 電子發燒友App
電子發燒友App


近日AWS re:Invent2022隆重召開,作為一年一度的云科技盛會,AWS高級副總裁Pete DeSantis介紹了 AWS 的一些重大工作成果與改進,主要包含硬件、網絡、科學和軟件四部分。本文將重點介紹Nitro V5、Graviton3E以及SRD網絡傳輸協議方面的創新。
硬件:Nitro V5、Graviton3E
會上,AWS 宣布推出第五代Nitro網絡安全芯片和硬件管理系統,以及全新基于ARM架構、自研的高性能計算服務器CPU芯片Graviton 3E。
Nitro V5
Nitro V5由 Annapurna Labs 團隊打造,是AWS DPU的最新迭代。DeSantis 指出,與上代相比,Nitro V5采用的晶體管數量翻倍,內存速度提高了50%,PCIe帶寬也實現了翻倍。這意味著Nitro V5每瓦性能提高40%,PPS(每包設備轉發)性能提高60%,延遲降低30%,此外,能耗比也將提升大約30%。

Graviton 3E
AWS 專為高性能工作負載設計推出了新的 Graviton3E CPU。相比具有550億個晶體管的Graviton 3,Graviton 3E在性能上有較大提升,包括并行負載執行效率(HPL)最高提升35%,用于金融相關運算執行效率提升30%。

DeSantis 表示,Graviton 3E在某些高性能計算能力上是現有Graviton芯片的兩倍,當與其他AWS技術結合時新芯片的性能提高20%。在虛擬化應用部分,Graviton 3E芯片可組成最多64組虛擬CPU,并具有128GB存儲容量,最快將在2023年初開始布署應用。
EC2 實例
DeSantis 還展示了三個新的 EC2 實例——C7gn、R7iz 和 Hpc7g。
1)C7gn由 AWS Graviton3E和 Nitro v5提供支持,專為要求苛刻的網絡密集型工作負載而設計,例如虛擬網絡設備和數據分析。C7gn實例支持高達 200 Gbps 的網絡帶寬和高達 50% 的數據包處理性能,它將提供多種尺寸,最多 64 個 vCPU 和 128 GiB 內存。
2)Hpc7g同樣由 Graviton3E 提供支持,這個新實例將提供多種大小,最多 64 個 vCPU 和 128 GiB 內存。它旨在為緊密耦合的計算密集型 HPC 和分布式計算工作負載的公司提供最佳性價比。
3)R7iz由第 4 代英特爾至強可擴展處理器(代號 Sapphire Rapids)提供支持,將提供多種大小,最多 128 個 vCPU 和 1 TiB 內存。
客戶變友商?
2021年,AWS業務凈銷售額為622.02億美元,同比增長37%,是全球最大的云計算提供商,也是數據中心芯片的最大買家之一。但Graviton 3E的推出,使AWS與其合作伙伴英特爾、英偉達、AMD“芯片三巨頭”展開競爭。
服務器芯片市場歷來由英特爾主導,但近年來AMD 占據了很大一部分業務,英偉達的 GPU 也因運行AI系統和其他復雜任務而受到許多企業的青睞。AWS 相信自己也有機會從中獲利,據悉,AWS在2015年收購了芯片制造商Annapurna Labs,隨后開始自研芯片設計工作。
DeSantis 認為,與購買英特爾、英偉達或AMD芯片相比,AWS自研芯片將為客戶提供更具性價比的算力支持。不過他也強調AWS與上述伙伴仍維持著密切的合作關系,并計劃繼續提供基于這些芯片廠商的高性能計算芯片相關服務。
網絡:SRD協議
網絡部分的重點是SRD網絡協議,SRD全稱Scalable Reliable Datagram,意思是可擴展的可靠數據報,SRD 是 AWS 為提高 HPC 性能而開發的一種高吞吐、低延遲的網絡傳輸協議,并于 2019 年公布。DeSantis聲稱 SRD 協議優于 TCP。
1970 年代起出現的TCP/IP 雖然是目前以太網架構的主要傳輸手段,但它的問題在于不適合對延遲敏感的應用,TCP傳輸是一對一的連接,就算解決了時延的問題,也難在故障時重新快速連線。
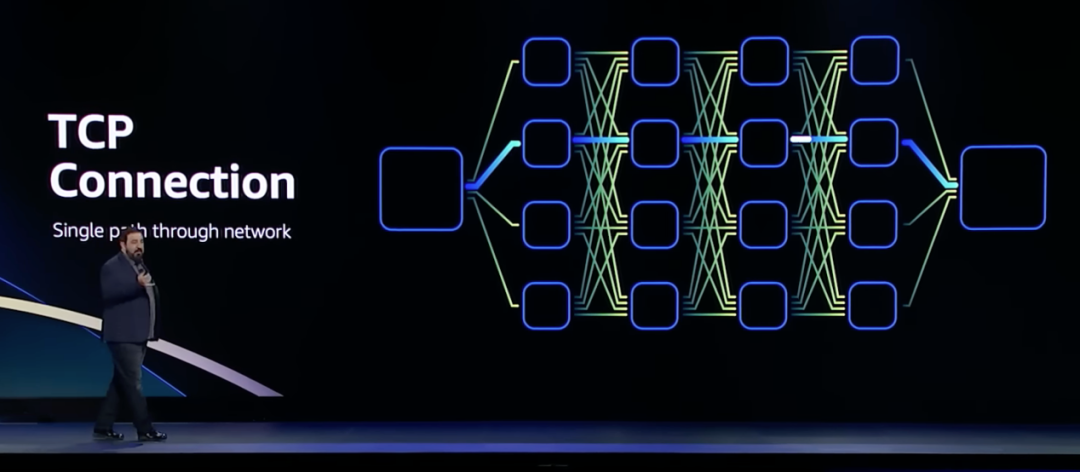
具體來看,數據中心中,理想情況下TCP的往返延遲為25us左右,如果發生擁塞或鏈路故障,TCP需要的等待時長會上升至50ms。帶來這些延遲的主要原因是TCP丟包之后的重傳機制。
TCP 是通用協議,沒有針對HPC場景進行優化,早在2020 年,AWS 已經提出需要移除TCP。
SRD 協議是專門為AWS網絡構建和優化的,可以將丟包重傳的延時從毫秒級降低到微秒級。

