 關于分布式訓練的線性加速實踐詳解
關于分布式訓練的線性加速實踐詳解
分布式訓練需求
Deep Learning 在過去幾年中取得了長足的發展,尤其在語音、圖像、機器翻譯、自然語言處理等領域更是取得了飛躍式的提升,但與之相伴的是模型越來越復雜,參數量越來越大,例如:Inception v3參數量約25million,ResNet 152 擁有 60million 參數、VGG16 約 140million 參數,Deep Speech 2 參數量更是超過300million,一些語言模型參數量甚至超過 1billion (Exploringthe Limits of Language Modeling)。數據并行訓練方式要求每個 GPU 節點擁有一份完整的模型參數副本,并在融合梯度時發送和接收完整的梯度數據,巨大的通信數據量給多機多卡并行訓練帶來了極大的網絡通信壓力。
另一方面,越來越多的機器學習領域開始轉向DeepLearning比如 TTS、NLP。這意味著 GPU 集群的用戶(研發人員)數量將大幅膨脹。如何在多用戶環境下更高效的分配、利用 GPU 資源?一個辦法是計算資源以 GPU 為單位分配給用戶,而不管這些 GPU 是否在同一臺物理機上。這種分配方式的資源利用率雖高但同時也要求分布式訓練效率要足夠高,高到可以忽略跨機通信時延。
以上兩方面原因促使我們必須尋找更高效的通信算法,最大限度釋放 GPU 集群的并行計算能力。
分布式訓練的通信方法和問題
模型參數量的大小與計算量不是成簡單的正比關系,比如相同參數量的全連接模型和 CNN 的計算量相差了幾個數量級,但模型的參數量與分布式訓練的網絡通信代價一定是正相關的,尤其是超大模型,跨節點同步參數通常會造成嚴重的網絡擁塞。
主流的 Deep Learning 框架解決參數同步的方式有兩種:同步更新和異步更新。同步更新模式下,所有 GPU 在同一時間點與參數服務器交換、融合梯度;異步更新模式下,GPU 更新參數的時間點彼此解耦,各自獨立與參數服務器通信,交換、融合梯度。兩種更新模式各有優缺點,為了文章不失焦點并限制篇幅,這里不做展開討論了,我們只列出結論:
異步更新通信效率高速度快,但往往收斂不佳,因為一些速度慢的節點總會提供過時、錯誤的梯度方向
同步更新通信效率低,通常訓練更慢,但訓練收斂穩定,因為同步更新基本等同于單卡調大 batch size 訓練
在實際生產環境中,我們通常很看重模型效果和訓練速度,但當魚與熊掌不能兼得時,模型效果還是更重要一些的,為此犧牲一些訓練速度也不是不可接受,所以同步更新基本是主流方法
那么如何解決同步更新的網絡瓶頸問題呢?學者和工程師想出了多種優化方法,比如結合同步更新和異步更新、半精度訓練、稀疏梯度更新等等。限于篇幅,我們無法一一展開,在本文中,我們只介紹一種方法:Ring Allreduce。
如何搭建一套高效的分布式訓練框架
通過上面的分析,以及日常工作中的經驗,我們通常認為一個理想的 GPU 集群應包含這樣幾個特性:
1. GPU 跨機并行,達到近似線性加速比
2. 用戶以 GPUs 為單位申請資源,物理節點對用戶透明
3. 使用要簡單,甚至單機單卡、單機多卡、多機多卡可以由一套代碼實現
目標確定了,就來看看如何搭建這樣一套系統,我們選擇如下幾個組件:Kubernetes、TensorFlow以及 Horovod。
Kubernetes 是目前最流行的開源容器集群管理系統,在我們的系統中,Kubernetes 主要負責負責集群的容器化管理,包括 GPU 資源的申請、釋放、監控等。
TensorFlow 是 Google 大力推廣的基于數據流圖的 Deep Learning 框架,無論是使用者數量還是社區活躍程度,都遙遙領先其他競爭對手,在我們的系統中主要負責各個業務線上深度模型的搭建。
Horovod 是 Uber 新近開源的高效分布式訓練通信框架,Horovod本身只負責節點間網絡通信、梯度融合,在運行時需要綁定 TensorFlow 做單機運算。
這里有兩個問題需要說明一下:
1. TensorFlow 框架本身已經支持分布式訓練,為什么不直接使用呢?
因為TensorFlow的分布式框架是基于參數服務器的,這種結構容易造成網絡堵塞;
并且開源版 TensorFlow 的跨機通信是通過gRPC + ProtocolBuffers 實現的,這種方案的問題是,首先 gRPC 本身的效率就比較差,其次使用 Protocol Buffers 序列化就意味著節點間的所有交互必須經過內存,無法使用 GPUDirect RDMA,限制了速度提升;
即使拋開性能問題,編寫 TensorFlow 的分布式代碼也是一件十分繁瑣的工作,有過相關經驗的同學應該有所體會。
2. Horovod 是一個較新的分布式訓練通信框架,它有哪些優勢呢?
Horovod 有如下主要特點:Horovod可以實現接近 0.9x 的加速比;
一套代碼實現單機單卡、單機多卡、多機多卡;社區活躍,代碼迭代速度快,作為對比 Baidu Allreduce 已經停止維護了。
在接下來的兩小節中,我們將分別介紹 Horovod的核心算法和以及部署實踐。
Horovod 核心算法
Ring Allreduce ,原是 HPC 領域一種比較成熟的通信算法,后被 Baidu SVAIL 引入到 Deep Learning訓練框架中,并于 2017年2月公開 。Ring Allreduce 完全拋棄了參數服務器,理論上可以做到線性加速。Ring Allreduce 算法也是 Horovod的核心,Horovod對 Baidu SVAIL 的實現做了易用性改進和性能優化。
