 電子發燒友App
電子發燒友App











 創作
創作 發文章
發文章 發帖
發帖  提問
提問  發資料
發資料 發視頻
發視頻資料介紹
作者:Gerry Raptis
利用乒乓機制的交錯隊列減少風險
在本篇文章中,我們將提到Vulkan 圖形處理過程中夾雜計算任務時遇到的各式問題。為更準確地了解我們的話題,可查看文章第一部分。
第一部分概述了在Vulkan中如何使用barrier;具體來說,涉及圖形→計算barrier,隨后是一個中間幀計算→圖形barrier。這會嚴重削弱GPU任務調度能力,并導致暫停,降低性能。為此我們給出了在多種資源配置情況下的不同解決方案。
體系架構級方法
"算法"優先的方法是手動使任務交錯:也就是說,以我們希望的順序提交任務,并使它們在GPU 上執行。這會生成正確結果,也為我們提供足夠的可控性。在該情況下,首先為上一"邏輯"幀提交計算任務BN-1(注意缺少早期圖形任務),然后提交當前幀AN的早期圖形任務。隨后,將提交計算/圖形Barrier,接下來提交上一幀CN-1的后期圖形任務,最后提交圖形/計算Barrier。
這種方法會產生良好的結果,但會有損幀分離性,使維護更加困難。它對邏輯資源的需求將加倍,因為至少部分后期幀的操作代碼需要比早期幀操作先調度。此外,會引入一個額外的滯后幀。
其執行過程如下:
幀N: BN-1→AN→ 計算/圖形barrier → CN-1 → 圖形/計算barrier→提交N-1
幀N+1: BN→ AN+1→ 計算/圖形barrier → CN → 圖形/計算barrier→提交N
這將允許BN-1/AN重疊。
聽起來很復雜,而且也確實如此:計算多個幀操作通常需要大量的記錄。但是,如果在此方案中任務封裝的不錯,至少一定程度上會緩解該問題。但是,如果復雜性更高時(即更復雜的猜測計算→barrier→圖形→barrier→計算→barrier→圖形工作負載),它仍然可能崩潰。在任何情況下,為降低不斷增加的CPU 端復雜性成本,可以定制解決方案。
每個任務使用不同隊列
另一個有效的解決方案是使用不同的隊列,并在每個隊列提交幀的不同部分:每個早期計算、后期計算、早期圖形和后期圖形提交到自己的隊列,任務間連接使用信號量而非barrier。例如 ,PowerVR開發套件中的Vulkan粒子系統就是采用該方法,在對應的專用隊列中提交所有計算。
但在我看來,該方案有其挑戰性,它比交錯幀更好,因為它允許 GPU 處理自己的問題,而不會弄亂引擎的非 API 部分。在我看來,它也是第一個"真正的"解決方案。類似于上述方案,它至少會緩解部分問題。在討論其自身體系結構上的計算后處理時,Arm 在其社區網站上也將目光投向該方案。但是,它又取決于某些特定任務的重疊,一般來說,需要仔細生成大量的信號量,并且借助于隊列優先級,這些增加了部分復雜性,但也為您提供了另一個控制向量。在多個交錯計算/圖形任務的情況下,它也可能不能完全按照我們預期的方式工作。該方案非常有效,可能將其與別的方案結合是個好思路。
我們已經找到了值得推薦的不同方案。
更簡單、通用的方案:乒乓機制的交錯隊列
我們相信我們可以更簡單、更有效的方式來完成計算。為此,我們需要從全局上考慮我們的最終目標:我們需要在沒有Vulkan 規范介入的前提下,使 GPU 能夠在連續兩個幀中交替工作。
Vulkan 規范團隊中的精明者可能已經意識到,barrier是始終指向單個隊列的構造器。
PowerVR(和許多其它設備)設備可能會暴露多個相同/可互換的通用隊列(圖形+計算以及可能的呈現)。
因此,在這種情況下,為在不重新調整幀前提下避免跨幀同步,我們可以在不同隊列中為每個幀提交負載。這將允許一個幀中的任何負載與下一幀中的任何負載交錯執行,即使具有多個不同的圖形、頂點和計算任務,因為它們在不同隊列上顯式執行,可以不受制于彼此的barrier。
簡單來說:從同一隊列源中創建兩個相同的隊列,然后對于每個幀,您提交負載到與上一隊列不同的隊列上。隊列源很重要,因為它可以使您不必擔心資源隊列所有權等問題。
因此,幀提交過程如下:
幀 0:獲取下一個圖像→ 渲染 0(A0)→ 圖形/計算barrier→ 計算0(B0)→計算/圖形barrier→渲染0′(C0)→提交到隊列0 →呈現到隊列 0
幀 1:獲取下一個圖像→ 渲染 1A1→ 圖形/計算barrier→ 計算1B1→計算/圖形barrier→渲染1′C1→提交到隊列1→呈現到隊列1
幀 2:獲取下一個圖像→ 渲染2 A2→ 圖形/計算barrier→ 計算2B2→計算/圖形barrier→渲染2′C2→提交到隊列0 →呈現到隊列 0
幀 3:獲取下一個圖像→ 渲染 3A3→ 圖形/計算barrier→ 計算3B3→計算/圖形barrier→渲染3′C3→提交到隊列1→呈現到隊列1
...等等。
那么,這行得通嗎?而且,如果可以,其原因是什么?
