 電子發燒友App
電子發燒友App


1. 全文一覽
激光雷達全景分割是自動駕駛車輛全面理解周圍物體和場景的關鍵技術,它要求算法具有實時性。最近的無先驗方法雖然加快了運算速度,但由于難以建模不存在的實例中心和高昂的基于中心的聚類開銷,其有效性和效率仍然有限。為了實現準確和實時的激光雷達全景分割,本文提出了一種新的中心對焦網絡(CFNet)。具體來說,本文提出了一種中心對焦特征編碼(CFFE)模塊,它通過移動激光雷達點并填充中心點,顯式地建模了原始激光雷達點與虛擬實例中心之間的關系。此外,本文提出了一種中心去重模塊(CDM),它可以高效地保留每個實例的唯一中心,消除冗余的中心檢測。在SemanticKITTI和nuScenes兩個全景分割基準數據集上的評估結果表明,與所有現有方法相比,我們的CFNet在性能上取得了顯著的提升,同時速度比最高效的方法快1.6倍。
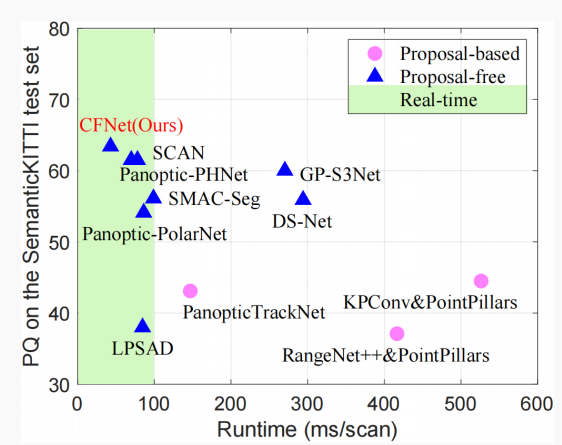
圖1. SemanticKITTI測試集上的PQ與運行時間。
2. 問題簡介
全景分割是一種將語義分割和實例分割結合在一起的技術。它為不可數的東西類(例如道路,人行道)分配語義標簽,同時為可數的東西類(例如汽車,行人)分配語義標簽和實例ID。激光雷達全景分割是自動駕駛安全的重要基礎,它利用激光雷達傳感器采集的點云有效地描述周圍環境。現有的激光雷達全景分割方法通常先進行語義分割,然后通過兩種方式實現東西類的實例分割,即基于先驗框架和無先驗框架的方法。
基于先驗框架的方法采用與圖像領域中著名的Mask R-CNN類似的兩階段流程。它首先使用3D檢測網絡生成物體先驗框,然后在每個先驗框內單獨提取實例分割結果。如圖1所示,這些方法通常非常復雜,由于其順序的多階段流水線,難以實現實時處理。
基于無先驗框架的方法更為簡潔。為了將東西點與實例ID關聯起來,這些方法通常利用實例中心。具體來說,它們回歸從點到對應中心的偏移量,然后采用與類別無關的基于中心的聚類模塊或基于鳥瞰圖(BEV)的中心熱力圖。然而,這些方法存在兩個問題。首先,對于中心特征提取和中心建模,由于激光雷達點通常是表面聚集的,在大多數情況下,實例中心是不存在的,這增加了難度。如圖2(a)所示,這種困難通常導致一個實例被錯誤地分割成多個部分。其次,對于利用冗余檢測到的中心,聚類模塊(例如MeanShift,DBSCAN)的計算時間過長,無法滿足實時自動駕駛感知系統的需求,而BEV中心熱力圖無法區分不同高度的物體位于同一個BEV網格中。
