") slab高速緩存的分類slab高速緩存分為哪兩大類?
slab高速緩存的分類slab高速緩存分為哪兩大類?
虛擬地址
即使是現(xiàn)代操作系統(tǒng)中,內(nèi)存依然是計算機中很寶貴的資源,看看你電腦幾個T固態(tài)硬盤,再看看內(nèi)存大小就知道了。
為了充分利用和管理系統(tǒng)內(nèi)存資源,Linux采用虛擬內(nèi)存管理技術(shù),利用虛擬內(nèi)存技術(shù)讓每個進程都有4GB 互不干涉的虛擬地址空間。
進程初始化分配和操作的都是基于這個「虛擬地址」,只有當(dāng)進程需要實際訪問內(nèi)存資源的時候才會建立虛擬地址和物理地址的映射,調(diào)入物理內(nèi)存頁。
打個不是很恰當(dāng)?shù)谋确剑@個原理其實和現(xiàn)在的某某網(wǎng)盤一樣。假如你的網(wǎng)盤空間是1TB,真以為就一口氣給了你這么大空間嗎?那還是太年輕,都是在你往里面放東西的時候才給你分配空間,你放多少就分多少實際空間給你,但你和你朋友看起來就像大家都擁有1TB空間一樣。
虛擬地址的好處
避免用戶直接訪問物理內(nèi)存地址,防止一些破壞性操作,保護操作系統(tǒng)
每個進程都被分配了4GB的虛擬內(nèi)存,用戶程序可使用比實際物理內(nèi)存更大的地址空間
4GB 的進程虛擬地址空間被分成兩部分:「用戶空間」和「內(nèi)核空間」
用戶空間內(nèi)核空間
物理地址
上面章節(jié)我們已經(jīng)知道不管是用戶空間還是內(nèi)核空間,使用的地址都是虛擬地址,當(dāng)需進程要實際訪問內(nèi)存的時候,會由內(nèi)核的「請求分頁機制」產(chǎn)生「缺頁異常」調(diào)入物理內(nèi)存頁。
把虛擬地址轉(zhuǎn)換成內(nèi)存的物理地址,這中間涉及利用MMU 內(nèi)存管理單元(Memory Management Unit ) 對虛擬地址分段和分頁(段頁式)地址轉(zhuǎn)換,關(guān)于分段和分頁的具體流程,這里不再贅述,可以參考任何一本計算機組成原理教材描述。
段頁式內(nèi)存管理地址轉(zhuǎn)換
Linux 內(nèi)核會將物理內(nèi)存分為3個管理區(qū),分別是:
ZONE_DMA
DMA內(nèi)存區(qū)域。包含0MB~16MB之間的內(nèi)存頁框,可以由老式基于ISA的設(shè)備通過DMA使用,直接映射到內(nèi)核的地址空間。
ZONE_NORMAL
普通內(nèi)存區(qū)域。包含16MB~896MB之間的內(nèi)存頁框,常規(guī)頁框,直接映射到內(nèi)核的地址空間。
ZONE_HIGHMEM
高端內(nèi)存區(qū)域。包含896MB以上的內(nèi)存頁框,不進行直接映射,可以通過永久映射和臨時映射進行這部分內(nèi)存頁框的訪問。
物理內(nèi)存區(qū)劃分
用戶空間
用戶進程能訪問的是「用戶空間」,每個進程都有自己獨立的用戶空間,虛擬地址范圍從從 0x00000000 至 0xBFFFFFFF 總?cè)萘?G 。
用戶進程通常只能訪問用戶空間的虛擬地址,只有在執(zhí)行內(nèi)陷操作或系統(tǒng)調(diào)用時才能訪問內(nèi)核空間。
進程與內(nèi)存
進程(執(zhí)行的程序)占用的用戶空間按照「 訪問屬性一致的地址空間存放在一起 」的原則,劃分成 5個不同的內(nèi)存區(qū)域。訪問屬性指的是“可讀、可寫、可執(zhí)行等 。
代碼段
代碼段是用來存放可執(zhí)行文件的操作指令,可執(zhí)行程序在內(nèi)存中的鏡像。代碼段需要防止在運行時被非法修改,所以只準(zhǔn)許讀取操作,它是不可寫的。
數(shù)據(jù)段
數(shù)據(jù)段用來存放可執(zhí)行文件中已初始化全局變量,換句話說就是存放程序靜態(tài)分配的變量和全局變量。
BSS段
BSS段包含了程序中未初始化的全局變量,在內(nèi)存中 bss 段全部置零。
