 電子發燒友App
電子發燒友App


深度學習作為新一代計算模式,近年來,其所取得的前所未有的突破掀起了人工智能新一輪發展熱潮。深度學習本質上是多層次的人工神經網絡算法,即模仿人腦的神經網絡,從最基本的單元上模擬了人類大腦的運行機制。由于人類大腦的運行機制與計算機有著鮮明的不同,深度學習與傳統計算模式有非常大的差別。
深度學習的人工神經網絡算法與傳統計算模式不同,它能夠從輸入的大量數據中自發的總結出規律,從而舉一反三,泛化至從未見過的案例中。因此,它不需要人為的提取所需解決問題的特征或者總結規律來進行編程。人工神經網絡算法實際上是通過大量樣本數據訓練建立了輸入數據和輸出數據之間的映射關系,其最直接的應用是在分類識別方面。例如訓練樣本的輸入是語音數據,訓練后的神經網絡實現的功能就是語音識別,如果訓練樣本輸入是人臉圖像數據,訓練后實現的功能就是人臉識別。
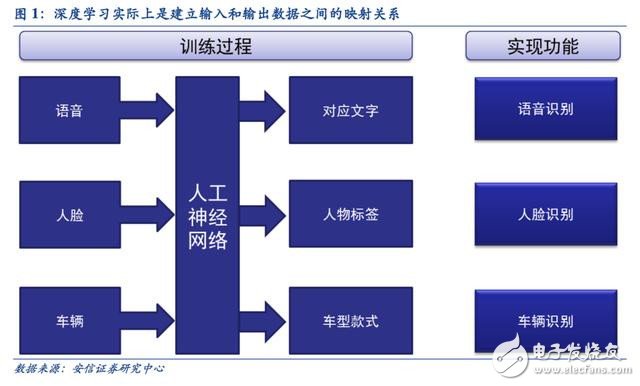
傳統計算機軟件是程序員根據所需要實現的功能原理編程,輸入至計算機運行即可,其計算過程主要體現在執行指令這個環節。而深度學習的人工神經網絡算法包含了兩個計算過程:
1、用已有的樣本數據去訓練人工神經網絡;
2、用訓練好的人工神經網絡去運行其它數據。 這種差別提升了對訓練數據量和并行計算能力的需求,降低了對人工理解功能原理的要求。
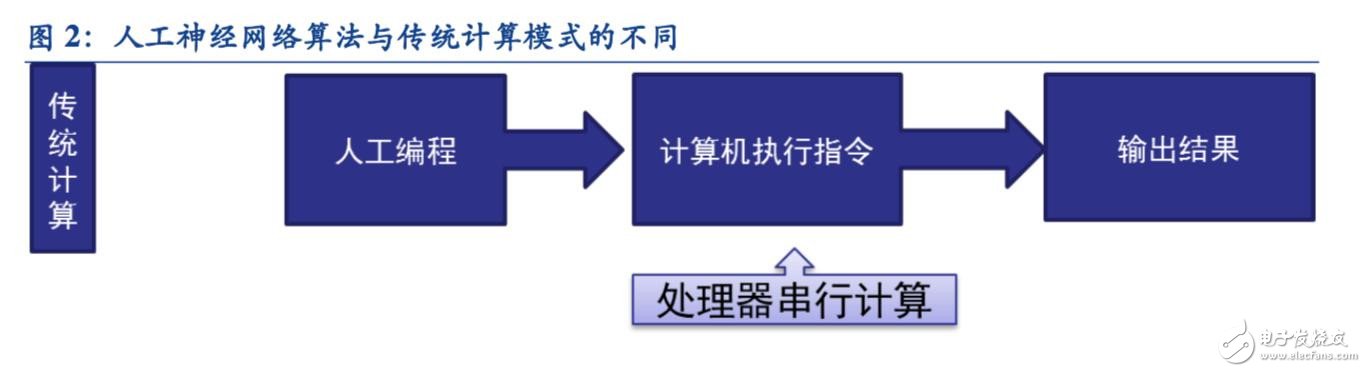

傳統計算架構無法支撐深度學習的海量數據并行運算
根據上文的分析我們可以看到,深度學習與傳統計算模式最大的區別就是不需要編程,但需要海量數據并行運算。
傳統處理器架構(包括x86 和ARM 等)往往需要數百甚至上千條指令才能完成一個神經元的處理,因此無法支撐深度學習的大規模并行計算需求。
為什么傳統計算架構無法支撐深度學習的大規模并行計算需求?因為傳統計算架構計算資源有限。
傳統計算架構一般由中央運算器(執行指令計算)、中央控制器(讓指令有序執行)、內存 (存儲指令)、輸入(輸入編程指令)和輸出(輸出結果)五個部分構成,其中中央運算器和中央控制器集成一塊芯片上構成了我們今天通常所講的 CPU。
我們從CPU 的內部結構可以看到:實質上僅單獨的 ALU 模塊(邏輯運算單元)是用來完成指令數據計算的,其他各個模塊的存在都是為了保證指令能夠一條接一條的有序執行。這種通用性結構對于傳統的編程計算模式非常適合,同時可以通過提升CPU 主頻(提升單位時間執行指令速度)來提升計算速度。
但對于并不需要太多的程序指令,卻需要海量數據運算的深度學習的計算需求,這種結構就顯得非常笨拙。尤其是在目前功耗限制下無法通過提升CPU 主頻來加快指令執行速度,這種矛盾愈發不可調和。因此,深度學習需要更適應此類算法的新的底層硬件來加速計算過程,也就是說,新的硬件對我們加速深度學習發揮著非常重要的作用。目前主要的方式是使用已有的GPU、FPGA 等通用芯片。
