") 三種pooling策略的對(duì)比
三種pooling策略的對(duì)比
?一、背景介紹
BERT和RoBERTa在文本語(yǔ)義相似度等句子對(duì)的回歸任務(wù)上,已經(jīng)達(dá)到了SOTA的結(jié)果。但是,它們都需要把兩個(gè)句子同時(shí)喂到網(wǎng)絡(luò)中,這樣會(huì)導(dǎo)致巨大的計(jì)算開銷:從10000個(gè)句子中找出最相似的句子對(duì),大概需要5000萬(wàn)(C100002=49,995,000)個(gè)推理計(jì)算,在V100GPU上耗時(shí)約65個(gè)小時(shí)。這種結(jié)構(gòu)使得BERT不適合語(yǔ)義相似度搜索,同樣也不適合無(wú)監(jiān)督任務(wù)(例如:聚類)。
本文基于BERT網(wǎng)絡(luò)做了修改,提出了Sentence-BERT(SBERT)網(wǎng)絡(luò)結(jié)構(gòu),該網(wǎng)絡(luò)結(jié)構(gòu)利用孿生網(wǎng)絡(luò)和三胞胎網(wǎng)絡(luò)結(jié)構(gòu)生成具有語(yǔ)義意義的句子embedding向量,語(yǔ)義相近的句子其embedding向量距離就比較近,從而可以用來進(jìn)行相似度計(jì)算(余弦相似度、曼哈頓距離、歐式距離)。該網(wǎng)絡(luò)結(jié)構(gòu)在查找最相似的句子對(duì),從上述的65小時(shí)大幅降低到5秒(計(jì)算余弦相似度大概0.01s),精度能夠依然保持不變。這樣SBERT可以完成某些新的特定任務(wù),例如相似度對(duì)比、聚類、基于語(yǔ)義的信息檢索。
二、模型介紹
1)pooling策略
SBERT在BERT/RoBERTa的輸出結(jié)果上增加了一個(gè)pooling操作,從而生成一個(gè)固定大小的句子embedding向量。實(shí)驗(yàn)中采取了三種pooling策略做對(duì)比:
直接采用CLS位置的輸出向量代表整個(gè)句子的向量表示
MEAN策略,計(jì)算各個(gè)token輸出向量的平均值代表句子向量
MAX策略,取所有輸出向量各個(gè)維度的最大值代表句子向量
三個(gè)策略的實(shí)驗(yàn)對(duì)比效果如下:
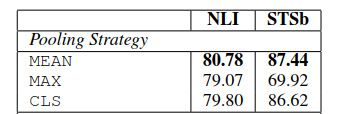
可見三個(gè)策略中,MEAN策略是效果最好的,所以后面實(shí)驗(yàn)?zāi)J(rèn)采用的是MEAN策略。
2)模型結(jié)構(gòu)
為了能夠fine-tune BERT/RoBERTa,文章采用了孿生網(wǎng)絡(luò)和三胞胎網(wǎng)絡(luò)來更新權(quán)重參數(shù),以達(dá)到生成的句子向量具有語(yǔ)義意義。該網(wǎng)絡(luò)結(jié)構(gòu)依賴于具體的訓(xùn)練數(shù)據(jù),文中實(shí)驗(yàn)了下面幾種結(jié)構(gòu)和目標(biāo)函數(shù):
Classification Objective Function:
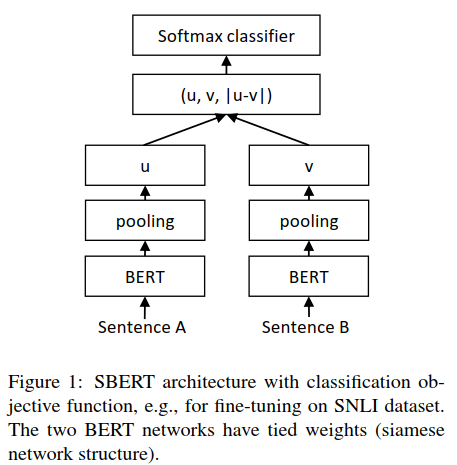
這里將embedding向量u和v以及它們之間的差向量拼接在一起,組成一個(gè)新的向量,乘以權(quán)重參數(shù)Wt∈R3n*k,n表示向量的維度,k是分類標(biāo)簽數(shù)量。
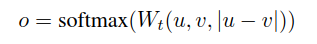