堆 heap堆是用于存放進程運行中被動態(tài)分配的內(nèi)存段,它的大小并不固定,可動態(tài)擴張或縮減。當(dāng)進程調(diào)用malloc等函數(shù)分配內(nèi)存時,新分配的內(nèi)存就被動態(tài)添加到堆上(堆被擴張);當(dāng)利用free等函數(shù)釋放內(nèi)存時,被釋放的內(nèi)存從堆中被剔除(堆被縮減)
棧 stack棧是用戶存放程序臨時創(chuàng)建的局部變量,也就是函數(shù)中定義的變量(但不包括 static 聲明的變量,static意味著在數(shù)據(jù)段中存放變量)。除此以外,在函數(shù)被調(diào)用時,其參數(shù)也會被壓入發(fā)起調(diào)用的進程棧中,并且待到調(diào)用結(jié)束后,函數(shù)的返回值也會被存放回棧中。由于棧的先進先出特點,所以棧特別方便用來保存/恢復(fù)調(diào)用現(xiàn)場。從這個意義上講,我們可以把堆棧看成一個寄存、交換臨時數(shù)據(jù)的內(nèi)存區(qū)。
上述幾種內(nèi)存區(qū)域中數(shù)據(jù)段、BSS 段、堆通常是被連續(xù)存儲在內(nèi)存中,在位置上是連續(xù)的,而代碼段和棧往往會被獨立存放。堆和棧兩個區(qū)域在 i386 體系結(jié)構(gòu)中棧向下擴展、堆向上擴展,相對而生。
你也可以在linux下用size 命令查看編譯后程序的各個內(nèi)存區(qū)域大小:
[lemon ~]# size /usr/local/sbin/sshd text data bss dec hexfilename1924532 12412 4268962363840 2411c0/usr/local/sbin/sshd
內(nèi)核空間
在 x86 32 位系統(tǒng)里,Linux 內(nèi)核地址空間是指虛擬地址從 0xC0000000 開始到 0xFFFFFFFF 為止的高端內(nèi)存地址空間,總計 1G 的容量, 包括了內(nèi)核鏡像、物理頁面表、驅(qū)動程序等運行在內(nèi)核空間 。
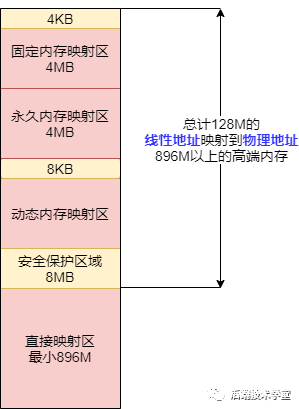
內(nèi)核空間細分區(qū)域。
直接映射區(qū)直接映射區(qū) Direct Memory Region:從內(nèi)核空間起始地址開始,最大896M的內(nèi)核空間地址區(qū)間,為直接內(nèi)存映射區(qū)。
直接映射區(qū)的896MB的「線性地址」直接與「物理地址」的前896MB進行映射,也就是說線性地址和分配的物理地址都是連續(xù)的。內(nèi)核地址空間的線性地址0xC0000001所對應(yīng)的物理地址為0x00000001,它們之間相差一個偏移量PAGE_OFFSET = 0xC0000000該區(qū)域的線性地址和物理地址存在線性轉(zhuǎn)換關(guān)系「線性地址 = PAGE_OFFSET + 物理地址」也可以用 virt_to_phys()函數(shù)將內(nèi)核虛擬空間中的線性地址轉(zhuǎn)化為物理地址。
高端內(nèi)存線性地址空間內(nèi)核空間線性地址從 896M 到 1G 的區(qū)間,容量 128MB 的地址區(qū)間是高端內(nèi)存線性地址空間,為什么叫高端內(nèi)存線性地址空間?下面給你解釋一下:
前面已經(jīng)說過,內(nèi)核空間的總大小 1GB,從內(nèi)核空間起始地址開始的 896MB 的線性地址可以直接映射到物理地址大小為 896MB 的地址區(qū)間。
退一萬步,即使內(nèi)核空間的1GB線性地址都映射到物理地址,那也最多只能尋址 1GB 大小的物理內(nèi)存地址范圍。
請問你現(xiàn)在你家的內(nèi)存條多大?快醒醒都 0202 年了,一般 PC 的內(nèi)存都大于 1GB 了吧!
