") 如何讓Bert模型在下游任務(wù)中提高性能?
如何讓Bert模型在下游任務(wù)中提高性能?
隨著Transformer 在NLP中的表現(xiàn),Bert已經(jīng)成為主流模型,然而大家在下游任務(wù)中使用時,是不是也會發(fā)現(xiàn)模型的性能時好時壞,甚至相同參數(shù)切換一下隨機種子結(jié)果都不一樣,又或者自己不管如何調(diào),模型總達不到想象中的那么好,那如何才能讓Bert在下游任務(wù)中表現(xiàn)更好更穩(wěn)呢?本文以文本分類為例,介紹幾種能幫你提高下游任務(wù)性能的方法。
Further Pre-training
最穩(wěn)定也是最常用的提升下游任務(wù)性能的手段就是繼續(xù)進行預(yù)訓(xùn)練了。繼續(xù)預(yù)訓(xùn)練目前有以下幾種模式。
二階段
首先回顧一下,Bert 是如何使用的呢?
我們假設(shè)通用泛化語料為 ,下游任務(wù)相關(guān)的數(shù)據(jù)為 , Bert 即在通用語料 上訓(xùn)練一個通用的Language Model, 然后利用這個模型學(xué)到的通用知識來做下游任務(wù),也就是在下游任務(wù)上做fine-tune,這就是二階段模式。
大多數(shù)情況下我們也都是這么使用的:下載一個預(yù)訓(xùn)練模型,然后在自己的數(shù)據(jù)上直接fine-tune。
三階段
在論文Universal Language Model Fine-tuning for Text Classification[1]中,作者提出了一個通用的范式ULMFiT:
在大量的通用語料上訓(xùn)練一個LM(Pretrain);
在任務(wù)相關(guān)的小數(shù)據(jù)上繼續(xù)訓(xùn)練LM(Domain transfer);
在任務(wù)相關(guān)的小數(shù)據(jù)上做具體任務(wù)(Fine-tune)。
那我們在使用Bert 時能不能也按這種范式,進行三階段的fine-tune 從而提高性能呢?答案是:能!
比如邱錫鵬老師的論文How to Fine-Tune BERT for Text Classification?[2]和Don't Stop Pretraining: Adapt Language Models to Domains and Tasks[3]中就驗證了,在任務(wù)數(shù)據(jù) 繼續(xù)進行pretraining 任務(wù),可以提高模型的性能。
那如果我們除了任務(wù)數(shù)據(jù)沒有別的數(shù)據(jù)時,怎么辦呢?簡單,任務(wù)數(shù)據(jù)肯定是相同領(lǐng)域的,此時直接將任務(wù)數(shù)據(jù)看作相同領(lǐng)域數(shù)據(jù)即可。所以,在進行下游任務(wù)之前,不妨先在任務(wù)數(shù)據(jù)上繼續(xù)進行pre-training 任務(wù)繼續(xù)訓(xùn)練LM ,之后再此基礎(chǔ)上進行fine-tune。
四階段
我們在實際工作上,任務(wù)相關(guān)的label data 較難獲得,而unlabeled data 卻非常多,那如何合理利用這部分?jǐn)?shù)據(jù),是不是也能提高模型在下游的性能呢?答案是:也能!
在大量通用語料上訓(xùn)練一個LM(Pretrain);
在相同領(lǐng)域 上繼續(xù)訓(xùn)練LM(Domain transfer);
在任務(wù)相關(guān)的小數(shù)據(jù)上繼續(xù)訓(xùn)練LM(Task transfer);
在任務(wù)相關(guān)數(shù)據(jù)上做具體任務(wù)(Fine-tune)。
而且上述兩篇論文中也給出了結(jié)論:先Domain transfer 再進行Task transfer 最后Fine-tune 性能是最好的。
如何further pre-training
how to mask
首先,在further pre-training時,我們應(yīng)該如何進行mask 呢?不同的mask 方案是不是能起到更好的效果呢?