新計算平臺生態正在建立
GPU 因其并行計算優勢最先被引入深度學習
GPU作為應對圖像處理需求而出現的芯片,其海量數據并行運算的能力與深度學習需求不謀而合,因此,被最先引入深度學習。
2011 年吳恩達率先將其應用于谷歌大腦中便取得驚人效果,結果表明12 顆NVIDIAD 的GPU 可以提供相當于2000 顆CPU 的深度學習性能,之后紐約大學、多倫多大學以及瑞士人工智能實驗室的研究人員紛紛在GPU 上加速其深度神經網絡。
英偉達(Nvidia)是全球可編程圖形處理技術的領軍企業,公司的核心產品是GPU 處理器。
英偉達通過GPU 在深度學習中體現的出色性能迅速切入人工智能領域,又通過打造NVIDIA CUDA 平臺大大提升其編程效率、開放性和豐富性,建立了包含CNN、DNN、深度感知網絡、RNN、LSTM 以及強化學習網絡等算法的平臺。
根據英偉達公開宣布的消息來看,在短短兩年里,與NVIDIA 在深度學習方面展開合作的企業便激增了近35 倍,增至3,400 多家企業,涉及醫療、生命科學、能源、金融服務、汽車、制造業以及娛樂業等多個領域。
英偉達針對各類智能計算設備開發對應GPU,使得深度學習可以滲透各種類型的智能機器
IT 巨頭爭相開源人工智能平臺
深度學習系統一方面需要利用龐大的數據對其進行訓練,另一方面系統中存在上萬個參數需要調整。
IT 巨頭開源人工智能平臺,旨在調動更多優秀的工程師共同參與發展其人工智能系統。開放的開發平臺將帶來下游應用的蓬勃發展。最典型的例子就是谷歌開源安卓平臺,直接促成下游移動互聯網應用的空前繁榮。
開源人工智能平臺可以增強云計算業務的吸引力和競爭力
以谷歌為例,用戶使用開源的TensorFlow 平臺訓練和導出自己所需要的人工智能模型,然后就可直接把模型導入TensorFlow Serving 對外提供預測類云服務,相當于TensorFlow 系列把整個用深度學習模型對外提供服務的方案全包了。
實質上是將開源深度學習工具用戶直接變為其云計算服務的用戶,包括阿里、亞馬遜在內的云計算服務商都將機器學習平臺嵌入其中作為增強其競爭實力和吸引更多用戶的方式。
2015 年以來,全球人工智能頂尖巨頭均爭向開源自身最核心的人工智能平臺,各種開源深度學習框架層出不窮,其中包括:Caffe、CNTK、MXNet、Neon、TensorFlow、Theano 和 Torch等。
人工智能催生新一代專用計算芯片
回顧計算機行業發展史,新的計算模式往往催生新的專用計算芯片。人工智能時代新計算的強大需求,正在催生出新的專用計算芯片。
GPU 及其局限性
目前以深度學習為代表的人工智能新計算需求,主要采用GPU、FPGA 等已有適合并行計算的通用芯片來實現加速。
在產業應用沒有大規模興起之時,使用這類已有的通用芯片可以避免專門研發定制芯片(ASIC)的高投入和高風險,但是,由于這類通用芯片設計初衷并非專門針對深度學習,因而,天然存在性能、功耗等方面的瓶頸。隨著人工智能應用規模的擴大,這類問題將日益突出。
