)的普及下,與病患相關(guān)的醫(yī)療數(shù)據(jù),如電子醫(yī)療記錄、醫(yī)囑、生物化學(xué)檢測(cè)結(jié)果以及基因組信息也已經(jīng)基本實(shí)現(xiàn)電子化[1],因此,通過數(shù)據(jù)挖掘、深度學(xué)習(xí)等方法對(duì)上述電子化信息進(jìn)行學(xué)習(xí),進(jìn)而得到患者與患者之間的相似程度,是實(shí)現(xiàn)疾病判斷、病情預(yù)測(cè)以及精準(zhǔn)醫(yī)療(precision medicine)等應(yīng)用的重要的前提條件,且上述過程也受啟發(fā)于實(shí)際臨床中醫(yī)生的診療過程。病患相似度度量方法的流程大致如圖1,首先根據(jù)患者的數(shù)據(jù)信息進(jìn)行數(shù)據(jù)抽象化,并選擇合適算法與度量方法對(duì)抽象化結(jié)果進(jìn)行相似度評(píng)估,進(jìn)而將相似度結(jié)果應(yīng)用于相應(yīng)的下游任務(wù)中。
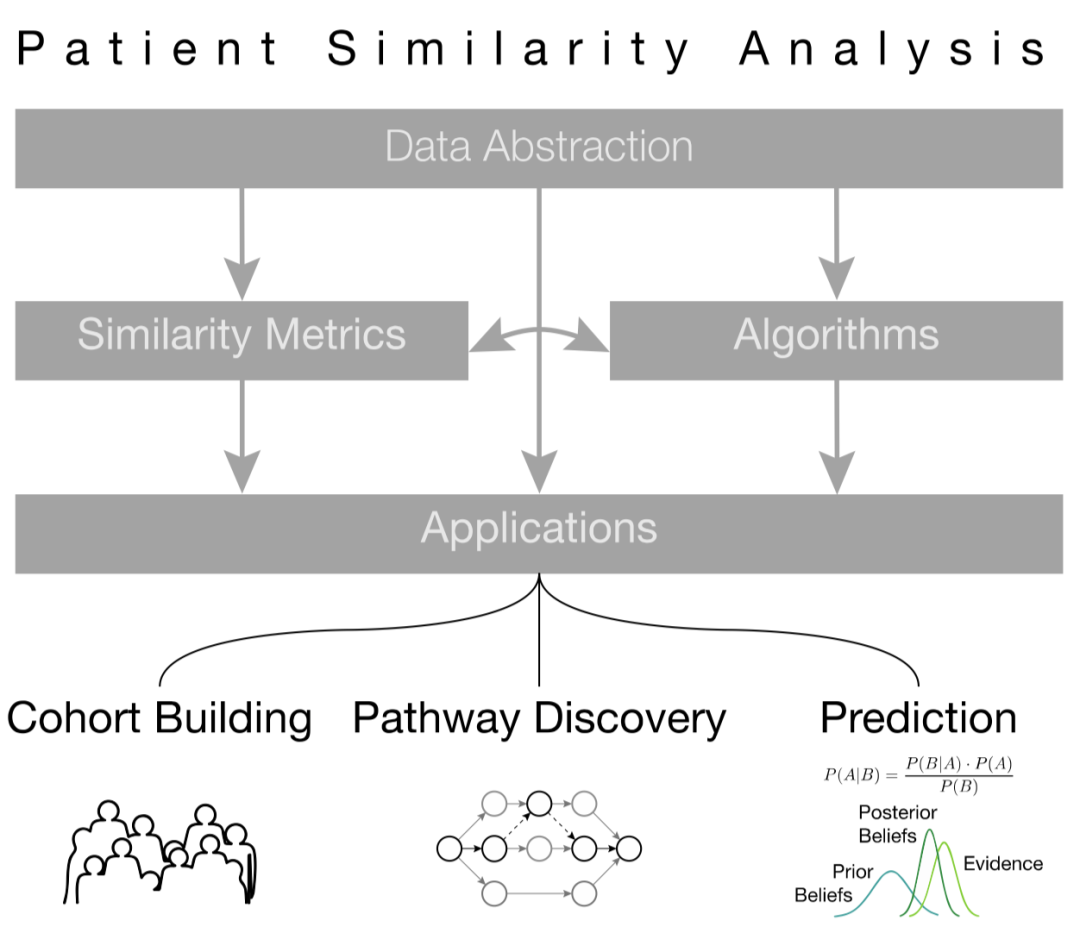
圖1 病患相似度分析工作的基本流程[3]
2.病患數(shù)據(jù)
病患相關(guān)數(shù)據(jù)是天然多模態(tài)(multi-modal)且異構(gòu)(heterogeneous)的,可能涵蓋文本信息(如病歷)、圖像信息(如CT影像)、時(shí)序信號(hào)信息(如心電圖)和數(shù)值信息(如血常規(guī)檢查結(jié)果)等等,從病患相似度的歷史研究中所包括的類型來看,一般可將病患數(shù)據(jù)分為以下五類[2]:
臨床數(shù)據(jù) Clinical data
分子數(shù)據(jù) Molecular data
圖像與生物信號(hào) Imaging and bio signals
實(shí)驗(yàn)室結(jié)果 Lab results
病患所述結(jié)果 Patient-reported outcomes
臨床數(shù)據(jù)包括電子病歷信息、醫(yī)保數(shù)據(jù)等;分子數(shù)據(jù)包括DNA信息、蛋白質(zhì)序列信息等;圖像與生物信號(hào)包括CT、MRI、心電圖等;實(shí)驗(yàn)室結(jié)果包括血液檢測(cè)結(jié)果、核酸抗體檢測(cè)結(jié)果等;病患所述結(jié)果包括患者出院后的回訪信息以及相關(guān)口述信息等。從形式上看,病患數(shù)據(jù)等的醫(yī)學(xué)相關(guān)數(shù)據(jù)都屬于縱向數(shù)據(jù)(longitudinal data),即數(shù)據(jù)來源于不同個(gè)體在不同時(shí)間節(jié)點(diǎn)測(cè)得的數(shù)據(jù)。
