 電子發燒友App
電子發燒友App


在過去的2016年,在計算機產業來說,相信沒有一個概念比人工智能更熱門。跨入2017年,專家們表示,人工智能生態圈的需求增長會更加迅猛。主要集中在為深度神經網絡找尋性能和效率更適合的“引擎”。
現在的深度學習系統依賴于軟件定義網絡和大數據學習產生的超大型運算能力,并靠此來實現目標。但很遺憾的是,這類型的運算配置是很難嵌入到那些運算能力、存儲大小、和帶寬都有限制的系統中(例如汽車、無人機和物聯網設備)。
這就給業界提出了一個新的挑戰,如何通過創新,把深度神經網絡的運算能力嵌入到終端設備中去。
Movidius公司的CEO Remi El-Ouazzane在幾個月前說過,將人工智能擺在網絡的邊緣將會是一個大趨勢。
Remi El-Ouazzane
在問到為什么人工智能會被“趕”到網絡邊緣的時候,CEA Architecture Fellow Marc Duranton給出了三個原因:分別是安全、隱私和經濟。他認為這三點是驅動業界在終端處理數據的重要因素。他指出,未來將會衍生更多“將數據轉化為信息”的需求。并且這些數據越早處理越好,他補充說。
CEA Architecture Fellow Marc Duranton
攝像一下,假如你的無人駕駛汽車是安全的,那么這些無人駕駛功能就不需要長時間依賴于聯盟處理;假設老人在家里跌倒了,那么這種情況當場就應該檢測到并判斷出來。考慮到隱私原因,這些是非常重要的,Duranton強調。
但這并不意味著收集家里十個攝像頭的所有圖片,并傳送給我,就稱作一個號的提醒。這也并不能降低“能耗、成本和數據大小”,Duranton補充說。
競賽正式開啟
從現在的情景看來,芯片供應商已經意識到推理機的增長需求。包括Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) 和Nvidia (Drive PX)在內的眾多半導體公司正在角逐低功耗、高性能的硬件加速器。幫助開發者更好的在嵌入式系統中執行“學習”。
從這些廠商的動作和SoC的發展方向看來,在后智能手機時代,推理機已經逐漸成為半導體廠商追逐的下一個目標市場。
在今年早些時候,Google的TPU橫空出世,昭示著業界意圖在機器學習芯片中推動創新的的意圖。在發布這個芯片的時候,搜索巨人表示,TPU每瓦性能較之傳統的FPGA和GPU將會高一個數量級。Google還表示,這個加速器還被應用到了今年年初風靡全球的AlphaGo系統里面。
但是從發布到現在,Google也從未披露過TPU的具體細節,更別說把這個產品對外出售。
很多SoC從業者從谷歌的TPU中得出了一個結論,他們認為,機器學習需要定制化的架構。但在他們針對機器學習做芯片設計的時候,他們又會對芯片的架構感到懷疑和好奇。同時他們想知道業界是否已經有了一種衡量不同形態下深度神經網絡(DNN)性能的工具。
工具已經到來
CEA聲稱,他們已經為幫推理機探索不同的硬件架構做好了準備,他們已經開發出了一個叫做N2D2,的軟件架構。他們夠幫助設計者探索和聲稱DNN架構。“我們開發這個工具的目的是為了幫助DNN選擇適合的硬件”,Duranton說。到2017年第一季度,這個N2D2會開源。Duranton承諾。
N2D2的特點在于不僅僅是在識別精度的基礎上對比硬件,它還能從處理時間、硬件成本和能源損耗的多個方面執行對比。因為針對不同的深度學習應用,其所需求的硬件配置參數都是不一樣的,所以說以上幾點才是最重要的,Duranton表示。
N2D2的工作原理
N2D2為現存的CPU、GPU和FPGA提供了一個參考標準。
邊緣計算的障礙
作為一個資深的研究組織,CEA已經在如何把DNN完美的推廣到邊緣計算領域進行了長時間的深入研究。在問到執行這種推進的障礙時,Duranton指出,由于功耗、尺寸和延遲的限制,這些“浮點”服務器方案不能應用。這就是最大的障礙。而其他的障礙包括了“大量的Mac、帶寬和芯片上存儲的尺寸”,Duranton補充說。
那就是說如何整合這種“浮點”方式,是最先應該被解決的問題。