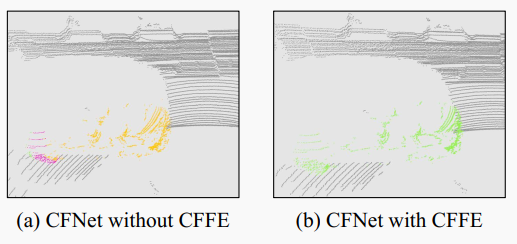
圖2. 一輛車的實例分割案例,不同顏色表示不同的實例。不帶我們的CFFE模塊,汽車被分割成部分(a),而CFFE顯著改善了這個問題(b)。
為了實現準確和快速的激光雷達全景分割,本文提出了一種無先驗框架的中心對焦網絡(CFNet)。為了更好地編碼中心特征,本文提出了一種新的中心對焦特征編碼(CFFE)模塊,它通過移動激光雷達點并填充中心點,以獲得更精確的預測(如圖2(b)所示)。為了更好地建模中心,CFNet不僅將全景分割任務分解為廣泛使用的語義分割和中心偏移回歸,而且還提出了一個新的置信度評分預測,以指示中心偏移回歸的準確性。然后,為了高效地利用檢測到的中心,本文設計了一個新的中心去重模塊(CDM),以選擇每個實例的唯一中心。CDM保留預測置信度更高的中心,同時抑制預測置信度較低的中心。最后,通過將移動后的東西點分配給最近的中心來實現實例分割。為了提高效率,CFNet建立在基于2D投影的分割范式之上。
3. 方法詳析
激光雷達全景分割任務的輸入是激光雷達點云數據集(其中是笛卡爾空間中的3D坐標,表示附加的激光雷達點特征,例如強度)。該任務的目標是為這些點分配一組標簽,其中是語義標簽(例如道路、建筑、汽車、行人),是第個點的實例ID。此外,可以分為不可數的東西類(例如道路、建筑)和可數的東西類(例如汽車、行人)。東西點的實例ID設置為0。
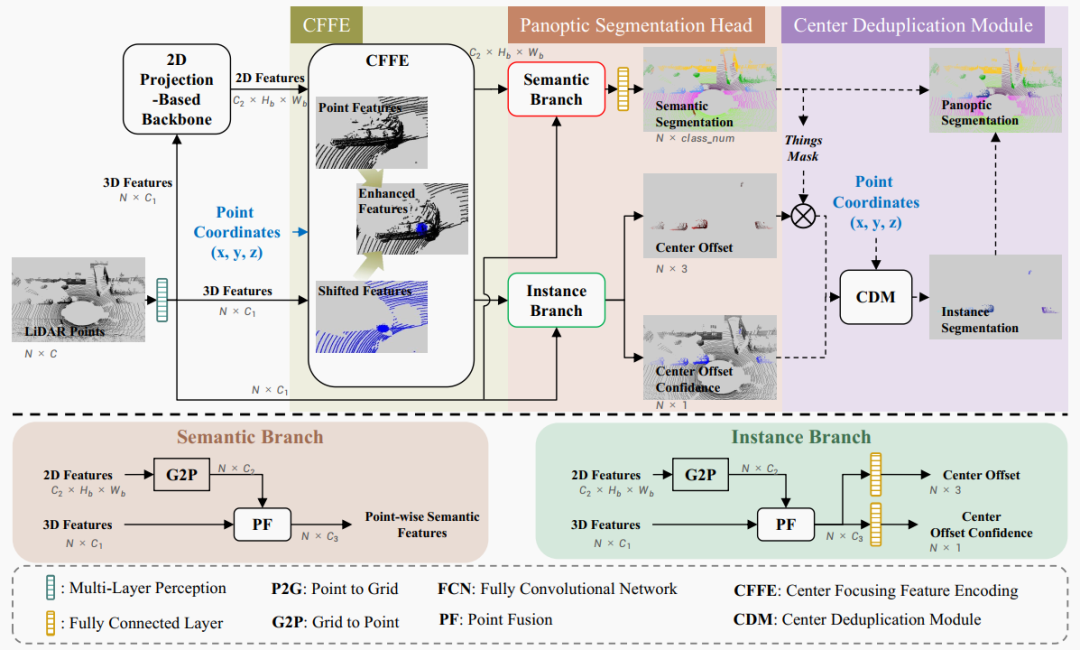
圖3. 我們CFNet的概覽。它由四個步驟組成:1) 基于2D投影的backbone在2D空間上提取特征;2) 提出的中心對焦特征編碼(CFFE)模擬和增強不存在的實例中心特征;3) 全景分割head預測輸出結果;4) 提出的中心去重模塊(CDM)實現實例分割,其與語義分割結果融合生成最終全景分割結果。虛線表示操作僅在推理時使用。