確實可行。BN(當前幀計算)和 CN(當前幀的后期圖形)之間的barrier將阻止 CN在BN完成之前啟動,但不會阻止 AN+1(下一幀的早期圖形)啟動,因為它在與Barrier不同的隊列上提交(一個額外的好處,由于隊列不同,AN+1與CN不需要強制排序)。
此技術解決了問題的核心:應用程序設置的barrier,旨在在單個幀中等待風險的發生,不會導致后續幀之間的任務間等待。我發現它相當令人欣喜,而且是迄今為止最簡單的可實現方案——只要您的通用隊列源中有多個隊列,就可以使用單個計數器(甚至是布爾類型)并交換每一幀,此時無需進一步修改:只要我們確保 CPU 資源得到正確管理(與單個隊列相同),不須施加額外同步。
簡而言之,由于每個連續幀都在不同的隊列中提交,因此 GPU 可以自由地在幀之間并行調度任務,預期結果為 (CN+1) 在(AN) 完成之后開始執行。它可確保渲染器及其相應的調度程序始終繁忙,并且中間的計算不會串行化幀。
—————–
計算工作負載:B0B1 B2B3 B4B5
圖形工作負載:A0 A1 C0 C1 A2 A3 C2 C3 A4 A5 C4 C5 ...
或(基本相同的效果)如下:
計算工作負載:B0 B1 B2 B3 B4 B5
圖形工作負載:A0 A1 C0 A2 C1 A3 C2 A4 C3 A5 C4 C5 ...
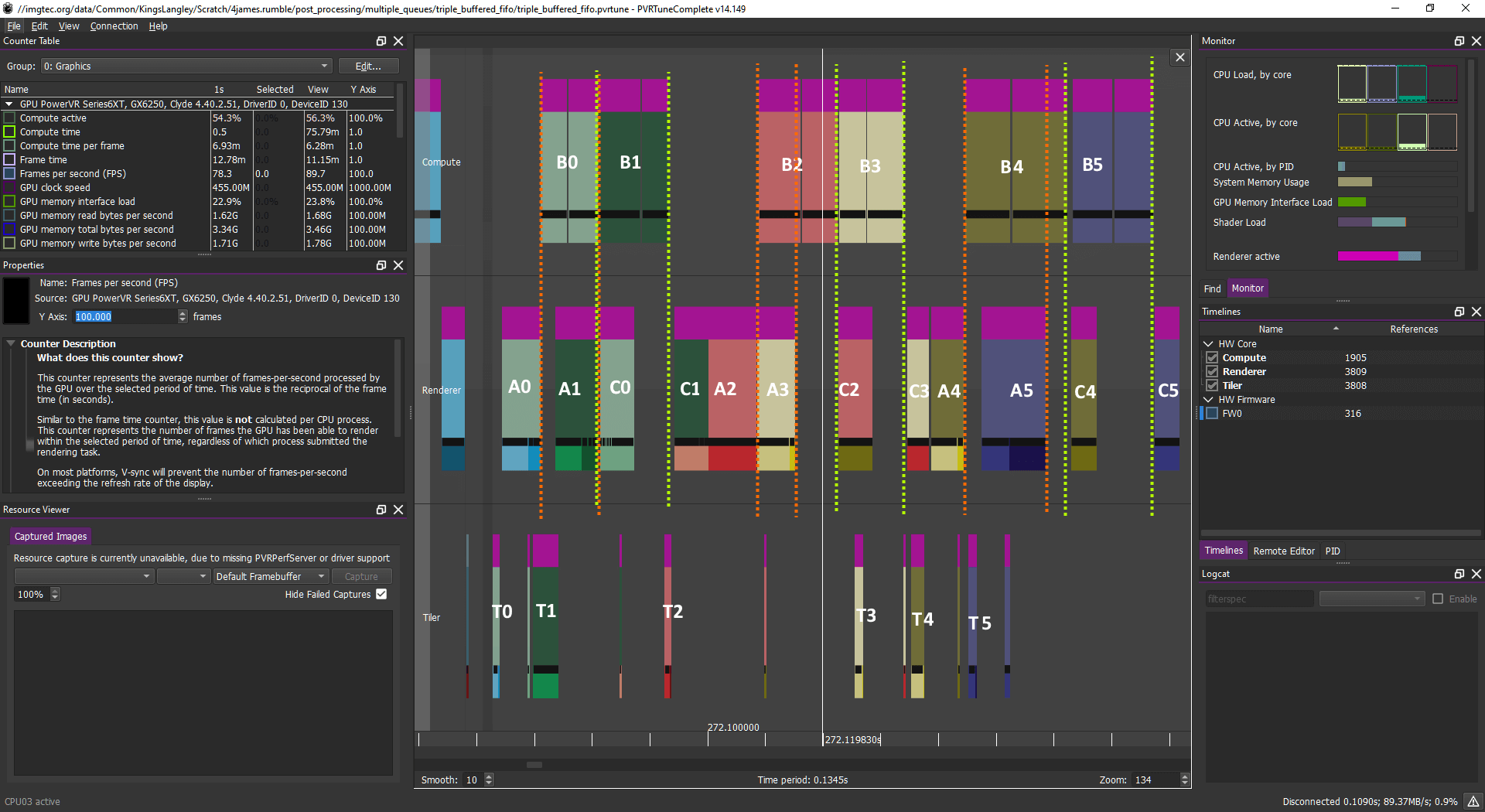
乍一看,這看起來可能很復雜,但實際很簡單。無論如何,該圖示告訴我們,GPU 正在處理一個幀(N)的計算,同時處理下一幀 (N+1) 的早期圖形或上一幀的后期圖形。
完全封裝的情況是"相當不可能",它甚至沒有必要達到這種水平的封裝。但是,您應具備類似的特征,計算與頂點/片段任務一起調度,允許USC 加載使用盡可能多的容量。
其他的適用方案
通常,在任何存在barrier的情況下(而不僅僅是圖形/計算/圖形)時使用此技術是一個好思路。在任何情況下,它都不會有損性能,并且在--任何情況下調度器都具備更好的靈活性。調度器可能不需要額外的靈活性,但在任何情況下它都不會有損性能,而且增加的復雜性微不足道。
任何類型的barrier(包括圖形/圖形)都有可能損害 GPU 調度不同幀負載的能力并會導致暫停(順便說一下,這是考慮使用barrier一個非常重要的原因,如果不考慮該因素,可以使用子類依賴性而非barrier)。計算示例非常重要,因為即使它們共享 PowerVR 上的執行內核、圖形和計算部件,它們也在不同的數據主設備上工作,因此始終有些任務要并行執行,因此,如果可能,我們總是希望它們盡量重疊工作。但是,即使只是不同幀的圖形負載交錯執行,也通常允許您在頂點和片段任務之間獲得更多的重疊,并確保 GPU 更好的飽和性。
