 Hadoop大數據存算分離方案:計算層無縫對接存儲系統
Hadoop大數據存算分離方案:計算層無縫對接存儲系統
Hadoop的誕生改變了企業對數據的存儲、處理和分析的過程,加速了大數據的發展。隨著大數據系統建設的深入,企業的數據基礎設施易出現計算資源浪費、存儲性能低、管理成本過高等挑戰。相比存算一體架構,存算分離架構具有性能與成本最優、兼具靈活性等特點,因此受到企業IT部門的青睞,并紛紛開始對Hadoop架構進行改造。
為滿足大數據不同場景需求,杉巖數據此前研發推出了兼容HDFS接口能力的高性能數據湖文件網關,為使湖倉一體方案更加完善,杉巖數據全新升級了面向AI訓練、機器學習、大數據分析等場景的高性能文件存儲——杉巖云原生文件存儲(以下簡稱杉巖CNFS),為客戶實現All in One的存儲能力。
存算分離實現方案:客戶端模式
杉巖CNFS支持客戶端模式,提供HCFS(Hadoop Compatible File System,Hadoop兼容文件協議)接口實現,對HDFS接口協議完全兼容,可以保證應用層就像使用原生HDFS存儲一樣使用杉巖CNFS。
實際場景中,通過在計算平臺部署安裝專用的客戶端與簡單的配置,即可實現Hadoop平臺的組件與分離部署的存儲交互。針對業界使用比較廣泛的CDH平臺(Hadoop商業發行版之一),杉巖CNFS也開發了配套的Parcel資源包,利用CDH自身的管理便捷地配置使用杉巖CNFS提供的存儲空間。