在這一節中,我們會詳細介紹Ring Allreduce 的算法流程:。
PS WORKER 框架下同步更新方式,以及網絡瓶頸定量分析
我們來定量分析一下,同步更新的網絡瓶頸問題,以Deep Speech 2 為例:
模型包含 300M 參數,相當于 1.2 G 的大小的內存數據(300M * sizeof(float))
假設網絡帶寬 1G bytes/s (萬兆網卡)
2 卡同步更新,需要 1.2 s 完成參數 Send(這還不算 Receive 的時間)
10 卡同步更新,需要 9.8 s 完成參數 Send
通過簡單的計算會發現,在單 ps 節點、有限帶寬環境下,通信時間隨著 GPU 數量的增加而線性增長,很難想象一個10卡的集群每訓練一個 batch 都需要等待 10 ~ 20s 來同步參數!通信時延幾乎完全覆蓋掉了 GPU 并行計算節節省下的計算時間,當然在實際訓練環境中,網絡速度也是能達到幾十 Gbps 的,而且通常也會多設置幾個 ps 節點,比如每個物理節點設置一個 ps ,這樣可以減輕帶寬瓶頸,但這些措施都沒有從根本上解決問題。

Ring Allreduce 框架下同步更新方式
在上面的通信方式中,網絡傳輸量跟 GPU 成正比,而Ring Allreduce 是一種通信量恒定的通信算法,也就是說,GPU 的網絡通信量不隨 GPU 的數量增加而增加,下面我們會詳細說明一下Ring Allreduce 框架下 GPU 的通信流程。
首先定義 GPU 集群的拓撲結構:
GPU 集群被組織成一個邏輯環
每個 GPU 有一個左鄰居、一個右鄰居
每個 GPU 只從左鄰居接受數據、并發送數據給右鄰居。
