 騰訊大數據十年發展歷程
騰訊大數據十年發展歷程
騰訊大數據團隊詳細披露了騰訊大數據十年發展歷程,并全面展示了騰訊第三代全棧機器學習平臺Angel在大模型數據訓練、深度學習、圖計算等方面的技術能力。
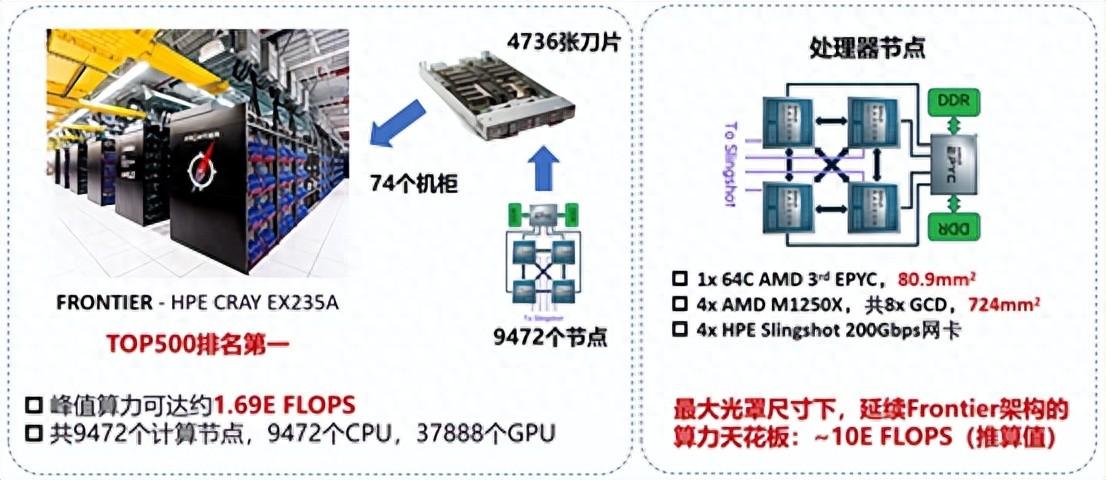
據騰訊大數據負責人劉煜宏介紹,騰訊大數據從2009年開始, 經歷離線計算、實時計算與機器學習三個階段,2009年之前,騰訊主要使用傳統的關系型數據庫。2009年開始,傳統的單機數據庫所提供的服務,在系統可擴展性、性價比方面已不再適用騰訊業務爆發式的增長。面對這種變化,騰訊大數據轉向分布式,基于開源的Hadoop體系,構建了騰訊第一代大數據平臺,并建設離線計算平臺,主要發力規模化。騰訊大數據由此進入第一階段。三年里,騰訊實現了從關系型數據庫到自建大數據平臺的全面遷移,到2012年,騰訊大數據的單集群規模突破了4400臺。
2012年,移動互聯網爆發,應對業務數據統計及時性、快速性的需求,騰訊大數據從Hadoop轉向Spark和Storm體系,在吸收開源技術的基礎上,結合騰訊自身的需求進行重寫,探索流式計算、秒級采集系統的建設,構建企業級的實時數據分析體系,騰訊大數據發展進入第二階段。
2015年至今,騰訊大數據邁入了第三階段。隨著數據挖掘、數據應用的深入,騰訊大數據再次自我迭代,于2016年推出了自研機器學習平臺Angel,專攻復雜計算場景,可進行大規模的數據訓練,支撐內容推薦、廣告推薦等AI應用場景。它由騰訊與北京大學聯合研發,兼顧了工業界的高可用性和學術界的創新性。
據騰訊Angel開發負責人肖品介紹,騰訊Angel從騰訊海量業務場景中而來,是超大樣本和超高維度的機器學習平臺。如今,Angel已在QQ、微信支付、騰訊廣告、騰訊視頻等騰訊旗下產品中廣泛應用,并向微眾銀行等行業合作伙伴全面開放,普遍適用于智能推薦、金融風險評估等圖計算業務場景。
2017年,騰訊Angel就正式開源。2018年8月,騰訊將Angel捐贈給Linux旗下專注人工智能的LF AI基金會,結合基金會成熟的運營,全面升級的 Angel與國際開源社區深入互動,致力于讓機器學習技術更易于上手研究及應用。
-
移動互聯網
+關注
關注
5文章
599瀏覽量
34108 -
機器學習
+關注
關注
66文章
8438瀏覽量
132907
發布評論請先 登錄
相關推薦
華為預制模塊化數據中心連續十年蟬聯全球第一
睿創微納五年&十年功勛員工頒獎大會圓滿舉行
LP-SCADA的發展歷程和應用行業?
“中國芯”產業的十年歷程和國內集成電路區域發展研究(下篇)

直徑測量工具的發展歷程
沃達豐與谷歌深化十年戰略合作
十年預言:Chiplet的使命
NAND閃存的發展歷程
BOE京東方與聯合國教科文組織UNESCO簽訂合作協議 成為首個支持聯合國“科學十年”的中國科技企業

亞馬遜豪擲千億美元,未來十年加速數據中心建設
PLC的發展歷程
聯發科談未來十年的戰略布局
何小鵬:歡迎特斯拉FSD進入中國,攜手推動智能汽車產業發展
制冷劑的發展歷程與發展趨勢
工業機器人減速器行業的十年變革





 工商網監
工商網監
評論