在Roberta 中提出,動態(tài)mask 方案比固定mask 方案效果更好。此外,在做Task transfer 時,由于數(shù)據(jù)通常較小,固定的mask 方案通常也容易過擬合,所以further pre-training 時,動態(tài)隨機mask 方案通常比固定mask 效果更好。
而ERNIE 和 SpanBert 中都給出了結(jié)論,更有針對性的mask 方案可以提升下游任務(wù)的性能,那future pre-training 時是否有什么方案能更有針對性的mask 呢?
劉知遠老師的論文Train No Evil: Selective Masking for Task-Guided Pre-Training[4]就提出了一種更有針對性的mask 方案Selective Mask,進行further pre-training 方案,該方案的整體思路是:
在 上訓(xùn)練一個下游任務(wù)模型 ;
利用 判斷token 是否是下游任務(wù)中的重要token,具體計算公式為:, 其中 為完整句子(序列), 為一個初始化為空的buffer,每次將句子中的token 往buffer中添加,如果加入的token 對當(dāng)前任務(wù)的表現(xiàn)與完整句子在當(dāng)前任務(wù)的表現(xiàn)差距小于閾值,則認(rèn)為該token 為重要token,并從buffer 中剔除;
利用上一步中得到的token label,訓(xùn)練一個二分類模型 ,來判斷句子中的token 是否為重要token;
利用 ,在domain 數(shù)據(jù)上進行預(yù)測,根據(jù)預(yù)測結(jié)果進行mask ;
進行Domain transfer pre-training;
在下游任務(wù)進行Fine-tuning。
上述方案驗證了更有針對性的mask 重要的token,下游任務(wù)中能得到不錯的提升。綜合下來,Selective Mask > Dynamic Mask > Static Mask
雖然selective mask 有提升,但是論文給出的思路太過繁瑣了,本質(zhì)上是判斷token 在下游任務(wù)上的影響,所以這里給出一個筆者自己腦洞的一個方案:「通過 在unlabeled 的Domain data 上直接預(yù)測,然后通過不同token 下結(jié)果的熵的波動來確定token 對下游任務(wù)的影響」。這個方案我沒有做過實驗,有興趣的可以試試。
when to stop
在further pretraining 時,該何時停止呢?是否訓(xùn)練的越久下游任務(wù)就提升的越多呢?答案是否定的。在進行Task transfer 時,應(yīng)該訓(xùn)練多少步,論文How to Fine-Tune BERT for Text Classification?[5]進行了實驗,最后得出的結(jié)論是100k步左右,下游任務(wù)上提升是最高的,這也與我自己的實驗基本吻合,訓(xùn)練過多就會過擬合,導(dǎo)致下游任務(wù)上提升小甚至降低。
此外,由于下游任務(wù)數(shù)據(jù)量的不同,進行多少步結(jié)果是最優(yōu)的也許需要實驗測試。這里給出一個更快捷穩(wěn)妥的方案:借鑒PET本質(zhì)上也是在訓(xùn)練MLM 任務(wù),我們可以先利用利用PET做fine-tuning,然后將最優(yōu)模型作為預(yù)訓(xùn)練后的模型來進行分類任務(wù)fine-tuning,這種方案我實驗后的結(jié)論是與直接進行Task transfer性能提升上相差不大。不了解PET的可以查看我之前博文PET-文本分類的又一種妙解[6].