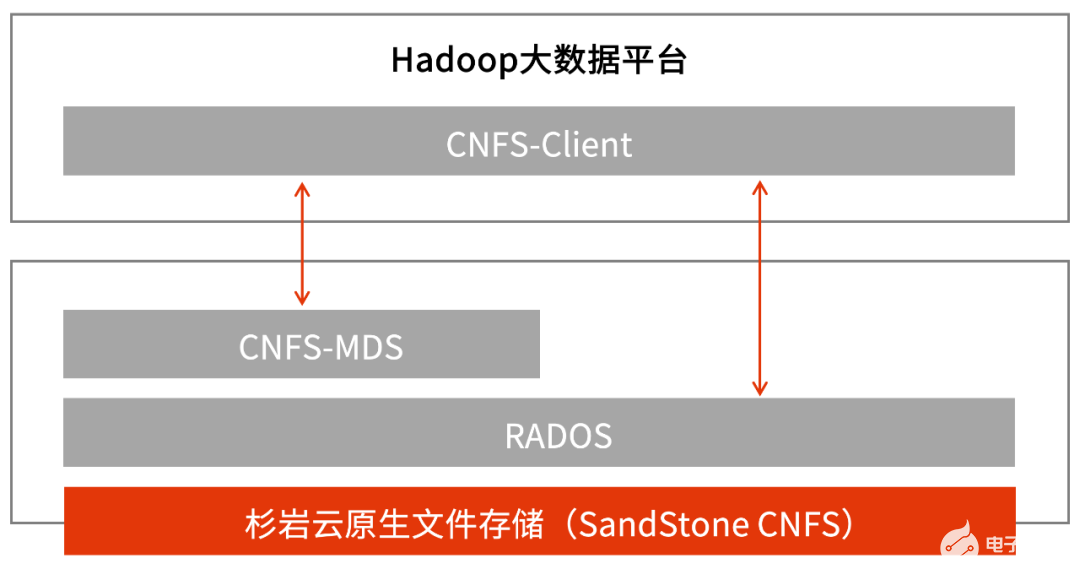
圖1 杉巖湖倉一體方案存算分離實現(客戶端模式)
但是像所有HCFS接口實現一樣,侵入式的部署方式使計算組件有了額外的依賴需要管理,當涉及計算組件自身的升級、替換等場景時,就要考慮杉巖CNFS客戶端軟件包和配置的同步,增加了運維工作。因此這種對接方式一定程度限制了計算組件自身的靈活性。
在實際應用中,用戶如果有相對較為頻繁的升級更替計算組件的場景,往往不能接受侵入式的部署對接方式。
實現無縫對接!杉巖數據推出HDFS網關服務端組件
針對這一需求,杉巖數據研發推出了HDFS網關服務端組件,進一步簡化對接部署過程。HDFS網關實現了原生HDFS協議,可收發原生HDFS協議的請求,計算節點通過Hadoop環境自帶的原生HDFS-Client即可訪問存儲系統,無需額外安裝專用客戶端。
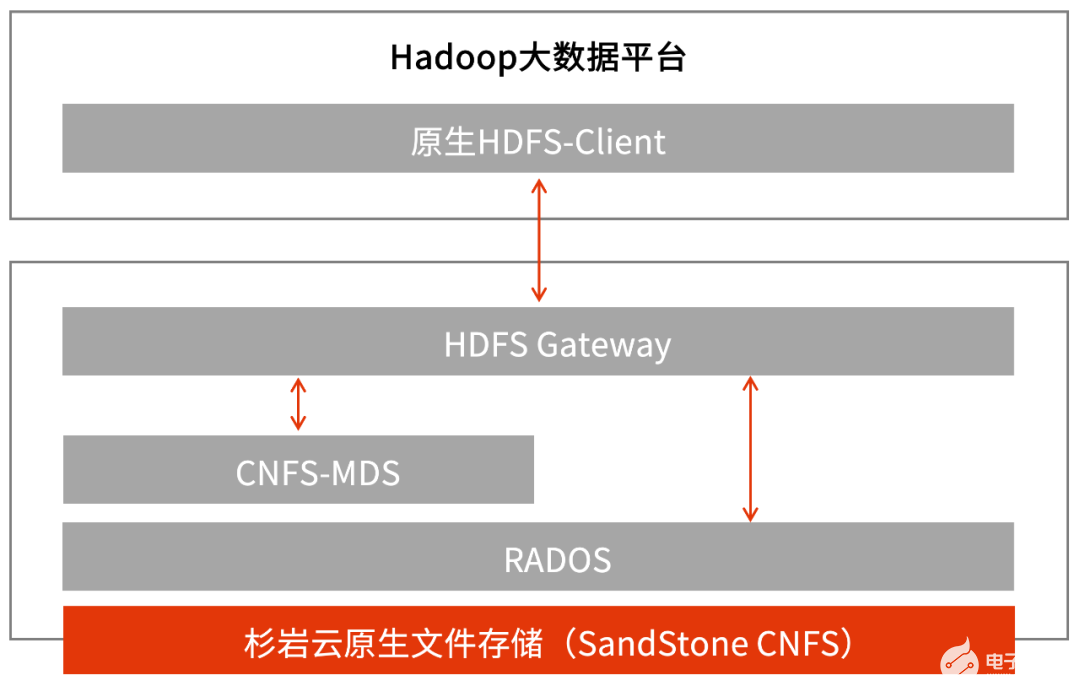
圖2 杉巖湖倉一體方案存算分離實現(服務端模式)
方案優勢
原生HDFS協議,兼容性良好:HDFS網關支持幾乎所有的HDFS數據面接口,可對接市場上常見的大數據平臺。
無縫對接,簡化對接部署過程:通過原生HDFS協議直接訪問存儲系統,無需在計算層安裝專用客戶端。計算組件升級、替換時,無需考慮客戶端配置,減少運維工作量。