GPU 作為圖像處理器,設計初衷是為了應對圖像處理中需要大規模并行計算。因此,其在應用于深度學習算法時,有三個方面的局限性:
第一, 應用過程中無法充分發揮并行計算優勢。深度學習包含訓練和應用兩個計算環節,GPU 在深度學習算法訓練上非常高效,但在應用時一次性只能對于一張輸入圖像進行處理, 并行度的優勢不能完全發揮。
第二, 硬件結構固定不具備可編程性。深度學習算法還未完全穩定,若深度學習算法發生大的變化,GPU 無法像FPGA 一樣可以靈活的配置硬件結構。
第三, 運行深度學習算法能效遠低于FPGA。學術界和產業界研究已經證明,運行深度學習算法中實現同樣的性能,GPU 所需功耗遠大于FPGA,例如國內初創企業深鑒科技基于FPGA 平臺的人工智能芯片在同樣開發周期內相對GPU 能效有一個數量級的提升。
FPGA 及其局限性
FPGA,即現場可編輯門陣列,是一種新型的可編程邏輯器件。其設計初衷是為了實現半定制芯片的功能,即硬件結構可根據需要實時配置靈活改變。
研究報告顯示,目前的FPGA市場由Xilinx 和Altera 主導,兩者共同占有85%的市場份額,其中Altera 在2015 年被intel以167 億美元收購(此交易為 intel 有史以來涉及金額最大的一次收購案例),另一家Xilinx則選擇與IBM 進行深度合作,背后都體現了 FPGA 在人工智能時代的重要地位。
盡管 FPGA 倍受看好,甚至新一代百度大腦也是基于FPGA 平臺研發,但其畢竟不是專門為了適用深度學習算法而研發,實際仍然存在不少局限:
第一,基本單元的計算能力有限。為了實現可重構特性,FPGA 內部有大量極細粒度的基本單元,但是每個單元的計算能力(主要依靠LUT 查找表)都遠遠低于CPU 和GPU 中的ALU模塊。
第二,速度和功耗相對專用定制芯片(ASIC)仍然存在不小差距。
第三,FPGA 價格較為昂貴,在規模放量的情況下單塊FPGA 的成本要遠高于專用定制芯片。
人工智能定制芯片是大趨勢,從發展趨勢上看,人工智能定制芯片將是計算芯片發展的大方向:
第一, 定制芯片的性能提升非常明顯。
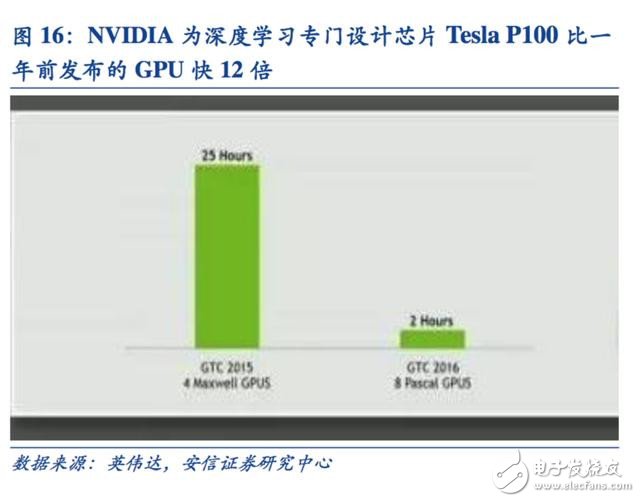
例如 NVIDIA 首款專門為深度學習從零開始設計的芯片Tesla P100 數據處理速度是其2014 年推出GPU 系列的12 倍。
谷歌為機器學習定制的芯片TPU 將硬件性能提升至相當于按照摩爾定律發展7 年后的水平。需要指出的是這種性能的飛速提升對于人工智能的發展意義重大。
中國科學院計算所研究員、 寒武紀深度學習處理器芯片創始人陳云霽博士在《中國計算機學會通訊》上撰文指出:通過設計專門的指令集、微結構、人工神經元電路、存儲層次,有可能在3~5 年內將深度學習模型的類腦計算機的智能處理效率提升萬倍(相對于谷歌大腦)。
