 電子發(fā)燒友App
電子發(fā)燒友App


深度學習本質(zhì)上是深層的人工神經(jīng)網(wǎng)絡,它不是一項孤立的技術(shù),而是數(shù)學、統(tǒng)計機器學習、計算機科學和人工神經(jīng)網(wǎng)絡等多個領(lǐng)域的綜合。深度學習的理解,離不開本科數(shù)學中最為基礎(chǔ)的數(shù)學分析(高等數(shù)學)、線性代數(shù)、概率論和凸優(yōu)化;深度學習技術(shù)的掌握,更離不開以編程為核心的動手實踐。沒有扎實的數(shù)學和計算機基礎(chǔ)做支撐,深度學習的技術(shù)突破只能是空中樓閣。
所以,想在深度學習技術(shù)上有所成就的初學者,就有必要了解這些基礎(chǔ)知識之于深度學習的意義。除此之外,我們的專業(yè)路徑還會從結(jié)構(gòu)與優(yōu)化的理論維度來介紹深度學習的上手,并基于深度學習框架的實踐淺析一下進階路徑。
最后,本文還將分享深度學習的實踐經(jīng)驗和獲取深度學習前沿信息的經(jīng)驗。
數(shù)學基礎(chǔ)
如果你能夠順暢地讀懂深度學習論文中的數(shù)學公式,可以獨立地推導新方法,則表明你已經(jīng)具備了必要的數(shù)學基礎(chǔ)。
掌握數(shù)學分析、線性代數(shù)、概率論和凸優(yōu)化四門數(shù)學課程包含的數(shù)學知識,熟知機器學習的基本理論和方法,是入門深度學習技術(shù)的前提。因為無論是理解深度網(wǎng)絡中各個層的運算和梯度推導,還是進行問題的形式化或是推導損失函數(shù),都離不開扎實的數(shù)學與機器學習基礎(chǔ)。
數(shù)學分析
在工科專業(yè)所開設的高等數(shù)學課程中,主要學習的內(nèi)容為微積分。對于一般的深度學習研究和應用來說,需要重點溫習函數(shù)與極限、導數(shù)(特別是復合函數(shù)求導)、微分、積分、冪級數(shù)展開、微分方程等基礎(chǔ)知識。在深度學習的優(yōu)化過程中,求解函數(shù)的一階導數(shù)是最為基礎(chǔ)的工作。當提到微分中值定理、Taylor公式和拉格朗日乘子的時候,你不應該只是感到與它們似曾相識。這里推薦同濟大學第五版的《高等數(shù)學》教材。
線性代數(shù)
深度學習中的運算常常被表示成向量和矩陣運算。線性代數(shù)正是這樣一門以向量和矩陣作為研究對象的數(shù)學分支。需要重點溫習的包括向量、線性空間、線性方程組、矩陣、矩陣運算及其性質(zhì)、向量微積分。當提到Jacobian矩陣和Hessian矩陣的時候,你需要知道確切的數(shù)學形式;當給出一個矩陣形式的損失函數(shù)時,你可以很輕松的求解梯度。這里推薦同濟大學第六版的《線性代數(shù)》教材。
概率論
概率論是研究隨機現(xiàn)象數(shù)量規(guī)律的數(shù)學分支,隨機變量在深度學習中有很多應用,無論是隨機梯度下降、參數(shù)初始化方法(如Xavier),還是Dropout正則化算法,都離不開概率論的理論支撐。除了掌握隨機現(xiàn)象的基本概念(如隨機試驗、樣本空間、概率、條件概率等)、隨機變量及其分布之外,還需要對大數(shù)定律及中心極限定理、參數(shù)估計、假設檢驗等內(nèi)容有所了解,進一步還可以深入學習一點隨機過程、馬爾可夫隨機鏈的內(nèi)容。這里推薦浙江大學版的《概率論與數(shù)理統(tǒng)計》。
凸優(yōu)化
結(jié)合以上三門基礎(chǔ)的數(shù)學課程,凸優(yōu)化可以說是一門應用課程。但對于深度學習而言,由于常用的深度學習優(yōu)化方法往往只利用了一階的梯度信息進行隨機梯度下降,因而從業(yè)者事實上并不需要多少“高深”的凸優(yōu)化知識。理解凸集、凸函數(shù)、凸優(yōu)化的基本概念,掌握對偶問題的一般概念,掌握常見的無約束優(yōu)化方法如梯度下降方法、隨機梯度下降方法、Newton方法,了解一點等式約束優(yōu)化和不等式約束優(yōu)化方法,即可滿足理解深度學習中優(yōu)化方法的理論要求。這里推薦一本教材,Stephen Boyd的《Convex Optimization》。