高數據吞吐能力,無單點故障:通過杉巖云原生文件存儲對HDFS網關的數據處理卸載能力,大大降低了HDFS網關的數據處理開銷,提升了整體的數據吞吐能力,并結合LVS實現了對HDFS網關的去中心化、水平擴展。
性能測試
LVS只處理HDFS NameNode的元數據相關RPC,實際占大部分網絡帶寬的數據讀寫是DataNode角色的block讀寫流量,不通過LVS,而由HDFS Gateway通過NameNode RPC返回自身節點的IP,HDFS-Client直接和各HDFS Gateway通訊。所以LVS不會成為大數據讀寫的瓶頸,如下圖所示:
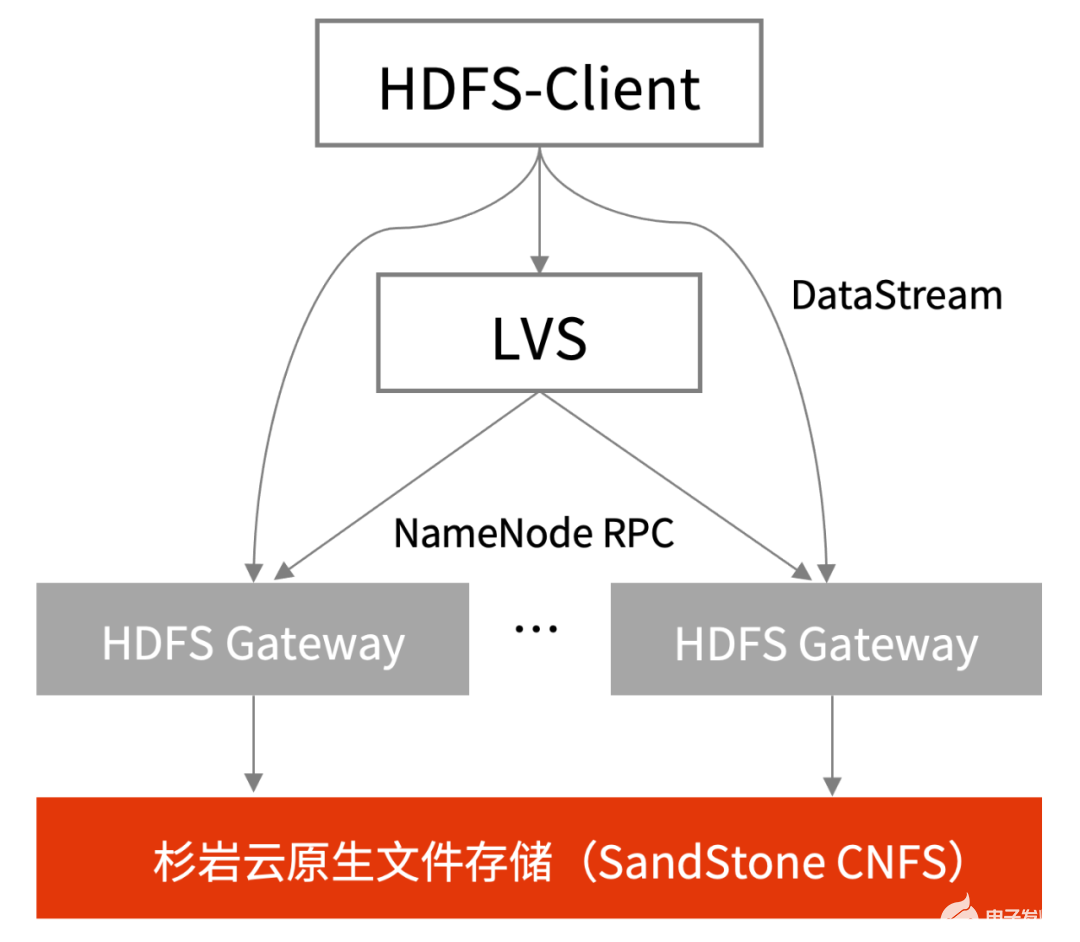
圖3 通過LVS訪問HDFS網關的交互
以下是在3節點存儲加3節點Hadoop集群環境,通過TestDFSIO讀寫9個30G文件的對比測試結果,可見HDFS網關對存儲系統帶寬影響較小。但HDFS網關的增加會使IO路徑長度多一跳,對存儲網絡帶寬需求增加,規劃存儲網絡時應考慮這一點。
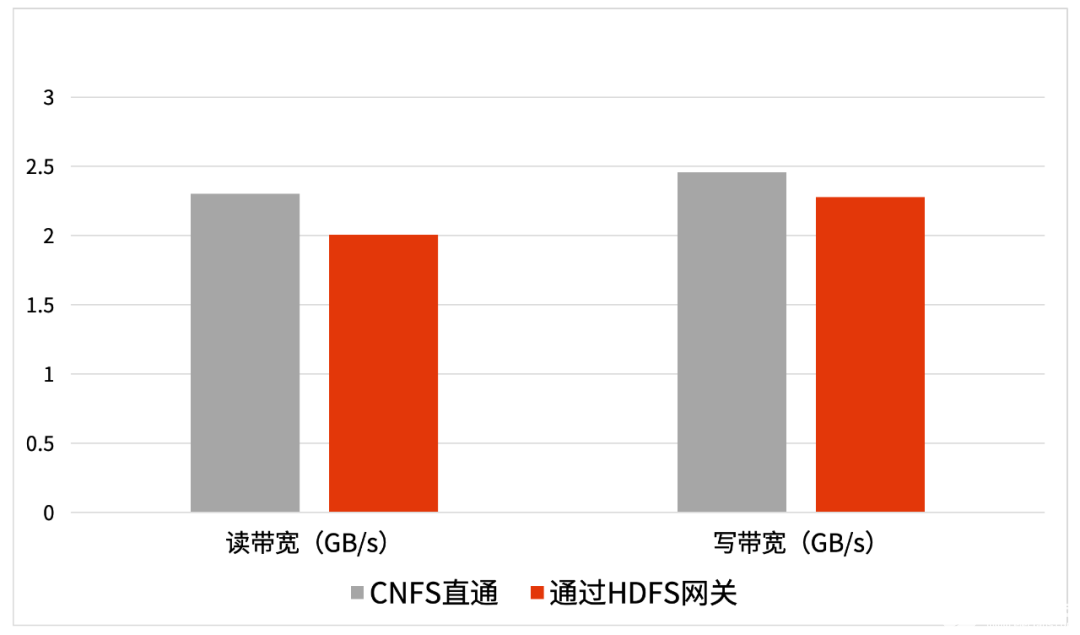
圖4 存算分離場景杉巖CNFS直通和通過HDFS網關帶寬測試
值得一提的是,有些計算層組件可能針對HDFS做特別的優化,例如Hbase就實現了自己的異步HDFS-Client,此情況下使用HDFS網關可以繼續使用計算側的特別優化,能獲得更好的性能。
總結