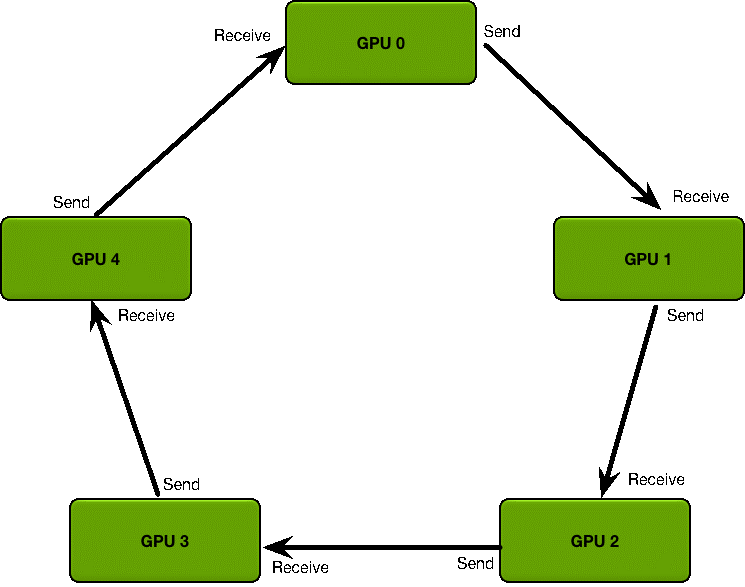
梯度融合過程分為兩階段:
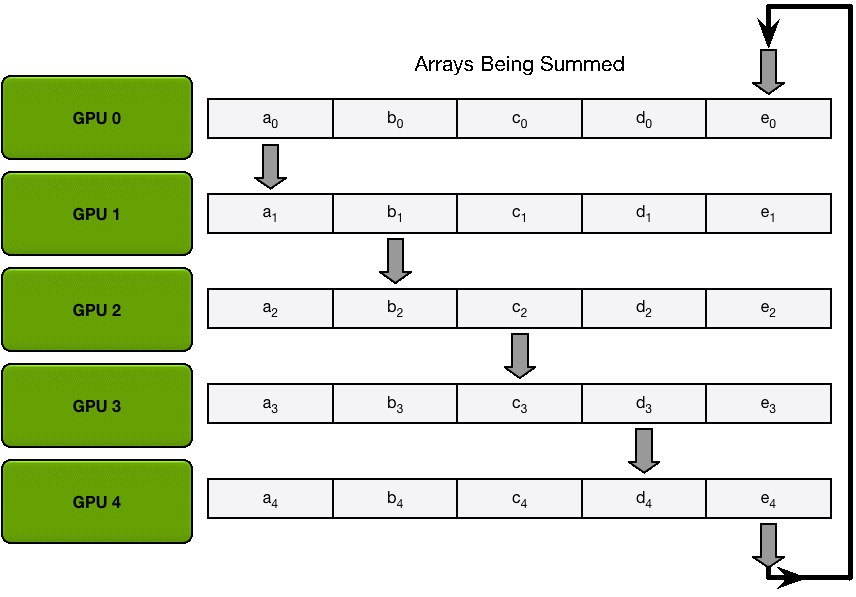
1. Scatter Reduce :在這個Scatter Reduce 階段,GPU 會逐步交換彼此的梯度并融合,最后每個 GPU 都會包含完整融合梯度的一部分
2. Allgather :GPU 會逐步交換彼此不完整的融合梯度,最后所有 GPU 都會得到完整的融合梯度
Scatter Reduce
為了方便說明,我們用梯度加和代替梯度融合。假設集群中有 N 個 GPU,那么將梯度數據等分為 N 份,接下來將在 GPUs 間進行 N-1 次Scatter Reduce 迭代,在每一次迭代中,每個 GPU 都會發送所有梯度數據的 1/N 給右鄰居,并從左鄰居接收所有梯度數據的 1/N 。同一次Scatter Reduce 迭代中,發送和接收的數據塊的編號是不同的,例如,第一輪迭代,第 n 個 GPU 會發送第 n 號數據塊,并接收第 n-1 號數據塊。經過 n-1 輪迭代,梯度數據會像圖2 所示,每個 GPU 都包含了部分完整梯度信息。
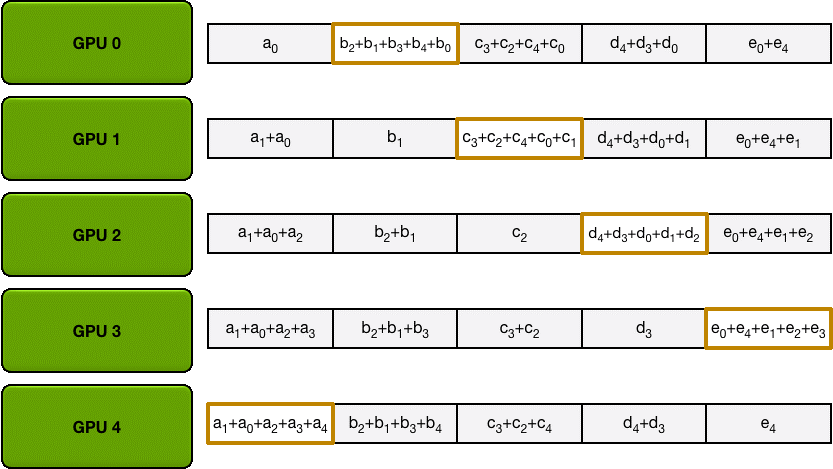
Allgather
和Scatter Reduce 階段類似,只不過這里只拷貝不求和,最終每個GPU 都得到了所有融合后的梯度。
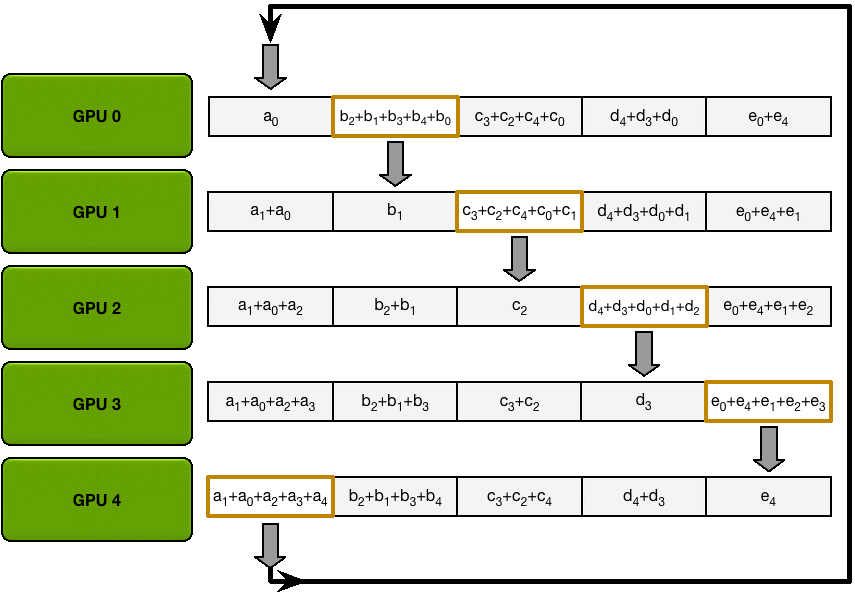

這么做有什么好處呢?