為了預測輸入激光雷達點云的標簽,我們的CFNet將這個過程分解為四個步驟,如圖3所示:1)應用現成的基于2D投影的backbone在2D空間上高效提取特征;2)使用新的中心對焦特征編碼(CFFE)生成中心對焦特征圖,以獲得更準確的預測;3)全景分割head將來自3D點和2D空間的特征進行融合,分別預測語義分割結果、中心偏移和中心偏移的置信度評分;4)在推理時進行后處理,生成全景分割結果,其中新的中心去重模塊(CDM)對移動后的東西點操作,選擇每個實例的一個中心,然后分配移動后的東西點到最近的中心以獲取實例ID。
3.1 中心對焦特征編碼
如上所述,一個對象的激光雷達點通常是表面聚集的,尤其對于汽車和卡車類別,這導致對象的中心是虛構的,在激光雷達點云中不存在。為了編碼不存在中心的特征,提出了一種新的中心對焦特征編碼(CFFE),它以backbone提取的2D特征和3D點坐標為輸入,生成增強的中心對焦特征圖,如圖3所示。
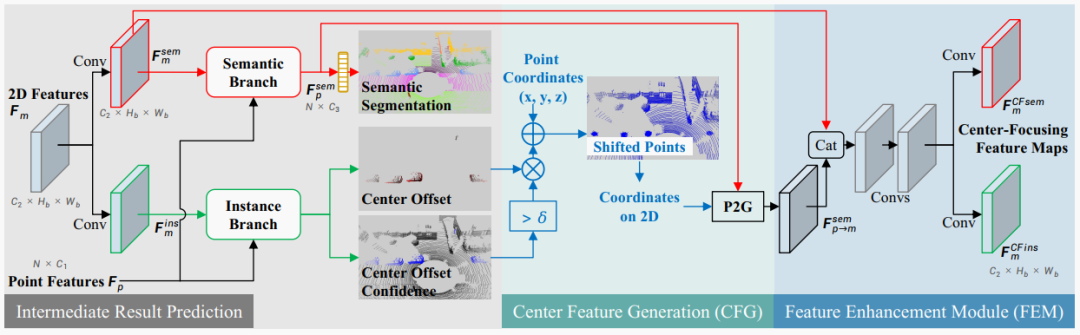
圖4. 提出的中心對焦特征編碼(CFFE)。“Conv”表示帶有3×3內核、批歸一化和ReLU層的2D卷積。語義分支和實例分支的細節如圖3所示。藍色箭頭是坐標相關的操作。
CFFE模塊由三個步驟組成,包括中間結果預測、中心特征生成和特征增強模塊,如圖4所示。
中間結果預測。在這一步中,CFFE根據2D特征 和3D點特征 預測中間結果(包括語義分割、中心偏移和其置信度分數),以便后續模擬中心特征。具體來說,在2D特征 上分別應用兩個卷積層,生成語義特征 和實例特征 (m是特定的2D視圖,如RV、BEV和極坐標視圖)。
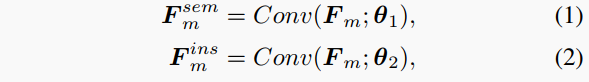
其中Conv表示順序2D卷積、批歸一化和ReLU操作, 和 是它們的可學習參數。然后,語義分支通過融合點特征和2D語義特征生成每點3D語義特征,
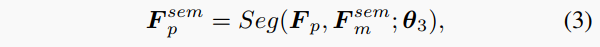
其中Seg是語義分支,是參數。最后,根據生成中間語義結果。中間的中心偏移結果和置信度分數是通過實例分支預測的,輸入為點特征和2D實例特征,