隨著5G和IoT的快速發展,數據激增,企業級大數據平臺建設逐漸深入,基于存算分離架構,計算承接豐富的應用接入需求,存儲提供成熟穩定的底座支撐業務發展和生態對接是大勢所趨。
上述內容體現了杉巖云原生文件存儲在Hadoop大數據存算分離場景中的優勢,杉巖數據推出HDFS網關服務端組件,通過原生HDFS協議直接訪問存儲系統,簡化了對接部署過程,為用戶提供了更多的選擇,使基于杉巖大數據智能存儲為基座的湖倉一體方案更加完善。
審核編輯:湯梓紅
-
存儲系統
+關注
關注
2文章
413瀏覽量
40865 -
Hadoop
+關注
關注
1文章
90瀏覽量
15992 -
HDFS
+關注
關注
1文章
30瀏覽量
9613 -
大數據
+關注
關注
64文章
8893瀏覽量
137461 -
存算分離
+關注
關注
0文章
6瀏覽量
76
發布評論請先 登錄
相關推薦
開源芯片系列講座第24期:基于SRAM存算的高效計算架構

存算一體化與邊緣計算:重新定義智能計算的未來


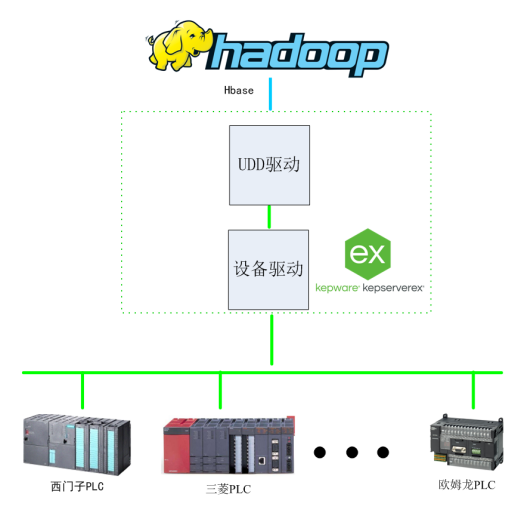
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
計算機存儲系統的工作原理和功能
數據中心存儲系統出現故障的處理方法有哪些?數據中心存儲系統出現故障怎么辦?
知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究






 工商網監
工商網監
評論