根據(jù)以上信息可知,病患數(shù)據(jù)特征一般有著較多的維度,每維特征的采樣次數(shù)與分辨率有所不同,且數(shù)據(jù)完備程度也不一樣[3],因此病患數(shù)據(jù)中大多存在噪聲、異常數(shù)據(jù)以及數(shù)據(jù)缺失等問題。同時(shí),由于患者在患病就醫(yī)后,病癥的減輕或加重都會(huì)導(dǎo)致患者的多次來訪和復(fù)檢,因此病患數(shù)據(jù)多為縱向數(shù)據(jù),即數(shù)據(jù)來源于每個(gè)個(gè)體在不同時(shí)間點(diǎn)上的觀測(cè)值[4]。
3.病患相似度度量相關(guān)數(shù)據(jù)
3.1 UCI 數(shù)據(jù)集[5]
UCI數(shù)據(jù)集是機(jī)器學(xué)習(xí)社區(qū)中使用率很高的領(lǐng)域豐富的數(shù)據(jù)集倉庫,其中也涵蓋與醫(yī)學(xué)健康相關(guān)的數(shù)據(jù)集,相關(guān)數(shù)據(jù)也為病患相似度度量工作的數(shù)據(jù)來源,包括帕金森氏癥數(shù)據(jù)集[6]、心臟病數(shù)據(jù)集[7]、糖尿病數(shù)據(jù)集[8]、癌癥數(shù)據(jù)集[9]等等。
3.2 ADNI數(shù)據(jù)集[10]
ADNI(Alzheimer‘s Disease Neuroimaging Initiative)是一個(gè)通過生物標(biāo)記與臨床數(shù)據(jù)追蹤阿爾茲海默癥發(fā)展過程的縱向研究計(jì)劃,數(shù)據(jù)內(nèi)容包括臨床診斷、生物樣本、藥物使用歷史、基因組數(shù)據(jù)以及腦補(bǔ)成像數(shù)據(jù),疾病的診斷工作每數(shù)月進(jìn)行一次并持續(xù)數(shù)年,研究對(duì)象被分為三組,分別為正常對(duì)照組、中度認(rèn)知障礙(MCI, Mild Cognitive Impairment)和阿爾茲海默癥患者(AD, Alzheimer’s Disease)。
3.3 SOF數(shù)據(jù)集[11]
SOF(Study of Osteoporotic Fracture)是一個(gè)長達(dá)二十余年的針對(duì)年長白人女性骨質(zhì)疏松病癥的醫(yī)院來訪縱向研究,研究旨在分析高齡白人女性患骨質(zhì)疏松的風(fēng)險(xiǎn)因素,研究對(duì)象被分為正常對(duì)照組、骨質(zhì)減少(osteopenia)以及骨質(zhì)疏松(osteoporosis)。
3.4 MIMIC數(shù)據(jù)集[12]
MIMIC-III(Medical Information Mart for Intensive Care III)是大規(guī)模的匿名化健康數(shù)據(jù)庫,包括了十余年間超過四千名患者在危重癥監(jiān)護(hù)病房的相關(guān)記錄,包括患者個(gè)人信息、生命體征監(jiān)測(cè)數(shù)據(jù)、實(shí)驗(yàn)室監(jiān)測(cè)數(shù)據(jù)、圖像報(bào)告等多種病患數(shù)據(jù)信息。
