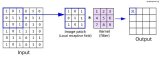
") 完整的Faster R-CNN框架
完整的Faster R-CNN框架
背景
Faster R-CNN 最早在 2015 年的 NIPS 發(fā)布。其在發(fā)布后經(jīng)歷了幾次修改,這在之后博文中會有討論。Faster-RCNN 是 RCNN 系列論文的第三次迭代,這一系列論文的一作和聯(lián)合作者是 Ross Girshick。
這一切始于 2014 年的一篇論文「Rich feature hierarchies for accurate object detection and semantic segmentation」(R-CNN),其使用了稱為 Selective Search 的算法用來提取感興趣候選區(qū)域,并用一個標(biāo)準(zhǔn)的卷積神經(jīng)網(wǎng)絡(luò) (CNN) 去分類和調(diào)整這些區(qū)域。Fast R-CNN 從 R-CNN 演變優(yōu)化而來,F(xiàn)ast R-CNN 發(fā)布于 2015 年上半年,其中一種稱為感興趣區(qū)域池化的技術(shù),使得網(wǎng)絡(luò)可以共享計算結(jié)果,從而讓模型提速。這一系列算法最終被優(yōu)化為 Faster R-CNN,這是第一個完全可微分的模型。
框架
Faster R-CNN 的框架由幾個模塊部件組成,所以其框架有些復(fù)雜。我們將從高層次的概述開始,之后會介紹不同組成部分的具體細(xì)節(jié)。
從一張圖片開始,我們將會得到:
一個邊框列表
每個邊框會被分配一個標(biāo)簽
每對標(biāo)簽和邊框所對應(yīng)的概率
完整的 Faster R-CNN 框架
輸入的圖片以長×寬×高的張量形式表征,之后會被饋送入預(yù)訓(xùn)練好的卷積神經(jīng)網(wǎng)絡(luò),在中間層得到特征圖。使用該特征圖作為特征提取器并用于下一流程。
上述方法在遷移學(xué)習(xí)中經(jīng)常使用,尤其在為小數(shù)據(jù)集訓(xùn)練分類器時,其通常取用了在另一個較大數(shù)據(jù)集訓(xùn)練好的權(quán)重。我們在下一章節(jié)會深入了解這個部分。接著,我們會使用到區(qū)域建議網(wǎng)絡(luò)(Region Proposal Network,RPN)。使用 CNN 計算得到的特征,去尋找到預(yù)設(shè)好數(shù)量的可能包含目標(biāo)的區(qū)域 (邊框)。
使用深度學(xué)習(xí)進(jìn)行目標(biāo)檢測最大的困難可能是生成一個長度可變的邊框列表。使用深度神經(jīng)網(wǎng)絡(luò)建模時,模型最后一部分通常是一個固定尺寸的張量輸出(除了循環(huán)神經(jīng)網(wǎng)絡(luò))。例如,在圖片分類中,輸出是 (N,) 形狀的張量,N 是類別的數(shù)量,其中在第 i 個位置標(biāo)量含有該圖片屬于類別 i 的概率。
RPN 中長度可變列表的問題可以使用錨點(diǎn)解決:使用固定尺寸的參考邊框在原始圖片上一致地定位。不是直接探測目標(biāo)在哪,而是把問題分兩個方面建模,對每個錨點(diǎn),我們考慮:
這個錨點(diǎn)包含相關(guān)目標(biāo)嗎?
如何調(diào)整錨點(diǎn)以更好的擬合到相關(guān)目標(biāo)?