Duranton認為,一些新的架構是在所難免的,隨之而來的一些類似“spike code”的新coding也是必然的。
經過CEA的研究指出,甚至二進制編碼都不是必須的。他們認為類似spike coding這類的時間編碼在邊緣能夠迸發出更強大的能量。
Spike coding之所以受歡迎,是因為它能明確展示神經系統內的數據解碼。往深里講,就是說這些基于事件的的編碼能夠兼容專用的傳感器和預處理。
這種和神經系統極度相似的編碼方式使得混合模擬和數字信號更容易實現,這也能夠幫助研究者打造低功耗的硬件加速器。
CEA也正在思考把神經網絡架構調整到邊緣計算的潛在可能。Duranton指出,現在人們正在推動使用‘SqueezeNet取替AlexNet。據報道,為達到同等精度,使用前者比后者少花50倍的參數。這類的簡單配置對于邊緣計算、拓撲學和降低Mac的數量來說,都是很重要的。
Duranton認為,從經典的DNN轉向嵌入式網絡是一種自發的行為。
P-Neuro,一個臨時的芯片
CEA的野心是去開發一個神經形態的電路。研究機構認為,在深度學習中,這樣的一個芯片是推動把數據提取放在傳感器端的一個有效補充。
但在達到這個目標之前,CEA相處了很多權宜之計。例如開發出D2N2這樣的工具,幫助芯片開發者開發出高TOPS的DNN解決方案。
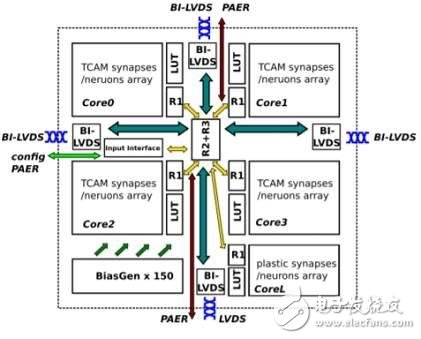
而對于那些想把DNN轉移到邊緣計算的玩家來說,他們也有相對應的硬件去實現。這就是CEA提供的低功耗可編程加速器——P-Neuro。現行的P-Neuro芯片是基于FPGA開發的。但Duranton表示,他們已經把這個FPAG變成了一個ASIC。
和嵌入式CPU對比的P-Neuro demo
在CEA的實驗室,Duranton他們已經在這個基于FPAG的P-Neuro搭建了一個面部識別的卷積神經網絡(CNN)。這個基于 P-Neuro的Demo和嵌入式CPU做了對比。(樹莓派、帶有三星Exynos處理器的安卓設備)。他們同樣都運行相同的CNN應用。他們都安排去從18000個圖片的數據庫中去執行“人臉特征提取”。
根據示例展示,P-Neuro的速度是6942張圖片每秒,而功耗也只是2776張圖每瓦。
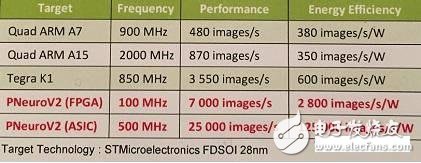
P-Neuro和GPU、CPU的對比
如圖所示,和Tegra K1相比,基于FPGA的P-Neuro在100Mhz工作頻率的時候,工作更快,且功耗更低。
P-Neuro是基于集群的SIMD架構打造,這個架構是以優化的分級存儲器體系和內部連接被大家熟知的。
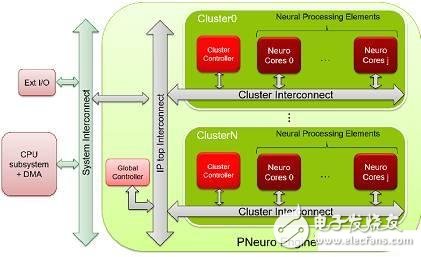
P-Neuro的框圖
對于CEA的研究者來說 ,P-Neuro 只是一個短期方案。現行的 P-Neuro 是在一個CMOS設備上打造的,使用的是二進制編碼。他們團隊正在打造一個全CMOS方案,并打算用spike coding。
為了充分利用先進設備的優勢,并且打破密度和功率的問題,他們團隊設立了一個更高的目標。他們考慮過把RRAM當做突觸元素,還考慮過FDSOI和納米線這樣的制程。
在一個“EU Horizon 2020”的計劃里面,他們希望做出一個神經形態架構的芯片,能夠支持最先進的機器學習。同時還是一個基于spike的學習機制。
這就是一個叫做NeuRAM3的項目。屆時,他們的芯片會擁有超低功耗、尺寸和高度可配置的神經架構。他們的目標是較之傳統方案,打造一個能將功耗降低50倍的產品。
Neuromorphic處理器

Neuromorphic處理器的基本參數
據介紹,這個方案包含了基于FD-SOI工藝的整體集成的3D技術,另外還用到的RRAM來做突觸元素。在NeuRAM3項目之下,這個新型的混合信號多核神經形態芯片設備較之IBM的TrueNorth,能明顯降低功耗。
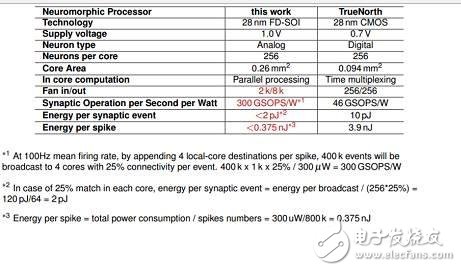
與IBM的TrueNorth對比