提升萬倍的意義在于,可以把谷歌大腦這樣的深度學習超級計算機放到手機中,幫助我們本地、實時完成各種圖像、語音和文本的理解和識別;更重要的是,具備實時訓練的能力之后,就可以不間斷地通過觀察人的行為不斷提升其能力,成為我們生活中離不開的智能助理。

第二, 下游需求量足夠攤薄定制芯片投入的成本。
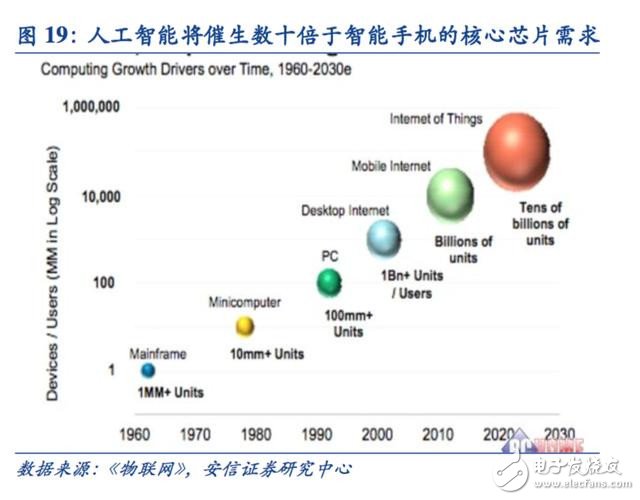
人工智能的市場空間將不僅僅局限于計算機、手機等傳統計算平臺,從無人駕駛汽車、無人機再到智能家居的各類家電,至少數十倍于智能手機體量的設備需要引入感知交互能力。
而出于對實時性的要求以及訓練數據隱私等考慮,這些能力不可能完全依賴云端,必須要有本地的軟硬件基礎平臺支撐。僅從這一角度考慮,人工智能定制芯片需求量就將數十倍于智能手機。

第三, 通過算法切入人工智能領域的公司希望通過芯片化、產品化來盈利。
目前通過算法切入人工智能領域的公司很多,包括采用語音識別、圖像識別、ADAS(高級駕駛輔助系統) 等算法的公司。由于它們提供的都是高頻次、基礎性的功能服務,因此,僅僅通過算法來實 現商業盈利往往會遇到瓶頸。通過將各自人工智能核心算法芯片化、產品化,則不但提升了原有性能,同時也有望為商業盈利鋪平道路。
目前包括 Mobileye、商湯科技、地平線機器人等著名人工智能公司都在進行核心算法芯片化的工作。

目前為人工智能專門定制芯片的大潮已經開始逐步顯露,英偉達在今年宣布研發投入超過20億美元用于深度學習專用芯片,而谷歌為深度學習定制的TPU 芯片甚至已經秘密運行一年,該芯片直接支撐了震驚全球的人機圍棋大戰。我國的寒武紀芯片也計劃于今年開始產業化。人機圍棋大戰中的谷歌“阿爾法狗”(AlphaGo) 使用了約 170 個圖形處理器(GPU)和 1200 個中央處理器(CPU),這些設備需要占用一個機房,還要配備大功率的空調,以及多名專家進行系統維護。AlphaGo 目前用的芯片數量,將來如果換成中國人研制的“寒武紀”架構的芯片,估計一個小盒子就全裝下了。這意味著“阿爾法狗”將可以跑得更快些。
人工智能專用芯片的涌現表明從芯片層面開啟的新一輪計算模式變革拉開帷幕,是人工智能產業正式走向成熟的拐點。
人工智能芯片發展路線圖
設計芯片的目的是從加速深度學習算法到希望從底層結構模擬人腦來更好實現智能。
目前人工智能芯片涵蓋了基于FPGA 的半定制、針對深度學習算法的全定制、類腦計算芯片三個階段。
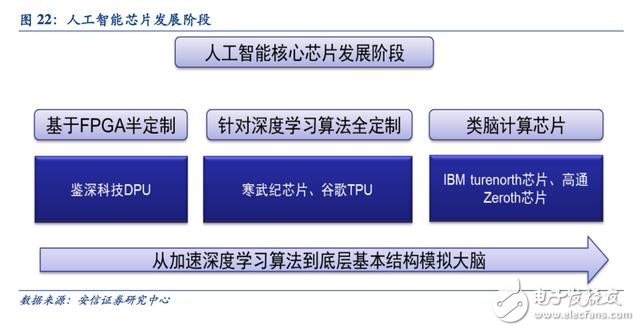
基于FPGA 的半定制人工智能芯片在芯片需求還未成規模、深度學習算法暫未穩定需要不斷迭代改進的情況下,利用具備可重構特性的FPGA 芯片來實現半定制的人工智能芯片是最佳選擇。這類芯片中的杰出代表是國內初創公司深鑒科技,該公司設計了“深度學習處理單元”(Deep Processing Unit,DPU)的芯片,希望以ASIC 級別的功耗來達到優于GPU 的性能,其第一批產品就是基于FPGA 平臺。這種半定制芯片雖然依托于FPGA 平臺,但是利用抽象出了指令集與編譯器,可以快速開發、快速迭代,與專用的FPGA 加速器產品相比,也具有非常明顯的優勢。
