 一種神經網絡結構改進方法「ReZero」
一種神經網絡結構改進方法「ReZero」
深度學習在眾多領域都取得了顯著進展,但與此同時也存在一個問題:深層網絡的訓練常常面臨梯度消失或梯度爆炸的阻礙,尤其是像 Transformer 這樣的大型網絡。現在,加州大學圣迭戈分校的研究者提出了一種名為 ReZero 的神經網絡結構改進方法,并使用 ReZero 訓練了具有一萬層的全連接網絡,以及首次訓練了超過 100 層的 Tansformer,效果都十分驚艷。
深度學習在計算機視覺、自然語言處理等領域取得了很多重大突破。神經網絡的表達能力通常隨著其網絡深度呈指數增長,這一特性賦予了它很強的泛化能力。然而深層的網絡也產生了梯度消失或梯度爆炸,以及模型中的信息傳遞變差等一系列問題。研究人員使用精心設計的權值初始化方法、BatchNorm 或 LayerNorm 這類標準化技術來緩解以上問題,然而這些技術往往會耗費更多計算資源,或者存在其自身的局限。
近日,來自加州大學圣迭戈分校(UCSD)的研究者提出一種神經網絡結構改進方法「ReZero」,它能夠動態地加快優質梯度和任意深層信號的傳播。

論文地址:https://arxiv.org/abs/2003.04887v1
代碼地址:https://github.com/majumderb/rezero
這個想法其實非常簡單:ReZero 將所有網絡層均初始化為恒等映射。在每一層中,研究者引入了一個關于輸入信號 x 的殘差連接和一個用于調節當前網絡層輸出 F(x) 的可訓練參數α,即:
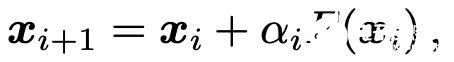
在剛開始訓練的時候將α設置為零。這使得在神經網絡訓練初期,所有組成變換 F 的參數所對應的梯度均消失了,之后這些參數在訓練過程中動態地產生合適的值。改進的網絡結構如下圖所示:
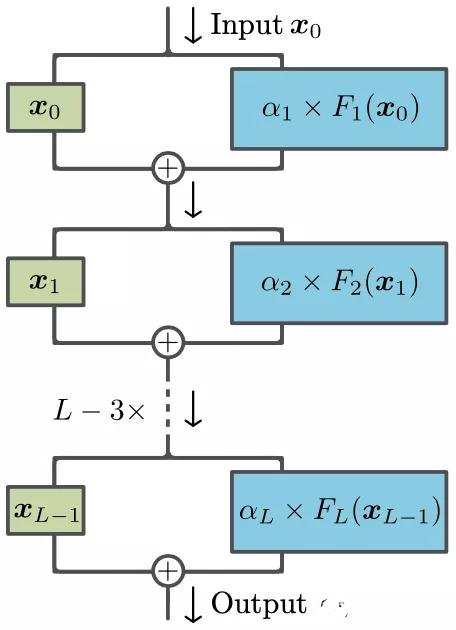
圖 1:ReZero 結構示意圖
ReZero 主要帶來了以下兩個益處:
1. 能夠訓練更深層神經網絡
學習信號能夠有效地在深層神經網絡中傳遞,這使得我們能夠訓練一些之前所無法訓練的網絡。研究者使用 ReZero 成功訓練了具有一萬層的全連接網絡,首次訓練了超過 100 層的 Tansformer 并且沒有使用學習速率熱身和 LayerNorm 這些奇技淫巧。
2. 更快的收斂速度
與帶有標準化操作的常規殘差網絡相比,ReZero 的收斂速度明顯更快。當 ReZero 應用于 Transformer 時,在 enwiki8 語言建模基準上,其收斂速度比一般的 Transformer 快 56%,達到 1.2BPB。當 ReZero 應用于 ResNet,在 CIFAR 10 上可實現 32% 的加速和 85% 的精度。
ReZero (residual with zero initialization)
ReZero 對深度殘差網絡的結構進行了簡單的更改,可促進動態等距(dynamical isometry)并實現對極深網絡的有效訓練。研究者在初始階段沒有使用那些非平凡函數 F[W_i] 傳遞信號,而是添加了一個殘差連接并通過初始為零的 L 個可學習參數α_i(作者稱其為殘差權重)來重新縮放該函數。目前,信號根據以下方式進行傳遞:
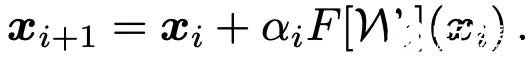
在初始階段,該網絡表示為恒等函數并且普遍滿足動態等距關系。在該架構修改中,即使某一層的 Jacobian 值消失,也可以訓練深度網絡(正如 ReLU 激活函數或自注意力機制出現這樣的狀況)。這一技術還可以在現有的已訓練網絡上添加新層。
