 谷歌開發機器學習模型,預警潛在危險
谷歌開發機器學習模型,預警潛在危險
據統計,每年死于用藥失誤的人數比死于工傷的人數還要多。
盡管沒有醫生或者護士愿意犯錯,2%的住院病人經歷過可能危及生命或造成永久傷害的藥物相關事件,而這些都是由于原本可以避免的失誤導致的。
用藥失誤導致醫療失誤的因素很多,往往都是由于不完善的系統、工具、流程或工作條件。如今,這一情況有望被AI解決。
谷歌健康的機器學習專家與加州大學舊金山分校(UCSF)計算與健康科學部門聯合發表了一項新的研究,描述了研究人員建立的一個機器學習模型,該模型可以使用病人的電子健康記錄(EHR)作為輸入,預測醫生正常應該采用的用藥模式,從而在實際用藥與預測結果不一致時提醒醫生。
該研究發表在《臨床藥理學和治療學》雜志上。

10萬病例的300萬份處方,訓練兩種機器學習模型
用于模型訓練的數據集包括來自超過10萬住院病人的大約300萬份藥物處方。
研究人員使用了回顧性的電子健康記錄數據,所有的研究都是使用開源的快速醫療互操作資源(FHIR)格式完成的,之前有研究已經證明使用這種格式使醫療數據對于機器學習更加有效。
同時數據集并不局限于特定的疾病或治療領域,這使得機器學習任務更具挑戰性,但也有助于確保模型可以識別更多種類的情況——例如,脫水患者需要不同于創傷性損傷患者的藥物治療。
為了保護隱私,這些數據已經經過了隨機移動日期和刪除記錄個人隱私數據的處理,包括姓名、地址、聯系方式、記錄號碼、醫生姓名、圖像等等。
根據這些數據,研究人員訓練了兩種機器學習模型:一種是長時短記憶(LSTM)遞歸神經網絡模型,另一個是常用于臨床研究的規則化、時間序列的邏輯模型。
研究人員將這兩種模型與一個簡單的基準進行比較,該基準根據患者的醫院服務(例如,普通內科、普通外科、婦產科、心臟病學等)和入院后的時間長短,對最常使用的藥物進行排序。在回顧性數據中,醫生每次開出一種藥物時,模型對990種可能的藥物進行排序,然后研究人員再看模型與醫生實際開出的藥物處方相吻合。
打個比方,假設一個有感染跡象的病人到達醫院,該模型回顧了病人電子健康記錄中記錄的信息:高溫、白細胞數量升高、呼吸頻率加快,并估計了在這種情況下不同藥物的處方可能性,將模型給出的概率最高的幾種藥物與與醫生實際處方的藥物(在這個例子中,抗生素萬古霉素和氯化鈉溶液)相對比。
一半情況下,實際處方在模型給出的前十結果中
在最后的6383組測試數據中,結果還是比較可靠的。
幾乎所有(93%)的情況下,模型給出的藥物中排名前10中,都包含至少一種臨床醫生一天之后實際會開出的藥物;
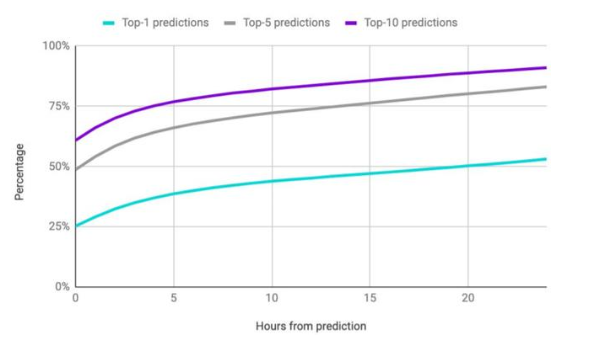
55%的情況下,模型將醫生開的所有處方藥包括在最有可能的10種處方藥中;
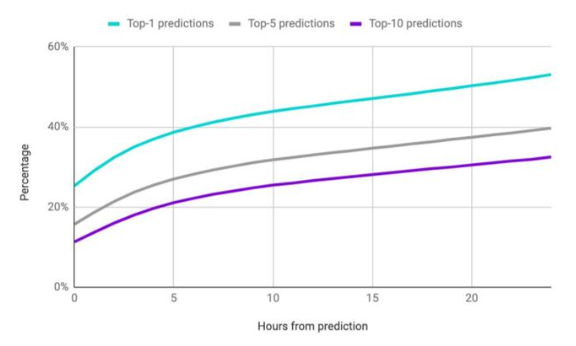
75%的情況下,模型將醫生開的所有處方藥包括在最有可能的25種處方藥中;
即使對于“假陰性”(醫生要求的藥物沒有出現在前25位的結果中) ,42%的情況下該模型會將同類藥物納入排名。
這種表現不能用僅僅預測先前處方藥的模型來解釋,即使我們在應用模型時屏蔽了以前的處方,它仍然保持了高性能。
這對醫生和病人來說意味著什么?
值得注意的是,這種方式訓練的模型只是對醫生的行為的重現,因為它出現在歷史數據,模型并沒有學到如何開具最佳的處方——這些藥物工作機理是什么,或什么副作用可能會發生。
然而,學習“正常”的處方是為了最終發現不正常、有潛在危險的處方。研究人員表示,在下一階段的研究中,他們將檢查在什么情況下,這些模型可以發現可能造成傷害的藥物誤用。
這是一項探索性的工作,結果表明機器學習可以應用于建立防止用藥錯誤,幫助保護患者安全。
研究人員表示期待著與醫生、藥劑師、其他臨床醫生和患者合作,以量化這樣的模型是否能夠及時捕捉到用藥錯誤,幫助保證患者在醫院的安全。
-
醫療
+關注
關注
8文章
1835瀏覽量
58887 -
AI
+關注
關注
87文章
31490瀏覽量
269907 -
機器學習
+關注
關注
66文章
8438瀏覽量
132928
發布評論請先 登錄
相關推薦
NPU與機器學習算法的關系
AI大模型與傳統機器學習的區別
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
Al大模型機器人
谷歌模型合成工具在哪下載安裝
谷歌模型軟件有哪些功能
谷歌模型怎么用手機打開文件
谷歌模型框架是什么?有哪些功能和應用?
谷歌公布基礎模型Genie,主攻2D平臺類游戲及機器人應用






 工商網監
工商網監
評論