眾所周知,大數據開發和分析、機器學習、數據挖掘中,都離不開各種開源分布式系統。最常見的就是 Hadoop、Hive、Spark這三個框架了。最近不少朋友有問到關于這些的問題: 大廠里還有在用
2020-09-17 13:17:00 4018
4018 hadoop學習總結(一)
2019-06-19 11:38:02
Hadoop測試——HDFS基準測試
2019-10-16 09:51:51
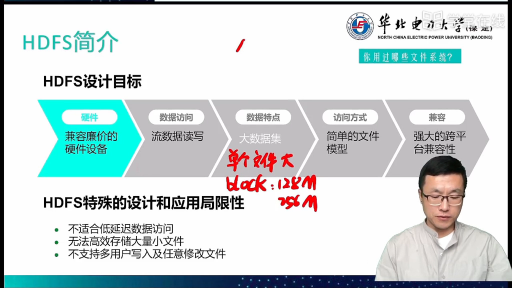
HDFS,Hadoop分布式文件系統,它是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,適合那些有著超大數據集的應用程序。HDFS的設計特點是:1.大數據文件,非常
2018-05-16 16:02:41
Hadoop教程:HDFS概述
2020-03-05 13:36:49
大數據基礎Hadoop311 的高可用HA安裝~踩坑記錄
2019-09-20 08:23:27
/hdfs/*chown -Rhadoop:hadoop/usr/local/hadoop/logs#重啟hadoopbin/stop-all.shbin/start-all.sh原因二:tmp文件問題#創建
2018-01-04 14:27:08
的二次包裝為主。基本上國內的這些發行版hadoop的安裝環境都是大同小異,網上查一下就會發現很多人在安裝這些hadoop的運營環境時,整個安裝過程非常復雜,耗時較長,重點就是很多人在經歷了漫長的安裝
2018-11-28 13:25:46
個模塊,為Hadoop各子項目提供各種工具,如:配置文件和日志操作等。2.HDFS:分布式文件系統,提供高吞吐量的應用程序數據訪問,對外部客戶機而言,HDFS 就像一個傳統的分級文件系統。可以創建
2018-05-16 16:04:57
Hadoop是一個用Java編寫的Apache開源框架,允許使用簡單的編程模型跨計算機集群分布式處理大型數據集。Hadoop框架工作的應用程序在跨計算機集群提供分布式存儲和計算的環境中工作
2018-05-11 16:00:10
Elasticsearch集成Hadoop最佳實踐 PDF 下載,Hadoop權威指南 大數據的存儲與分析PDF 下載
2019-05-08 17:01:00
應用一般都是批量處理,而不是用戶交互式處理,應用程序能以流的形式訪問數據集。Hadoop已經迅速成長為首選的、適用于非結構化數據的大數據分析解決方案,HDFS分布式文件系統是Hadoop的核心組件之一
2018-03-23 14:22:23
基金會所開發的分布式系統基礎架構。換句話說就是hadoop是一個能夠對大量數據進行分布式處理的軟件框架。Hadoopd之所謂會誕生,主要是由于進入到大數據時代,計算機需要處理的數據量太過龐大。這時就需要
2018-09-18 11:58:18
了整個HADOOP生態系統的全部組件,并深度優化,重新編譯為一個完整的更高性能的大數據通用計算平臺,實現了各部件的有機協調。因此DKH相比開源的大數據平臺,在計算性能上有了高達5倍(最大)的性能提升
2018-09-18 16:30:32
不是特別詳細。我把個人認為解釋的比較好的一個觀點分享給大家:它主要是從四個方面對Hadoop和spark進行了對比分析:1、目的:首先需要明確一點,hadoophe spark 這二者都是大數據框架
2018-11-30 15:51:36
Hadoop主要是分布式計算和存儲的框架,其工作過程主要依賴于HDFS分布式存儲系統和Mapreduce分布式計算框架,以下是其工作過程:階段 1用戶/應用程序可以通過指定以下項目來向Hadoop
2018-05-11 16:02:03
Hadoop50070是hdfs的web管理頁面,在搭建Hadoop集群環境時,有些大數據開發技術人員會遇到Hadoop 50070端口打不開的情況,引起該問題的原因很多,想要解決這個問題需要從以下