所以,內(nèi)核空間拿出了最后的 128M 地址區(qū)間,劃分成下面三個高端內(nèi)存映射區(qū),以達到對整個物理地址范圍的尋址。而在 64 位的系統(tǒng)上就不存在這樣的問題了,因為可用的線性地址空間遠大于可安裝的內(nèi)存。
動態(tài)內(nèi)存映射區(qū)
vmalloc Region 該區(qū)域由內(nèi)核函數(shù)vmalloc來分配,特點是:線性空間連續(xù),但是對應(yīng)的物理地址空間不一定連續(xù)。vmalloc 分配的線性地址所對應(yīng)的物理頁可能處于低端內(nèi)存,也可能處于高端內(nèi)存。
永久內(nèi)存映射區(qū)
Persistent Kernel Mapping Region 該區(qū)域可訪問高端內(nèi)存。訪問方法是使用 alloc_page (_GFP_HIGHMEM) 分配高端內(nèi)存頁或者使用kmap函數(shù)將分配到的高端內(nèi)存映射到該區(qū)域。
固定映射區(qū)
Fixing kernel Mapping Region 該區(qū)域和 4G 的頂端只有 4k 的隔離帶,其每個地址項都服務(wù)于特定的用途,如 ACPI_BASE 等。
內(nèi)核空間物理內(nèi)存映射
回顧一下
上面講的有點多,先別著急進入下一節(jié),在這之前我們再來回顧一下上面所講的內(nèi)容。如果認(rèn)真看完上面的章節(jié),我這里再畫了一張圖,現(xiàn)在你的腦海中應(yīng)該有這樣一個內(nèi)存管理的全局圖。
內(nèi)核空間用戶空間全圖
內(nèi)存數(shù)據(jù)結(jié)構(gòu)
要讓內(nèi)核管理系統(tǒng)中的虛擬內(nèi)存,必然要從中抽象出內(nèi)存管理數(shù)據(jù)結(jié)構(gòu),內(nèi)存管理操作如「分配、釋放等」都基于這些數(shù)據(jù)結(jié)構(gòu)操作,這里列舉兩個管理虛擬內(nèi)存區(qū)域的數(shù)據(jù)結(jié)構(gòu)。
用戶空間內(nèi)存數(shù)據(jù)結(jié)構(gòu)
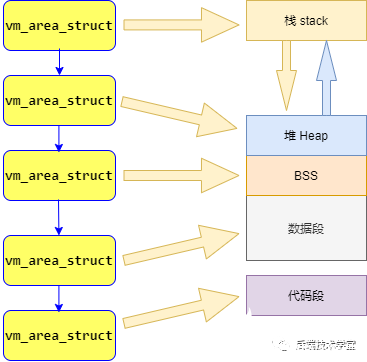
在前面「進程與內(nèi)存」章節(jié)我們提到,Linux進程可以劃分為 5 個不同的內(nèi)存區(qū)域,分別是:代碼段、數(shù)據(jù)段、BSS、堆、棧,內(nèi)核管理這些區(qū)域的方式是,將這些內(nèi)存區(qū)域抽象成vm_area_struct的內(nèi)存管理對象。
vm_area_struct是描述進程地址空間的基本管理單元,一個進程往往需要多個vm_area_struct來描述它的用戶空間虛擬地址,需要使用「鏈表」和「紅黑樹」來組織各個vm_area_struct。
鏈表用于需要遍歷全部節(jié)點的時候用,而紅黑樹適用于在地址空間中定位特定內(nèi)存區(qū)域。內(nèi)核為了內(nèi)存區(qū)域上的各種不同操作都能獲得高性能,所以同時使用了這兩種數(shù)據(jù)結(jié)構(gòu)。
用戶空間進程的地址管理模型:
wm_arem_struct
內(nèi)核空間動態(tài)分配內(nèi)存數(shù)據(jù)結(jié)構(gòu)
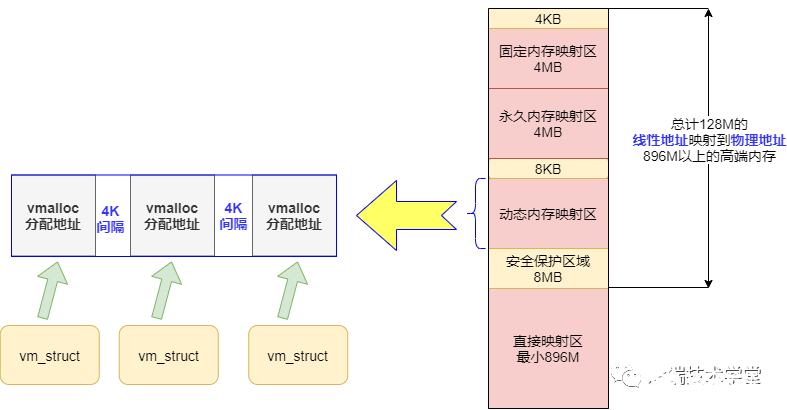
在內(nèi)核空間章節(jié)我們提到過「動態(tài)內(nèi)存映射區(qū)」,該區(qū)域由內(nèi)核函數(shù)vmalloc來分配,特點是:線性空間連續(xù),但是對應(yīng)的物理地址空間不一定連續(xù)。vmalloc 分配的線性地址所對應(yīng)的物理頁可能處于低端內(nèi)存,也可能處于高端內(nèi)存。
vmalloc 分配的地址則限于vmalloc_start與vmalloc_end之間。每一塊vmalloc分配的內(nèi)核虛擬內(nèi)存都對應(yīng)一個vm_struct結(jié)構(gòu)體,不同的內(nèi)核空間虛擬地址之間有4k大小的防越界空閑區(qū)間隔區(qū)。
與用戶空間的虛擬地址特性一樣,這些虛擬地址與物理內(nèi)存沒有簡單的映射關(guān)系,必須通過內(nèi)核頁表才可轉(zhuǎn)換為物理地址或物理頁,它們有可能尚未被映射,當(dāng)發(fā)生缺頁時才真正分配物理頁面。
動態(tài)內(nèi)存映射
前面分析了 Linux 內(nèi)存管理機制,下面深入學(xué)習(xí)物理內(nèi)存管理和虛擬內(nèi)存分配。
通過前面的學(xué)習(xí)我們知道,程序可沒這么好騙,任你內(nèi)存管理把虛擬地址空間玩出花來,到最后還是要給程序?qū)崒嵲谠诘奈锢韮?nèi)存,不然程序就要罷工了。
所以物理內(nèi)存這么重要的資源一定要好好管理起來使用(物理內(nèi)存,就是你實實在在的內(nèi)存條),那么內(nèi)核是如何管理物理內(nèi)存的呢?