下面我們來定量的分析一下,每個 GPU 在Scatter Reduce 階段,接收 N-1 次數據,N 是 GPU 數量;每個 GPU 在allgather 階段,接收 N-1 次 數據;每個 GPU 每次發送 K/N 大小數據塊,K 是總數據大小;所以,Data Transferred=2(N?1)*K/N =
(2(N?1)/N)*K,隨著 GPU 數量 N 增加,總傳輸量恒定!總傳輸量恒定意味著通信成本不隨 GPU 數量增長而增長,也就是說我們系統擁有理論上的線性加速能力。再回到 DS2 的例子,300million參數也就是 1.2Gb 數據量,Ring Allreduce 方式更新一次需要傳送并接收 2.4Gb 數據,假設網絡使用 GPUDirect RDMA + InfiniBand,GPUDirect RDMA 帶寬約為10Gb/s;InfiniBand 帶寬約為6Gb/s,所以通信瓶頸在 InfiniBand 。(2.4Gb)/(6.0Gb/s) ≈ 400ms,也就是每輪迭代需要 400 ms 做參數同步,這 400ms 的數據傳輸時間是恒定的,不隨 GPU 數量增加而增加。
在 Kubernetes 環境部署Horovod
Kubernetes 是一套容器集群管理系統,支持集群化的容器應用,從使用角度看
Kubernetes 包含幾個重要的概念:
1. pod,pod 由一個或多個容器構成,在問本文描述的場景下,一個 pod 包含一個容器,容器中包含1個或多個 GPU 資源
2. Services,對外提供服務發現,后面通常會對接容器實例
3. YAML , YAML 是一種類似 JSON 的描述語言 ,在Kubernetes 中用 YAML 定義 pod 、Service 、Replication Controller等組件
4.kubectl,kubectl 是一套命令行工具,負責執行開發人員和 Kubernetes 集群間的交互操作,例如查看 Kubernetes 集群內 pod 信息匯總kubectl get pod;查看 Kubernetes 內物理節點信息匯總 kubectl get node