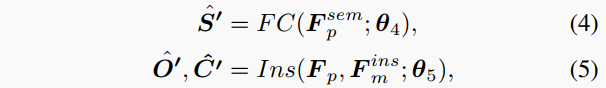
其中Ins是實例分支,FC表示全連接層。語義分支和實例分支的結構及訓練目標與全景分割head中的相同,在圖3和3.2節中說明。
**中心特征生成(CFG)**。在這一步中,CFFE通過將3D語義點特征根據上述中間結果移位到預測的中心,生成移位的中心特征。
首先,根據以下公式計算一個預測中心的坐標:
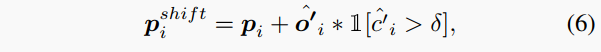
其中是原始3D激光雷達點坐標,是一個二值指示器,指示置信度是否大于。換句話說,它不移動東西點或置信度低的東西點。
然后,將移位的3D點作為新坐標的特征點,將3D語義特征 通過Point to Grid (P2G)操作重新投影到具有這個新坐標的2D投影特征圖上。
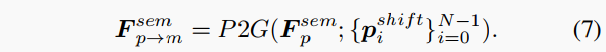
與相比,更關注假想的中心,因為大多數東西點已經移位到它們預測的中心。
**特征增強模塊(FEM)**。CFFE最后融合語義特征圖和重新投影的移位中心特征圖來生成中心對焦語義特征圖和實例特征圖,它們將由后續的語義分支和實例分支進行更準確的預測。增強模塊由簡單的連接操作和幾個卷積層組成,詳細結構在補充材料中。
另外,對于應用多視圖融合backbone的情況,每個視圖的特征圖、、、 (例如m ∈ {RV, BEV})都根據上述流程獨立計算。然后,它們在點融合(PF)模塊中進行融合,生成集成的3D點特征和每點預測。
3.2 全景分割頭
為了更好地建模實例中心,全景分割頭使用語義分支預測語義分割,實例分支同時估計中心偏移和新引入的置信度分數,給定中心對焦語義特征圖和實例特征圖。
語義分支。為了進行每點預測,語義分支首先應用Grid到點(G2P)操作從2D語義特征圖獲取3D點表示。然后,一個PF模塊將來自G2P操作的點表示和原始3D點進行融合,生成點表示的語義特征。在獲得點的語義特征之后,一個全連接(FC)層用于預測最終的每點語義結果()。 表示第個激光雷達點屬于第類的概率。預測的語義標簽通過選擇概率最高的類獲得,即 。
參考CPGNet,采用了相同的損失函數,包括加權交叉熵損失、Lovász-Softmax損失和轉換一致性損失。