可能會有點(diǎn)困擾,但是沒關(guān)系,下面會深入了解。
在取得一系列的相關(guān)目標(biāo)和其在原始圖片上的位置后,目標(biāo)探測問題就可以相對直觀地解決了。使用 CNN 提取到的特征和相關(guān)目標(biāo)的邊框,我們在相關(guān)目標(biāo)的特征圖上使用感興趣區(qū)域池化 (RoI Pooling),并將與目標(biāo)相關(guān)的特征信息存入一個新的張量。之后的流程與 R-CNN 模型一致,利用這些信息:
對邊框內(nèi)的內(nèi)容分類(或者舍棄它,并用「背景」標(biāo)記邊框內(nèi)容)
調(diào)整邊框的坐標(biāo)(使之更好地包含目標(biāo))
顯然,這樣做會遺失掉部分信息,但這正是 Faster-RCNN 如何進(jìn)行目標(biāo)探測的基本思想。下一步,我們會仔細(xì)討論框架、損失函數(shù)以及訓(xùn)練過程中各個組件的具體細(xì)節(jié)。
基礎(chǔ)網(wǎng)絡(luò)
之前提到過,F(xiàn)aster R-CNN 第一步要使用在圖片分類任務(wù) (例如,ImageNet) 上預(yù)訓(xùn)練好的卷積神經(jīng)網(wǎng)絡(luò),使用該網(wǎng)絡(luò)得到的中間層特征的輸出。這對有深度學(xué)習(xí)背景的人來說很簡單,但是理解如何使用和為什么這樣做才是關(guān)鍵,同時,可視化中間層的特征輸出也很重要。沒有一致的意見表明哪個網(wǎng)絡(luò)框架是最好的。原始的 Faster R-CNN 使用的是在 ImageNet 上預(yù)訓(xùn)練的 ZF 和 VGG,但之后出現(xiàn)了很多不同的網(wǎng)絡(luò),且不同網(wǎng)絡(luò)的參數(shù)數(shù)量變化很大。例如,MobileNet,以速度優(yōu)先的一個小型的高效框架,大約有 330 萬個參數(shù),而 ResNet-152(152 層),曾經(jīng)的 ImageNet 圖片分類競賽優(yōu)勝者,大約有 6000 萬個參數(shù)。最新的網(wǎng)絡(luò)結(jié)構(gòu)如 DenseNet,可以在提高準(zhǔn)確度的同時縮減參數(shù)數(shù)量。
VGG
在討論網(wǎng)絡(luò)結(jié)構(gòu)孰優(yōu)孰劣之前,讓我們先以 VGG-16 為例來嘗試?yán)斫?Faster-RCNN 是如何工作的。
VGG 網(wǎng)絡(luò)結(jié)構(gòu)
VGG,其名字來自于在 ImageNet ILSVRC 2014 競賽中使用此網(wǎng)絡(luò)的小組組名,首次發(fā)布于論文」Very Deep Convolutional Networks for Large-Scale Image Recognition」, 作者是 Karen Simonyan 和 Andrew Zisserman。以今天的標(biāo)準(zhǔn)來看這個網(wǎng)絡(luò)談不上深度,但是在發(fā)布之際 VGG16 比當(dāng)時常用的網(wǎng)絡(luò)要多一倍的層數(shù),其推動了「深度 → 更強(qiáng)大性能 → 更好結(jié)果」的浪潮(只要訓(xùn)練是可行的)。
當(dāng)使用 VGG 進(jìn)行分類任務(wù)時,其輸入是 224×224×3 的張量 (表示一個 224×224 像素大小的 RGB 圖片)。在分類任務(wù)中輸入圖片的尺寸是固定的,因為網(wǎng)絡(luò)最后一部分的全連接層需要固定長度的輸入。在接入全連接層前,通常要將最后一層卷積的輸出展開成一維張量。
因為要使用卷積網(wǎng)絡(luò)中間層的輸出,所以輸入圖片的尺寸不再有限制。至少,在這個模塊中不再是問題,因為只有卷積層參與計算。讓我們深入了解一下底層的細(xì)節(jié),看看具體要使用哪一層卷積網(wǎng)絡(luò)的輸出。Faster R-CNN 論文中沒有具體指定使用哪一層;但是在官方的實現(xiàn)中可以觀察到,作者使用的是 conv5/conv5_1 這一層 (caffe 代碼)。
