 電子發(fā)燒友App
電子發(fā)燒友App


1956年的夏天,一場在美國達特茅斯(Dartmouth)大學召開的學術會議,多年以后被認定為全球人工智能研究的起點。2016年的春天,一場AlphaGo與世界頂級圍棋高手李世石的人機世紀對戰(zhàn),把全球推上了人工智能浪潮的新高。
經歷了兩次起伏,人工智能現在進入了全球爆發(fā)的前夜。僅在中國就有上億人直接或間接地觀看了AlphaGo與李世石的比賽,而在2016年初,還有IBM在全球大舉推廣基于IBM Watson的認知計算,Watson的前身就是1997年打敗了國際象棋大師卡斯帕羅夫的“深藍”。
中國有句古話叫做60年一輪回。然而對于人工智能來說,往后的60年并不僅是輪回,而是新生。前60年的人工智能歷程,可以用“無窮動”來形容;后60年的人工智能發(fā)展,可以用“無窮大”來期許。
“無窮動”是一首意大利小提琴名曲,卡耐基·梅隆大學人工智能教授邢波用這個名字命名自己研究小組研發(fā)的新一代分布式機器學習系統(tǒng)。“無窮動”又是一種寓意,代表了在過去60年間甚至到更遠的古代,人們對于智能機器永無止境的想象以及去實踐的沖動。
人們對于智能機器的想像永無止境
亞里士多德曾說過,如果機器能干很多活,豈不能讓人類解放出來。《星球大戰(zhàn)》《黑客帝國》《人工智能》等科幻電影,激發(fā)了一代又一代學者和實業(yè)家,前伏后繼地投入到人工智能的研究中。AlphaGo算法的主要發(fā)明人,就是受了“深藍”的影響而加入AI的行列。
在前60年的發(fā)展中,人工智能研究也取得了階段性成果,特別是有監(jiān)督深度學習在自然語言理解、語音識別、圖像識別等人工智能基礎領域,都已經發(fā)展到了成熟階段。接下來,就是AlphaGo開創(chuàng)的無監(jiān)督深度學習的未來——擺脫人類“監(jiān)督”的增強學習。
實際上,隨著計算機的發(fā)明,人們一直在探討,這到底會導致什么樣的人工智能?一種預見是可以產生功能性的人工智能,這就是今天有監(jiān)督深度學習所廣泛取得的成果。還有一種觀點是人工智能可以模仿人的思維和感情活動,這就是無監(jiān)督深度學習將要開創(chuàng)的未來。
當智能機器可以自己張開眼睛看世界,通過自主探索世界來獲得智能的話,未來可能出現的變化就是“無窮大”了。從“無窮動”到“無窮大”,2016年注定是一個精彩之年。
上篇:前60年“無窮動”的韻律
人工智能頭60年的發(fā)展,就是在起起伏伏、寒冬與新潮、失望與希望之間的無窮動韻律,尋找著理論與實踐的最佳結合點。
從清華大學畢業(yè)后,邢波到Rutgers大學和伯克利攻讀研究生,之后到卡耐基·梅隆大學成為一名人工智能領域的教授。卡耐基·梅隆是全球重要的人工智能研究基地,很多原創(chuàng)性成果都出自這所大學。
卡耐基·梅隆大學人工智能教授邢波
邢波在卡耐基·梅隆大學成立了一個人工智能小組SAILING LAB,試圖在人工智能各個方面產生突破,理論研究包括概率圖模型的最大似然和最大間隔學習、非參數空間高維推理、非穩(wěn)態(tài)時間序列分析、非參數貝葉斯化推理等,應用研究包括計算生物學、群體遺傳學、基因組學、社交網絡和社交群體、互聯網級文本挖掘和自然語言處理、計算金融等。
2016年3月19日,在AlphaGo戰(zhàn)勝李世石后的第4天,邢波隨著《未來論壇》之理解未來系列講座走進了京東集團。邢波回顧了全球人工智能歷程,人工智能作為一個科學和工程領域,得益于20個世紀國際科學、計算機科學、信息論、控制論等很多科學發(fā)展的交匯點。人工智能的研究基于一個很基本的假設,即認為人的思維活動可以用機械方式替代。
60年前的全球人工智能大會
