 MLPerf Inference基準測試結果的第二輪發布
MLPerf Inference基準測試結果的第二輪發布
今天是MLPerf Inference基準測試結果的第二輪發布(0.7版)。與7月份宣布的最新培訓結果一樣,新的推論數字表明提交的公司數量有所增加,支持的平臺和工作負載也有所增加。MLPerf推斷編號分為四類-數據中心,邊緣,移動和筆記本。提交的數量從43個增加到327個,提交的公司數量從僅僅9個增加到21個。提交的公司包括半導體公司,設備OEM和幾個測試實驗室。這輪提交的明顯遺漏包括Google和所有中國公司,包括先前的參與者阿里巴巴和騰訊。
作為快速更新,MLPerf是一個行業協會,旨在開發機器學習(ML)/人工智能(AI)解決方案的標準。MLPerf是一組基準測試的匯編,用于測量ML / AL硬件,軟件和服務的訓練和推理性能。最新的Inference v0.7結果僅是第二次發布推理結果。第一次是大約一年前。MLPerf組織正在不斷努力,以代表真實AI工作負載的新模型或增強模型來增強基準套件。此外,該組織正在努力提高測試頻率,以每年至少兩次為目標,正在考慮允許在主要版本之間發布測試結果,并努力添加其他限定詞,例如用于評估AI平臺效率的功耗數據。測試結果可以由電子價值鏈中的任何公司提供,并可以進行隨機審核。
每個細分類別都包括一個“封閉”和“開放”細分。“封閉”部分是指使用與參考模型相同的工作量模型運行的測試。“開放”部分允許更改模型,以便供應商可以展示相對于其他目標工作負載的性能。此外,還有一些細分市場-當前市場上的產品“可用”,未來六個月內市場上的產品的“預覽”,以及仍在開發中或剛剛考慮的產品的“研究,開發或內部”實驗室項目。為了保持一致,我們大多數分析都集中在封閉和可用的細分上。在某些情況下,產品沒有所有測試的編號,因為沒有提交編號或無法達到最低99%的準確度等級。由于基準套件不斷變化,在套件達到更成熟的狀態之前,將數字與以前的結果進行比較并不是特別有用。但是,從結果中可以收集到很多東西。
對于數據中心應用,推理0.7v測試包括四個新基準測試-代表自然語言處理工作負載的雙向編碼器表示和轉換(BERT),代表推薦工作負載的深度學習推薦模型(DLRM),代表醫學成像的3D U-Net工作量,以及代表語音到文本工作量的遞歸神經網絡轉換器(RNN-T)。在封閉類別中,結果類似于7月份發布的培訓測試結果。加速平臺在性能上大大超過了純CPU平臺,領先的加速器是GPU,領先的GPU則是英偉達基于Ampere架構的新型A-100 GPU。在每個工作負載中,前任領導者特斯拉(T4)GPU的性能提升顯然是顯而易見的。這證明了Ampere架構的價值,該架構允許在單個GPU上進行七個推理分區。在其他加速器方面,僅Xilinx FPGA代表并且僅在開放類別中。
責任編輯:lq
-
人工智能
+關注
關注
1794文章
47642瀏覽量
239650 -
機器學習
+關注
關注
66文章
8438瀏覽量
132928 -
深度學習
+關注
關注
73文章
5512瀏覽量
121410 -
MLPerf
+關注
關注
0文章
35瀏覽量
647
發布評論請先 登錄
相關推薦
MLCommons推出AI基準測試0.5版
上海貝嶺推出第二代高精度基準電壓源
Sam Altman親自推銷Rain AI尋求新融資
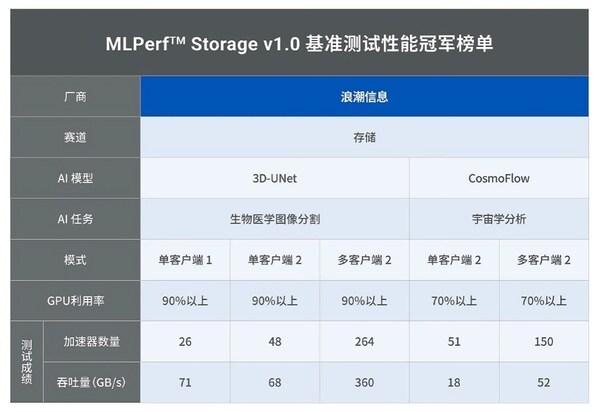
浪潮信息AS13000G7榮獲MLPerf? AI存儲基準測試五項性能全球第一
Applied Intuition再獲3億美元融資,加速AI技術布局
PhotonVentures基金募資達7500萬歐元,開發集成光子學的“深度技術”
華為Pura 70新機悄然發售,全年銷量有望破5000萬臺
UL Procyon AI 發布圖像生成基準測試,基于Stable Diffusion
連接器企業盛凌電子深交所IPO新進展
九州風神沖刺北交所IPO
九州風神北交所IPO新進展
九州風神北交所IPO迎新進展!主打高性能散熱器,募資5億進軍馬來西亞和歐洲市場
三星電子薪資談判困局,罷工危機隱現
Vision Board/首款ARM Cortex-M85開發板價格大公開






 工商網監
工商網監
評論