 ARM Cortex-A78、Cortex-X1、Mali-G78三種技術對比
ARM Cortex-A78、Cortex-X1、Mali-G78三種技術對比
2019年5月,ARM發布了Cortex-A77 CPU和Mali-G77 GPU架構(準確說是IP,又稱內核授權),剛剛量產的天璣1000+就是首款同時采用上述IP組合的旗艦級5G SoC。
ARM正式發布了下一代IP,由Cortex-X1、Cortex-A78和Mali-G78組成的“三劍客”,從即將在今年9月發布的麒麟1000開始,未來的5G SoC都將因它們而獲益,并有望進一步拉近與同期蘋果A系列SoC的性能差距。
那么,ARM新一代的“三劍客”都有啥特色?
驍龍865為啥最厲害?CPU和GPU架構了解下!
硬核科普!為啥說SoC的性能取決于架構和工藝?
麒麟990的最大遺憾!ARM Cortex-A77架構到底好在哪?
為啥iPhone總能默秒全?這才是蘋果驕傲的本錢!
Cortex-A78:常規迭代更新
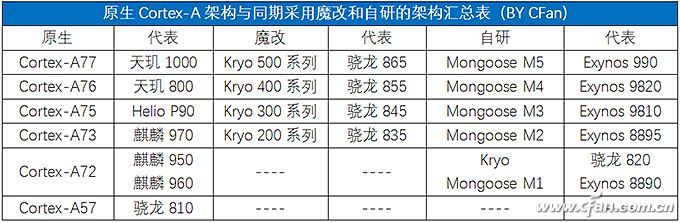
目前,驍龍865、天璣1000和Exyno 980等5G SoC都拿Cortex-A77架構作為CPU中的“大核”,也因此獲得了強悍的運算動力。
作為Cortex-A77的接班人,Cortex-A78其實并沒有什么本質上的變化,Cortex-A76、A77、A78都采用了相同的Austin微架構,三代核心在設計上存在很多共性。
用ARM的話來說,就是芯片供應商(如高通、聯發科等)在構建核心時可以非常容易地升級SoC的IP設計,不會花費太多經歷和成本,從而縮短了開發周期。
因此,大家不要對Cortex-A78性能抱有太大期待,ARM官方數據顯示,A78相較于A77,其IPC(架構性能)只提升了7%,功耗降低了4%,內核小了5%,四核簇面積的縮小了15%。
還好,與Cortex-A78搭配的是最新一代的5nm制程工藝,天生就具備更好的能效比。
現在SoC內單個“大核”在滿載時的功耗約為1W,此時7nm工藝生產的Cortex-A77可以跑到2.6GHz,而5nm工藝生產的Cortex-A78則可達到3GHz,相當于在相同功耗下獲得了20%的性能提升。

另一方面,在相同的性能下,5nm工藝生產的2.1GHz Cortex-A78功耗比7nm工藝2.3GHz的Cortex-A77降低了50%,有助于提高5G手機的續航。
說實話,ARM的這種計算方式令人頭大,不合理也不公平。如果Cortex-A77也用5nm工藝生產,性能也會比7nm工藝時提升不少,功耗也會明顯下降。
反之,如果用7nm工藝生產Cortex-A78,其性能和功耗表現也不見得比Cortex-A77好多少。
只是,新工藝和新架構搭配是科技發展的趨勢也最經濟,還利于宣傳。所以咱們也就別較真兒了。
Cortex-X1:自研的終結
從iPhone 5開始,蘋果A系列處理器就開始了“自研”之旅,而這也是為什么每一代iPhone的性能幾乎都可以領先同期Android手機圈的所有處理器。
所謂的“自研”,就是購買ARM最高級的指令集授權,然后根據自身需要開發兼容ARM的架構,能領先ARM公版的Cortex-A架構多少全看芯片商的技術水平。