每一層卷積網(wǎng)絡(luò)都在前一層的信息基礎(chǔ)上提取更加抽象的特征。第一層通常學(xué)習(xí)到簡單的邊緣,第二層尋找目標(biāo)邊緣的模式,以激活后續(xù)卷積網(wǎng)絡(luò)中更加復(fù)雜的形狀。最終,我們得到一個在空間維度上比原始圖片小很多,但表征更深的卷積特征圖。特征圖的長和寬會隨著卷積層間的池化而縮小,深度會隨著卷積層濾波器的數(shù)量而增加。
從圖片到卷積特征圖
卷積特征圖將圖片的所有信息編碼到深度的維度上,同時保留著原始圖片上目標(biāo)物體的相對位置信息。例如,如果圖片左上角有一個紅色矩形,經(jīng)過卷積層的激活,那么紅色矩形的位置信息仍然保留在卷積特征圖的左上角。
VGG vs ResNet
如今,ResNet 已經(jīng)取代大多數(shù) VGG 網(wǎng)絡(luò)作為提取特征的基礎(chǔ)框架。Faster-RCNN 的三位聯(lián)合作者 (Kaiming He, Shaoqing Ren 和 Jian Sun) 也是論文「Deep Residual Learning for Image (https://arxiv.org/abs/1512.03385) Recognition」的作者,這篇論文最初介紹了 ResNets 這一框架。
ResNet 對比 VGG 的優(yōu)勢在于它是一個更深層、大型的網(wǎng)絡(luò),因此有更大的容量去學(xué)習(xí)所需要的信息。這些結(jié)論在圖片分類任務(wù)中可行,在目標(biāo)探測的問題中也應(yīng)該同樣有效。
ResNet 在使用殘差連接和批歸一化的方法后更加易于訓(xùn)練,這些方法在 VGG 發(fā)布的時候還沒有出現(xiàn)。
錨點(diǎn)
現(xiàn)在,我們將使用處理過后的特征圖并建議目標(biāo)區(qū)域,也就是用于分類任務(wù)的感興趣區(qū)域。之前提到過錨點(diǎn)是解決長度可變問題的一種方法,現(xiàn)在將詳細(xì)介紹。
我們的目標(biāo)是尋找圖片中的邊框。這些邊框是不同尺寸、不同比例的矩形。設(shè)想我們在解決問題前已知圖片中有兩個目標(biāo)。那么首先想到的應(yīng)該是訓(xùn)練一個網(wǎng)絡(luò),這個網(wǎng)絡(luò)可以返回 8 個值:包含(xmin, ymin, xmax, ymax)的兩個元組,每個元組都用于定義一個目標(biāo)的邊框坐標(biāo)。這個方法有著根本問題,例如,圖片可能是不同尺寸和比例的,因此訓(xùn)練一個可以直接準(zhǔn)確預(yù)測原始坐標(biāo)的模型是很復(fù)雜的。另一個問題是無效預(yù)測:當(dāng)預(yù)測(xmin,xmax)和(ymin,ymax)時,應(yīng)該強(qiáng)制設(shè)定 xmin 要小于 xmax,ymin 要小于 ymax。
另一種更加簡單的方法是去預(yù)測參考邊框的偏移量。使用參考邊框(xcenter, ycenter, width, height),學(xué)習(xí)預(yù)測偏移量(Δxcenter,Δycenter,Δwidth,Δheight),因此我們只得到一些小數(shù)值的預(yù)測結(jié)果并挪動參考變量就可以達(dá)到更好的擬合結(jié)果。
錨點(diǎn)是用固定的邊框置于不同尺寸和比例的圖片上,并且在之后目標(biāo)位置的預(yù)測中用作參考邊框。
我們在處理的卷積特征圖的尺寸分別是 convwidth×convheight×convdepth,因此在卷積圖的 convwidth×convheight 上每一個點(diǎn)都生成一組錨點(diǎn)。很重要的一點(diǎn)是即使我們是在特征圖上生成的錨點(diǎn),這些錨點(diǎn)最終是要映射回原始圖片的尺寸。
因為我們只用到了卷積和池化層,所以特征圖的最終維度與原始圖片是呈比例的。數(shù)學(xué)上,如果圖片的尺寸是 w×h,那么特征圖最終會縮小到尺寸為 w/r 和 h/r,其中 r 是次級采樣率。如果我們在特征圖上每個空間位置上都定義一個錨點(diǎn),那么最終圖片的錨點(diǎn)會相隔 r 個像素,在 VGG 中,r=16。