2018-04-10 16:02:13
提供了存儲,則MapReduce為海量的數據提供了計算。國內互聯網的飛速發展催生了大數據技術的快速成長,海量的數據急切需要一種合適的處理方式。Hadoop正值風口,所以迎來了爆發式的發展。國內
2018-12-28 16:08:44
hadoop框架結構核心:hadoop的框架結構最核心的設計就是:HDFS和MapReduce。HDFS為海量的數據提供了存儲,MapReduce為海量的數據提供了計算。大數據一體化開發框架:大數據
2018-10-15 15:59:43
架構上的列存儲數據庫,并且已經與Pig/Hive很好地集成。通過Java API可以近無縫地使用HBase。Sqoop設計的目的是方便從傳統數據庫導入數據到Hadoop數據集合(HDFS/Hive
2018-12-26 15:02:33
集中的大型分布式數據庫 或者分布式存儲集群,利用分布式技術來對存儲于其內的集中的海量數據進行普通的查詢和分類匯總等,以此滿足大多數常見的分析需求。特點和挑戰:導入數據量大,查詢涉及的數據量大,查詢請求
2018-06-11 16:41:53
HBase的命令行工具,最簡單的接口,適合HBase管理使用,可以使用shell命令來查詢HBase中數據的詳細情況。安裝完HBase之后,啟動hadoop集群(利用hdfs存儲),啟動
2018-06-15 15:06:44
的發展趨勢是,實時交互式的查詢效率和分析能力,當前的大數據處理一直在向著近似于傳統數據庫體驗的方向發展。大數據的4V特性,即類型復雜,海量,快速和價值,其總體架構包括三層,數據存儲,數據處理和數據分析
2018-07-26 16:26:24
能源行業2.3.3. 通信行業2.3.4. 零售業3、大數據解決方案3.1. 大數據技術組成3.1.1. 分析技術3.1.2. 存儲數據庫...
2021-07-12 06:12:11
Hadoop教程:大數據概述
2019-08-27 10:52:24
是大數據開發的重要框架,其核心是HDFS和MapReduce,HDFS為海量的數據提供了存儲,MapReduce為海量的數據提供了計算,因此,需要重點掌握,除此之外,還需要掌握Hadoop集群
2018-04-08 16:50:41
數據庫(例如 : MySQL ,Oracle ,Postgres等)中的數據導進到Hadoop的HDFS中,也可以將HDFS的數據導進到關系型數據庫中。7.SparkSpark 是一種與 Hadoop
2018-04-24 15:24:01
大數據分析邏輯,全英文,請勿公開
2018-10-08 17:08:52
大數據的時代已經來了,信息的爆炸式增長使得越來越多的行業面臨這大量數據需要存儲和分析的挑戰。Hadoop作為一個開源的分布式并行處理平臺,以其高拓展、高效率、高可靠等優點越來越受到歡迎。這同時也帶動
2018-10-17 15:12:09
`大數據也不是近幾年才出現的新東西,只是最近幾年才真正意義上變得熱門、火爆!而這要得益于互聯網信息技術的快速發展,網絡改變世界、改變生活,大數據技術的應用讓這樣的改變更為深刻。關注大數據或者是互聯網
2018-10-19 15:12:26
解決方案在市場上不能說是很多吧,畢竟大數據技術難度高度擺在這里,不是一般的企業就可以去做的。不同的解決方案會一些方面存在一定的差異,這里給大家介紹分析一下DKH大數據解決方案的的優勢。DKH大數據解決方案
2018-11-02 13:25:40
hadoop2.7]# yarn rmadmin -refreshNodes三、文件存檔1、基礎描述HDFS存儲的特點,適合海量數據的大文件,如果每個文件都很小,會產生大量的元數據信息,占用過多的內存
2021-01-05 17:11:03
工具值得推薦?