高通曾在驍龍600/800時代采用過自研的Krait架構,距離最新的驍龍820也是自研的Kyro。只是,高通發現自研架構的能耗比很難領先公版Cortex-A架構太多,不經濟,所以從驍龍835開始就采取了BoC戰略,也就是咱們常說的“魔改”,基于現有的公版Cortex-A架構進行版定制化。
華為從麒麟980開始,也采用了類似的思路,其大核也是基于Cortex-A架構進行了“based”,同樣是一種魔改。需要注意的是,公版Cortex-A架構可以進行“魔改”的地方并不多,大家基本都是拿緩存部分開刀,所以無論是高通還是麒麟,其魔改后的內核與公版架構之間的性能差異并不大,關鍵還是看主頻。
三星從Exynos 8890開始也加入到自研大軍,并推出了名為貓鼬(Mongoose)的架構核心。但是,經過四代自主研發后,三星在2019年底已經決定放棄自研的Mongoose內核,并解散了位于德州奧斯汀的整個研發團隊,未來將全面使用ARM的設計方案。
可見,除了蘋果,其他芯片商的自研之路可謂一路荊棘,費力不討好。
好消息是,ARM此次發布的“三劍客”中的Cortex-X1,其實就是一種允許芯片商在其上進行高度定制的IP內核,可以完全取代辛苦的“自研”之路。
從ARM公布的架構細節上來看,Cortex-X1與Cortex-A78都是ARMv8.2指令集下的,指令集是兼容的,但Cortex-X1是自定義CPU核,解碼帶寬從4路提升到5路,增加了25%,NEON浮點從2條128b提升到了4條128b,相當于浮點性能翻倍。緩存方面,Cortex-X1的L1緩存可達64KB,L2緩存1MB,L3緩存可達8MB,是Cortex-A78的兩倍。
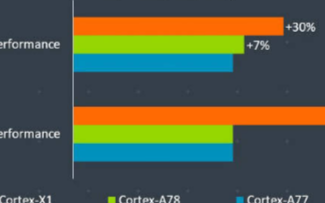
基于以上的改進,Cortex-X1較之上一代A77,其單核性能可提升30%、AI性能更是大漲100%。
按照ARM的規劃,未來Cortex-X1將扮演旗艦級5G SoC內的“超大核”,而Cortex-A78則屬于普通的“大核”,再與Cortex-A55構成“1+3+4”的三叢集DynamIQ集群,以實現性能和功耗的完美平衡。
唯一可惜的,就是Cortex-X1內核會占用更大的封裝面積。ARM的資料顯示,4個Cortex-A78核心在搭配4MB L3緩存時,其性能比前代A77可提升20%,同時核心面積降低15%;而1個Cortex-X1+3個Cortex-A78在搭配8MB L3緩存時,雖然核心面積會增加15%,但峰值性能提升了30%。
換句話說,Cortex-X1至少可以帶來比Cortex-A78額外的10%的性能提升,看起來也不大啊?
Mali-G78:計算單元暴增
在Android領域,ARM公版的Mali系列GPU已經一枝獨秀,昔日的老對手PowerVR已被邊緣化。而新一代Mali-G78 GPU的問世,將進一步鞏固ARM的親兒子在GPU領域的領先地位。
也許是沒有太大的競爭壓力,所以Mali-G78依舊沿用了Mali-G77采用的Valhall圖形架構,但它對全局時鐘域進行了優化,改為全新的兩級結構,實現了上層共享GPU模塊與實際著色器核心頻率的分離,也就是異步時鐘域。這樣一來,GPU的核心可以工作在與其他部分不同的頻率上,可快可慢,從而解決幾何輸出與計算、紋理、引擎之間的不平衡問題,還能讓GPU運行在不同電壓上,從而降低功耗、提高能效,這也是桌面級CPU、GPU通用的做法。
此外,Mali-G78還徹底重寫了FMA(融合乘加)引擎,包括新的乘法架構、新的加法架構、FP32/FP16浮點,可以節省30%的功耗。
在Mali-G77時代,最多可以搭配16個計算單元,也就是Mali-G77 MC16,但受制于成本、發熱和功耗,哪怕是最激進的Exynos 990也才用了11個計算單元,即Mali-G77 MC11,天璣1000+則配備了Mali-G77 MC9。
這一次,Mali-G78最多可以武裝24個計算單元,較之前輩增加了50%。但正如上面的原因,哪怕搭配最新的5nm工藝,估計實際商用的最大規模也就是16個左右,再多手機散熱就壓不住了。
根據ARM的資料顯示,得益于綜合架構、工藝等各方面的改進,Mali-G78相比于Mali-G77的性能提升幅度可達25%,即便是在同等工藝條件下也可提升15%, 同時能效提升10%,機器學習性能提升15%。
看起來還不錯。
此外,ARM還新推出了Mali-G68 GPU,用于填補Mali-G7系列和Mali-G5系之間的空白。從現有的資料來看,Mali-G68的架構和參數和Mali-G78一模一樣,只是最多僅能搭配6個計算單元。
換句話說,搭配1~6個計算單元的Mali-G78就叫Mali-G68,超過6個計算單元的則是Mali-G77。
即將在9月份發布的麒麟1000系列應該是首發Cortex-A78和Mali-G78的5G SoC,但它能否用上Cortex-X1架構還不得而知。而明年上市的驍龍875、天璣2000和Exyno 1000系列也將用上“三劍客”中的至少1個成員,至于它們實際性能較之現有的旗艦能有多少提升,就讓我們拭目以待吧。
-
ARM
+關注
關注
134文章
9164瀏覽量
368625 -
Cortex
+關注
關注
2文章
203瀏覽量
46558 -
Mali
+關注
關注
0文章
3瀏覽量
8914
發布評論請先 登錄
相關推薦
ARM 最新公布Cortex-A78 CPU,并首次推出Cortex-X系列CPU
小編科普Cortex-A78的性能有哪些?
Arm Cortex?A78AE核心技術參考手冊
Mali-G78性能計數器1.2參考指南
Arm Cortex-A78 Core技術參考手冊
Arm即將推出新一代的旗艦CPU、GPU和NPU
ARM推出高性能Cortex-A78C架構 面向筆記本等產品
三星正式宣布了新的Exynos 1080 SoC
Exynos 2100支持14個圖形內核的ARM Mali-G78 GPU
ARM發布Cortex A78C增強版大核架構
ARM發布A78C增強版大核架構,優化筆記本電腦
Arm發布新的Cortex-A78C CPU,預計將為移動設備供電
三星Exynos 1080芯片將由vivo X60系列首發
三星正式發布 5nm 芯片 Exynos 2100:Cortex-X1 超大核,性能大幅提升
Cortex-X1 Arm全新Cortex-X1高性能CPU






 工商網監
工商網監
評論