物理內(nèi)存管理
在Linux系統(tǒng)中通過分段和分頁機制,把物理內(nèi)存劃分 4K 大小的內(nèi)存頁 Page(也稱作頁框Page Frame),物理內(nèi)存的分配和回收都是基于內(nèi)存頁進行,把物理內(nèi)存分頁管理的好處大大的。
假如系統(tǒng)請求小塊內(nèi)存,可以預(yù)先分配一頁給它,避免了反復(fù)的申請和釋放小塊內(nèi)存帶來頻繁的系統(tǒng)開銷。
假如系統(tǒng)需要大塊內(nèi)存,則可以用多頁內(nèi)存拼湊,而不必要求大塊連續(xù)內(nèi)存。你看不管內(nèi)存大小都能收放自如,分頁機制多么完美的解決方案!
But,理想很豐滿,現(xiàn)實很骨感。如果就直接這樣把內(nèi)存分頁使用,不再加額外的管理還是存在一些問題,下面我們來看下,系統(tǒng)在多次分配和釋放物理頁的時候會遇到哪些問題。
物理頁管理面臨問題
物理內(nèi)存頁分配會出現(xiàn)外部碎片和內(nèi)部碎片問題,所謂的「內(nèi)部」和「外部」是針對「頁框內(nèi)外」而言,一個頁框內(nèi)的內(nèi)存碎片是內(nèi)部碎片,多個頁框間的碎片是外部碎片。
外部碎片當(dāng)需要分配大塊內(nèi)存的時候,要用好幾頁組合起來才夠,而系統(tǒng)分配物理內(nèi)存頁的時候會盡量分配連續(xù)的內(nèi)存頁面,頻繁的分配與回收物理頁導(dǎo)致大量的小塊內(nèi)存夾雜在已分配頁面中間,形成外部碎片,舉個例子:
外部碎片
內(nèi)部碎片物理內(nèi)存是按頁來分配的,這樣當(dāng)實際只需要很小內(nèi)存的時候,也會分配至少是 4K 大小的頁面,而內(nèi)核中有很多需要以字節(jié)為單位分配內(nèi)存的場景,這樣本來只想要幾個字節(jié)而已卻不得不分配一頁內(nèi)存,除去用掉的字節(jié)剩下的就形成了內(nèi)部碎片。
內(nèi)部碎片
頁面管理算法
方法總比困難多,因為存在上面的這些問題,聰明的程序員靈機一動,引入了頁面管理算法來解決上述的碎片問題。
Buddy(伙伴)分配算法Linux 內(nèi)核引入了伙伴系統(tǒng)算法(Buddy system),什么意思呢?就是把相同大小的頁框塊用鏈表串起來,頁框塊就像手拉手的好伙伴,也是這個算法名字的由來。
具體的,所有的空閑頁框分組為11個塊鏈表,每個塊鏈表分別包含大小為1,2,4,8,16,32,64,128,256,512和1024個連續(xù)頁框的頁框塊。最大可以申請1024個連續(xù)頁框,對應(yīng)4MB大小的連續(xù)內(nèi)存。
伙伴系統(tǒng)
因為任何正整數(shù)都可以由 2^n 的和組成,所以總能找到合適大小的內(nèi)存塊分配出去,減少了外部碎片產(chǎn)生 。
分配實例
比如:我需要申請4個頁框,但是長度為4個連續(xù)頁框塊鏈表沒有空閑的頁框塊,伙伴系統(tǒng)會從連續(xù)8個頁框塊的鏈表獲取一個,并將其拆分為兩個連續(xù)4個頁框塊,取其中一個,另外一個放入連續(xù)4個頁框塊的空閑鏈表中。釋放的時候會檢查,釋放的這幾個頁框前后的頁框是否空閑,能否組成下一級長度的塊。
命令查看
[lemon]]# cat /proc/buddyinfo Node 0, zone DMA 1 0 0 0 2 1 1 0 1 1 3 Node 0, zone DMA32 3198 4108 4940 4773 4030 2184 891 180 67 32 330 Node 0, zone Normal 42438 37404 16035 4386 610 121 22 3 0 0 1
slab分配器看到這里你可能會想,有了伙伴系統(tǒng)這下總可以管理好物理內(nèi)存了吧?不,還不夠,否則就沒有slab分配器什么事了。
那什么是slab分配器呢?