原始圖片的錨點(diǎn)中心
為了選擇一組合適錨點(diǎn),我們通常定義一組固定尺寸 (例如,64px、128px、256px,此處為邊框大小) 和比例 (例如,0.5、1、1.5,此處為邊框長寬比) 的邊框,使用這些變量的所有可能組合得到候選邊框 (這個例子中有 1 個錨點(diǎn)和 9 個邊框)。
左側(cè):錨點(diǎn)、中心:特征圖空間單一錨點(diǎn)在原圖中的表達(dá),右側(cè):所有錨點(diǎn)在原圖中的表達(dá)
區(qū)域建議網(wǎng)絡(luò)
RPN 采用卷積特征圖并在圖像上生成建議。
像我們之前提到的那樣,RPN 接受所有的參考框(錨點(diǎn))并為目標(biāo)輸出一套好的建議。它通過為每個錨點(diǎn)提供兩個不同的輸出來完成。
第一個輸出是錨點(diǎn)作為目標(biāo)的概率。如果你愿意,可以叫做「目標(biāo)性得分」。注意,RPN 不關(guān)心目標(biāo)的類別,只在意它實際上是不是一個目標(biāo)(而不是背景)。我們將用這個目標(biāo)性得分來過濾掉不好的預(yù)測,為第二階段做準(zhǔn)備。第二個輸出是邊框回歸,用于調(diào)整錨點(diǎn)以更好的擬合其預(yù)測的目標(biāo)。
RPN 是用完全卷積的方式高效實現(xiàn)的,用基礎(chǔ)網(wǎng)絡(luò)返回的卷積特征圖作為輸入。首先,我們使用一個有 512 個通道和 3x3 卷積核大小的卷積層,然后我們有兩個使用 1x1 卷積核的并行卷積層,其通道數(shù)量取決于每個點(diǎn)的錨點(diǎn)數(shù)量。
RPN 架構(gòu)的卷積實現(xiàn),其中 k 是錨點(diǎn)的數(shù)量。
對于分類層,我們對每個錨點(diǎn)輸出兩個預(yù)測值:它是背景(不是目標(biāo))的分?jǐn)?shù),和它是前景(實際的目標(biāo))的分?jǐn)?shù)。
對于回歸或邊框調(diào)整層,我們輸出四個預(yù)測值:Δxcenter、Δycenter、Δwidth、Δheight,我們將會把這些值用到錨點(diǎn)中來得到最終的建議。
使用最終的建議坐標(biāo)和它們的目標(biāo)性得分,然后可以得到一套很好的對于目標(biāo)的建議。
訓(xùn)練、目標(biāo)和損失函數(shù)
RPN 執(zhí)行兩種不同類型的預(yù)測:二進(jìn)制分類和邊框回歸調(diào)整。為了訓(xùn)練,我們把所有的錨點(diǎn)分成兩類。一類是「前景」,它與真實目標(biāo)重疊并且其 IoU(Intersection of Union)值大于 0.5;另一類是「背景」,它不與任何真實目標(biāo)重疊或與真實目標(biāo)的 IoU 值 小于 0.1。
然后,我們對這些錨點(diǎn)隨機(jī)采樣,構(gòu)成大小為 256 的 mini batch——維持前景錨點(diǎn)和背景錨點(diǎn)之間的平衡比例。
RPN 用所有以 mini batch 篩選出來的錨點(diǎn)和二進(jìn)制交叉熵(binary cross entropy)來計算分類損失。然后它只用那些標(biāo)記為前景的 mini batch 錨點(diǎn)來計算回歸損失。為了計算回歸的目標(biāo),我們使用前景錨點(diǎn)和最接近的真實目標(biāo),并計算將錨點(diǎn)轉(zhuǎn)化為目標(biāo)所需的正確 Δ。
論文中建議使用 Smooth L1 loss 來計算回歸誤差,而不是用簡單的 L1 或 L2 loss。Smooth L1 基本上就是 L1,但是當(dāng) L1 的誤差足夠小,由確定的 σ 定義時,可以認(rèn)為誤差幾乎是正確的且損失以更快的速率減小。
使用 dynamic batches 是具有挑戰(zhàn)性的,這里的原因很多。即使我們試圖維持前景錨點(diǎn)和背景錨點(diǎn)之間的平衡比例,但這并不總是可能的。根據(jù)圖像上的真實目標(biāo)以及錨點(diǎn)的大小和比例,可能會得到零前景錨點(diǎn)。在這種情況下,我們轉(zhuǎn)而使用對于真實框具有最大 IoU 值的錨點(diǎn)。這遠(yuǎn)非理想情況,但是為了總是有前景樣本和目標(biāo)可以學(xué)習(xí),這還是挺實用的。