3.5 ICD-9-CM 編碼集[13]
ICD-9-CM(The international classification of disease, ninth revision, clinical modification) 是在臨床中將診斷結(jié)果編碼表示的一種官方標(biāo)準(zhǔn),包括疾病編碼列表,疾病類型分類以及手術(shù)、診斷、診療手段分類系統(tǒng)。
4.深度病患相似度學(xué)習(xí)[14]
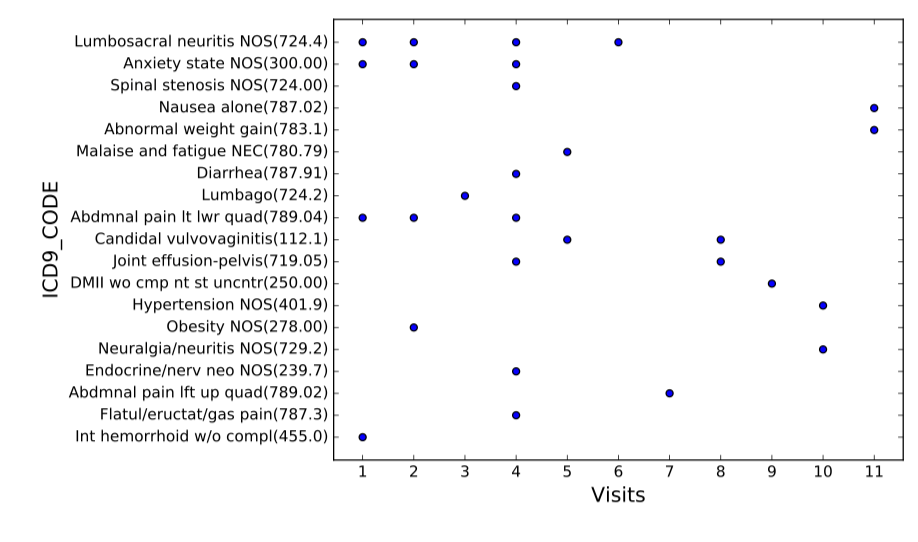
圖2 患者數(shù)據(jù)樣例(橫軸為病患來訪醫(yī)院序列,縱軸為醫(yī)療事件對(duì)應(yīng)的ICD9編碼)
Suo等人[14]于2018年在IEEE TRANSACTIONS ON NANOBIOSCIENCE上發(fā)表了一種基于深度學(xué)習(xí)的病患相似度學(xué)習(xí)方法,模型分為兩個(gè)模塊,分別是表示學(xué)習(xí)和相似度學(xué)習(xí)。病患數(shù)據(jù)是由代表醫(yī)療相關(guān)事件對(duì)應(yīng)的ICD編碼形成的獨(dú)熱編碼矩陣,如圖2,每名患者對(duì)應(yīng)一個(gè)矩陣,橫軸代表患者來訪醫(yī)院的時(shí)間序列,縱軸為醫(yī)療事件對(duì)應(yīng)的ICD9編碼,若患者患有疾病或有相關(guān)癥狀,則矩陣對(duì)應(yīng)位置為1。在表示學(xué)習(xí)中,作者通過全連接層將患者的高維稀疏獨(dú)熱向量矩陣映射到低維稠密空間,并依托卷積神經(jīng)網(wǎng)絡(luò)捕捉病患信息的連續(xù)的時(shí)序特征;對(duì)于相似度學(xué)習(xí),作者使用基于softmax的有監(jiān)督分類方法并通過triplet loss使每兩個(gè)患者對(duì)相似的患者距離更近而不相似的患者距離更遠(yuǎn),以此在患者聚類任務(wù)上實(shí)現(xiàn)較好的效果。
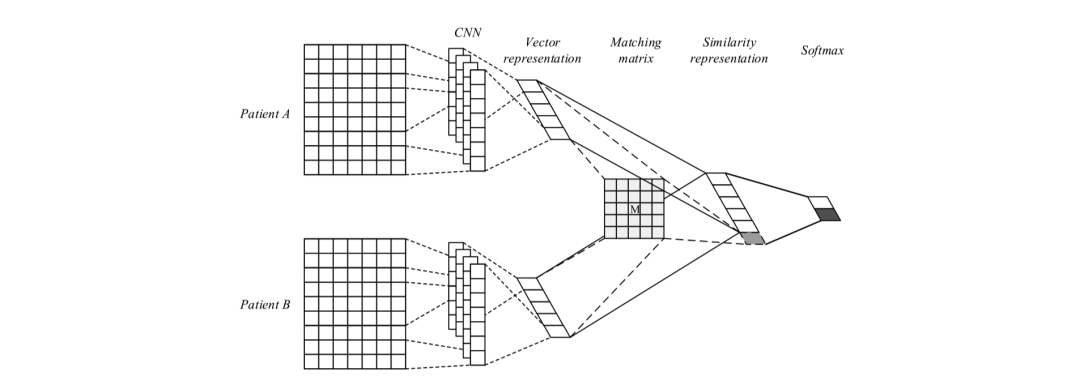
圖3 模型結(jié)構(gòu)
5.病患相似度度量的可解釋性
在各種病患相似度度量方法被初步探索后,在真實(shí)的使用場景下,醫(yī)療相關(guān)從業(yè)人員在關(guān)注模型的性能的同時(shí),更加關(guān)注模型輸出結(jié)果過程中的透明度和可解釋性。Huai等人[15]因此在BIBM 2020提出了一種為所學(xué)習(xí)到的病患相似度模型行為提供全局解釋的模型無關(guān)的方法。一般來說,病患相似度的研究工作可能包括數(shù)十種特征,作者認(rèn)為通過篩選選擇眾多特征中數(shù)量最少且足以解釋模型判斷結(jié)果的特征子集作為解釋模型判斷的依據(jù)可以很好地為實(shí)際場景下的相關(guān)人員提供參考。對(duì)于數(shù)據(jù)集中的患者個(gè)體,每兩個(gè)患者間即可計(jì)算一次相似度,相似度結(jié)果一般為相似或相異,而當(dāng)隨機(jī)減少數(shù)據(jù)集中的特征數(shù)量后重新計(jì)算每兩個(gè)患者間的相似度,結(jié)果會(huì)產(chǎn)生一定的變化,而通過量化評(píng)估這一變化即可評(píng)價(jià)去除的特征的重要性,并以此作為該特征在度量病患間相似度時(shí)的貢獻(xiàn)程度。
