 欠擬合和過擬合是什么?解決方法總結
欠擬合和過擬合是什么?解決方法總結
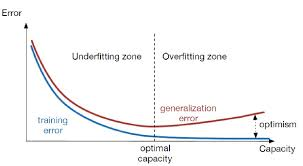
欠擬合與過擬合
欠擬合是指模型在訓練集、驗證集和測試集上均表現不佳的情況;
過擬合是指模型在訓練集上表現很好,到了驗證和測試階段就大不如意了,即模型的泛化能力很差。
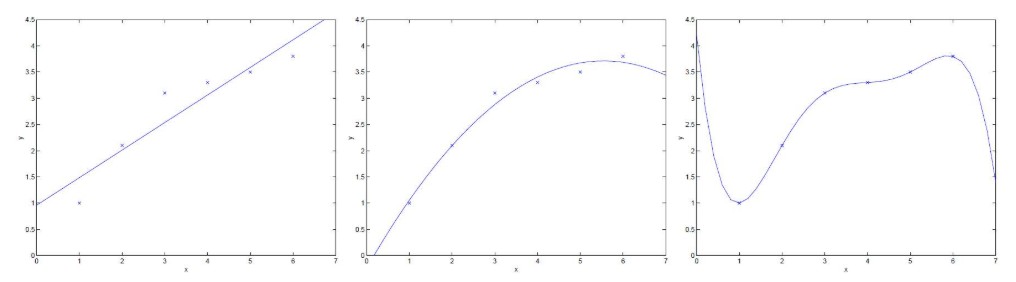
欠擬合和過擬合一直是機器學習訓練中的難題,在進行模型訓練的時候往往要對這二者進行權衡,使得模型不僅在訓練集上表現良好,在驗證集以及測試集上也要有出色的預測能力。下面對解決欠擬合和過擬合的一般方法作一總結,說明大致的處理方向,具體應用還得結合實際的任務、數據和算法模型等。
解決欠擬合(高偏差)的方法
1. 模型復雜化
? 對同一個算法復雜化。例如回歸模型添加更多的高次項,增加決策樹的深度,增加神經網絡的隱藏層數和隱藏單元數等
? 棄用原來的算法,使用一個更加復雜的算法或模型。例如用神經網絡來替代線性回歸,用隨機森林來代替決策樹等
2. 增加更多的特征,使輸入數據具有更強的表達能力
? 特征挖掘十分重要,尤其是具有強表達能力的特征,往往可以抵過大量的弱表達能力的特征
? 特征的數量往往并非重點,質量才是,總之強特最重要
? 能否挖掘出強特,還在于對數據本身以及具體應用場景的深刻理解,往往依賴于經驗
3. 調整參數和超參數
? 超參數包括:
- 神經網絡中:學習率、學習衰減率、隱藏層數、隱藏層的單元數、Adam優化算法中的β1和β2參數、batch_size數值等
- 其他算法中:隨機森林的樹數量,k-means中的cluster數,正則化參數λ等
4. 增加訓練數據往往沒有用
? 欠擬合本來就是模型的學習能力不足,增加再多的數據給它訓練它也沒能力學習好
5. 降低正則化約束
? 正則化約束是為了防止模型過擬合,如果模型壓根不存在過擬合而是欠擬合了,那么就考慮是否降低正則化參數λ或者直接去除正則化項
解決過擬合(高方差)的方法
1. 增加訓練數據數
? 發生過擬合最常見的現象就是數據量太少而模型太復雜
? 過擬合是由于模型學習到了數據的一些噪聲特征導致,增加訓練數據的量能夠減少噪聲的影響,讓模型更多地學習數據的一般特征
? 增加數據量有時可能不是那么容易,需要花費一定的時間和精力去搜集處理數據
? 利用現有數據進行擴充或許也是一個好辦法。例如在圖像識別中,如果沒有足夠的圖片訓練,可以把已有的圖片進行旋轉,拉伸,鏡像,對稱等,這樣就可以把數據量擴大好幾倍而不需要額外補充數據
? 注意保證訓練數據的分布和測試數據的分布要保持一致,二者要是分布完全不同,那模型預測真可謂是對牛彈琴了
2. 使用正則化約束
? 在代價函數后面添加正則化項,可以避免訓練出來的參數過大從而使模型過擬合。使用正則化緩解過擬合的手段廣泛應用,不論是在線性回歸還是在神經網絡的梯度下降計算過程中,都應用到了正則化的方法。常用的正則化有l1正則和l2正則,具體使用哪個視具體情況而定,一般l2正則應用比較多
3. 減少特征數
? 欠擬合需要增加特征數,那么過擬合自然就要減少特征數。去除那些非共性特征,可以提高模型的泛化能力
4. 調整參數和超參數
? 不論什么情況,調參是必須的
5. 降低模型的復雜度
? 欠擬合要增加模型的復雜度,那么過擬合正好反過來
6. 使用Dropout
? 這一方法只適用于神經網絡中,即按一定的比例去除隱藏層的神經單元,使神經網絡的結構簡單化
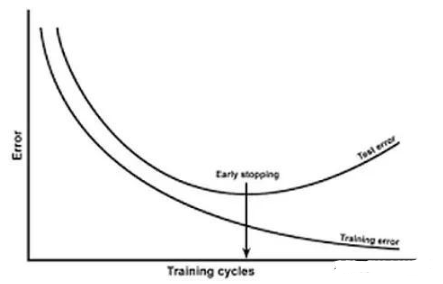
7. 提前結束訓練
? 即early stopping,在模型迭代訓練時候記錄訓練精度(或損失)和驗證精度(或損失),倘若模型訓練的效果不再提高,比如訓練誤差一直在降低但是驗證誤差卻不再降低甚至上升,這時候便可以結束模型訓練了
-
機器學習
+關注
關注
66文章
8438瀏覽量
132911
發布評論請先 登錄
相關推薦
神經網絡中避免過擬合5種方法介紹
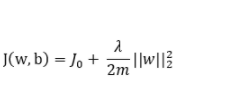
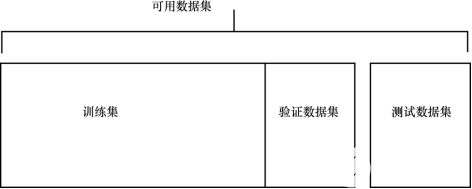
機器學習基礎知識 包括評估問題,理解過擬合、欠擬合以及解決問題的技巧
深度學習中過擬合/欠擬合的問題及解決方案
曲線擬合的判定方法
GPS高程擬合方法研究
解析訓練集的過度擬合與欠擬合

過擬合的概念和用幾種用于解決過擬合問題的正則化方法

深度學習中過擬合、欠擬合問題及解決方案





 工商網監
工商網監
評論