后處理
非極大抑制(Non-maximum suppression):由于錨點(diǎn)經(jīng)常重疊,因此建議最終也會在同一個目標(biāo)上重疊。為了解決重復(fù)建議的問題,我們使用一個簡單的算法,稱為非極大抑制(NMS)。NMS 獲取按照分?jǐn)?shù)排序的建議列表并對已排序的列表進(jìn)行迭代,丟棄那些 IoU 值大于某個預(yù)定義閾值的建議,并提出一個具有更高分?jǐn)?shù)的建議。
雖然這看起來很簡單,但對 IoU 的閾值設(shè)定一定要非常小心。太低,你可能會丟失對目標(biāo)的建議;太高,你可能會得到對同一個目標(biāo)的很多建議。常用值是 0.6。
建議選擇:應(yīng)用 NMS 后,我們保留評分最高的 N 個建議。論文中使用 N=2000,但是將這個數(shù)字降低到 50 仍然可以得到相當(dāng)好的結(jié)果。
獨(dú)立應(yīng)用程序
RPN 可以獨(dú)立使用,而不需要第二階段的模型。在只有一類對象的問題中,目標(biāo)性概率可以用作最終的類別概率。這是因為在這種情況下,「前景」=「目標(biāo)類別」以及「背景」=「不是目標(biāo)類別」。
一些從獨(dú)立使用 RPN 中受益的機(jī)器學(xué)習(xí)問題的例子包括流行的(但仍然是具有挑戰(zhàn)性的)人臉檢測和文本檢測。
僅使用 RPN 的優(yōu)點(diǎn)之一是訓(xùn)練和預(yù)測的速度都有所提高。由于 RPN 是一個非常簡單的僅使用卷積層的網(wǎng)絡(luò),所以預(yù)測時間比使用分類基礎(chǔ)網(wǎng)絡(luò)更快。
興趣區(qū)域池化
在 RPN 步驟之后,我們有很多沒有分配類別的目標(biāo)建議。我們接下來要解決的問題就是如何將這些邊框分類到我們想要的類別中。
最簡單的方法是采用每個建議,裁剪出來,然后讓它通過預(yù)訓(xùn)練的基礎(chǔ)網(wǎng)絡(luò)。然后,我們可以用提取的特征作為基礎(chǔ)圖像分類器的輸入。這種方法的主要問題是運(yùn)行所有 2000 個建議的計算效率和速度都是非常低的。
Faster R-CNN 試圖通過復(fù)用現(xiàn)有的卷積特征圖來解決或至少緩解這個問題。這是通過用興趣區(qū)域池化為每個建議提取固定大小的特征圖實現(xiàn)的。R-CNN 需要固定大小的特征圖,以便將它們分類到固定數(shù)量的類別中。
興趣區(qū)域池化
一種更簡單的方法(被包括 Luminoth 版本的 Faster R-CNN 在內(nèi)的目標(biāo)檢測實現(xiàn)方法所廣泛使用),是用每個建議來裁剪卷積特征圖,然后用插值(通常是雙線性的)將每個裁剪調(diào)整為固定大小(14×14×convdepth)。裁剪之后,用 2x2 核大小的最大池化來獲得每個建議最終的 7×7×convdepth 特征圖。
選擇這些確切形狀的原因與下一模塊(R-CNN)如何使用它有關(guān),這些設(shè)定是根據(jù)第二階段的用途得到的。
基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)
基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(R-CNN)是 Faster R-CNN 工作流的最后一步。從圖像上獲得卷積特征圖之后,用它通過 RPN 來獲得目標(biāo)建議并最終為每個建議提取特征(通過 RoI Pooling),最后我們需要使用這些特征進(jìn)行分類。R-CNN 試圖模仿分類 CNNs 的最后階段,在這個階段用一個全連接層為每個可能的目標(biāo)類輸出一個分?jǐn)?shù)。
R-CNN 有兩個不同的目標(biāo):
1. 將建議分到一個類中,加上一個背景類(用于刪除不好的建議)。
2. 根據(jù)預(yù)測的類別更好地調(diào)整建議的邊框。