一般來說,內(nèi)核對象的生命周期是這樣的:分配內(nèi)存-初始化-釋放內(nèi)存,內(nèi)核中有大量的小對象,比如文件描述結(jié)構(gòu)對象、任務(wù)描述結(jié)構(gòu)對象,如果按照伙伴系統(tǒng)按頁分配和釋放內(nèi)存,對小對象頻繁的執(zhí)行「分配內(nèi)存-初始化-釋放內(nèi)存」會非常消耗性能。
伙伴系統(tǒng)分配出去的內(nèi)存還是以頁框為單位,而對于內(nèi)核的很多場景都是分配小片內(nèi)存,遠用不到一頁內(nèi)存大小的空間。slab分配器,「通過將內(nèi)存按使用對象不同再劃分成不同大小的空間」,應(yīng)用于內(nèi)核對象的緩存。
伙伴系統(tǒng)和slab不是二選一的關(guān)系,slab 內(nèi)存分配器是對伙伴分配算法的補充。
大白話說原理
對于每個內(nèi)核中的相同類型的對象,如:task_struct、file_struct 等需要重復(fù)使用的小型內(nèi)核數(shù)據(jù)對象,都會有個 slab 緩存池,緩存住大量常用的「已經(jīng)初始化」的對象,每當(dāng)要申請這種類型的對象時,就從緩存池的slab 列表中分配一個出去;而當(dāng)要釋放時,將其重新保存在該列表中,而不是直接返回給伙伴系統(tǒng),從而避免內(nèi)部碎片,同時也大大提高了內(nèi)存分配性能。
主要優(yōu)點
slab 內(nèi)存管理基于內(nèi)核小對象,不用每次都分配一頁內(nèi)存,充分利用內(nèi)存空間,避免內(nèi)部碎片。
slab 對內(nèi)核中頻繁創(chuàng)建和釋放的小對象做緩存,重復(fù)利用一些相同的對象,減少內(nèi)存分配次數(shù)。
數(shù)據(jù)結(jié)構(gòu)
slab分配器
kmem_cache 是一個cache_chain 的鏈表組成節(jié)點,代表的是一個內(nèi)核中的相同類型的「對象高速緩存」,每個kmem_cache 通常是一段連續(xù)的內(nèi)存塊,包含了三種類型的 slabs 鏈表:
slabs_full (完全分配的 slab 鏈表)
slabs_partial (部分分配的slab 鏈表)
slabs_empty ( 沒有被分配對象的slab 鏈表)
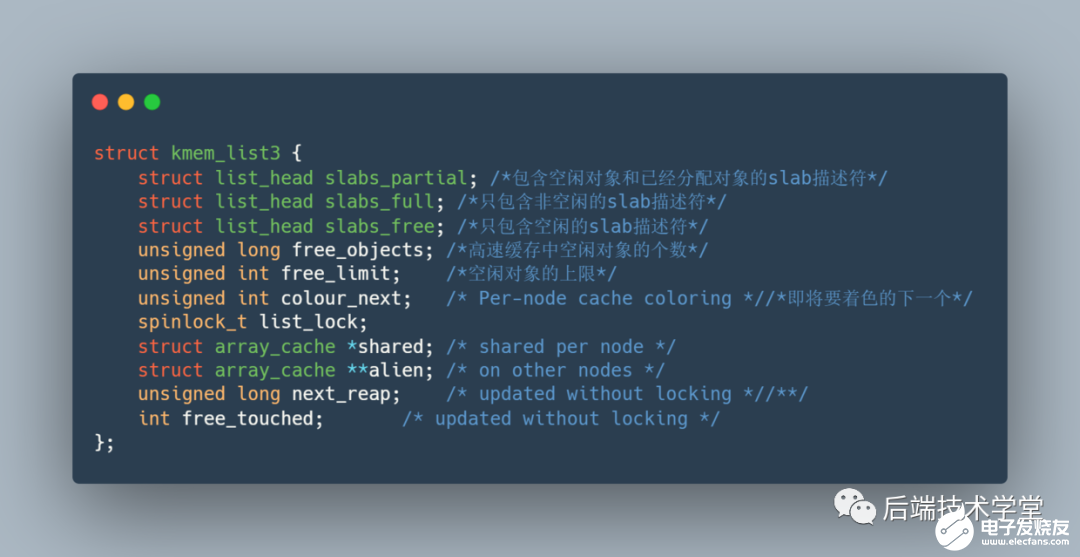
kmem_cache 中有個重要的結(jié)構(gòu)體 kmem_list3 包含了以上三個數(shù)據(jù)結(jié)構(gòu)的聲明。
kmem_list3 內(nèi)核源碼
slab 是slab 分配器的最小單位,在實現(xiàn)上一個 slab 由一個或多個連續(xù)的物理頁組成(通常只有一頁)。單個slab可以在 slab 鏈表之間移動,例如如果一個「半滿slabs_partial鏈表」被分配了對象后變滿了,就要從 slabs_partial 中刪除,同時插入到「全滿slabs_full鏈表」中去。內(nèi)核slab對象的分配過程是這樣的:
如果slabs_partial鏈表還有未分配的空間,分配對象,若分配之后變滿,移動 slab 到slabs_full 鏈表
如果slabs_partial鏈表沒有未分配的空間,進入下一步
如果slabs_empty 鏈表還有未分配的空間,分配對象,同時移動slab進入slabs_partial鏈表
如果slabs_empty為空,請求伙伴系統(tǒng)分頁,創(chuàng)建一個新的空閑slab, 按步驟 3 分配對象
slab分配圖解
命令查看
上面說的都是理論,比較抽象,動動手來康康系統(tǒng)中的 slab 吧!你可以通過 cat /proc/slabinfo 命令,實際查看系統(tǒng)中slab 信息。
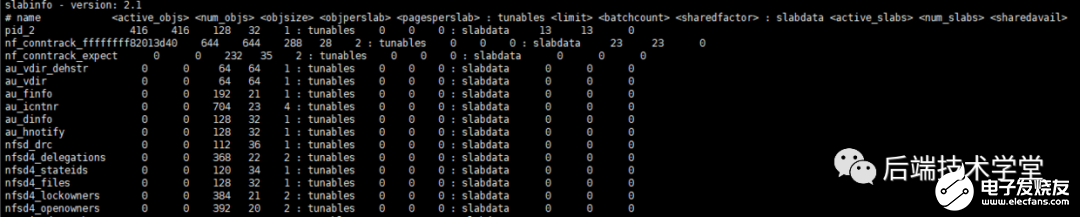
slabinfo查詢
slabtop 實時顯示內(nèi)核 slab 內(nèi)存緩存信息。
slabtop查詢
slab高速緩存的分類slab高速緩存分為兩大類,「通用高速緩存」和「專用高速緩存」。
通用高速緩存
slab分配器中用 kmem_cache 來描述高速緩存的結(jié)構(gòu),它本身也需要 slab 分配器對其進行高速緩存。cache_cache 保存著對「高速緩存描述符的高速緩存」,是一種通用高速緩存,保存在cache_chain 鏈表中的第一個元素。
另外,slab 分配器所提供的小塊連續(xù)內(nèi)存的分配,也是通用高速緩存實現(xiàn)的。通用高速緩存所提供的對象具有幾何分布的大小,范圍為32到131072字節(jié)。內(nèi)核中提供了 kmalloc() 和 kfree() 兩個接口分別進行內(nèi)存的申請和釋放。
專用高速緩存
內(nèi)核為專用高速緩存的申請和釋放提供了一套完整的接口,根據(jù)所傳入的參數(shù)為指定的對象分配slab緩存。
專用高速緩存的申請和釋放
kmem_cache_create() 用于對一個指定的對象創(chuàng)建高速緩存。它從 cache_cache 普通高速緩存中為新的專有緩存分配一個高速緩存描述符,并把這個描述符插入到高速緩存描述符形成的 cache_chain 鏈表中。kmem_cache_destory() 用于撤消和從 cache_chain 鏈表上刪除高速緩存。
slab的申請和釋放
slab 數(shù)據(jù)結(jié)構(gòu)在內(nèi)核中的定義,如下:
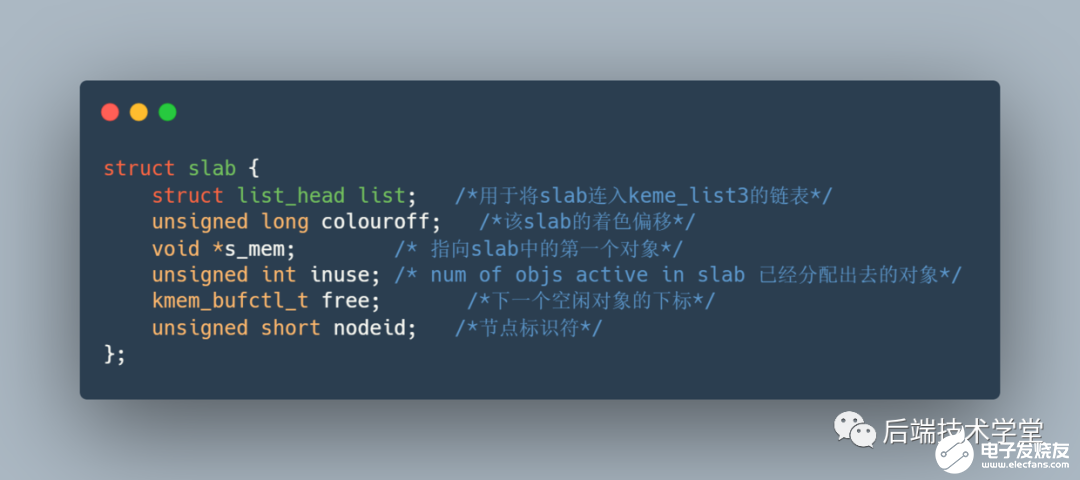
slab結(jié)構(gòu)體內(nèi)核代碼
kmem_cache_alloc() 在其參數(shù)所指定的高速緩存中分配一個slab,對應(yīng)的 kmem_cache_free() 在其參數(shù)所指定的高速緩存中釋放一個slab。
虛擬內(nèi)存分配