6.病患數(shù)據(jù)安全
在數(shù)據(jù)驅(qū)動(dòng)的病患相似度度量方法不斷發(fā)展的同時(shí),方法背后所使用數(shù)據(jù)的安全性也逐漸成為了患者、醫(yī)療機(jī)構(gòu)以及相關(guān)監(jiān)管部門關(guān)心的話題,同時(shí)很多醫(yī)療機(jī)構(gòu)出于對(duì)患者個(gè)人信息的保護(hù),不愿將敏感的醫(yī)療相關(guān)數(shù)據(jù)對(duì)研究人員開放,在這種背景下,在不訪問所有人數(shù)據(jù)的前提下進(jìn)行模型學(xué)習(xí)成為了解決這一數(shù)據(jù)安全問題的前提。Huai等人[16]在SDM 2018上,在提出不相關(guān)特征提取模型的前提下,還考慮了上述數(shù)據(jù)安全問題,進(jìn)而提出了分布式病患相似度度量模型,即分布在不同地點(diǎn)的數(shù)據(jù)在進(jìn)行度量模型學(xué)習(xí)時(shí),只將學(xué)習(xí)得到的參數(shù)上傳學(xué)習(xí)器,而學(xué)習(xí)器通過對(duì)全局參數(shù)進(jìn)行優(yōu)化迭代將結(jié)果回傳至每個(gè)節(jié)點(diǎn)進(jìn)行迭代直至全局收斂。Xu等人[17]在AAAI 2019的工作中將聯(lián)邦學(xué)習(xí)(Federated Learning)方法引入病患相似度度量工作,實(shí)現(xiàn)在數(shù)據(jù)本地保存的同時(shí)完成模型的訓(xùn)練,并通過最小化相似度留存損失以及異質(zhì)信息損失進(jìn)而同時(shí)保留同類與異類數(shù)據(jù)間的關(guān)系。
編輯:lyn
-
人工智能
+關(guān)注
關(guān)注
1794文章
47622瀏覽量
239587 -
數(shù)據(jù)挖掘
+關(guān)注
關(guān)注
1文章
406瀏覽量
24287 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5512瀏覽量
121404
原文標(biāo)題:【賽爾筆記】病患相似度度量簡述
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
對(duì)話華為大咖,探討油氣行業(yè)數(shù)字化轉(zhuǎn)型和人工智能技術(shù)的應(yīng)用與實(shí)踐






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論