 facebook AI研究院又發布了一個大規模的詞匯實例分割數據集
facebook AI研究院又發布了一個大規模的詞匯實例分割數據集
聚焦于關鍵科學問題的數據不斷促進著目標檢測領域的技術進步,使得目標檢測的性能從簡單的圖像擴展到了復雜的場景,從邊框標注拓展到了語義分割掩膜。
近日來自facebook AI研究院的研究人員們又發布了一個大規模的詞匯實例分割數據集(Large Vocabulary Instance Segmentation,LVIS ),包含了164k圖像,并針對超過1000類物體進行了約200萬個高質量的實例分割標注。由于數據集中包含自然圖像中的物體分布天然具有長尾屬性,LVIS數據集將促進深度學習在圖像分割領域的進一步發展。
目標檢測是計算機視覺領域的重要任務,適用性強、用途廣泛、發展迅速,近年來在數據集、基準算法和檢測能力上都得到了大幅度提升,并衍生出一系列新的能力,包括圖像分割、三維表示和三維目標檢測等內容。
目前針對目標檢測算法的嚴格測評只在少量的分類上進行(例如20類/80類),那么在真實環境中有大規模類別的物體或者出現了罕見的物體時該如何處理?這就為科學家們提出了新的問題。
圖像中目標類別的長尾效應是不可避免的,標注更多的數據集雖然可以有效地發現先前未見或罕見的類別,但有效地從小樣本中學習至今還是機器學習與計算機視覺領域一個重要的開放問題,也使得這一領域成為科學界與工業界研究最為活躍的領域。但要深入的對這一領域進行研究,一個高質量的數據集和基準必不可少!
FAIR的研究人員針對這一研究方向設計并收集了稱為LVIS的針對于大規模詞匯實例分割的數據集,這一數據集包含了164k圖像,超過1000類數據,約兩百萬個標注。
值得一提的是,這個數據集的收集流程沒有預先確定的類別(沒有類別先驗),首先收集圖像然后根據圖像中目標的自然分布來進行標注。大量的人工標注代替了機器的自動化標注使得圖像中自然存在的長尾分布可以被有效識別。
COCO和ADE20K數據集
研究人員設計了一個有效的眾包標注流程,可以在高質量標注的前提下獲取大規模的數據集。對于目標檢測和實例分割來說,標注的質量對于算法十分重要。類似COCO這樣相對較粗的標注限制了算法對于mask預測質量的提升。與COCO和ADE20K相比,LVIS數據的標注mask具有更大的重疊面積和更好的邊緣連續性。
在構建數據集的過程中,研究人員采用了評價優先的設計原則。這意味著研究人員首先確定了對算法性能進行評價的方法,并基于這一方法來進行數據集的收集和構建,以滿足評測方法的需求。研究人員提出的測評基準使用了類似coco風格的的實例分割和AP計算方法。
但針對自然圖像中較為長尾的數據集,需要解決兩個不可避免的問題:
1)在類別龐大的情況下,如果某個目標擁有多個標簽,該如何公平的評測檢測器的性能?
2)針對164k圖像超過一千個類別的標注任務,如何設計合適的標注流程來減少工作量?
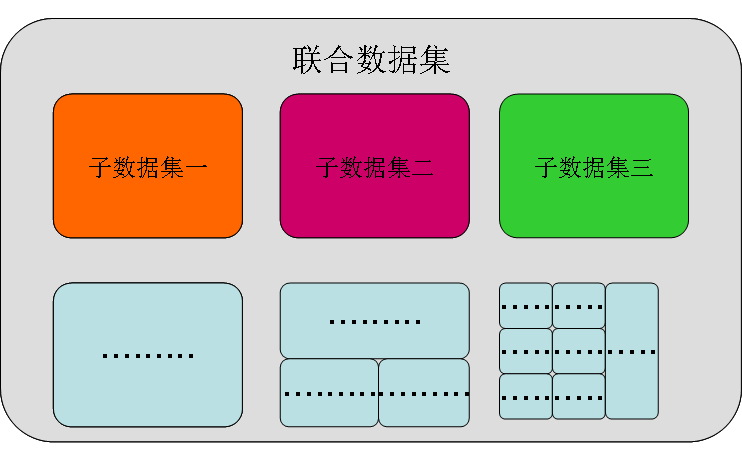
解決這些問題的關鍵在于構建聯合數據集:通過多個小數據集聯合構建大規模的完整數據集,而每一個子數據集則類似于只聚焦于某個單一類別的傳統數據集。在標注過程中,每一個小數據集將集中標注某一個特定的類別,將圖中某個特定類別的所有目標窮盡(exhaustive )標注。
對于完整的大數據集來說,構成的子數據集間可能會有重疊,單一目標可能會有多個標簽。此外由于在每個小數據集中進行了針對一類物體的窮盡標注,在完整的聯合數據集中就無需對所有的類別進行窮盡標注,這樣的方法極大地減小了標注的工作量。
更為關鍵的是,在測試評價時算法并不知道每張圖片組成的標記類別,它將對所有的標記類別一視同仁地進行處理,這將對聯合數據集內的各個數據集提供公平的測評。
LVIS數據集針對的是實例分割任務,這一任務的主要目標是在給定分類已知固定類別的情況下,算法可以針對一張事先未見過的圖像進行處理,并輸出圖像中出現的每一個實例及其對應的分類和置信度分數。通過算法生成的一系列輸出,可以計算出掩膜的平均精度mAP。