因此,任何barrier情況都存在潛在風險,所以使用多個隊列是備選。
注意事項:如何采用交錯隊列防止亂序
我們未能發現任何嚴重的不利條件。在不同幀之間使用不同的隊列沒有額外開銷。我們確定的唯一限制很明顯:同一隊列源必須支持多個圖形計算隊列,不過,所有 PowerVR 設備都支持該特性。
我們能夠識別的另一潛在問題是確保正確的呈現順序。但是,交換鏈對象本身將確保這一點,因為圖像以 FIFO 和郵箱呈現模式調用的 vkQueuePresent 順序呈現。對于其它模式(例如即時),您可能需要確保當前操作正確同步,以便按順序執行;這也相當容易實現。
最后,如果設備強制采用單個呈現隊列,您可以修改如下,最終只在單個隊列上呈現:
幀 0:獲取下一個圖像→ 渲染 0→ 記錄圖形/計算barrier→ 計算0 →計算/圖形barrier→渲染0′→提交到隊列0 →呈現到隊列 0
幀 1:獲取下一個圖像→ 渲染 1→ 記錄圖形/計算barrier→ 計算1→計算/圖形barrier→渲染1′→提交到隊列1 →呈現到隊列0
幀 2:獲取下一個圖像→ 渲染2→ 記錄圖形/計算barrier→ 計算2→計算/圖形barrier→渲染2′→提交到隊列0 →呈現到隊列 0
幀 3:獲取下一個圖像→ 渲染 3→ 記錄圖形/計算barrier→ 計算3→計算/圖形barrier→渲染3′→提交到隊列1 →呈現到隊列0
...等等。
它不僅利用了并行性,還確保了具有交換鏈"特殊"實現的驅動程序不會出現亂序幀呈現的風險。
簡言之,我們完全可以放心的使用該技術。如果你發現了潛在的問題,請告訴我們。
重要性能說明
需要提醒的是,PowerVR 調度時與 CPU 線程調度工作方式不同,因為后者需要昂貴的上下文切換并保存到主存——如果調度器在同一 USC 上并行執行兩個任務,在大多數情況下,它們之間切換成本為零,因此每當需要等待操作時(例如內存訪問),調度器都可以切換到另一個任務并隱藏內存操作延遲。這是我們性能得以提升的重要部分。
下面是我們需要澄清的:該技術主要不是填充可能出現空閑的不同硬件部分負載,我們試圖做的是指導驅動程序正確調度負載,減少開銷并隱藏延遲。PowerVR 是一個統一的體系結構,頂點、圖形和計算任務都在同一個 USC 上執行。與在不同頂點和片段著色器內核單獨執行的早期圖形設備不同,100%性能提升是無法實現的。我們不是要填充空閑內核;只是要 GPU非空閑時, 所有USC 都在運行(不排除一些意外狀況發生)。
最后,在僅有圖形的負載中,還可能會遇到這樣的情況,barrier會阻止不同幀之間的重疊。
未來工作