優(yōu)化的時(shí)候采用交叉熵?fù)p失函數(shù)。
Regression Objective Function:
兩個(gè)句子嵌入向量u和v的相似度計(jì)算結(jié)構(gòu)如下:
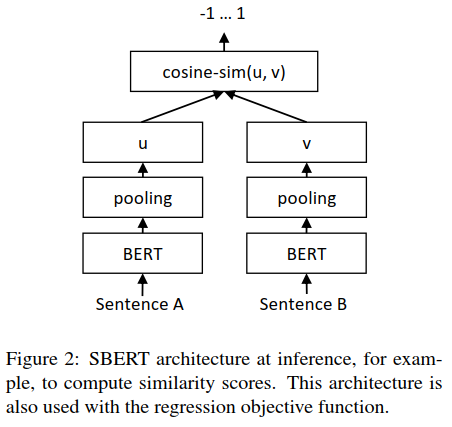
采取MAE(mean squared error)損失作為優(yōu)化的目標(biāo)函數(shù)。
Triplet Objective Function:
給定一個(gè)主句a、一個(gè)正面句子p和一個(gè)負(fù)面句子n,三元組損失調(diào)整網(wǎng)絡(luò),使得a和p之間的距離小于a和n之間的距離。數(shù)學(xué)上,我們最小化以下?lián)p失函數(shù):
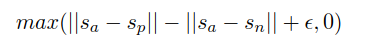
s表示a、p、n的句子嵌入向量,||·||表示距離,邊緣參數(shù)ε表示sp與sa的距離至少比sn近ε。
3)模型訓(xùn)練
文中訓(xùn)練結(jié)合了SNLI(Stanford Natural Language Inference)和Multi-Genre NLI兩種數(shù)據(jù)集。SNLI有570,000個(gè)人工標(biāo)注的句子對(duì),標(biāo)簽分為矛盾、蘊(yùn)含、中立三種;MultiNLI是SNLI的升級(jí)版,格式和標(biāo)簽都一樣,有430,000個(gè)句子對(duì),主要是一系列口語(yǔ)和書面語(yǔ)文本。文本蘊(yùn)含關(guān)系描述的是兩個(gè)文本之間的推理關(guān)系,其中一個(gè)文本作為前提(premise),另一個(gè)文本作為假設(shè)(hypothesis),如果根據(jù)前提P能夠推理得出假設(shè)H,那么就說P蘊(yùn)含H,記做P->H。參考樣例如下:

實(shí)驗(yàn)時(shí),每個(gè)epoch作者用3-way softmax分類目標(biāo)函數(shù)對(duì)SBERT進(jìn)行fine-tune,batch_size=16,采用Adam優(yōu)化器,learning rate=2e-5,pooling策略是MEAN。
三、評(píng)測(cè)-語(yǔ)義文本相似度(Semantic Textual Similarity-STS)
在評(píng)測(cè)的時(shí)候,這里采用余弦相似度來比較兩個(gè)句子向量的相似度。
1)無(wú)監(jiān)督STS
本次評(píng)測(cè)采用的是STS 2012-2016 五年的任務(wù)數(shù)據(jù)、STS benchmark數(shù)據(jù)(2017年構(gòu)建)、SICK-Relatedness數(shù)據(jù),這些數(shù)據(jù)集都是標(biāo)好label的句子對(duì),label表示句子之間的相互關(guān)系,范圍為0~5,樣例如下:

無(wú)監(jiān)督評(píng)測(cè)不采用這些數(shù)據(jù)集的任何訓(xùn)練數(shù)據(jù),直接用上述訓(xùn)練好的模型來計(jì)算句子間的相似度,然后通過斯皮爾曼等級(jí)相關(guān)系數(shù)來衡量模型的優(yōu)劣。結(jié)果如下:
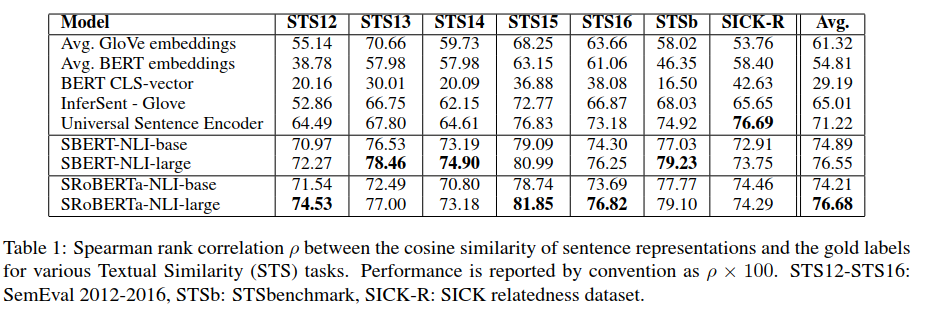