實例分支。與語義分支類似,實例分支也采用G2P操作和一個PF模塊獲得點表示的實例特征。一個FC層用于預測每點的中心偏移。的真值是從第個點到其對應的實例中心的偏移向量。
對于中心偏移回歸,優化的損失函數僅考慮東西類,形式化如下:
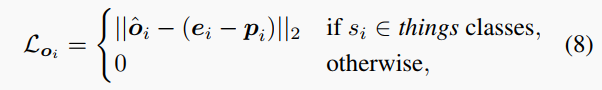
其中是實例的軸對齊中心。
然后,損失函數求和如下:
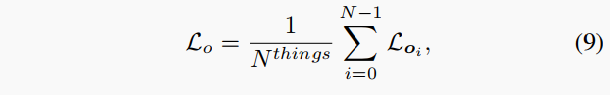
其中和分別是所有點和東西點的數量。
對于置信度分數回歸,另一個FC層用于預測每點的置信度分數,以指示的準確度。通過sigmoid激活函數激活以確保。監督的真值標簽由以下生成:
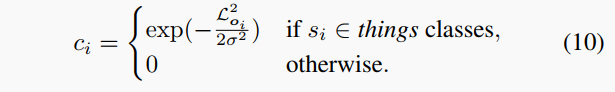
對于東西點,越低,越高。這意味著中心偏移回歸更準確的點有更高的置信度分數。
采用加權二進制交叉熵損失,
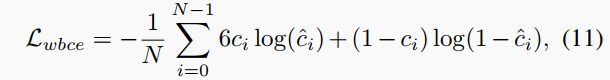
其中東西點被手動強調,因為它們的數量遠少于東西點的數量。
最后,每個結果組(來自CFNet或CFFE)的損失定義為:
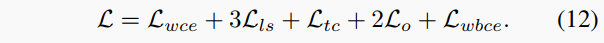
總損失是來自CFNet和CFFE的兩個損失之和。
3.3 中心去重模塊
給定最終預測的語義分割結果、中心偏移和置信度分數,本節介紹如何在推理時利用檢測到的中心來獲取全景分割結果,并闡述關鍵模塊中心去重模塊(CDM)。
后處理。對于全景分割結果,首先生成實例分割,然后通過融合語義分割和實例分割標簽獲得最終全景分割。有五個步驟生成最終全景分割:
根據預測的語義標簽選擇東西點,以及它們的偏移和置信度分數(其中M是東西點的數量)。
每個移位后的東西點作為實例中心候選。
CDM根據坐標和置信度分數為每個實例選擇一個中心,同時抑制其他候選中心。
實例ID 通過將移位后的東西點分配給所有中心中最近的一個獲得(D是檢測到的實例數量)。
多數投票法將一個預測實例中最頻繁出現的語義標簽重新分配給該實例的所有點,以進一步確保預測實例內語義標簽的一致性。