那就得是奧威BI大數據分析工具。主要原因有三:
1、奧威BI方案,開箱即用,立得百張BI報表,大量節省BI報表開發時間,一步到位完成銷售、財務、庫存、采購、應收、生產六大主題。
2
2023-12-05 09:36:05
導致了存儲成本的下降,這使得設備的造價出現大幅下降。新技術和新算法的出現是大數據火起來的第三個原因。最后一個原因也是最本質的原因就是商業利益的驅動極大地促進了大數據的發展。 數據是知識的源泉。但是
2018-08-27 10:53:23
/hadoop2.7/data/tmp/dfs/name/*拷貝SecondaryNameNode中數據到NameNode數據存儲目錄下;# 注意SecondaryNameNode服務配置在hop03上
2021-01-05 17:13:29
即席查詢大數據分析的三要素是人、數據、計算與存儲,而計算存儲作為大數據分析的基礎能力。Quick BI兼容Oracle 、Mysql等關系數據庫,來支撐小數據集的分析與處理,也兼容Hadoop等分布式數據
2018-04-03 11:42:18
測試等過程。對于我們這些入門級新手來說簡直每個都是坑。國內的發行版hadoop那么多,似乎都沒有來填這樣的坑?不知道是沒法解決,還是沒有想到?安裝運行環境這樣的坑,那些做國產大數據底層開發的,如果
2018-12-19 13:56:08
1.上傳文件 1)hadoop fs -put words.txt /path/to/input/ 2)hdfs dfs -put words.txt /path/wc/input/2.獲取hdfs
2019-07-08 08:10:31
/image-1652144875665.png)]Apache Hadoop 能做些什么呢?搭建大型的數據倉庫以及PB級別的數據的存儲、處理、分析、統計等業務,這些 Hadoop 都不在話下。而且,在
2022-07-22 21:26:53
/image-1652144875665.png)]Apache Hadoop 能做些什么呢?搭建大型的數據倉庫以及PB級別的數據的存儲、處理、分析、統計等業務,這些 Hadoop 都不在話下。而且,在
2022-07-22 21:31:37
` 本帖最后由 a156789156782 于 2018-6-14 10:11 編輯
【教學基地實驗小屋】03008虛擬儀器大數據處理初步分析部分通過本節學習對文檔的操作來入門大數據分析,直接
2018-06-13 21:45:35
大數據(big data)目錄1什么是大數據2大數據的定義3大數據的特點[1]4大數據的作用[2]5大數據的分析6大數據的技術7大數據的處理8大數據的常見誤解9大數據時代存儲所面對的問題[3]10大數據應用與案例分析11相關條目12參考文獻什么是大數據...
2021-07-12 06:52:21
Hadoop是在分布式服務器集群上存儲海量數據并運行分布式分析應用的一個平臺,其核心部件是HDFS與MapReduce。HDFS是一個分布式文件系統,可對數據系統進行分布式儲存讀取
2018-03-13 15:21:18
下載的。DKhadoop免費版本的沒有安裝過的,我用的是大快的其他版本的。可能是習慣了吧,所以覺得還是很好用的。其實提供免費版試用版本的不是只有大快搜索了,很多做大數據hadoop開發的一般都會提供一些“乞丐版”。但
2018-11-07 14:10:20
→ Kafka → Sqoop → Pig學習目標:掌握大數據學習基石Hadoop、數據串行化系統與技術、數據的統計分析、分布式集群、流行的隊列、數據遷移、大數據平臺分析等第三階段:Storm
2018-03-01 15:41:13
框架、Yarn集群資源管理和調度平臺、hdfs分布式文件系統、hive數據倉庫、HBase實時分布式數據庫、Flume日志收集工具、sqoop數據庫ETL工具、zookeeper分布式協作服務、Mahout數據挖掘庫等。