結(jié)果顯示直接采用BERT的輸出結(jié)果,效果挺差的,甚至不如直接計(jì)算GloVe嵌入向量的平均值效果好;采用本文的孿生網(wǎng)絡(luò)在NLI數(shù)據(jù)集上fine-tuning后的模型效果明顯要好很多,SBERT和SRoBERTa差異不大。
2)有監(jiān)督STS
有監(jiān)督STS數(shù)據(jù)集采用的是STS benchmark(簡(jiǎn)稱STSb)數(shù)據(jù)集,就是上面提到的2017年抽取構(gòu)建的,是當(dāng)前比較流行的有監(jiān)督STS數(shù)據(jù)集。它主要來自三個(gè)方面:字幕、新聞、論壇,包含8,628個(gè)句子對(duì),訓(xùn)練集5,749,驗(yàn)證集1,500,測(cè)試集1,379。BERT將句子對(duì)同時(shí)輸入網(wǎng)絡(luò),最后再接一個(gè)簡(jiǎn)單的回歸模型作為輸出,目前在此數(shù)據(jù)集上取得了SOTA的效果。
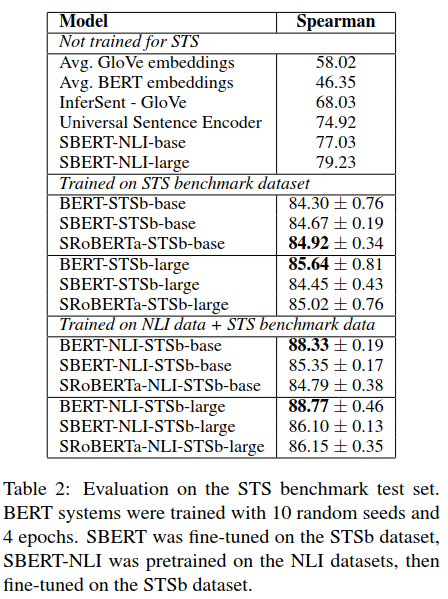
上述實(shí)驗(yàn)結(jié)果分為三塊:
not trained for STS:表示直接采用的是跟上面無(wú)監(jiān)督評(píng)測(cè)一樣的模型,結(jié)果也一樣;
Trained on STS benchmark:表示沒有使用NLI數(shù)據(jù)集,直接在STSb訓(xùn)練數(shù)據(jù)集上利用孿生網(wǎng)絡(luò)結(jié)構(gòu)構(gòu)建回歸模型fine-tuning;
Trained on NLI data+STS benchmark:表示利用孿生網(wǎng)絡(luò)先在NLI數(shù)據(jù)集上訓(xùn)練分類模型學(xué)習(xí)句子向量表示,然后在STSb訓(xùn)練集上再利用回歸模型再次學(xué)習(xí)句子embedding,相當(dāng)于利用兩種數(shù)據(jù)集進(jìn)行了兩次fine-tuning。
評(píng)測(cè)的時(shí)候都是采用的STSb的測(cè)試集進(jìn)行評(píng)測(cè)。可以看到,最后一種訓(xùn)練方式表現(xiàn)最好,尤其單純的BERT架構(gòu)有較大的提升幅度。
四、評(píng)測(cè)-SentEval
SentEval是一個(gè)當(dāng)前流行的用來評(píng)測(cè)句子embedding質(zhì)量的工具,這里句子embedding可以作為邏輯回歸模型的特征,從而構(gòu)建一個(gè)分類器,并在test集上計(jì)算其精度。這里利用SentEval工具在下面幾個(gè)遷移任務(wù)上對(duì)比SBERT與其它生成句子embedding的方法:
MR(movie review):電影評(píng)論片段的情感預(yù)測(cè),二分類
CR(product review):顧客產(chǎn)品評(píng)論的情感預(yù)測(cè),二分類
SUBJ(subjectivity status):電影評(píng)論和情節(jié)摘要中句子的主觀性預(yù)測(cè),二分類
MPQA(opinion-polarity):來自新聞網(wǎng)的短語(yǔ)級(jí)意見極性分類,二分類
SST(Stanford sentiment analysis):斯坦福情感樹庫(kù),二分類
TREC(question-type classification):來自TREC的細(xì)粒度問題類型分類,多分類