談到人工智能,就不能不提到鼻祖式人物:圖靈。1936年,英國數學家、邏輯學家阿蘭·麥席森·圖靈(1912~1954)提出了一種抽象的計算模型——圖靈機(TuringMachine),用紙帶式機器來模擬人們進行數學運算的過程,圖靈本人被視為計算機科學之父。
1959年,圖靈發(fā)表了一篇劃時代的論文《計算機器與智能》,文中提出了人工智能領域著名的圖靈測試——如果電腦能在5分鐘內回答由人類測試者提出的一系列問題,且其超過30%的回答讓測試者誤認為是人類所答,則電腦就通過測試并可下結論為機器具有智能。
卡耐基·梅隆大學
圖靈測試的概念極大影響人工智能對于功能的定義,在這個途徑上,卡耐基·梅隆兩位科學家A.Newell和H.Simon的“邏輯理論家”程序非常精妙地證明了羅素《數學原理》52道中的38道。Simon宣稱在10年之內,機器就可以達到和人類智能一樣的高度。
第一批人工智能探索者找到共同的語言后,于整整60年前的1956年,在美國達特茅斯大學開了一次會,希望確立人工智能作為一門科學的任務和完整路徑。與會者們也宣稱,人工智能的特征都可以被精準描述,精準描述后就可以用機器來模擬和實現。后來普遍認為,達特茅斯會議標志著人工智能的正式誕生。
人工智能第一次浪潮和寒冬
達特茅斯會議推動了全球第一次人工智能浪潮的出現,即為1956年到1974年。當時樂觀的氣氛彌漫著整個學界,在算法方面出現了很多世界級的發(fā)明,其中包括一種叫做增強學習的雛形(即貝爾曼公式),增強學習就是谷歌AlphaGo算法核心思想內容。現在常聽到的深度學習模型,其雛形叫做感知器,也是在那幾年間發(fā)明的。
60年前的達特茅斯大學
除了算法和方法論有了新的進展,在第一次浪潮中,科學家們還造出了聰明的機器。其中,有一臺叫做STUDENT(1964)的機器能證明應用題,還有一臺叫做ELIZA(1966)的機器可以實現簡單人機對話。于是,人工智能界認為按照這樣的發(fā)展速度,人工智能真的可以代替人類。
第一次人工智能冬天出現在1974年到1980年。這是怎么回事呢?因為人們發(fā)現邏輯證明器、感知器、增強學習等等只能做很簡單、非常專門且很窄的任務,稍微超出范圍就無法應對。這里面存在兩方面局限:一方面,人工智能所基于的數學模型和數學手段被發(fā)現有一定的缺陷;另一方面,有很多計算復雜度以指數程度增加,所以成為了不可能完成的計算任務。
先天缺陷導致人工智能在早期發(fā)展過程中遇到瓶頸,所以第一次冬天很快到來,對人工智能的資助相應也就被縮減或取消了。
現代PC“促成”第二次人工智能寒冬
進入20世紀80年代,卡耐基·梅隆大學為DEC公司制造出了專家系統(tǒng)(1980),這個專家系統(tǒng)可幫助DEC公司每年節(jié)約4000萬美元左右的費用,特別是在決策方面能提供有價值的內容。受此鼓勵,很多國家包括日本、美國都再次投入巨資開發(fā)所謂第5代計算機(1982),當時叫做人工智能計算機。
在80年代出現了人工智能數學模型方面的重大發(fā)明,其中包括著名的多層神經網絡(1986)和BP反向傳播算法(1986)等,也出現了能與人類下象棋的高度智能機器(1989)。此外,其它成果包括能自動識別信封上郵政編碼的機器,就是通過人工智能網絡來實現的,精度可達99%以上,已經超過普通人的水平。于是,大家又開始覺得人工智能還是有戲。
早期的專家系統(tǒng)Symbolics 3640
然而,1987年到1993年現代PC的出現,讓人工智能的寒冬再次降臨。當時蘋果、IBM開始推廣第一代臺式機,計算機開始走入個人家庭,其費用遠遠低于專家系統(tǒng)所使用的Symbolics和Lisp等機器。相比于現代PC,專家系統(tǒng)被認為古老陳舊而非常難以維護。于是,政府經費開始下降,寒冬又一次來臨。