SRD提供跨多個路徑的負載平衡以及從數據包丟失或鏈路故障中快速恢復。利用商用以太網交換機上的標準ECMP功能并解決其局限性。SRD采用專門的擁塞控制算法,通過將排隊保持在最低限度,有助于進一步降低丟包的機會并最大限度地減少重傳時間。
SRD提供可靠但亂序的交付,并將次序恢復的任務留給上層。強制執行嚴格的有序交付通常只會造成隊頭阻塞、增加延遲并減少帶寬。SRD不保留數據包順序,而是通過盡可能多的網絡路徑發送數據包,同時避免路徑過載。通過在接收處以極快的速度進行重新排序,最終在充分利用網絡吞吐能力的基礎上,極大降低傳輸延遲。
DeSantis表示,EFA、EBS和ENA都用上了自家的SRD。
EFA是用于大規模運行HPC/ML應用的高性能網絡接口,直接與Nitro 控制器配合使用,實現更低延遲和更高吞吐量,支持內核旁路和RDMA。這避免了使用傳統網絡協議的上下文切換和內存復制帶來的低延遲和性能下降。對性能敏感的應用更適合使用EFA。

EBS(Elastic Block Store)
EBS為EC2實例提供塊級存儲,它被各種任務關鍵型應用(如IO密集型數據庫使用),對于塊存儲,性能、離群值、尾部延遲都很重要。EBS對網絡延遲最敏感的地方之一是寫入,它能將極少數(P99.999)會出現的35ms延遲降低五倍,并且能將整體的延遲水平降到一個全新的水平。
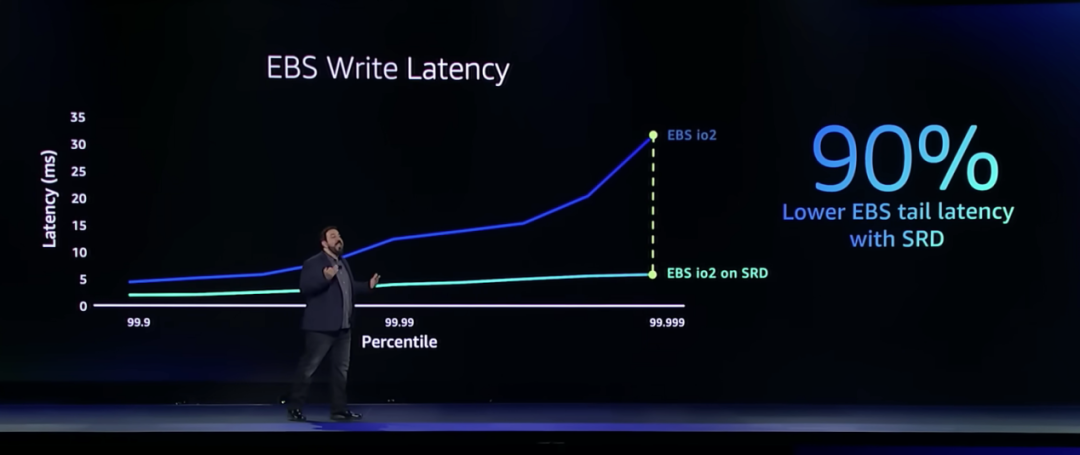
EBS和SRD的結合還將吞吐量提高了4倍。