機器學習
歸根結(jié)底,深度學習只是機器學習方法的一種,而統(tǒng)計機器學習則是機器學習領(lǐng)域事實上的方法論。以監(jiān)督學習為例,需要你掌握線性模型的回歸與分類、支持向量機與核方法、隨機森林方法等具有代表性的機器學習技術(shù),并了解模型選擇與模型推理、模型正則化技術(shù)、模型集成、Bootstrap方法、概率圖模型等。深入一步的話,還需要了解半監(jiān)督學習、無監(jiān)督學習和強化學習等專門技術(shù)。這里推薦一本經(jīng)典教材《The elements of Statistical Learning》。
計算機基礎(chǔ)
深度學習要在實戰(zhàn)中論英雄,因此具備GPU服務器的硬件選型知識,熟練操作Linux系統(tǒng)和進行Shell編程,熟悉C++和Python語言,是成長為深度學習實戰(zhàn)高手的必備條件。當前有一種提法叫“全棧深度學習工程師”,這也反映出了深度學習對于從業(yè)者實戰(zhàn)能力的要求程度:既需要具備較強的數(shù)學與機器學習理論基礎(chǔ),又需要精通計算機編程與必要的體系結(jié)構(gòu)知識。
編程語言
在深度學習中,使用最多的兩門編程語言分別是C++和Python。迄今為止,C++語言依舊是實現(xiàn)高性能系統(tǒng)的首選,目前使用最廣泛的幾個深度學習框架,包括Tensorflow、Caffe、MXNet,其底層均無一例外地使用C++編寫。而上層的腳本語言一般為Python,用于數(shù)據(jù)預處理、定義網(wǎng)絡模型、執(zhí)行訓練過程、數(shù)據(jù)可視化等。當前,也有Lua、R、Scala、Julia等語言的擴展包出現(xiàn)于MXNet社區(qū),呈現(xiàn)百花齊放的趨勢。這里推薦兩本教材,一本是《C++ Primer第五版》,另外一本是《Python核心編程第二版》。
Linux操作系統(tǒng)
深度學習系統(tǒng)通常運行在開源的Linux系統(tǒng)上,目前深度學習社區(qū)較為常用的Linux發(fā)行版主要是Ubuntu。對于Linux操作系統(tǒng),主要需要掌握的是Linux文件系統(tǒng)、基本命令行操作和Shell編程,同時還需熟練掌握一種文本編輯器,比如VIM。基本操作務必要做到熟練,當需要批量替換一個文件中的某個字符串,或者在兩臺機器之間用SCP命令拷貝文件時,你不需要急急忙忙去打開搜索引擎。這里推薦一本工具書《鳥哥的Linux私房菜》。
CUDA編程
深度學習離不開GPU并行計算,而CUDA是一個很重要的工具。CUDA開發(fā)套件是NVidia提供的一套GPU編程套件,實踐當中應用的比較多的是CUDA-BLAS庫。這里推薦NVidia的官方在線文檔。
其他計算機基礎(chǔ)知識
掌握深度學習技術(shù)不能只滿足于使用Python調(diào)用幾個主流深度學習框架,從源碼著手去理解深度學習算法的底層實現(xiàn)是進階的必由之路。這個時候,掌握數(shù)據(jù)結(jié)構(gòu)與算法(尤其是圖算法)知識、分布式計算(理解常用的分布式計算模型),和必要的GPU和服務器的硬件知識(比如當我說起CPU的PCI-E通道數(shù)和GPU之間的數(shù)據(jù)交換瓶頸時,你能心領(lǐng)神會),你一定能如虎添翼。
深度學習入門
接下來分別從理論和實踐兩個角度來介紹一下深度學習的入門。
深度學習理論入門
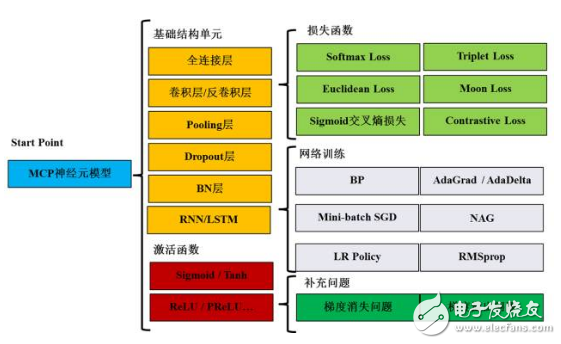
我們可以用一張圖(圖1)來回顧深度學習中的關(guān)鍵理論和方法。從MCP神經(jīng)元模型開始,首先需要掌握卷積層、Pooling層等基礎(chǔ)結(jié)構(gòu)單元,Sigmoid等激活函數(shù),Softmax等損失函數(shù),以及感知機、MLP等經(jīng)典網(wǎng)絡結(jié)構(gòu)。接下來,掌握網(wǎng)絡訓練方法,包括BP、Mini-batch SGD和LR Policy。最后還需要了解深度網(wǎng)絡訓練中的兩個至關(guān)重要的理論問題:梯度消失和梯度溢出。