前面討論的都是對物理內(nèi)存的管理,Linux 通過虛擬內(nèi)存管理,欺騙了用戶程序假裝每個程序都有 4G 的虛擬內(nèi)存尋址空間(如果這里不懂我說啥,建議回頭看下 別再說你不懂Linux內(nèi)存管理了,10張圖給你安排的明明白白!)。
所以我們來研究下虛擬內(nèi)存的分配,這里包括用戶空間虛擬內(nèi)存和內(nèi)核空間虛擬內(nèi)存。
注意,分配的虛擬內(nèi)存還沒有映射到物理內(nèi)存,只有當(dāng)訪問申請的虛擬內(nèi)存時,才會發(fā)生缺頁異常,再通過上面介紹的伙伴系統(tǒng)和 slab 分配器申請物理內(nèi)存。
用戶空間內(nèi)存分配
mallocmalloc 用于申請用戶空間的虛擬內(nèi)存,當(dāng)申請小于 128KB 小內(nèi)存的時,malloc使用 sbrk或brk 分配內(nèi)存;當(dāng)申請大于 128KB 的內(nèi)存時,使用 mmap 函數(shù)申請內(nèi)存;
存在問題
由于 brk/sbrk/mmap 屬于系統(tǒng)調(diào)用,如果每次申請內(nèi)存都要產(chǎn)生系統(tǒng)調(diào)用開銷,cpu 在用戶態(tài)和內(nèi)核態(tài)之間頻繁切換,非常影響性能。
而且,堆是從低地址往高地址增長,如果低地址的內(nèi)存沒有被釋放,高地址的內(nèi)存就不能被回收,容易產(chǎn)生內(nèi)存碎片。
解決
因此,malloc采用的是內(nèi)存池的實現(xiàn)方式,先申請一大塊內(nèi)存,然后將內(nèi)存分成不同大小的內(nèi)存塊,然后用戶申請內(nèi)存時,直接從內(nèi)存池中選擇一塊相近的內(nèi)存塊分配出去。
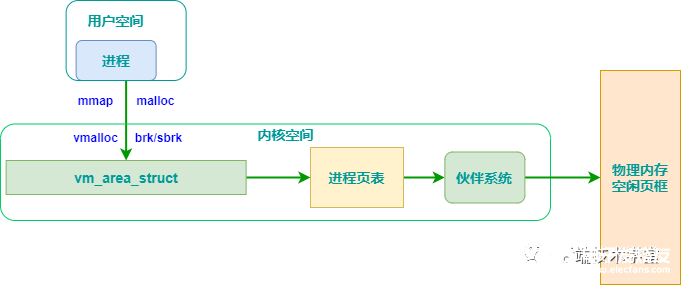
內(nèi)核空間內(nèi)存分配
在講內(nèi)核空間內(nèi)存分配之前,先來回顧一下內(nèi)核地址空間。kmalloc 和 vmalloc 分別用于分配不同映射區(qū)的虛擬內(nèi)存,看這張上次畫的圖:
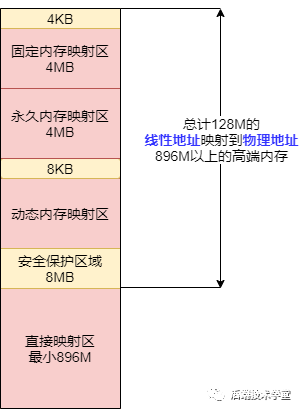
內(nèi)核空間細分區(qū)域
kmallockmalloc() 分配的虛擬地址范圍在內(nèi)核空間的「直接內(nèi)存映射區(qū)」。
按字節(jié)為單位虛擬內(nèi)存,一般用于分配小塊內(nèi)存,釋放內(nèi)存對應(yīng)于 kfree ,可以分配連續(xù)的物理內(nèi)存。函數(shù)原型在 《linux/kmalloc.h》 中聲明,一般情況下在驅(qū)動程序中都是調(diào)用 kmalloc() 來給數(shù)據(jù)結(jié)構(gòu)分配內(nèi)存 。
還記得前面說的 slab 嗎?kmalloc 是基于slab 分配器的 ,同樣可以用cat /proc/slabinfo 命令,查看 kmalloc 相關(guān) slab 對象信息,下面的 kmalloc-8、kmalloc-16 等等就是基于slab分配的 kmalloc 高速緩存。