那時,甚至學者們都不太好意思說是從事人工智能研究的。人們開始思考人工智能到底往何處走,到底要實現什么樣的人工智能。
現代AI的曙光:新工具、新理念和摩爾定律
如何在有限的資源下做有用的事情,這是人工智能一直以來的挑戰(zhàn)。一個現實的途徑就是像人類造飛機一樣,從生物界獲得啟發(fā)后,以工程化方法對功能進行簡化、部署簡單的數學模型以及開發(fā)強大的飛機引擎。
現代AI的曙光發(fā)生在這個階段,出現了新的數學工具、新的理論和摩爾定律。人工智能也在確定自己的方向,其中一個選擇就是要做實用性、功能性的人工智能,這導致了一個新的人工智能路徑。由于對于人工智能任務的明確和簡化,帶來了新的繁榮。
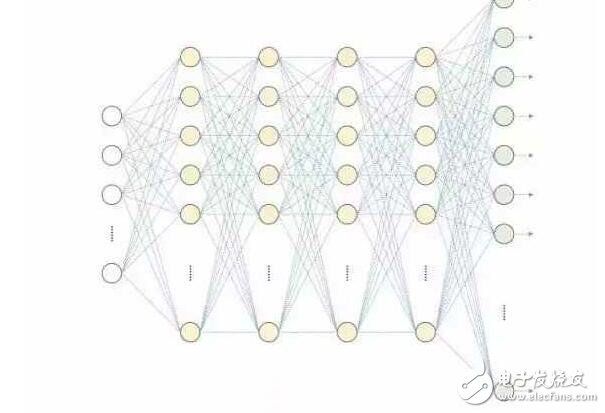
基于神經元網絡的深度學習算法示意圖
在新的數學工具方面,原來已經存在于數學或者其他學科的文獻中的數學模型,被重新發(fā)掘或者發(fā)明出來。當時比較顯著幾個成果包括最近獲得圖靈獎的圖模型以及圖優(yōu)化、深度學習網絡等,都是大約在15年前重新被提出來,重新開始研究。
在新的理論方面,由于數學模型對自然世界的簡化,有著非常明確的數理邏輯,使得理論分析和證明成為可能,可以分析出到底需要多少數據量和計算量來以得期望的結果,這對開發(fā)相應的計算系統(tǒng)非常有幫助。
在更重要的一方面,摩爾定律讓計算越來越強大,而強大計算機很少被用在人工智能早期研究中,因為早期的人工智能研究更多被定義為數學和算法研究。當更強大的計算能力被轉移到人工智能研究后,顯著提高了人工智能的研究效果。
由于這一系列的突破,人工智能又產生了一個新的繁榮期。最早的結果即為1997年IBM深藍戰(zhàn)勝國際象棋大師。在更加通用型的功能性方面,機器在數學競賽、識別圖片的比賽中,也可以達到或者超過人類的標準。
人工智能的繁榮也促進了機器人的進步,包括把人工智能原理用在機器狗的設計上。無論是人工智能狗還是無人車駕駛,都不是用編程方法寫出來,而是通過一套學習算法在模擬器中不斷的走路和開車,讓機器自己產生行為策略,這是人工智能和原先控制論最不同的地方。
2011年,Facebook的挑戰(zhàn)
在2011年的時候,邢波迎來做教授的第一次學術休假,美國教授大概每6年可以做一次休假。邢波選擇去了一家很年輕的公司做客座教授,這就是當時的Facebook。那個時候只有500人的Facebook在斯坦福大學的倉庫里搭起了自己的實驗室,當時Facebook提出希望連接上億用戶,也希望能夠運用人工智能投放有價值的廣告以增加公司收入。
Facebook當時的目標為在不久的將來把用戶從1億增長到10億,邢波的任務就是幫助Facebook實現這個愿景。作為Facebook的第一個客座教授,他的第一個任務要把用戶在社交網絡里連接起來,然后把這種連接投射到社交空間中,從而做社群檢測并把社群檢測用來實現用戶分組和特征化。
這個任務并不難,可以通過混合成員隨機區(qū)塊模型來實現,這是2011年最好的處理網絡數據的AI算法。但其中有一個問題,即計算的復雜度呈平方級現象,即用戶數每增加10倍就需要100倍的CPU和存儲,因此單機最多處理1萬人,這是當時最大問題。
邢波于是通過研究算法模型實現計算加速,包括在社交網絡抽取比“邊”更強大的特征叫做“三角形”,模型也從混合塊模型升級到混合三角模型。混合算法實現了顯著的革新,計算復雜度在不斷下降。當時的研究成果被用于全球電影明星網絡研究,大約在100萬人左右的網絡,可實時展示人們在模型驅動下不斷在社交空間找朋友并落入到不同的社交群。








 工商網監(jiān)
工商網監(jiān)
評論