 深度學習與對象檢測之人臉識別
深度學習與對象檢測之人臉識別
通過往期的分享,我們了解到人臉識別的大概過程,主要包括:
1、人臉圖片的搜集(原始數據)
2、從圖片中識別到人臉
3、人臉數據提取
4、人臉數據保存
5、從圖片或者視頻中檢測到人臉
6、人臉數據提取
7、被識別的人臉與數據庫中的數據一一對比,識別出人臉
以上人臉識別過程,存在一定的問題,當人臉原始數據比較大時,數據庫中必然存在比較多的人臉數據,當進行人臉識別時,被識別的人臉與數據庫中的數據對比時,必然會消耗大量的時間,對人臉實時識別的速度有較大的影響。受CNN卷積神經網絡的啟發,我們使用神經網絡來進行人臉數據的訓練,標簽是人臉的名字,數據是人臉數據,使用神經網絡對人臉數據進行訓練,這樣當數據比較大時,神經網絡識別速度與正確率就越高,大大提高人臉識別的速度與正確率,這樣人臉識別的過程便成為如下過程:
1、人臉圖片的搜集(原始數據)
2、從圖片中識別到人臉
3、人臉數據提取與保存
4、人臉數據與人臉標簽的神經網絡訓練,保存訓練模型
5、從圖片或者視頻中檢測到人臉
6、識別到的人臉進行神經網絡預測,進行人臉識別
本期介紹人臉數據的提取
1、人臉原始圖片的搜集
要進行人臉識別,就要搜集用戶的人臉圖片,我們從網站上搜集了幾個明星的照片來進行本期文章的分享。
首先在目錄文件下新建一個dataset文件夾,里面放置多個文件夾,每個文件夾便是一個明星的照片,文件夾名稱是明星的名字,目錄類似如下:
2、設置人臉檢測模型與人臉提取嵌入數據模型
人臉檢測模型,我們直接使用 ResNet-10和SSD算法在caffe上面訓練好的模型
人臉數據提取嵌入模型,使用OpenFace的openface_nn4.small2.v1.t7模型,此模型訓練在pytorch上,可以直接使用opencv來進行加載

臉檢測模型與人臉提取嵌入數據模型
3、初始化圖片地址,初始化人臉數據數組與人臉名稱標簽數組
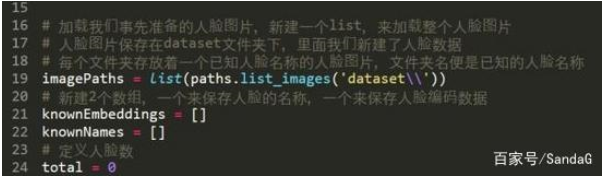
初始化人臉數據
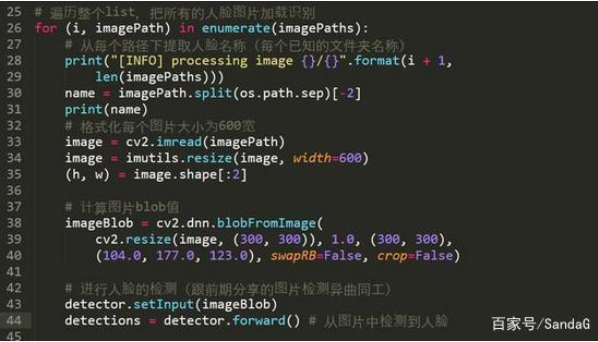
4、遍歷整個dataset目錄,進行圖片處理
30行提取了文件夾的名稱,此名稱便是后期需要保存的label值
33-35行,進行了圖片的讀取以及resize處理
38行計算圖片的blob值
43-44行,把圖片的blob值放入人臉檢測神經網絡進行人臉的檢測
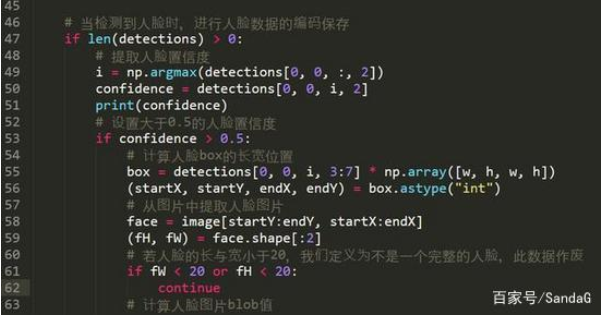
47行,當在圖片中檢測到 人臉時,其神經網絡的len值會大于0
50行,當檢測到人臉時,我們提取人臉的置信度
53行設計人臉置信度為0.5
55-59行,計算人臉在圖片中的位置,并提取人臉的尺寸
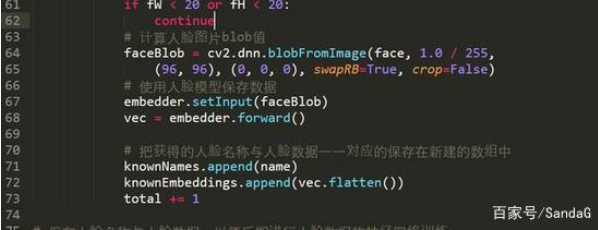
61-62行,當人臉尺寸較小時 ,我們忽略此人臉信息,選擇圖片中人臉比較大的人臉
64行,當人臉圖片尺寸符合要求時,我們計算人臉的blob值
67-68行,把人臉圖片的blob值傳遞人臉嵌入數據神經網絡
71-72行,保存人臉的label與人臉數據到數組中
5、保存人臉數據
當遍歷完成后,dataset中的所有的人臉數據便保存在了事先建立的數組中
77行,新建一個字典數據,把人臉的label以及人臉數據保存到本地,方便后期進行神經網絡的訓練

以上5步便完成了整個人臉的數據采集,當然,若想后期人臉識別的精度較高,需要進行大量的人臉數據搜集。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100802 -
數據模型
+關注
關注
0文章
49瀏覽量
10022 -
人臉識別
+關注
關注
76文章
4012瀏覽量
81934
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論