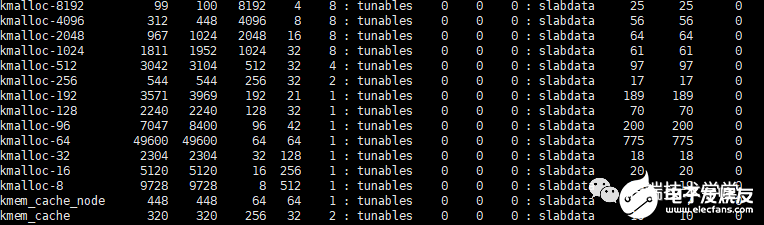
slabinfo-kmalloc
vmallocvmalloc 分配的虛擬地址區(qū)間,位于 vmalloc_start 與vmalloc_end 之間的「動態(tài)內(nèi)存映射區(qū)」。
一般用分配大塊內(nèi)存,釋放內(nèi)存對應(yīng)于 vfree,分配的虛擬內(nèi)存地址連續(xù),物理地址上不一定連續(xù)。函數(shù)原型在 《linux/vmalloc.h》 中聲明。一般用在為活動的交換區(qū)分配數(shù)據(jù)結(jié)構(gòu),為某些 I/O 驅(qū)動程序分配緩沖區(qū),或為內(nèi)核模塊分配空間。
下面的圖總結(jié)了上述兩種內(nèi)核空間虛擬內(nèi)存分配方式。
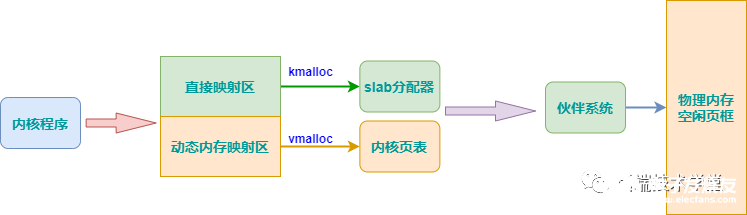
總結(jié)一下
Linux內(nèi)存管理是一個非常復(fù)雜的系統(tǒng),本文所述只是冰山一角,從宏觀角度給你展現(xiàn)內(nèi)存管理的全貌,但一般來說,這些知識在你和面試官聊天的時候還是夠用的,當(dāng)然也希望大家能夠通過讀書了解更深層次的原理。
本文可以作為一個索引一樣的學(xué)習(xí)指南,當(dāng)你想深入某一點學(xué)習(xí)的時候可以在這些章節(jié)里找到切入點,以及這個知識點在內(nèi)存管理宏觀上的位置。
責(zé)任編輯:pj
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3052瀏覽量
74239 -
高速緩存
+關(guān)注
關(guān)注
0文章
30瀏覽量
11079 -
分配器
+關(guān)注
關(guān)注
0文章
195瀏覽量
25811
發(fā)布評論請先 登錄
相關(guān)推薦
緩存對大數(shù)據(jù)處理的影響分析
HTTP緩存頭的使用 本地緩存與遠程緩存的區(qū)別
TMS320C6000 DSP高速緩存用戶指南

TMS320C64x在高性能DSP應(yīng)用中的高速緩存使用情況
寄存器和高速緩存有什么區(qū)別
內(nèi)部存儲器有哪些
電機主要包括什么和什么兩大類
CP3SP33帶高速緩存、DSP、藍牙、USB和雙CAN接口的連接處理器數(shù)據(jù)表
Cortex R52內(nèi)核Cache的相關(guān)概念(2)

數(shù)控程序編程通常可分為哪兩大類
plc存儲器分為哪兩大類,作用分別是什么
使用.cmm閃存初始SW借助Trace32 SW腳本,數(shù)據(jù)無法從高速緩存內(nèi)存讀取特定扇區(qū)的數(shù)據(jù),為什么?

Linux內(nèi)核內(nèi)存管理之slab分配器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論