在最初的 Faster R-CNN 論文中,R-CNN 對每個建議采用特征圖,將它平坦化并使用兩個大小為 4096 的有 ReLU 激活函數(shù)的全連接層。
然后,它對每個不同的目標(biāo)使用兩種不同的全連接層:
一個有 N+1 個單元的全連接層,其中 N 是類的總數(shù),另外一個是背景類。
一個有 4N 個單元的全連接層。我們希望有一個回歸預(yù)測,因此對 N 個類別中的每一個可能的類別,我們都需要 Δcenterx、Δcentery、Δwidth、Δheight。
R-CNN 架構(gòu)
訓(xùn)練和目標(biāo)
R-CNN 的目標(biāo)與 RPN 的目標(biāo)的計算方法幾乎相同,但是考慮的是不同的可能類別。我們采用建議和真實邊框,并計算它們之間的 IoU。
那些有任何真實邊框的建議,只要其 IoU 大于 0.5,都被分配給那個真實數(shù)據(jù)。那些 IoU 在 0.1 和 0.5 之間的被標(biāo)記為背景。與我們在為 RPN 分配目標(biāo)時相反的是,我們忽略了沒有任何交集的建議。這是因為在這個階段,我們假設(shè)已經(jīng)有好的建議并且我們對解決更困難的情況更有興趣。當(dāng)然,這些所有的值都是可以為了更好的擬合你想找的目標(biāo)類型而做調(diào)整的超參數(shù)。
邊框回歸的目標(biāo)是計算建議和與其對應(yīng)的真實框之間的偏移量,僅針對那些基于 IoU 閾值分配了類別的建議。
我們隨機(jī)抽樣了一個尺寸為 64 的 balanced mini batch,其中我們有高達(dá) 25% 的前景建議(有類別)和 75% 的背景。
按照我們對 RPN 損失所做的相同處理方式,現(xiàn)在的分類損失是一個多類別的交叉熵?fù)p失,使用所有選定的建議和用于與真實框匹配的 25% 建議的 Smooth L1 loss。由于 R-CNN 邊框回歸的全連接網(wǎng)絡(luò)的輸出對于每個類都有一個預(yù)測,所以當(dāng)我們得到這種損失時必須小心。在計算損失時,我們只需要考慮正確的類。
后處理
與 RPN 相似,我們最終得到了很多已經(jīng)分配了類別的目標(biāo),在返回它們之前需要進(jìn)一步處理。
為了實施邊框調(diào)整,我們必須考慮哪個類別具有對該建議的最高概率。我們也需要忽略具有最高概率的背景類的建議。
在得到最終目標(biāo)和忽略被預(yù)測為背景的目標(biāo)之后,我們應(yīng)用基于類的 NMS。這通過按類進(jìn)行分組完成,通過概率對其排序,然后將 NMS 應(yīng)用于每個獨(dú)立的組。
對于我們最后的目標(biāo)列表,我們也可以設(shè)置一個概率閾值并且對每個類限制目標(biāo)的數(shù)量。
訓(xùn)練
在最初的論文中,F(xiàn)aster R-CNN 是用多步法訓(xùn)練的,獨(dú)立地訓(xùn)練各部分并且在應(yīng)用最終的全面訓(xùn)練方法之前合并訓(xùn)練的權(quán)重。之后,人們發(fā)現(xiàn)進(jìn)行端到端的聯(lián)合訓(xùn)練會帶來更好的結(jié)果。
把完整的模型放在一起后,我們得到 4 個不同的損失,兩個用于 RPN,另外兩個用于 R-CNN。我們在 RPN 和 R-CNN 中有可訓(xùn)練的層,我們也有可以訓(xùn)練(微調(diào))或不能訓(xùn)練的基礎(chǔ)網(wǎng)絡(luò)。
是否訓(xùn)練基礎(chǔ)網(wǎng)絡(luò)的決定取決于我們想要學(xué)習(xí)的目標(biāo)特性和可用的計算能力。如果我們想檢測與在原始數(shù)據(jù)集(用于訓(xùn)練基礎(chǔ)網(wǎng)絡(luò))上的數(shù)據(jù)相似的目標(biāo),那么除了嘗試壓縮我們能獲得的所有可能的性能外,其他做法都是沒有必要的。另一方面,為了擬合完整的梯度,訓(xùn)練基礎(chǔ)網(wǎng)絡(luò)在時間和必要的硬件上都是昂貴的。
用加權(quán)和將四種不同的損失組合起來。這是因為相對于回歸損失,我們可能希望給分類損失更大的權(quán)重,或者相比于 RPN 可能給 R-CNN 損失更大的權(quán)重。