how to fine-tuning
不同的fine-tuning 方法也是影響下游任務(wù)性能的關(guān)鍵因素。
optimizer
關(guān)于優(yōu)化方案上,Bert 的論文中建議使用與bert 預(yù)訓(xùn)練時一致的方案進行fine-tuning,即使用weighted decay修正后的Adam,并使用warmup策略 搭配線性衰減的學(xué)習(xí)率。不熟悉的同學(xué)可以查看我之前的博文optimizer of bert[7]
learning rate
不合適的learning rate可能會導(dǎo)致災(zāi)難性遺忘,通常learning rate 在 之間,更大的learning rate可能就會發(fā)生災(zāi)難性遺忘,不利于優(yōu)化。
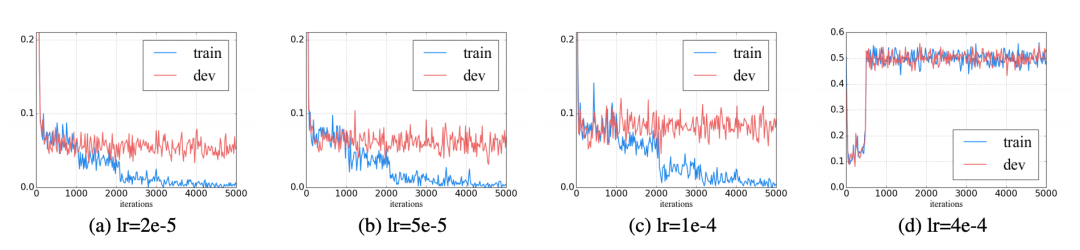
此外,對transformer 逐層降低學(xué)習(xí)率也能降低發(fā)生災(zāi)難性遺忘的同時提升一些性能。
multi-task
Bert在預(yù)訓(xùn)練時,使用了兩個task:NSP 和 MLM,那在下游任務(wù)中,增加一個輔助的任務(wù)是否能帶來提升呢?答案是否定的。如我之前嘗試過在分類任務(wù)的同時,增加一個相似性任務(wù):讓樣本與label desc的得分高于樣本與其他樣本的得分,但是最終性能并沒有得到提升。具體的實驗過程請看博文模型增強之從label下手[8]。
此外,論文How to Fine-Tune BERT for Text Classification?[9]也任務(wù)multi-task不能帶來下游任務(wù)的提升。
which layer
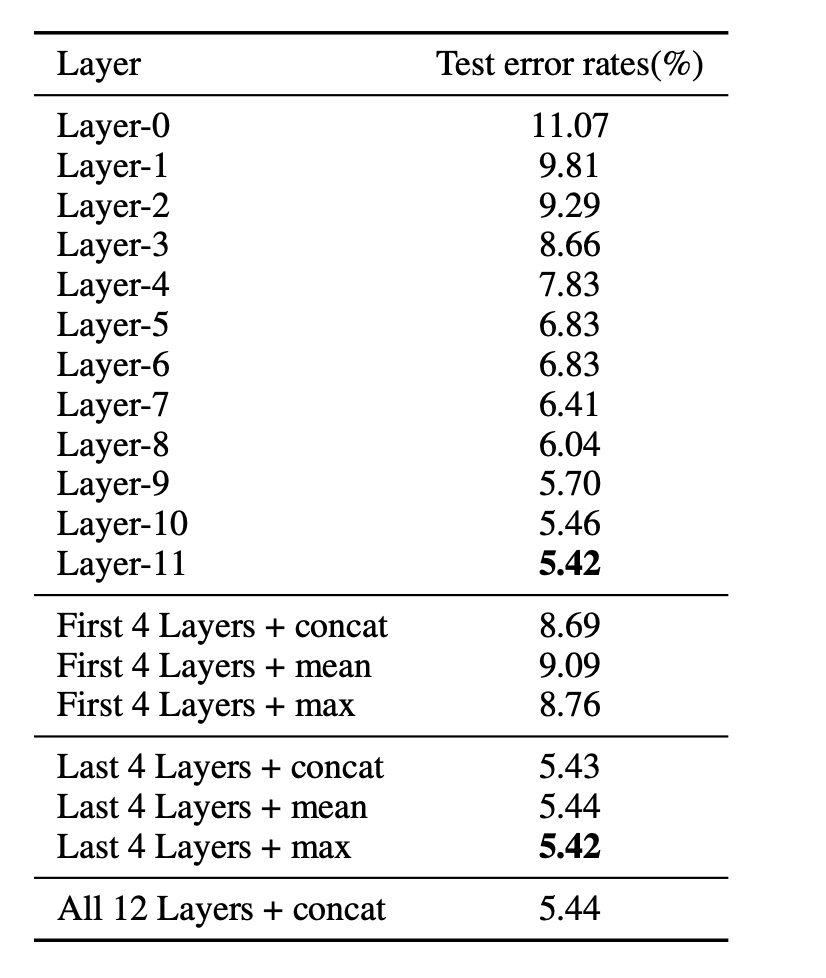
Bert的結(jié)構(gòu)上是一個12層的transformer,在做文本分類時,通常我們是直接使用最后一層的[CLS]來做fine-tuning,這樣是最優(yōu)的嗎?有沒有更好的方案?