2018-09-20 16:00:57
發現真正的問題所在。接觸過hadoop的人都知道,單獨搭建hadoo里每個組建都需要運行環境、修改配置文件、測試等過程。如果僅僅是安裝一下運行環境就行了,那你就大錯特錯了,幾乎每個組件都是坑,這些坑幾乎是
2018-09-13 13:37:51
我們就來看看大數據。1.HBase是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化數據集群。像Facebook,都拿它做大型實時
2018-02-28 17:02:51
以及亞馬遜等大型企業也將大數據技術列為未來發展的關鍵籌碼,可見,大數據技術在當今乃至未來的重要性!大數據技術,簡而言之,就是提取大數據價值的技術,是根據特定目標,經過數據收集與存儲、數據篩選、算法分析
2018-03-13 16:50:40
大數據初學者的福利——Hadoop快速入門教程
2020-04-15 11:38:59
***出臺了城市大數據發展計劃。政務大數據處理平臺是一款匯集大數據處理、在線分析、數據挖掘、數據模型、可視化展現于一體的綜合性大數據分析平臺。它提供了基于hadoop存儲、數據立方體與計算的OLPA
2018-10-23 15:52:15
空閑把大快DKM大數據運維管理平臺的內容整理了一些,作為DKHadoop相配套的管理平臺,是有必要對DKM有所了解的。DKM 是DKHadoop管理平臺。作為大數據平臺端到端Apache Hadoop
2019-01-11 15:28:26
源碼HDFS之DataNode:啟動過程
2019-07-29 13:31:35
使用Maxcompute的用戶,從hive秒速遷移到Maxcompute的使用上。首先,回顧下hive的概念。1、hive是基于hadoop的,以表的形式來存儲數據,實際上數據是存儲在hdfs上,數據
2018-01-23 17:44:33
的影響。大數據領域的框架和產品將更加 Cloud Native 。計算和存儲的分離。我們知道每個公有云都有自己對應的分布式存儲,比如 AWS 的 S3 。 S3 在一些場合可以替換我們所熟知的 HDFS
2019-10-14 10:56:24
hadoop大數據windows搭建環境
2017-09-08 08:52:44 4
4 從大數據到快速數據 除了能夠以批處理模式分析大型數據集之外,現代數據驅動型組織還需要盡快從所收集的數據中生成洞察,并最終采取行動。在這方面,傳統的Hadoop堆棧(HDFS作為存儲
2017-09-30 14:09:360 。 Hadoop 采用動態存儲資源分配,可以將數據更平衡的分布于不同的Data Node 節點,防止出現數據不平衡而造成部
2017-10-27 14:38:546 人們常常使用HDFS作為存儲服務的核心,大數據的實用性和發展對于企業來講都是很重要的。而在大數據發展之初,最主要的應用場景仍然是離線批處理場景,對存儲的需求追求的是吞吐量,HDFS正是針對這樣的場景而設計的,而隨著技術不斷的發展,越來越多的場景會對存儲提出新的需求,HDFS也面臨著新的挑戰
2017-11-02 11:05:242854 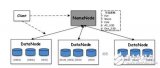
改進,并且DAO層實現校園云端網絡的可變動態操作。實踐應用結果表明:優化后的HDFS方案能夠有效地減少名稱節點內存的損耗,擴展了HDFS集群的命名空間,并且能夠有效地提升讀取文件元數據信息的速度。有效地提升了校園云存儲平臺的管理效率和數據
2017-11-06 17:52:057 基于上述大數據的特征,通過傳統IT技術存儲和處理大數據成本高昂。一個企業要大力發展大數據應用首先需要解決兩個問題:一是低成本、快速地對海量、多類別的數據進行抽取和存儲;二是使用新的技術對數據進行分析
2017-11-17 15:50:0832108 