除了常規(guī)的損失之外,我們也有正則化損失,為了簡潔起見,我們可以跳過這部分,但是它們在 RPN 和 R-CNN 中都可以定義。我們用 L2 正則化一些層。根據(jù)正在使用哪個基礎(chǔ)網(wǎng)絡(luò),以及如果它經(jīng)過訓(xùn)練,也有可能進(jìn)行正則化。
我們用隨機(jī)梯度下降的動量算法訓(xùn)練,將動量值設(shè)置為 0.9。你可以輕松的用其他任何優(yōu)化方法訓(xùn)練 Faster R-CNN,而不會遇到任何大問題。
學(xué)習(xí)率從 0.001 開始,然后在 50K 步后下降到 0.0001。這是通常最重要的超參數(shù)之一。當(dāng)用 Luminoth 訓(xùn)練時,我們經(jīng)常從默認(rèn)值開始,并以此開始做調(diào)整。
評估
在一些特定的 IoU 閾值下,使用標(biāo)準(zhǔn)平均精度均值(mAP)來完成評估(例如,mAP@0.5)。mAP 是源于信息檢索的度量標(biāo)準(zhǔn),并且常用于計算排序問題中的誤差和評估目標(biāo)檢測問題。
我們不會深入討論細(xì)節(jié),因為這些類型的度量標(biāo)準(zhǔn)值得用一篇完整博客來總結(jié),但重要的是,當(dāng)你錯過了你應(yīng)該檢測到的框,以及當(dāng)你發(fā)現(xiàn)一些不存在的東西或多次檢測到相同的東西時,mAP 會對此進(jìn)行懲罰。
結(jié)論
到目前為止,你應(yīng)該清楚 Faster R-CNN 的工作方式、設(shè)計目的以及如何針對特定的情況進(jìn)行調(diào)整。如果你想更深入的了解它的工作原理,你應(yīng)該看看 Luminoth 的實現(xiàn)。
Faster R-CNN 是被證明可以用相同的原理解決復(fù)雜的計算機(jī)視覺問題的模型之一,在這個新的深度學(xué)習(xí)革命剛開始的時候,它就展現(xiàn)出如此驚人的結(jié)果。
目前正在建立的新模型不僅用于目標(biāo)檢測,還用于基于這種原始模型的語義分割、3D 目標(biāo)檢測等等。有的借用 RPN,有的借用 R-CNN,還有的建立在兩者之上。因此,充分了解底層架構(gòu)非常重要,從而可以解決更加廣泛的和復(fù)雜的問題。
責(zé)任編輯:lq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101060 -
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
211瀏覽量
15653 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5512瀏覽量
121430
原文標(biāo)題:詳解 Faster R-CNN目標(biāo)檢測的實現(xiàn)過程
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗】2.具身智能機(jī)器人的基礎(chǔ)模塊
cnn常用的幾個模型有哪些
CNN與RNN的關(guān)系?
CNN的定義和優(yōu)勢
如何在TensorFlow中構(gòu)建并訓(xùn)練CNN模型
如何利用CNN實現(xiàn)圖像識別
NLP模型中RNN與CNN的選擇
cnn卷積神經(jīng)網(wǎng)絡(luò)分類有哪些
cnn卷積神經(jīng)網(wǎng)絡(luò)三大特點(diǎn)是什么
CNN模型的基本原理、結(jié)構(gòu)、訓(xùn)練過程及應(yīng)用領(lǐng)域
卷積神經(jīng)網(wǎng)絡(luò)cnn模型有哪些
深入了解目標(biāo)檢測深度學(xué)習(xí)算法的技術(shù)細(xì)節(jié)

基于Python和深度學(xué)習(xí)的CNN原理詳解
如何選擇RTOS?使用R-Rhealstone框架評估
鉛框架 - Fusheng R970 RoHS/Halogen測試報告






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論