論文How to Fine-Tune BERT for Text Classification?[10]中針對這個問題也做了實驗,對比了不同的layer不同的抽取策略,最終結(jié)論是所有層拼接效果最好,但是與直接使用最后一層差距不大。
而論文Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model[11]中,作者通過組合多種粒度的語義信息,即將12層的[CLS]拼接后,送人CNN,在Hate Speech Detection 中能帶來8個點的提升!cnn.png)
所以在fine-tuning時,也可以想一想到底是哪種粒度的語義信息對任務(wù)更重要。
Self-Knowledge Distillation
self-knowledge distillation(自蒸餾)也是一種常用的提升下游任務(wù)的手段。做法是先在Task data上fine-tuning 一個模型,然后通過模型得到Task data 的soft labels,然后使用soft labels 代替hard label 進行fine-tuning。更多細(xì)節(jié)可以查看之前的博文Knowledge Distillation之知識遷移[12]
知識注入
通過注入外部知識到bert中也能提升Bert的性能,常用的方式主要有兩種:
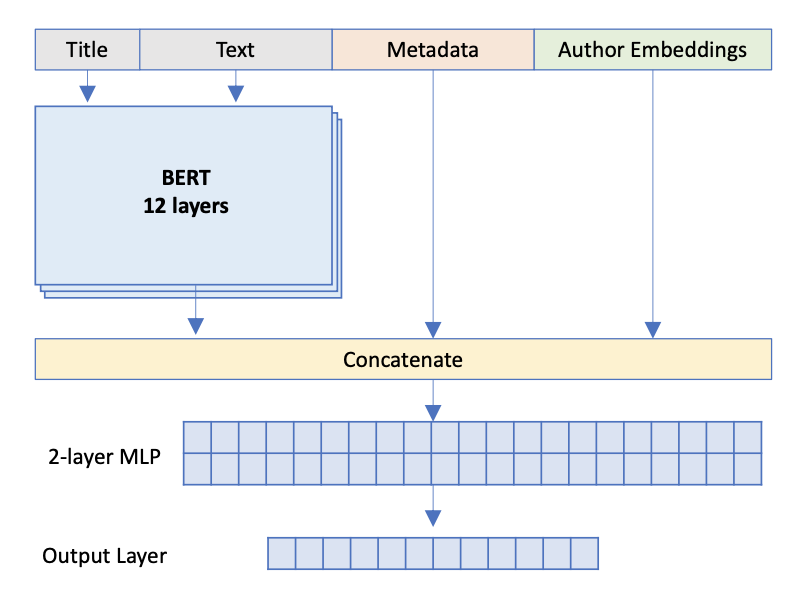
在bert embedding 層注入:通過將外部Embedding 與Bert token-embedding 拼接(相加)進行融合,然后進行transformer一起作用下游;
在transformer的最后一層,拼接外部embedding,然后一起作用下游。
如Enriching BERT with Knowledge Graph Embeddings for Document Classification[13]中,通過在transformer的最后一層中拼接其他信息,提高模型的性能。
數(shù)據(jù)增強
NLP中數(shù)據(jù)增強主要有兩種方式:一種是保持語義的數(shù)據(jù)增強,一種是可能破壞語義的局部擾動增強。
保持語義通常采用回譯法,局部擾動的通常使用EDA,更多細(xì)節(jié)可以查看之前博文NLP中的數(shù)據(jù)增強[14]
原文標(biāo)題:【BERT】如何提升BERT在下游任務(wù)中的性能
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
模型
+關(guān)注
關(guān)注
1文章
3298瀏覽量
49071 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22069
原文標(biāo)題:【BERT】如何提升BERT在下游任務(wù)中的性能
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
【「大模型啟示錄」閱讀體驗】如何在客服領(lǐng)域應(yīng)用大模型
如何優(yōu)化MEMS設(shè)計以提高性能
澎峰科技高性能大模型推理引擎PerfXLM解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論