而NeuRAM3項目的參與者包括了IMEC, IBM Zurich, ST Microelectronics, CNR (The National Research Council in Italy), IMSE (El Instituto de Microelectrónica de Sevilla in Spain), 蘇黎世大學和德國的雅各布大學。
更多AI芯片角逐
其實AI芯片這個市場,已經吸引了很多玩家,無論是傳統的半導體業者,還是所謂的初創企業,都開始投奔這個下一個金礦。除了上面說的CEA這個。我們不妨來看一下市場上還有哪些AI芯片。
一、傳統廠商的跟進
(1)Nvidia
英偉達是GPU霸主,雖然錯過了移動時代,但他們似乎在AI時代,重獲榮光,從其過去一年內的股票走勢,就可以看到市場對他們的信心。我們來看一下他有什么計劃,在這個領域。
在今年四月,Nvidia發布了一個先進的機器學習芯片——Tesla P100 GPU。按照英偉達CEO黃仁勛所說,這個產品較之英偉達的前代產品,任務處理速度提高了12倍。這個耗費了20億美元開發的芯片上面集成了1500億個晶體管。
據介紹,全新的 NVIDIA Pascal? 架構讓 Tesla P100 能夠為 HPC 和超大規模工作負載提供超高的性能。憑借每秒超過 20 萬億次的 FP16 浮點運算性能,經過優化的 Pascal 為深度學習應用程序帶來了令人興奮的新可能。
而通過加入采用 HBM2 的 CoWoS(晶圓基底芯片)技術,Tesla P100 將計算和數據緊密集成在同一個程序包內,其內存性能是上一代解決方案的 3 倍以上。這讓數據密集型應用程序的問題解決時間實現了跨時代的飛躍。
再者,因為搭載了 NVIDIA NVLink? 技術, Tesla P100的快速節點可以顯著縮短為具備強擴展能力的應用程序提供解決方案的時間。采用 NVLink 技術的服務器節點可以 5 倍的 PCIe 帶寬互聯多達八個 Tesla P100。這種設計旨在幫助解決擁有極大計算需求的 HPC 和深度學習領域的全球超級重大挑戰。
(2)Intel
在今年十一月。Intel公司發布了一個叫做Nervana的AI處理器,他們宣稱會在明年年中測試這個原型。如果一切進展順利,Nervana芯片的最終形態會在2017年底面世。這個芯片是基于Intel早前購買的一個叫做Nervana的公司。按照Intel的人所說,這家公司是地球上第一家專門為AI打造芯片的公司。
Intel公司披露了一些關于這個芯片的一些細節,按照他們所說,這個項目代碼為“Lake Crest”,將會用到Nervana Engine 和Neon DNN相關軟件。。這款芯片可以加速各類神經網絡,例如谷歌TensorFlow框架。芯片由所謂的“處理集群”陣列構成,處理被稱作“活動點”的簡化數學運算。相對于浮點運算,這種方法所需的數據量更少,因此帶來了10倍的性能提升。
Lake Crest利用私有的數據連接創造了規模更大、速度更快的集群,其拓撲結構為圓環形或其他形式。這幫助用戶創造更大、更多元化的神經網絡模型。這一數據連接中包含12個100Gbps的雙向連接,其物理層基于28G的串并轉換。
這一2.5D芯片搭載了32GB的HBM2內存,內存帶寬為8Tbps。芯片中沒有緩存,完全通過軟件去管理片上存儲。
英特爾并未透露這款產品的未來路線圖,僅僅表示計劃發布一個名為Knights Crest的版本。該版本將集成未來的至強處理器和Nervana加速處理器。預計這將會支持Nervana的集群。不過英特爾沒有透露,這兩大類型的芯片將如何以及何時實現整合。
至于整合的版本將會有更強的性能,同時更易于編程。目前基于圖形處理芯片(GPU)的加速處理器使編程變得更復雜,因為開發者要維護單獨的GPU和CPU內存。
據透露,到2020年,英特爾將推出芯片,使神經網絡訓練的性能提高100倍。一名分析師表示,這一目標“極為激進”。毫無疑問,英特爾將迅速把這一架構轉向更先進的制造工藝,與已經采用14納米或16納米FinFET工藝的GPU展開競爭。
(3)IBM