當您希望將不同的任務提交到不同的隊列類型/源情況下,此技術可以而且將起作用。一個重要的免責聲明是,該技術不會取代幀的不同負載使用不同隊列的潛在好處——如本文及其他文章中所討論到的,使用不同的專用隊列(特別是使用不同的隊列優先級來最小化幀延遲)。
因此,在這些情況下,可以使用相同的邏輯——唯一的區別是,您不會將一個隊列分裂為兩個隊列,而是將所有(或大多數)使用barrier的隊列復用。這可能并非所有隊列,因此不能替代常識和良好設計。在某些體系結構中,您可能使用三個不同的隊列,并且只需要將其中一個或者多個中的兩個隊列復用并進行乒乓操作。最重要的是在barrier旁邊至少增加一個隊列。
例如,假設一個專用計算隊列與多個通用隊列并存,此技術可能仍然有用。事實上,在多數的有趣場景下,擁有多組具有不同優先級的不同隊列并且幀之間交換集,這可以提供驚人的精細控制和靈活性。
這種情況可能工作如下:
(此處的隊列 C2 是一個專用計算隊列,隊列 0 和隊列 1 是我們要復用的通用隊列):
幀 0:獲取下一個圖像→ 渲染 0 → 提交到隊列 0 → 信號量給隊列 2 → 計算 0,提交到隊列 C2→ 信號量給隊列 0 → 渲染0′→ 提交到隊列 0→ 呈現給隊列 0
幀1:獲取下一個圖像→ 渲染1→ 提交到隊列 1→ 信號量給隊列 2→ 計算 1,提交到隊列 C2→ 信號量給隊列 1→ 渲染1′→ 提交到隊列 1→ 呈現給隊列 1
幀2:獲取下一個圖像→ 渲染2→ 提交到隊列 0 → 信號量給隊列 2 → 計算 2,提交到隊列 C2→ 信號量給隊列 0 → 渲染2′→ 提交到隊列 0→ 呈現給隊列 0
幀 3:獲取下一個圖像→ 渲染3→ 提交到隊列1→ 信號量給隊列 2 → 計算 3,提交到隊列 C2→ 信號量給隊列 1→ 渲染3′→ 提交到隊列 1→ 呈現給隊列 1
幀 4:獲取下一個圖像→ 渲染4→ 提交到隊列 0 → 信號量給隊列 2 → 計算 4,提交到隊列 C2→ 信號量給隊列 0 → 渲染4′→ 提交到隊列 0→ 呈現給隊列 0
同樣,此處的多個圖形隊列是必要的,以允許在當前幀的第二次渲染之前調度連續幀的第一次渲染。
結論
我們向您展現了一個非常完整和通用的解決方案,用以解決常見但現實的難題。無論何時,盡可能為每幀使用多個隊列,您可以無風險、更簡單地獲得驚人的性能提升。希望這將對您的項目有幫助!如果該技術確實幫助到您,歡迎向我們分享您的故事。
我們在 PowerVR SDK中的許多演示中都使用此技術,而且我們在編寫后處理演示時也受到了啟發,并使用了該技術。
英文鏈接:https://www.imgtec.com/blog/vulkan-synchronisation-and-graphics-compute-...