MRPC:Microsoft Research Paraphrase Corpus from parallel news sources,釋義檢測(cè)。
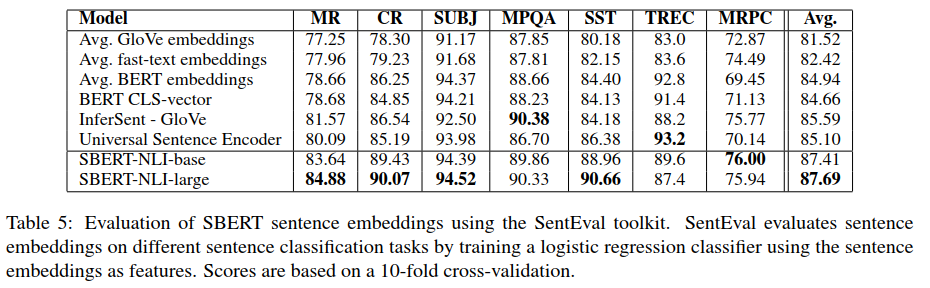
實(shí)驗(yàn)結(jié)果顯示,SBERT生成的句子向量似乎能夠很好捕獲情感信息,在MR、CR、SST上都有較大的提升;BERT在之前的STS數(shù)據(jù)集上表現(xiàn)比較差,但是在SentEval上卻有了不錯(cuò)的效果表現(xiàn),這是因?yàn)镾TS數(shù)據(jù)集上利用余弦相似度衡量句子向量,余弦相似度對(duì)于向量的每一個(gè)維度都是同等的,然而SentEval是利用邏輯回歸分類器來評(píng)測(cè),這樣某些維度會(huì)對(duì)最終的分類結(jié)果產(chǎn)生影響。
所以,BERT的直接輸出結(jié)果無(wú)論是CLS位置的還是平均embedding都不適合用來計(jì)算余弦相似度、曼哈頓距離和歐式距離。雖然BERT在SentEval上面表現(xiàn)稍微好一些,但是基于NLI數(shù)據(jù)集的SBERT還是達(dá)到了SOTA的效果。
五、消融研究
為了對(duì)SBERT的不同方面進(jìn)行消融研究,以便更好地了解它們的相對(duì)重要性,我們?cè)赟NLI和Multi-NLI數(shù)據(jù)集上構(gòu)建了分類模型,在STSb數(shù)據(jù)集上構(gòu)建了回歸模型。在pooling策略上,對(duì)比了MEAN、MAX、CLS三種策略;在分類目標(biāo)函數(shù)中,對(duì)比了不同的向量組合方式。結(jié)果如下:
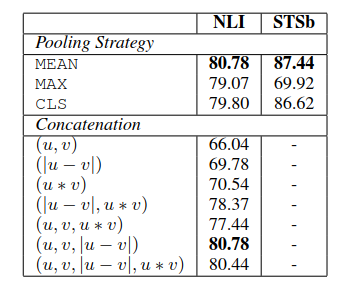
在pooling策略上,MEAN效果最好;在向量組合模式上,只有在分類訓(xùn)練的時(shí)候才使用,結(jié)果顯示element-wise的|u-v|影響最大。
責(zé)任編輯:xj
原文標(biāo)題:Sentence-BERT: 一種能快速計(jì)算句子相似度的孿生網(wǎng)絡(luò)
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5511瀏覽量
121391 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
289瀏覽量
13381
原文標(biāo)題:Sentence-BERT: 一種能快速計(jì)算句子相似度的孿生網(wǎng)絡(luò)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
示波器的三種觸發(fā)模式
三種封裝形式下的400G光模塊概述
什么是PID調(diào)節(jié)器的三種模式
I2S有左對(duì)齊,右對(duì)齊跟標(biāo)準(zhǔn)的I2S三種格式,那么這三種格式各有什么優(yōu)點(diǎn)呢?
基本放大電路有哪三種
mosfet的三種工作狀態(tài)及工作條件是什么
單片機(jī)的三種總線結(jié)構(gòu)
三種功率器件的應(yīng)用區(qū)別

放大電路的三種組態(tài)可以放大什么
晶體管的三種工作狀態(tài)
簡(jiǎn)述斬波電路的三種控制方式
VMware虛擬機(jī)的三種網(wǎng)絡(luò)模式
運(yùn)放的三種應(yīng)用
運(yùn)動(dòng)控制的三種控制方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論