") PWIL:不依賴對(duì)抗性的新型模擬學(xué)習(xí)
PWIL:不依賴對(duì)抗性的新型模擬學(xué)習(xí)
強(qiáng)化學(xué)習(xí) (Reinforcement Learning,RL) 是一種通過(guò)反復(fù)試驗(yàn)訓(xùn)練智能體 (Agent) 在復(fù)雜環(huán)境中有序決策的范式,在游戲、機(jī)器人操作和芯片設(shè)計(jì)等眾多領(lǐng)域都取得了巨大成功。智能體的目標(biāo)通常是最大化在環(huán)境中收集的總獎(jiǎng)勵(lì) (Reward),這可以基于速度、好奇心、美學(xué)等各種參數(shù)。然而,由于 RL 獎(jiǎng)勵(lì)函數(shù)難以指定或過(guò)于稀疏,想要設(shè)計(jì)具體的 RL 獎(jiǎng)勵(lì)函數(shù)并非易事。
游戲
https://ai.googleblog.com/2019/06/introducing-google-research-football.html
這種情況下,模仿學(xué)習(xí)(Imitation Learning,IL) 方法便派上了用場(chǎng),因?yàn)檫@種方法通過(guò)專家演示而不是精心設(shè)計(jì)的獎(jiǎng)勵(lì)函數(shù)來(lái)學(xué)習(xí)如何完成任務(wù)。然而,最前沿 (SOTA) 的 IL 方法均依賴于對(duì)抗訓(xùn)練,這種訓(xùn)練使用最小化/最大化優(yōu)化過(guò)程,但在算法上不穩(wěn)定并且難以部署。
在“原始 Wasserstein 模仿學(xué)習(xí)”(Primal Wasserstein Imitation Learning,PWIL) 中,我們基于 Wasserstein 距離(也稱為推土機(jī)距離)的原始形式引入了一種新的 IL 方法,這種方法不依賴對(duì)抗訓(xùn)練。借助 MuJoCo 任務(wù)套件,我們通過(guò)有限數(shù)量的演示(甚至是單個(gè)示例)以及與環(huán)境的有限交互來(lái)模仿模擬專家,以此證明 PWIL 方法的有效性。
原始 Wasserstein 模仿學(xué)習(xí)
https://arxiv.org/pdf/2006.04678.pdf
MuJoCo 任務(wù)套件
https://gym.openai.com/envs/#mujoco