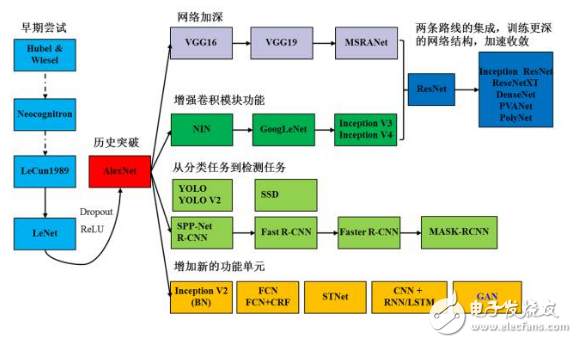
以卷積神經(jīng)網(wǎng)絡為例,我們用圖2來展示入門需要掌握的知識。起點是Hubel和Wiesel的對貓的視覺皮層的研究,再到日本學者福島邦彥神經(jīng)認知機模型(已經(jīng)出現(xiàn)了卷積結(jié)構(gòu)),但是第一個CNN模型誕生于1989年,1998年誕生了后來被大家熟知的LeNet。隨著ReLU和Dropout的提出,以及GPU和大數(shù)據(jù)所帶來的歷史機遇,CNN在2012年迎來了歷史性的突破——誕生了AlexNet網(wǎng)絡結(jié)構(gòu)。2012年之后,CNN的演化路徑可以總結(jié)為四條:
更深的網(wǎng)絡;
增強卷積模的功能以及上訴兩種思路的融合ResNet和各種變種;
從分類到檢測,最新的進展為ICCV 2017的Best Paper Mask R-CNN;
增加新的功能模塊。
深度學習實踐入門
掌握一個開源深度學習框架的使用,并進一步地研讀代碼,是實際掌握深度學習技術(shù)的必經(jīng)之路。當前使用最為廣泛的深度學習框架包括Tensorflow、Caffe、MXNet和PyTorch等。框架的學習沒有捷徑,按照官網(wǎng)的文檔step by step配置及操作,參與GitHub社區(qū)的討論,遇到不能解答的問題及時Google是快速實踐入門的好方法。
初步掌握框架之后,進一步的提升需要依靠于具體的研究問題,一個短平快的策略是先刷所在領(lǐng)域權(quán)威的Benchmark。例如人臉識別領(lǐng)域的LFW和MegaFace,圖像識別領(lǐng)域與物體檢測領(lǐng)域的ImageNet、Microsoft COCO,圖像分割領(lǐng)域的Pascal VOC等。通過復現(xiàn)或改進別人的方法,親手操練數(shù)據(jù)的準備、模型的訓練以及調(diào)參,能在所在領(lǐng)域的Benchmark上達到當前最好的結(jié)果,實踐入門的環(huán)節(jié)就算初步完成了。
后續(xù)的進階,就需要在實戰(zhàn)中不斷地去探索和提升了。例如:熟練的處理大規(guī)模的訓練數(shù)據(jù),精通精度和速度的平衡,掌握調(diào)參技巧、快速復現(xiàn)或改進他人的工作,能夠?qū)崿F(xiàn)新的方法等等。
深度學習實戰(zhàn)經(jīng)驗
在這里,分享四個方面的深度學習實戰(zhàn)經(jīng)驗。
1. 充足的數(shù)據(jù)
大量且有標注的數(shù)據(jù),依舊在本質(zhì)上主宰著深度學習模型的精度,每一個深度學習從業(yè)者都需要認識到數(shù)據(jù)極端重要。獲取數(shù)據(jù)的方式主要有三種:開放數(shù)據(jù)(以學術(shù)界開放為主,如ImageNet和LFW)、第三方數(shù)據(jù)公司的付費數(shù)據(jù)和結(jié)合自身業(yè)務產(chǎn)生的數(shù)據(jù)。
2. 熟練的編程實現(xiàn)能力
深度學習算法的實現(xiàn)離不開熟練的編程能力,熟練使用Python進行編程是基礎(chǔ)。如果進一步的修改底層實現(xiàn)或增加新的算法,則可能需要修改底層代碼,此時熟練的C++編程能力就變得不可或缺。一個明顯的現(xiàn)象是,曾經(jīng)只需要掌握Matlab就可以笑傲江湖的計算機視覺研究者,如今也紛紛需要開始補課學習Python和C++了。
3. 充裕的GPU資源
深度學習的模型訓練依賴于充裕的GPU資源,通過多機多卡的模型并行,就可以有效的提高模型收斂速度,從而更快的完成算法驗證和調(diào)參。一個專業(yè)從事深度學習的公司或?qū)嶒炇遥瑩碛袛?shù)十塊到數(shù)百塊的GPU資源已經(jīng)是普遍現(xiàn)象。
4. 創(chuàng)新的方法