**中心去重模塊(CDM)**。CDM以移位點和置信度分數為輸入,為每個實例獲得一個中心。受到邊界框NMS的啟發,如果兩個中心之間的歐式距離小于閾值,我們的CDM會抑制置信度較低的中心。CDM的偽代碼如算法1所示,其中兩個中心距離小于被認為是同一個實例。CDM的過程很簡單,可以輕松在CUDA中實現。
4. 實驗結果
本文在SemanticKITTI和nuScenes全景分割基準上評估了CFNet,在單個NVIDIA RTX 3090 GPU上進行運行時間測量,使用全景質量(PQ)指標評估性能。經驗證,CFNet在兩個基準上的表現均遠超現有方法,CFNet比最高效的方法快1.6倍。
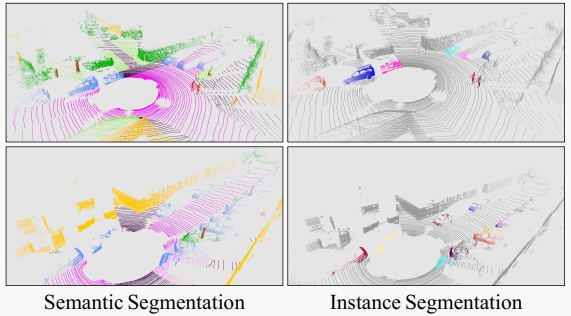
圖5. 我們的 CFNet 在 SemanticKITTI 測試集上的可視化。不同的顏色代表不同的類或實例。
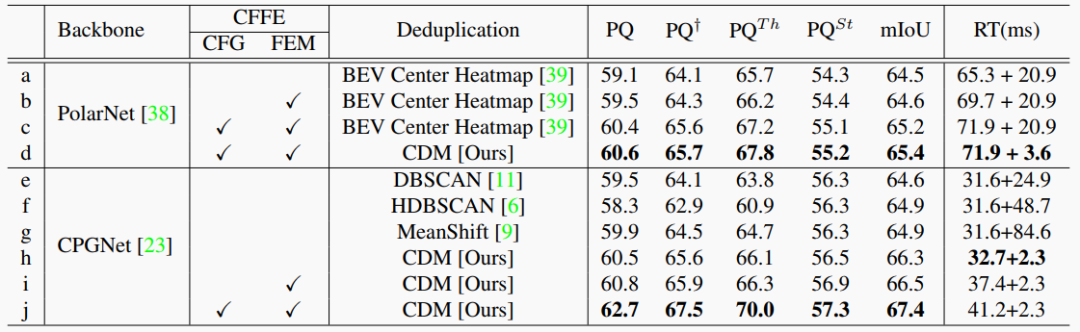
表1. SemanticKITTI驗證集上的ablation研究。RT:運行時間。
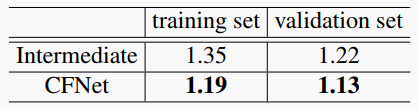
表2. 在SemanticKITTI訓練集和驗證集上,中間結果和帶CFFE的CFNet的東西中心偏移的平均誤差,單位米(m)。
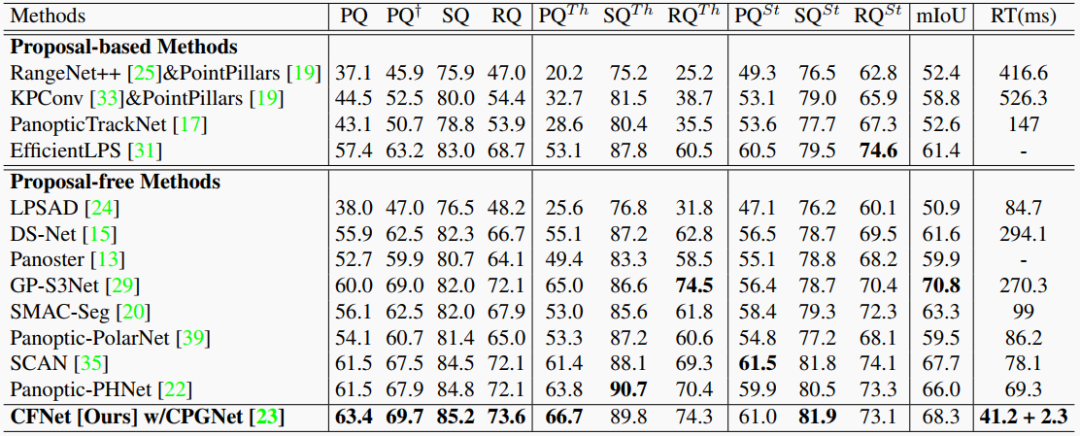
表3. SemanticKITTI 測試集的結果。
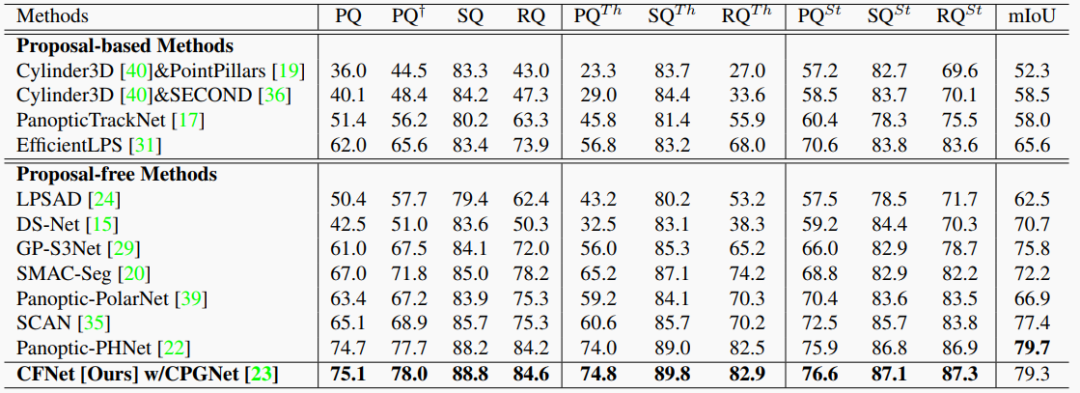
表4. NuScenes 驗證集的結果。
5. 結論
本文提出了一種新穎的無先驗的中心對焦網絡(CFNet),用于實時的激光雷達全景分割。為了更好地建模和利用不存在的實例中心,本文提出了一種新的中心對焦特征編碼(CFFE)模塊,用于生成增強的中心對焦特征圖,以及一種中心去重模塊(CDM),用于為每個實例保留唯一的中心,然后將移動后的東西點分配給最近的中心,以獲取實例ID。從實驗中可以看出,中心建模和利用是無先驗的激光雷達全景分割方法中的一個關鍵問題,而模擬不存在的中心特征是有前景的,并且顯示出明顯的優勢。
審核編輯:黃飛
?












 工商網監
工商網監
評論