另外,近期我們還會有一篇詳細介紹TensorFlow on Kubernetes 的文章,所以關于Kubernetes 的詳細信息本文就不贅述了。
Build image
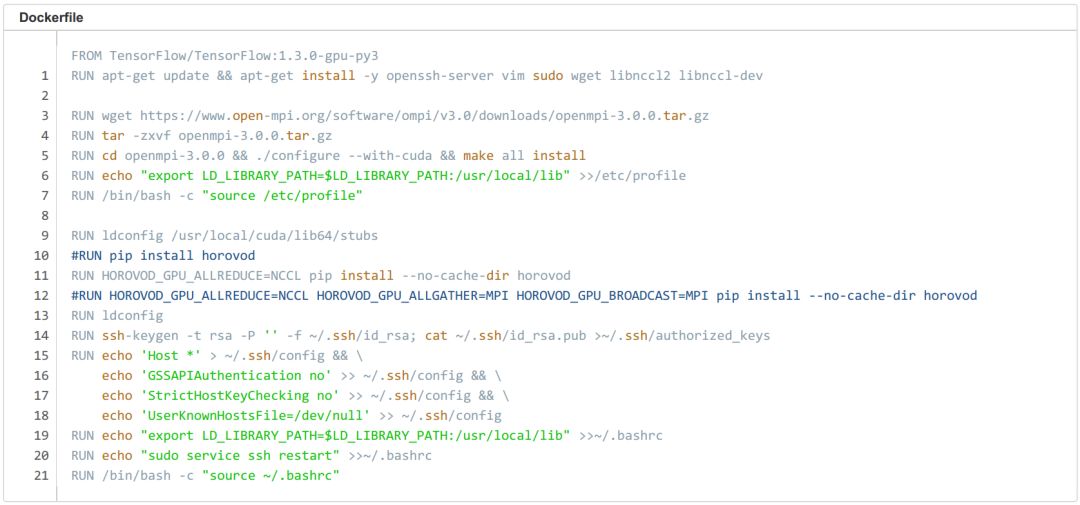
首先我們需要創建一個 Horovod鏡像,這個鏡像需要包含 TensorFlow 環境 、Horovod環境 、以及 OpenMPI的免密的登陸配置,我們可以選擇TensorFlow:1.3.0-gpu-py3 作為基礎鏡像,通過 Dockerfile 逐步安裝 Horovod環境及 Open MPI免密登陸配置。
第一步,安裝 Horovod相關依賴:apt-getupdate ; apt-get install -y openssh-server wgetlibnccl2 libnccl-dev。
第二步,下載并安裝 Open MPI,注意:如果你的網絡環境支持 RDMA,那你需要帶 --with-cuda 參數從源碼配置安裝:./configure --with-cuda ; make all install。
第三步,安裝 Horovod:HOROVOD_GPU_ALLREDUCE=NCCLpip install --no-cache-dir horovod,
第四步,設置 MPI SSH 免密登陸環境,方法見下面的Dockerfile。
編寫完成 Dockerfile 后,我們就可以 build 鏡像了:docker build -t horovod:v1 . 。
MPI on Kubernetes 相關問題
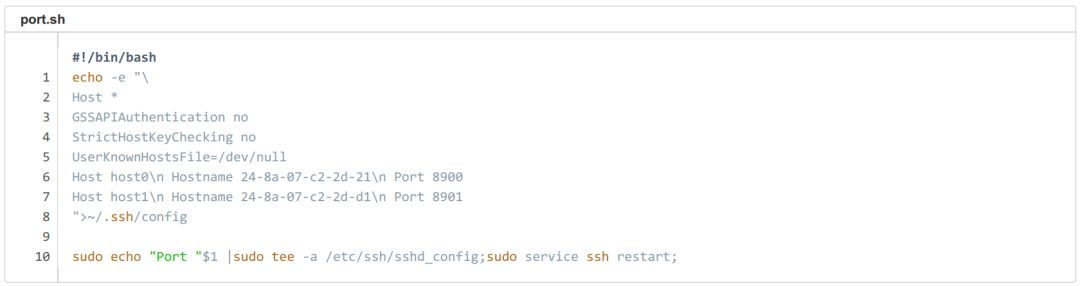