HADOOP的核心組件有: HDFS(分布式文件系統) YARN(運算資源調度系統) MAPREDUCE(分布式運算編程框架) 2. HDFS的概念 hdfs是一個文件系統,用于存儲文件,通過統一的命名空間–目錄樹來定位文件。它是分布式的,由很多服務器聯合起來實現其功能,集群中的服務器有各自的角色。
2017-11-27 20:03:02920 針對海量web日志數據在存儲和計算方面存在的問題,結合當前的大數據技術,提出一種基于Hadoop與聚類分析的網絡日志分析模型。利用Hadoop中的MapReduce編程模型對海量Web日志進行處理
2017-12-07 15:40:170 容量,優化存儲空間利用率。利用Hadoop大數據處理平臺下的分布式文件系統(HDFS)和非關系型數據庫HBase兩種數據管理模式,設計并實現一種可擴展分布式重刪存儲系統。其中,MapReduce并行編程框架實現分布式并行重刪處理,HDFS負責重刪后的數據存儲
2017-12-22 14:19:500 Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。Hadoop實現了一個分布式文件系統,簡稱HDFS。
2017-12-25 15:28:5216583 Hadoop 由許多元素構成。其最底部是 Hadoop Distributed File System(HDFS),它存儲 Hadoop 集群中所有存儲節點上的文件。HDFS(對于本文)的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。
2017-12-25 16:19:474003 
Hadoop得以在大數據處理應用中廣泛應用得益于其自身在數據提取、變形和加載(ETL)方面上的天然優勢。Hadoop的分布式架構,將大數據處理引擎盡可能的靠近存儲,對例如像ETL這樣的批處理操作相對合適,因為類似這樣操作的批處理結果可以直接走向存儲。
2017-12-25 16:46:1322756 
計算機組成的集群中對海量數據進行分布式計算(或專為離線和大規模數據分析而設計的)并不適合那種對幾個記錄隨機讀寫的在線事務處理模式。 Hadoop=HDFS(文件系統,數據存儲技術相關)+ Mapreduce(數據處理),Hadoop的數據來源可以是任何形式,在處理半結構化和非結構化數據
2017-12-29 16:32:4039568 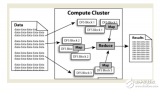
SOH(SQL over HDFS)系統通常將數據存儲于分布式文件系統 HDFS(Hadoop distributed file system)中,采用 Map/Reduce 或分布式查詢引擎來處
2017-12-30 13:15:230 大數據就是Hadoop嗎?當然不是,但是很多人一提到大數據就會立刻想到Hadoop。大數據技術一旦進入超級計算時代,很快便可應用于普通企業,在遍地開花的過程中,它將改變許多行業業務經營的模式。但是很多人對大數據存在誤解,下面就來縷一縷大數據與Hadoop之間的關系。
2018-01-02 09:21:184512 Hive是基于Hadoop的數據倉庫工具,可對存儲在HDFS上的文件中的數據集進行數據整理、特殊查詢和分析處理,提供了類似于SQL語言的查詢語言–HiveQL,可通過HQL語句實現簡單的MR統計,Hive將HQL語句轉換成MR任務進行執行。
2018-02-11 10:17:277162 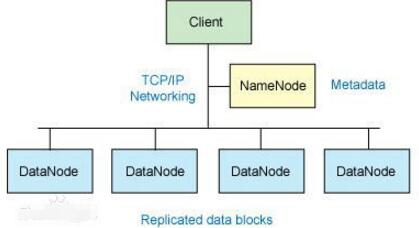
Hadoop在2006年開始成為雅虎項目,隨后成為頂級的Apache開源項目。它是一種通用的分布式處理形式,具有多個組件:
HDFS(分布式文件系統),它將文件以Hadoop本機格式存儲,并在集群中并行化;
YARN,協調應用程序運行時的調度程序.