百年巨人IBM,在很早以前就發布過wtson,現在他的人工智能機器早就投入了很多的研制和研發中去。而在去年,他也按捺不住,投入到類人腦芯片的研發,那就是TrueNorth。
TrueNorth是IBM參與DARPA的研究項目SyNapse的最新成果。SyNapse全稱是Systems of Neuromorphic Adaptive Plastic Scalable Electronics(自適應可塑可伸縮電子神經系統,而SyNapse正好是突觸的意思),其終極目標是開發出打破馮?諾依曼體系的硬件。
這種芯片把數字處理器當作神經元,把內存作為突觸,跟傳統馮諾依曼結構不一樣,它的內存、CPU和通信部件是完全集成在一起。因此信息的處理完全在本地進行,而且由于本地處理的數據量并不大,傳統計算機內存與CPU之間的瓶頸不復存在了。同時神經元之間可以方便快捷地相互溝通,只要接收到其他神經元發過來的脈沖(動作電位),這些神經元就會同時做動作。
2011年的時候,IBM首先推出了單核含256 個神經元,256×256 個突觸和 256 個軸突的芯片原型。當時的原型已經可以處理像玩Pong游戲這樣復雜的任務。不過相對來說還是比較簡單,從規模上來說,這樣的單核腦容量僅相當于蟲腦的水平。
不過,經過3年的努力,IBM終于在復雜性和使用性方面取得了突破。4096個內核,100萬個“神經元”、2.56億個“突觸”集成在直徑只有幾厘米的方寸(是2011年原型大小的1/16)之間,而且能耗只有不到70毫瓦,IBM的集成的確令人印象深刻。
這樣的芯片能夠做什么事情呢?IBM研究小組曾經利用做過DARPA 的NeoVision2 Tower數據集做過演示。它能夠實時識別出用30幀每秒的正常速度拍攝自斯坦福大學胡佛塔的十字路口視頻中的人、自行車、公交車、卡車等,準確率達到了80%。相比之下,一臺筆記本編程完成同樣的任務用時要慢100倍,能耗卻是IBM芯片的1萬倍。
跟傳統計算機用FLOPS(每秒浮點運算次數)衡量計算能力一樣,IBM使用SOP(每秒突觸運算數)來衡量這種計算機的能力和能效。其完成460億SOP所需的能耗僅為1瓦—正如文章開頭所述,這樣的能力一臺超級計算機,但是一塊小小的助聽器電池即可驅動。
通信效率極高,從而大大降低能耗這是這款芯片最大的賣點。TrueNorth的每一內核均有256個神經元,每一個神經有分別都跟內外部的256個神經元連接。
(4)Google
其實在Google上面,我是很糾結的,這究竟是個新興勢力,還是傳統公司。但考慮到Google已經那么多年了,我就把他放在傳統里面吧。雖然傳統也是很新的。而谷歌的人工智能相關芯片就是TPU。也就是Tensor Processing Unit。
TPU是專門為機器學習應用而設計的專用芯片。通過降低芯片的計算精度,減少實現每個計算操作所需的晶體管數量,從而能讓芯片的每秒運行的操作個數更高,這樣經過精細調優的機器學習模型就能在芯片上運行的更快,進而更快的讓用戶得到更智能的結果。Google將TPU加速器芯片嵌入電路板中,利用已有的硬盤PCI-E接口接入數據中心服務器中。
據Google 資深副總Urs Holzle 透露,當前Google TPU、GPU 并用,這種情況仍會維持一段時間,但也語帶玄機表示,GPU 過于通用,Google 偏好專為機器學習設計的芯片。GPU 可執行繪圖運算工作,用途多元;TPU 屬于ASIC,也就是專為特定用途設計的特殊規格邏輯IC,由于只執行單一工作,速度更快,但缺點是成本較高。至于CPU,Holzle 表示,TPU 不會取代CPU,研發TPU 只是為了處理尚未解決的問題。但是他也指出,希望芯片市場能有更多競爭。
如果AI算法改變了(從邏輯上講隨著時間的推移算法應該會改變),你是不是想要一款可以重新編程的芯片,以適應這些改變?如果情況是這樣的,另一種芯片適合,它就是FPGA(現場可編程門陣列)。FPGA可以編程,和ASIC不同。微軟用一些FPGA芯片來增強必應搜索引擎的AI功能。我們很自然會問:為什么不使用FPGA呢?








 工商網監
工商網監
評論