實驗結果
更快的深層全連接網絡訓練
圖 3 展示了訓練損失的演變過程。在一個簡單實驗中,一個使用了 ReZero 的 32 層網絡,擬合訓練數據的收斂速度相比其他技術快了 7 到 15 倍。值得注意的是,與常規的全連接網絡相比,殘差連接在沒有額外的標準化層時會降低收斂速度。這可能是因為初始化階段信號的方差并不獨立于網絡深度。
隨著深度的增加,ReZero 架構的優勢更加明顯。為了驗證該架構可用于深度網絡訓練,研究者在一臺配備 GPU 的筆記本電腦上成功訓練了多達 1 萬層的全連接 ReZero 網絡,使其在訓練數據集上過擬合。
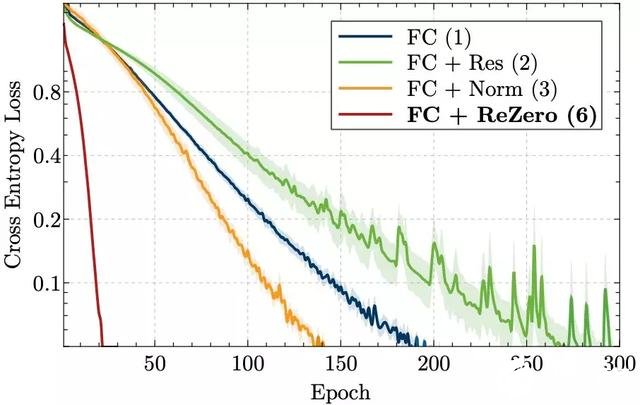
圖 3:256 寬度和 ReLU 激活的 32 層全連接網絡四種變體,在訓練過程中的交叉熵損失。
更快的深層 Transformer 訓練
研究者提出,常規的 Transformer 會抑制深層信號傳遞,他們在輸入序列 x 的 n x d 個 entry 的無窮小變化下評估其變化,獲得注意力處理的輸入-輸出 Jacobian,從而驗證了之前的觀點。
圖 5a 展示了不同深度中使用 Xavier 統一初始化權重的 Transformer 編碼層的輸入-輸出 Jacobian 值。淺層的 Transformer 表現出峰值在零點附近的單峰分布,可以發現,深層結構中 Jacobian 出現了大量超出計算精度的峰值。雖然這些分布取決于不同初始化方法,但以上量化的結論在很大范圍內是成立的。這些結果與普遍認為的相一致,也就是深層 Transformer 很難訓練。
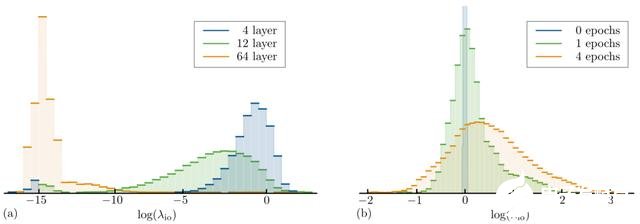
圖 5:多個輸入-輸出 Jacobian 矩陣中對數奇異值λ_io 的直方圖。(a)層數分別為 4、12、64 層的 Transformer 編碼器網絡;(b)是 64 層時訓練前和訓練中的 ReZero Transformer 編碼器網絡。深層 Transformer 距離動態等距很遠,即λ_io 1,而 ReZero Transformer 更接近動態等距,平均奇異值 λ_io ≈ 1。
能夠在多項 NLP 任務中實現 SOTA 的 Transformer 模型通常是小于 24 層的,這項研究中,最深層模型最多使用了 78 層,并且需要 256 個 GPU 來訓練。研究者又將這一模型擴展至數百個 Transformer 層,并且仍然可以在臺式機上訓練。為了檢查該方法是否可以擴展至更深層的 Transformer 模型之上,研究者將 ReZero Transformer 拓展到了 64 及 128 層,并與普通 Transformer 進行了對比。
結果顯示,收斂之后,12 層的 ReZero Transformer 與常規的 Transformer 取得了相同的 BPB。也就是說,用 ReZero 來替代 LayerNorm 不會失去任何模型表現。訓練普通的 Transformer 模型會導致收斂困難或訓練緩慢。當達到 64 層時,普通的 Transformer 模型即使用了 warm-up 也無法收斂。ReZero Transformer 在α初始化為 1 時發散,從而支持了α = 0 的初始化理論。深層的 ReZero Transformer 比淺層的 Transformer 表現出了更優越的性能。
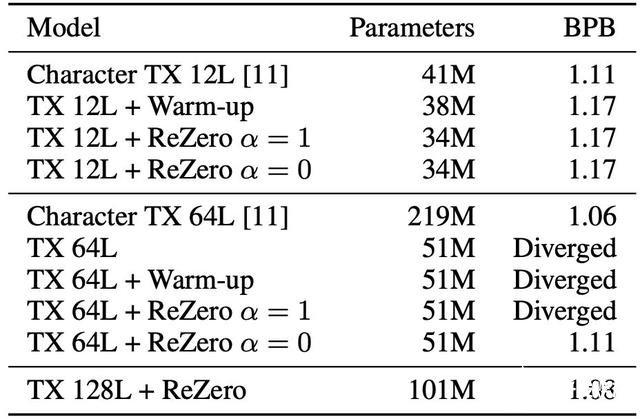
表 3:在 enwiki8 測試集上的 Transformers (TX) 對比。
收斂速度比較