DeSantis表示即將推出的新的EBS io2 數據平臺,將與SRD 一起運行。
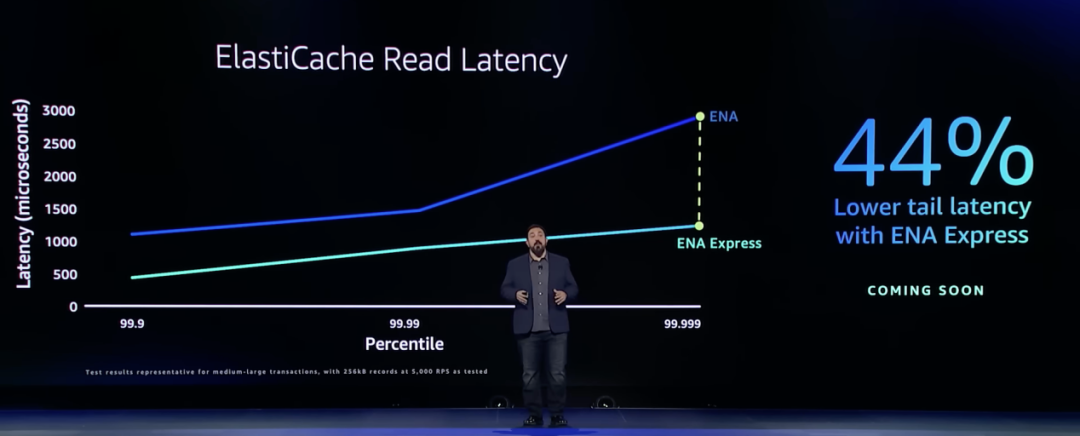
ENA(Elastic Network Adapter)
ENA是用于EC2實例的標準網絡驅動程序。ENA利用Nitro控制器從主EC2服務器卸載工作,允許客戶講更多資源用于他們的工作負載。ENA Express可以引入任何網絡接口,可以與任何網絡協議(如TCP/UDP)一起工作,只需在ENA上啟用ENA Express接口,就可以獲得更低延遲和更高吞吐量。
?

科學:機器學習
科學方面的創新主要討論的是機器學習,DeSantis談到的兩大性能改進是:
1)使用STOCHASTIC ROUNDING,使用戶能夠同時獲得16位計算精度的訓練速度和32位的計算精度。
2)Ring of Rings 算法使計算處理器能夠在模型每次迭代后更有效地交換信息,從而使處理器之間的同步速度提高 75%。
軟件:Lambda SnapStart
軟件運行方面的創新主要談的是Lambda SnapStart。Lambda 是一項計算服務,是 Serverless 技術的先驅者,使用者無需預置或管理服務器即可運行代碼。
Lambda 最大的優勢就是模型操作簡單、價格經濟實惠,但仍面臨著“冷啟動”這一挑戰,Lambda SnapStart 通過使用Firecracker及快照功能將性能提高90%,減少了Lambda運行軟件應用時的冷啟動時間。此外,Lambda SnapStart可以對延遲敏感的 Java 應用程序提供高達 10 倍更快啟動時間的改進性能,只需最少或無需更改代碼。
值得一提的是,DeSantis稱 Amazon Lambda SnapStart 版本自發布起免費向公眾開放,Amazon Lambda SnapStart 項目地址:
https://github.com/aws/aws-lambda-snapstart-java-rules
編輯:黃飛
?










 工商網監
工商網監
評論