以深度學習領(lǐng)域權(quán)威的ImageNet競賽為例,從2012年深度學習技術(shù)在競賽中奪魁到最后一屆2017競賽,方法創(chuàng)新始終是深度學習進步的核心動力。如果只是滿足于多增加一點數(shù)據(jù),把網(wǎng)絡加深或調(diào)幾個SGD的參數(shù),那么是難以做出真正一流的成果的。
根據(jù)筆者的切身經(jīng)歷,方法創(chuàng)新確實能帶來難以置信的結(jié)果。一次參加阿里巴巴組織的天池圖像檢索比賽,筆者提出的一點創(chuàng)新——使用標簽有噪聲數(shù)據(jù)的新型損失函數(shù),結(jié)果竟極大地提高了深度模型的精度,還拿到了當年的冠軍。
深度學習前沿
前沿信息的來源:
實戰(zhàn)中的技術(shù)進階,必需要了解深度學習的最新進展。換句話說,就是刷論文:除了定期刷Arxiv,刷代表性工作的Google Scholar的引用,關(guān)注ICCV、CVPR和ECCV等頂級會議之外,知乎的深度學習專欄和Reddit上時不時會有最新論文的討論(或者精彩的吐槽)。
一些高質(zhì)量的公眾號,例如Valse前沿技術(shù)選介、深度學習大講堂、Paper Weekly等,也時常有深度學習前沿技術(shù)的推送,也都可以成為信息獲取的來源。同時,關(guān)注學術(shù)界大佬LeCun和Bengio等人的Facebook/Quora主頁,關(guān)注微博大號“愛可可愛生活”等人,也常有驚喜的發(fā)現(xiàn)。
建議關(guān)注的重點:
新的網(wǎng)絡結(jié)構(gòu)。在以SGD為代表的深度學習優(yōu)化方法沒有根本性突破的情況下,修改網(wǎng)絡結(jié)構(gòu)是可以較快提升網(wǎng)絡模型精度的方法。2015年以來,以ResNet的各種改進為代表的各類新型網(wǎng)絡結(jié)構(gòu)如雨后春筍般涌現(xiàn),其中代表性的有DenseNet、SENet、ShuffuleNet等。
新的優(yōu)化方法。縱觀從1943年MCP模型到2017年間的人工神經(jīng)網(wǎng)絡發(fā)展史,優(yōu)化方法始終是進步的靈魂。以誤差反向傳導(BP)和隨機梯度下降(SGD)為代表的優(yōu)化技術(shù)的突破,或是Sigmoid/ReLU之后全新一代激活函數(shù)的提出,都非常值得期待。筆者認為,近期的工作如《Learning gradient descent by gradient descent》以及SWISH激活函數(shù),都很值得關(guān)注。但能否取得根本性的突破,也即完全替代當前的優(yōu)化方法或ReLU激活函數(shù),尚不可預測。
新的學習技術(shù)。深度強化學習和生成對抗網(wǎng)絡(GAN)。最近幾周刷屏的Alpha Zero再一次展示了深度強化學習的強大威力,完全不依賴于人類經(jīng)驗,在圍棋項目上通過深度強化學習“左右互搏”所練就的棋力,已經(jīng)遠超過上一代秒殺一眾人類高手的AlghaGo Master。同樣的,生成對抗網(wǎng)絡及其各類變種也在不停地預告一個學習算法自我生成數(shù)據(jù)的時代的序幕。筆者所在的公司也正嘗試將深度強化學習和GAN相結(jié)合,以此用于跨模態(tài)的訓練數(shù)據(jù)的增廣。
新的數(shù)據(jù)集。數(shù)據(jù)集是深度學習算法的練兵場,因此數(shù)據(jù)集的演化是深度學習技術(shù)進步的縮影。以人臉識別為例,后LFW時代,MegaFace和Microsoft Celeb-1M數(shù)據(jù)集已接棒大規(guī)模人臉識別和數(shù)據(jù)標簽噪聲條件下的人臉識別。后ImageNet時代,Visual Genome正試圖建立一個包含了對象、屬性、關(guān)系描述、問答對在內(nèi)的視覺基因組。














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論