選擇 enwiki8 上的語言建模作為基準,因為較難的語言模型是 NLP 任務性能的良好指標。在實驗中,其目標是通過測量 12 層的 Transformer 在 enwiki8 上達到 1.2 位每字節(BPB)所需的迭代次數,由此來衡量所提出的每種方法的收斂速度。
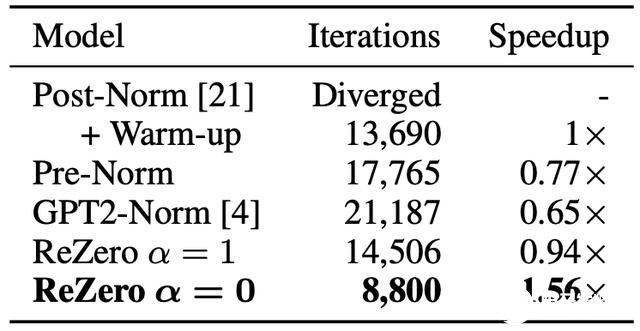
表二:針對 ReZero 的 12 層 Transformers 歸一化后與 enwiki8 驗證集上達到 1.2 BPB 時所需的訓練迭代比較。
更快的殘差網絡訓練
通過前述部分,看到了 ReZero 的連接是如何使深層網絡的訓練成為可能的,并且這些深層網絡都包含會消失的 Jacobian 奇異值,例如 ReLU 激活或自我注意力。但是,如果沒有 ReZero 的連接或者是其他架構的更改,其中某些架構將無法執行訓練。在本節中,會將 ReZero 連接應用于深層殘差網絡從而進行圖像識別。
雖然這些網絡并不需要 ReZero 連接便可以進行訓練,但通過觀察發現,在 CIFAR-10 數據集上訓練的 ResNet56 model4(最多 200 個 epochs)的驗證誤差得到了非常明顯的提升:從(7.37±0.06)%到(6.46±0.05)%。這一效果是將模型中的所有殘差連接轉換為 ReZero 連接之后得到的。在實施 ReZero 之后,驗證誤差降低到 15%以下的次數也減少了(32±14)%。盡管目前這些結果只提供了有限的信息,但它們仍指出了 ReZero 連接擁有更廣泛的適用性,從而也推進了進一步的研究。
上手實操
項目地址:
https://github.com/majumderb/rezero
在此提供了自定義的 ReZero Transformer 層(RZTX),比如以下操作將會創建一個 Transformer 編碼器:
import torchimport torch.nn as nnfrom rezero.transformer import RZTXEncoderLayerencoder_layer = RZTXEncoderLayer(d_model=512, nhead=8)transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)src = torch.rand(10, 32, 512)out = transformer_encoder(src)
創建一個 Transformer 解碼器:
import torchimport torch.nn as nnfrom rezero.transformer import RZTXDecoderLayerdecoder_layer = RZTXDecoderLayer(d_model=512, nhead=8)transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)memory = torch.rand(10, 32, 512)tgt = torch.rand(20, 32, 512)out = transformer_decoder(tgt, memory)
注意確保 norm 參數保留為 None,以免在 Transformer 中用到 LayerNorm。
-
編碼器
+關注
關注
45文章
3664瀏覽量
135075 -
神經網絡
+關注
關注
42文章
4779瀏覽量
101052 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13616
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論