2018-06-04 12:48:006565 闡述了智能電網面臨的挑戰以及大數據關鍵技術對電力行業的可持續發展和堅強智能電網建立的重要意義。分別從智能電網主數據管理、用電信息統一存儲管理、電能質量分析、配網運營能力分析等幾個典型大數據系統分析了大數據關鍵技術在智能電網中的應用。
2018-03-27 15:31:016 如何高效地存儲大數據并支持實時大數據處理與分析是大數據技術發展面臨的首要問題。近年來,以相變存儲器、閃存等為代表的新型存儲為實現高效的大數據存儲和管理提供了新思路。以相變存儲器為代表的存儲級主存技術
2018-03-28 16:05:2824 針對空間科學大數據的快速檢索需求,提出了分布式區域檢索算法。算法主要包括四維空間科學數據的索引方法和分布式四維空間科學數據的索引架構兩部分。在KTS存儲結構下,通過基于立方體的Block-Grid
2018-04-03 14:54:400 本視頻主要詳細介紹了大數據分析工具有哪些,分別有hadoop、HPCC、Storm、ApacheDrill、RapidMiner。
2019-02-28 15:28:2311698 在工作崗位上,大數據工程師需要基于Hadoop,Spark等構建數據分析平臺,進行設計、開發分布式計算業務。負責大數據平臺(Hadoop,HBase,Spark等)集群環境的搭建,性能調優和日常維護。負責數據倉庫設計,數據ETL的設計、開發和性能優化。參與構建大數據平臺,依托大數據技術建設用戶畫像。
2019-05-30 15:52:095339 Hadoop的優點
(1)Hadoop具有按位存儲和處理數據能力的高可靠性。
(2)Hadoop通過可用的計算機集群分配數據,完成存儲和計算任務,這些集群可以方便地擴展到數以千計的節點中,具有
2019-10-04 12:16:006476 HADOOP DISTRIBUTED FILE SYSTEM,簡稱HDFS,是一個分布式文件系統。它是谷歌的GFS提出之后出現的另外一種文件系統。它有一定高度的容錯性,而且提供了高吞吐量的數據訪問,非常適合大規模數據集上的應用。
2020-03-15 17:14:001954 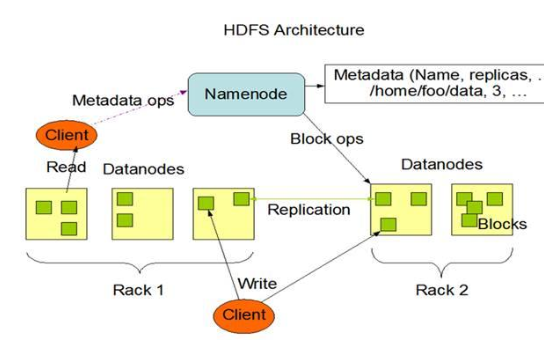
大數據到底有多“大”?根據IBM的說法,每天都會產生2.5萬億字節的數據,世界上所有數據的90%都是在過去兩年中創建的。意識到這個巨大的信息商店的價值就需要數據分析工具,這些數據分析工具足夠復雜,價格便宜,而且對于各種規模的公司來說都很容易使用。
2020-03-20 14:16:202521 
Hadoop 是一個分布式系統基礎架構,在大數據領域被廣泛的使用,它將大數據處理引擎盡可能的靠近存儲,Hadoop 最核心的設計就是 HDFS 和 MapReduce,HDFS 為海量的數據提供