我們在調試過程中發現,Kubernetes 環境運行 Open MPI必須將 pod 設置為 host 網絡模式,否則 MPI 節點間通信時會 hang 住。host 網絡模式的問題在于它會占用宿主機端口號,多用戶環境下會有沖突,所以我們還需要想辦法為每個 pod 獨立設置一個SSH端口號,并通知集群里所有 Horovod節點。
方法詳見下面的腳本:腳本在 pod 創建時啟動,其中 Host** 為集群中所有節點的節點名和 SSH 端口號,腳本的最后一行作用是更改本機的 SSH端口號。這種方法可行但并不優雅,所以如果你有其他更好的方案,請在文章下方留言告訴我。
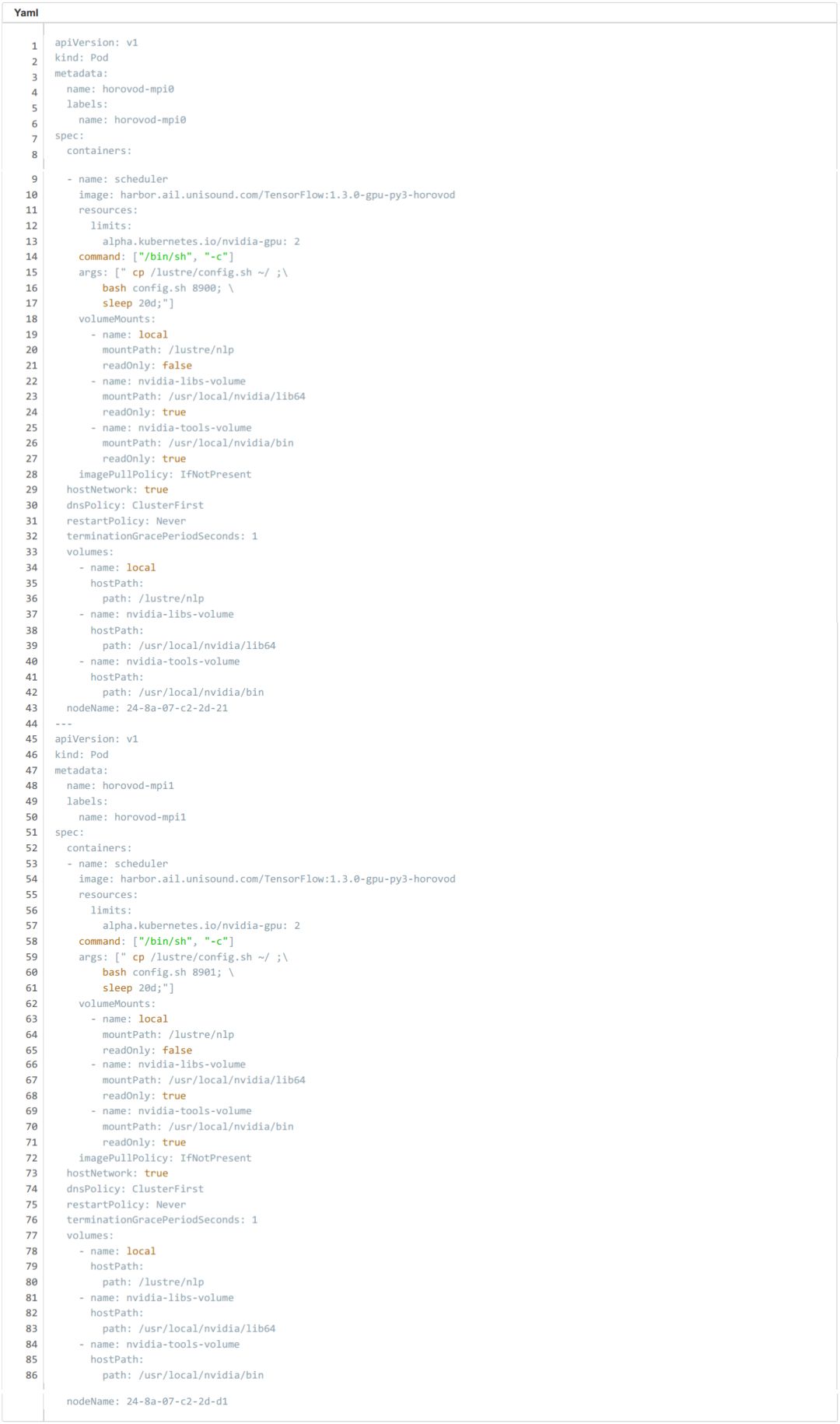
Pod yaml
這里我們申請 2 pod,每個 pod 各 2 個 GPU ,horovod-mpi0 的 SSH端口設置為 8900 ;horovod-mpi1 的 SSH端口設置為 8901。
測試腳本及 Benchmark
·集群環境:Kubernetes,兩機兩卡,1080ti
啟動腳本:
如果將 Benchmark 整理成圖表,那么看起來是這樣的。
在普通以太網環境下, 2 機 4 卡相比單機單卡,Horovod 可加速 3.6 倍。
-
服務器
+關注
關注
12文章
9239瀏覽量
85675 -
計算量
+關注
關注
0文章
4瀏覽量
6884
發布評論請先 登錄
相關推薦
分布式軟件系統
LED分布式恒流原理
基于分布式調用鏈監控技術的全息排查功能
分布式系統的優勢是什么?
HarmonyOS應用開發-分布式設計
如何高效完成HarmonyOS分布式應用測試?
分布式系統硬件資源池原理和接入實踐
GL Studio的分布式虛擬訓練系統關鍵技術
關于分布式系統的幾個問題
探究超大Transformer語言模型的分布式訓練框架
歐拉(openEuler)的分布式能力加速舉例
基于PyTorch的模型并行分布式訓練Megatron解析

分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進





 工商網監
工商網監
評論