來源:電子創新網
- 基于FPGA和DSP的機載圖形顯示系統 36次下載
- 如何用Matlab繪制二維圖形資料下載
- Vulkan同步機制和圖形-計算-圖形轉換的風險(一)
- Microchip圖形庫與鍵盤的配合使用 0次下載
- 混合式數據同步機制 0次下載
- 一種采用Lock_Free同步機制的數據結構的研究 0次下載
- MFC編程基礎-圖形學 0次下載
- MFC圖形界面編程入門教程 0次下載
- 計算機圖形學講義 0次下載
- 用于無線網絡MMORPG的同步機制 13次下載
- MATLAB圖形繪制基本技術 0次下載
- 域一致性新型鎖同步機制的實現
- 多線程同步機制在應用程序與驅動程序通信中的應用
- 圖形處理器的流執行模型
- 圖形的數學處理--基點計算,節點計算,輔助計算
- 計算機圖形學:探索虛擬世界的構建之道 264次閱讀
- 圖形渲染的技術和原理:探索視覺效果的奇妙世界 683次閱讀
- 從圖形到通用計算:GPGPU技術的進化之路 880次閱讀
- MATLAB中特殊圖形的繪制示例 741次閱讀
- 30個MATLAB圖形繪制 1439次閱讀
- 淺談Linux kernel中的同步機制 747次閱讀
- 數字/同步機轉換器的設計方案 2028次閱讀
- 基于有限狀態機的FlexRay時鐘同步機制 3295次閱讀
- 可變電阻器的圖形符號 2.3w次閱讀
- PCB圖形轉移關鍵工藝過程分析 5551次閱讀
- 計算機圖形學年鑒:研究現狀、應用和未來 1081次閱讀
- 常用電氣電路的圖形符號 5w次閱讀
- 計算機圖形學總覽:圖像和圖像的概念辨析 6457次閱讀
- 清華AMiner團隊發布計算機圖形學研究報告 3002次閱讀
- 基于FPGA圖形和字符加速的液晶顯示設計 2522次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1電子電路原理第七版PDF電子教材免費下載
- 0.00 MB | 1491次下載 | 免費
- 2單片機典型實例介紹
- 18.19 MB | 95次下載 | 1 積分
- 3S7-200PLC編程實例詳細資料
- 1.17 MB | 27次下載 | 1 積分
- 4筆記本電腦主板的元件識別和講解說明
- 4.28 MB | 18次下載 | 4 積分
- 5開關電源原理及各功能電路詳解
- 0.38 MB | 11次下載 | 免費
- 6100W短波放大電路圖
- 0.05 MB | 4次下載 | 3 積分
- 7基于單片機和 SG3525的程控開關電源設計
- 0.23 MB | 4次下載 | 免費
- 8基于AT89C2051/4051單片機編程器的實驗
- 0.11 MB | 4次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 2PADS 9.0 2009最新版 -下載
- 0.00 MB | 66304次下載 | 免費
- 3protel99下載protel99軟件下載(中文版)
- 0.00 MB | 51209次下載 | 免費
- 4LabView 8.0 專業版下載 (3CD完整版)
- 0.00 MB | 51043次下載 | 免費
- 5555集成電路應用800例(新編版)
- 0.00 MB | 33562次下載 | 免費
- 6接口電路圖大全
- 未知 | 30320次下載 | 免費
- 7Multisim 10下載Multisim 10 中文版
- 0.00 MB | 28588次下載 | 免費
- 8開關電源設計實例指南
- 未知 | 21539次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935053次下載 | 免費
- 2protel99se軟件下載(可英文版轉中文版)
- 78.1 MB | 537793次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420026次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234313次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191183次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183277次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138039次下載 | 免費





 工商網監
工商網監
評論