2020-04-02 08:00:0012 如今,開源分析已牢固地成為企業軟件堆棧的一部分,“大數據”一詞似乎已經過時,并且Hadoop已成為死法已成為人們公認的民間傳說。不過,這太夸張了;盡管Hadoop不再炙手可熱,但它仍然是一個重要因素
2020-08-17 17:58:432339 在大數據的發展當中,大數據技術生態的組件,也在不斷地拓展開來,而其中的Hive組件,作為Hadoop的數據倉庫工具,可以實現對Hadoop集群當中的大規模數據進行相應的數據處理。今天我們的大數據入門
2020-12-08 12:25:321347 學大數據需要具備什么基礎?學大數據應具備編程開發經驗,今天主要介紹學大數據應具備的基礎,學員從java基礎開始,學習大數據開發過程中的離線數據分析、實時數據分析和內存數據計算等重要內容;涵蓋大數據
2020-10-13 15:41:491993 近日,華為云OBS對象存儲服務OBSA-HDFS組件代碼完成了開源社區同行評審,已經正式合入Apache Hadoop社區,標志華為云存算分離大數據方案正式獲得社區認可,客戶可以通過社區獲取
2021-01-22 16:52:532070 數據湖的發展契機,來源于近年來的AI熱潮和云計算、5G的發展,在日益發展的海量數據時代,數據已成為企業發展的核心資產,通過構建適用于大數據的底層架構,圍繞Hadoop提供語義一致性、數據治理和安全性
2021-08-24 16:22:32562 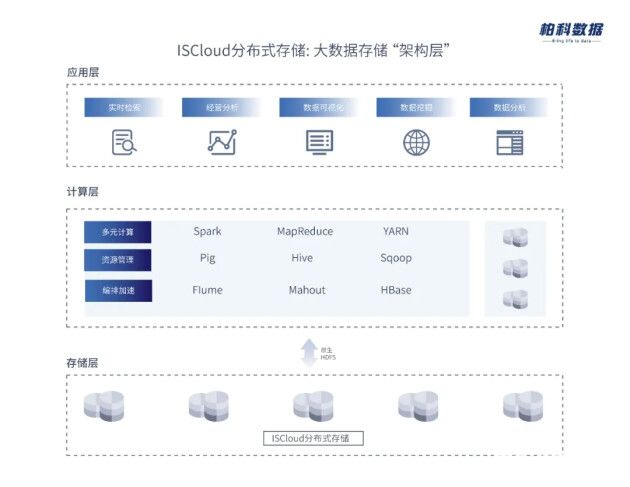
摘要: 研究產品相關大數據資源組織存儲與檢索查詢技術,提出在Hadoop平臺基礎上對產品大數據資源進行分塊存儲。基于MapReduce并行架構模型,提出多副本一致性Hash數據存儲算法,算法充分考慮
2022-03-22 11:09:40593 Hadoop的誕生改變了企業對數據的存儲、處理和分析的過程,加速了大數據的發展。隨著大數據系統建設的深入,企業的數據基礎設施易出現計算資源浪費、存儲性能低、管理成本過高等挑戰。相比存算一體架構
2022-12-26 14:45:16774 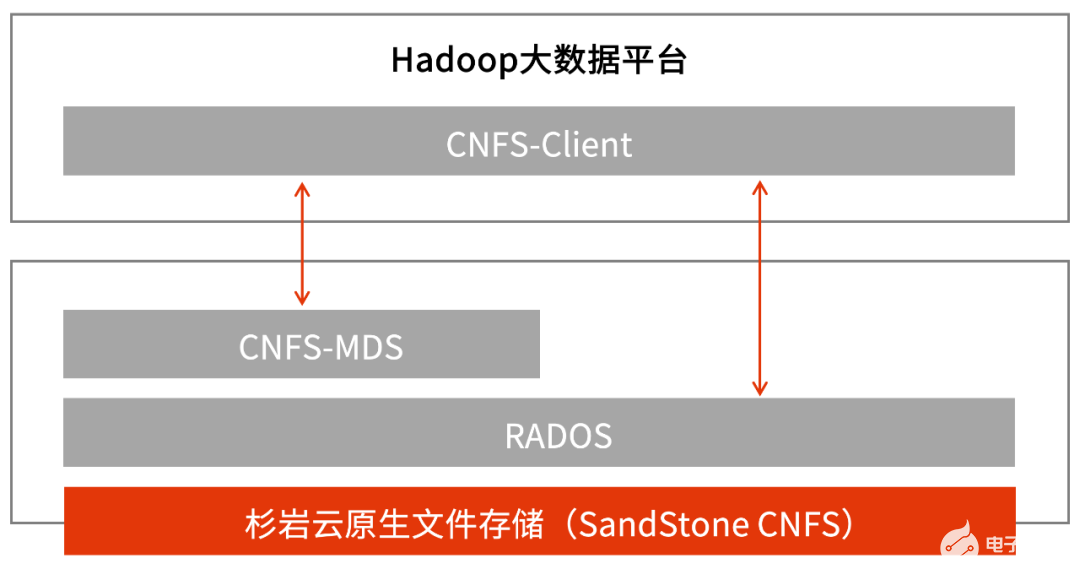
大數據的成功管理取決于幾個方面,例如數據的收集、存儲、處理、分析和可視化。在大數據的處理過程中,各種技術和算法也被不斷地應用于解決各種問題。大數據技術將繼續發展和應用于各種領域,成為管理和處理信息的有效手段。
2023-05-03 09:23:002654 Hadoop是一個開源的分布式計算框架,它可以處理大規模數據集并能夠在通常由計算機集群或者計算機網絡上的數千臺計算機上并行運行。Hadoop的設計初衷是為了解決大規模數據處理和分析的問題,它采用
2024-02-05 10:52:01301
 電子發燒友App
電子發燒友App














 工商網監
工商網監
評論