但在算法的測評中,研究人員將面臨著一系列問題。隨著分類數目的增加,實例的標簽不可避免的將會出現重疊和混淆:部分視覺概念的重合、父子分類關系的的界定和同義詞的識別等等。如果沒有有效的方法處理這些問題,測評的方法將會產生很大的不公平性。
例如很多玩具都不是鹿,大多數鹿都是不是玩具,但是一只玩具鹿同時是玩具也是一只鹿,這時目標檢測算法很有可能得到錯誤的標記。再比如,一輛車的標記是交通工具vehicle,算法如果輸入了car那么就會被判定為錯誤。
這些問題的發生主要來源于GT標注缺失了一個或者多個描述目標的標簽。如果算法預測到了某個標簽但是沒有在GT中標注過就會得到錯誤的懲罰。但對于這個新的數據集來說,每一個物體的標簽都被窮盡且正確的標注,上面的問題就可以迎刃而解。
數據集標注流程
數據集的標注流程分為了六個主要的步驟包括目標定點、窮盡標記、實例分割和驗證、窮盡標注驗證、負例標簽等。
目標定點中標注者被要求將圖像中輸入不同類別的實例進行標記,這個階段將迭代進行,使得標注者可以不斷從圖像中發掘出自然場景下目標的長尾信息。隨后再針對第一階段標記的每一個類別,將進行徹底的實例標記,找出每一類別包含的所有實例。在圖中可以看到標記者又標記出了更多的書。
在第三和第四階段,分別對前面標記的實例進行實例分割標注和驗真,重復進行直到準確率超過99%通過驗證。第五階段將進行窮盡標注驗證檢測,檢查是否所有的實例都被分割和標注類別,如果有就將缺失標注實例的類別篩選出來進行補充標注。最后一步的負例標簽將用來驗證類別子類的標簽沒有出現在圖像中。更詳細的標注細節請參看論文的第三部分。
探索數據集
下面讓我們來探索一下數據集,下圖中可以看到每張圖像里對于某一類圖像都進行了完善地標注,小的、被遮掩的難以辨認的,目標實例都被標注了出來。比如第一行最后一列的車牌標注和第三行最后一列的相機標注,盡管很小但也別明確地畫出掩膜。這些目標對于圖像的抽象和理解十分重要。
下圖中各類實例也別分別標注出來了:
子數據集中,每個實例都被窮盡標注。例如對于飛機這個分類,下圖展示了每張圖片中所有的飛機,無論是飛機的一部分還是完整的飛機都被標注了出來。
還有這些誘人的水果,都被一個個挑了出來。就拿菠蘿來說吧,無論是商店里的完整菠蘿還是沙拉里的菠蘿,就連披薩里的菠蘿丁也被標記出來了。
還有更多好玩的的數據集和詳細的分類信息,請參看數據集網站:
-
圖像
+關注
關注
2文章
1089瀏覽量
40535 -
Facebook
+關注
關注
3文章
1429瀏覽量
54887 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46074 -
數據集
+關注
關注
4文章
1209瀏覽量
24792
原文標題:FAIR提出大規模細粒度詞匯級標記數據集LVIS,有效識別長尾分布
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鯤云科技與中國工業互聯網研究院成立AI+安全生產聯合實驗室
安謀科技與智源研究院達成戰略合作,共建開源AI“芯”生態

藍思科技將新增昆山創新研究院,重點服務蘋果
AI大模型的訓練數據來源分析
Zettabyte與緯創攜手打造臺灣首個超大規模AI數據中心
易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)合作挖掘智能駕駛數據新價值
山東大學智能創新研究院加入甲辰計劃,為RISC-V生態繁榮聚勢賦能

開芯院發布全球首個開源大規模片上互聯網絡IP“溫榆河”

香港應科院—國芯科技新型AI芯片聯合研究實驗室正式成立

長沙北斗研究院總部基地正式奠基
北京開源芯片研究院正式加入甲辰計劃!
航天宏圖與天儀研究院合作共同推動遙感衛星數據應用創新

本源入榜胡潤研究院2024全球獨角獸榜單!

依托廣立微建設的浙江省集成電路EDA技術重點企業研究院正式掛牌






 工商網監
工商網監
評論