左圖:使用任務(wù)的真實(shí)獎(jiǎng)勵(lì)(與速度有關(guān))訓(xùn)練的算法類人機(jī)器人“專家”;右圖:使用 PWIL 基于專家演示訓(xùn)練的智能體
對(duì)抗模仿學(xué)習(xí)
最前沿的對(duì)抗 IL 方法的運(yùn)作方式與生成對(duì)抗網(wǎng)絡(luò) (GAN) 類似:訓(xùn)練生成器(策略)以最大化判別器(獎(jiǎng)勵(lì))的混淆度,以便判別器本身被訓(xùn)練來(lái)區(qū)分智能體的狀態(tài)-動(dòng)作對(duì)和專家的狀態(tài)-動(dòng)作對(duì)。對(duì)抗 IL 方法可以歸結(jié)為分布匹配問(wèn)題,即最小化度量空間中概率分布之間距離的問(wèn)題。不過(guò),就像 GAN 一樣,對(duì)抗 IL 方法也依賴于最小化/最大化優(yōu)化問(wèn)題,因此在訓(xùn)練穩(wěn)定性方面面臨諸多挑戰(zhàn)。
訓(xùn)練穩(wěn)定性方面面臨諸多挑戰(zhàn)
https://developers.google.com/machine-learning/gan/problems
模仿學(xué)習(xí)歸結(jié)為分步匹配
PWIL 方法的原理是將 IL 表示為分布匹配問(wèn)題(在本例中為 Wasserstein 距離)。第一步為從演示中推斷出專家的狀態(tài)-動(dòng)作分布:即專家采取的動(dòng)作與相應(yīng)環(huán)境狀態(tài)之間的關(guān)系的集合。接下來(lái)的目標(biāo)是通過(guò)與環(huán)境的交互來(lái)最大程度地減少智能體的狀態(tài)-動(dòng)作分布與專家的狀態(tài)-動(dòng)作分布之間的距離。相比之下,PWIL 是一種非對(duì)抗方法,因此可繞過(guò)最小化/最大化優(yōu)化問(wèn)題,直接最小化智能體的狀態(tài)-動(dòng)作對(duì)分布與專家的狀態(tài)-動(dòng)作對(duì)分布之間的 Wasserstein 距離。
PWIL 方法
計(jì)算精確的 Wasserstein 距離會(huì)受到限制(智能體軌跡結(jié)束時(shí)才能計(jì)算出),這意味著只有在智能體與環(huán)境交互完成后才能計(jì)算獎(jiǎng)勵(lì)。為了規(guī)避這種限制,我們?yōu)榫嚯x設(shè)置了上限,可以據(jù)此定義使用 RL 優(yōu)化的獎(jiǎng)勵(lì)。
結(jié)果表明,通過(guò)這種方式,我們確實(shí)可以還原專家的行為,并在 MuJoCo 模擬器的許多運(yùn)動(dòng)任務(wù)中最小化智能體與專家之間的 Wasserstein 距離。對(duì)抗 IL 方法使用來(lái)自神經(jīng)網(wǎng)絡(luò)的獎(jiǎng)勵(lì)函數(shù),因此,當(dāng)智能體與環(huán)境交互時(shí),必須不斷對(duì)函數(shù)進(jìn)行優(yōu)化和重新估計(jì),而 PWIL 根據(jù)專家演示離線定義一個(gè)不變的獎(jiǎng)勵(lì)函數(shù),并且它所需的超參數(shù)量遠(yuǎn)遠(yuǎn)低于基于對(duì)抗的 IL 方法。
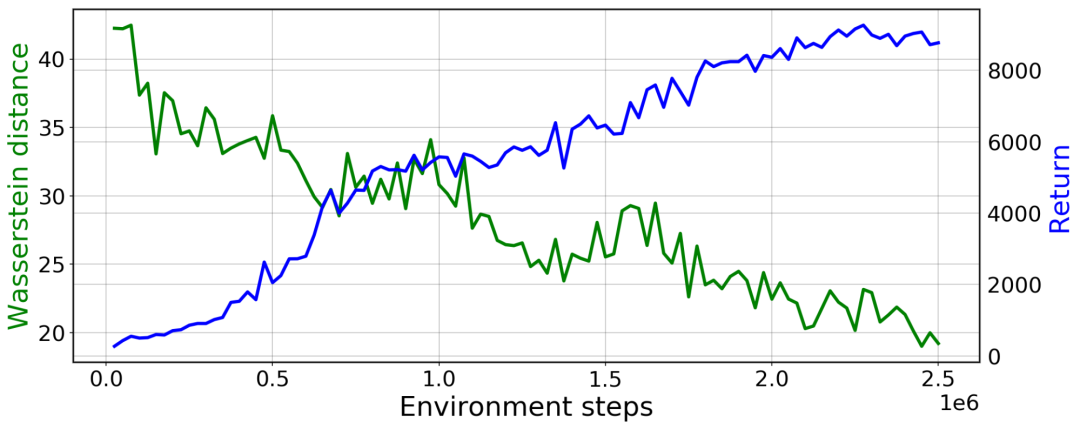
PWIL 在類人機(jī)器人上的訓(xùn)練曲線:綠色表示與專家狀態(tài)-動(dòng)作分布的 Wasserstein 距離;藍(lán)色表示智能體的回報(bào)(所收集獎(jiǎng)勵(lì)的總和)
類人機(jī)器人
https://gym.openai.com/envs/Humanoid-v2/
衡量真實(shí)模仿學(xué)習(xí)環(huán)境的相似度
與 ML 領(lǐng)域的眾多挑戰(zhàn)類似,許多 IL 方法都在合成任務(wù)上進(jìn)行評(píng)估,其中通常有一種方法可以使用任務(wù)的底層獎(jiǎng)勵(lì)函數(shù),并且可以根據(jù)性能(即預(yù)期的獎(jiǎng)勵(lì)總和)來(lái)衡量專家行為與智能體行為之間的相似度。
PWIL 過(guò)程中會(huì)創(chuàng)建一個(gè)指標(biāo),該指標(biāo)可以針對(duì)任何 IL 方法。這種方法能將專家行為與智能體行為進(jìn)行比較,而無(wú)需獲得真正的任務(wù)獎(jiǎng)勵(lì)。從這個(gè)意義上講,我們可以在真正的 IL 環(huán)境中使用 Wasserstein 距離,而不僅限于合成任務(wù)。
結(jié)論
在交互成本較高的環(huán)境(例如,真實(shí)的機(jī)器人或復(fù)雜的模擬器)中,PWIL 可以作為首選方案,不僅因?yàn)樗梢赃€原專家的行為,還因?yàn)樗x的獎(jiǎng)勵(lì)函數(shù)易于調(diào)整,且無(wú)需與環(huán)境交互即可定義。
這為未來(lái)的探索提供了許多機(jī)會(huì),包括部署到實(shí)際系統(tǒng)、將 PWIL 擴(kuò)展到只能使用演示狀態(tài)(而不是狀態(tài)和動(dòng)作)的設(shè)置,以及最終將 PWIL 應(yīng)用于基于視覺(jué)的觀察。
責(zé)任編輯:lq
-
模擬器
+關(guān)注
關(guān)注
2文章
881瀏覽量
43363 -
智能體
+關(guān)注
關(guān)注
1文章
164瀏覽量
10608 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11284
原文標(biāo)題:PWIL:不依賴對(duì)抗性的新型模擬學(xué)習(xí)
文章出處:【微信號(hào):tensorflowers,微信公眾號(hào):Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
魯棒性在機(jī)器學(xué)習(xí)中的重要性
鑒源實(shí)驗(yàn)室·如何通過(guò)雷達(dá)攻擊自動(dòng)駕駛汽車-針對(duì)點(diǎn)云識(shí)別模型的對(duì)抗性攻擊的科普
原生鴻蒙系統(tǒng)正式發(fā)布,余承東宣布不依賴國(guó)外核心技術(shù)
N型插頭具備溫度抗性嗎

FORT單元-不依賴GPS的步跟蹤定位穿戴設(shè)備@PNI

HDS-6智能型模擬斷路器使用說(shuō)明

深度學(xué)習(xí)的典型模型和訓(xùn)練過(guò)程
VBS雷達(dá)智能對(duì)抗仿真控制系統(tǒng)
智能型模擬斷路器如何使用?——每日了解電力知識(shí)

模擬電子電路學(xué)習(xí)教程
深度學(xué)習(xí)生成對(duì)抗網(wǎng)絡(luò)(GAN)全解析
5V 4:1 通用型模擬多路復(fù)用器TMUX1204數(shù)據(jù)表

百度CEO李彥宏:不會(huì)受制于美國(guó)限制,中國(guó)AI發(fā)展仍有強(qiáng)大動(dòng)力
隨機(jī)通信下多智能體系統(tǒng)的干擾攻擊影響研究






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論