最大似然估計學習總結 - 最大似然檢測算法認識與理解
最大似然估計學習總結------MadTurtle
1. 作用
在已知試驗結果(即是樣本)的情況下,用來估計滿足這些樣本分布的參數,把可能性最大的那個參數![]() 作為真實
作為真實![]() 的參數估計。
的參數估計。
2. 離散型
設![]() 為離散型隨機變量,
為離散型隨機變量,![]() 為多維參數向量,如果隨機變量
為多維參數向量,如果隨機變量![]() 相互獨立且概率計算式為P{
相互獨立且概率計算式為P{![]() ,則可得概率函數為P{
,則可得概率函數為P{![]() }=
}=![]() ,在
,在![]() 固定時,上式表示
固定時,上式表示![]() 的概率;當
的概率;當![]() 已知的時候,它又變成
已知的時候,它又變成![]() 的函數,可以把它記為
的函數,可以把它記為![]() ,稱此函數為似然函數。似然函數值的大小意味著該樣本值出現的可能性的大小,既然已經得到了樣本值
,稱此函數為似然函數。似然函數值的大小意味著該樣本值出現的可能性的大小,既然已經得到了樣本值![]() ,那么它出現的可能性應該是較大的,即似然函數的值也應該是比較大的,因而最大似然估計就是選擇使
,那么它出現的可能性應該是較大的,即似然函數的值也應該是比較大的,因而最大似然估計就是選擇使![]() 達到最大值的那個
達到最大值的那個![]() 作為真實
作為真實![]() 的估計。
的估計。
3. 連續型
設![]() 為連續型隨機變量,其概率密度函數為
為連續型隨機變量,其概率密度函數為![]() ,
,![]() 為從該總體中抽出的樣本,同樣的如果
為從該總體中抽出的樣本,同樣的如果![]() 相互獨立且同分布,于是樣本的聯合概率密度為
相互獨立且同分布,于是樣本的聯合概率密度為![]() 。大致過程同離散型一樣。
。大致過程同離散型一樣。
4. 關于概率密度(PDF)
我們來考慮個簡單的情況(m=k=1),即是參數和樣本都為1的情況。假設進行一個實驗,實驗次數定為10次,每次實驗成功率為0.2,那么不成功的概率為0.8,用y來表示成功的次數。由于前后的實驗是相互獨立的,所以可以計算得到成功的次數的概率密度為:
![]() =
=![]() 其中y
其中y![]()
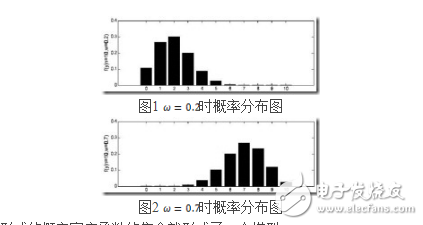
由于y的取值范圍已定,而且![]() 也為已知,所以圖1顯示了y取不同值時的概率分布情況,而圖2顯示了當
也為已知,所以圖1顯示了y取不同值時的概率分布情況,而圖2顯示了當![]() 時的y值概率情況。
時的y值概率情況。
那么![]() 在[0,1]之間變化而形成的概率密度函數的集合就形成了一個模型。
在[0,1]之間變化而形成的概率密度函數的集合就形成了一個模型。
5. 最大似然估計的求法
由上面的介紹可以知道,對于圖1這種情況y=2是最有可能發生的事件。但是在現實中我們還會面臨另外一種情況:我們已經知道了一系列的觀察值和一個感興趣的模型,現在需要找出是哪個PDF(具體來說參數![]() 為多少時)產生出來的這些觀察值。要解決這個問題,就需要用到參數估計的方法,在最大似然估計法中,我們對調PDF中數據向量和參數向量的角色,于是可以得到似然函數的定義為:
為多少時)產生出來的這些觀察值。要解決這個問題,就需要用到參數估計的方法,在最大似然估計法中,我們對調PDF中數據向量和參數向量的角色,于是可以得到似然函數的定義為:
![]()
該函數可以理解為,在給定了樣本值的情況下,關于參數向量![]() 取值情況的函數。還是以上面的簡單實驗情況為例,若此時給定y為7,那么可以得到關于
取值情況的函數。還是以上面的簡單實驗情況為例,若此時給定y為7,那么可以得到關于![]() 的似然函數為:
的似然函數為:
![]()
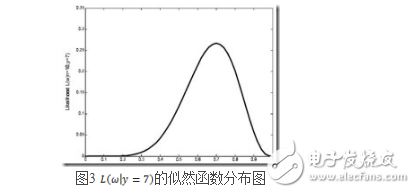
繼續回顧前面所講,圖1,2是在給定![]() 的情況下,樣本向量y取值概率的分布情況;而圖3是圖1,2橫縱坐標軸相交換而成,它所描述的似然函數圖則指出在給定樣本向量y的情況下,符合該取值樣本分布的各種參數向量
的情況下,樣本向量y取值概率的分布情況;而圖3是圖1,2橫縱坐標軸相交換而成,它所描述的似然函數圖則指出在給定樣本向量y的情況下,符合該取值樣本分布的各種參數向量![]() 的可能性。若
的可能性。若![]() 相比于
相比于![]() ,使得y=7出現的可能性要高,那么理所當然的
,使得y=7出現的可能性要高,那么理所當然的![]() 要比
要比![]() 更加接近于真正的估計參數。所以求
更加接近于真正的估計參數。所以求![]() 的極大似然估計就歸結為求似然函數
的極大似然估計就歸結為求似然函數![]() 的最大值點。那么
的最大值點。那么![]() 取何值時似然函數
取何值時似然函數![]() 最大,這就需要用到高等數學中求導的概念,如果是多維參數向量那么就是求偏導。
最大,這就需要用到高等數學中求導的概念,如果是多維參數向量那么就是求偏導。
主要注意的是多數情況下,直接對變量進行求導反而會使得計算式子更加的復雜,此時可以借用對數函數。由于對數函數是單調增函數,所以![]() 與
與![]() 具有相同的最大值點,而在許多情況下,求
具有相同的最大值點,而在許多情況下,求![]() 的最大值點比較簡單。于是,我們將求
的最大值點比較簡單。于是,我們將求![]() 的最大值點改為求
的最大值點改為求![]() 的最大值點。
的最大值點。
![]()
若該似然函數的導數存在,那么對![]() 關于參數向量的各個參數求導數(當前情況向量維數為1),并命其等于零,得到方程組:
關于參數向量的各個參數求導數(當前情況向量維數為1),并命其等于零,得到方程組:
![]()
可以求得![]() 時似然函數有極值,為了進一步判斷該點位最大值而不是最小值,可以繼續求二階導來判斷函數的凹凸性,如果
時似然函數有極值,為了進一步判斷該點位最大值而不是最小值,可以繼續求二階導來判斷函數的凹凸性,如果![]() 的二階導為負數那么即是最大值,這里再不細說。
的二階導為負數那么即是最大值,這里再不細說。
還要指出,若函數![]() 關于
關于![]() 的導數不存在,我們就無法得到似然方程組,這時就必須用其它的方法來求最大似然估計值,例如用有界函數的增減性去求
的導數不存在,我們就無法得到似然方程組,這時就必須用其它的方法來求最大似然估計值,例如用有界函數的增減性去求![]() 的最大值點
的最大值點
- 第 1 頁:最大似然檢測算法認識與理解
- 第 2 頁:最大似然估計學習總結
本文導航
非常好我支持^.^
(162) 93.6%
不好我反對
(11) 6.4%
相關閱讀:
- [電子說] 智慧礦山ai算法系列解析 堵料檢測算法功能優勢 2023-09-28
- [工業控制] 基于改進FCOS的表面缺陷檢測算法 2023-09-28
- [電子說] 淺談圖像處理-harris角點檢測算法 2023-09-22
- [電子說] 更深層地理解深偽技術 2023-09-11
- [電子說] 大學畢業設計一席談之四十一 壓電信號的睡眠檢測算法(11)完善程序 2023-08-29
- [汽車電子] 基于Transformer的目標檢測算法難點 2023-08-24
- [電子說] 掌握基于Transformer的目標檢測算法的3個難點 2023-08-22
- [汽車電子] 基于Transformer的目標檢測算法 2023-08-16
( 發表人:李倩 )