針對深度學習算法的全定制人工智能芯片
這類芯片是完全采用ASIC 設計方法全定制,性能、功耗和面積等指標面向深度學習算法都做到了最優。谷歌的TPU 芯片、我國中科院計算所的寒武紀深度學習處理器芯片就是這類芯片的典型代表。
以寒武紀處理器為例,目前寒武紀系列已包含三種原型處理器結構:
寒武紀1 號(英文名DianNao,面向神經網絡的原型處理器結構)、寒武紀2 號(英文名 DaDianNao,面向大規模神經網絡)、寒武紀3 號(英文名 PuDianNao,面向多種深度學習算法)。
其中寒武紀2 號在28nm 工藝下主頻為606MHz,面積67.7 mm2,功耗約16W。其單芯片性能超過了主流GPU 的21 倍,而能耗僅為主流GPU 的1/330。64 芯片組成的高效能計算系統較主流GPU 的性能提升甚至可達450 倍,但總能耗僅為1/150。
第三階段:類腦計算芯片這類芯片的設計目的不再局限于僅僅加速深度學習算法,而是在芯片基本結構甚至器件層面上希望能夠開發出新的類腦計算機體系結構,比如會采用憶阻器和 ReRAM 等新器件來提高存儲密度。
這類芯片的研究離成為市場上可以大規模廣泛使用的成熟技術還有很大的差距,甚至有很大的風險,但是長期來看類腦芯片有可能會帶來計算體系的革命。這類芯片的典型代表是IBM 的TrueNorth 芯片。
TrueNorth 處理器由54 億個連結晶體管組成,構成了包含100 萬個數字神經元陣列,這些神經元又可通過2.56 億個電突觸彼此通信。該芯片采用跟傳統馮諾依曼不一樣的結構,將內存、處理器單元和通信部件完全集成在一起,因此信息的處理完全在本地進行,而且由于本地處理的數據量并不大,傳統計算機內存與CPU之間的瓶頸不復存在。同時神經元之間可以方便快捷地相互溝通,只要接收到其他神經元發過來的脈沖(動作電位),這些神經元就會同時做動作實現事件驅動的異步電路特性。由于不需要同步時鐘該芯片功耗極低:16 個TrueNorth 芯片的功耗僅為2.5 瓦,僅與平板電腦相當。
類腦計算芯片市場空間巨大
據預測,包含消費終端的類腦計算芯片市場將在2022 年以前達到千億美元的規模,其中消費終端是最大市場,占整體98.17%,其它需求包括工業檢測、航空、軍事與國防等領域。
核心芯片是人工智能時代的戰略制高點
核心芯片將決定一個新的計算時代的基礎架構和未來生態,因此,谷歌、微軟、IBM、Facebook等全球IT 巨頭都投巨資加速人工智能核心芯片的研發,旨在搶占新計算時代的戰略制高點,掌控人工智能時代主導權。
回顧在PC 和移動互聯網時代分別處于霸主地位的X86 架構和ARM 架構的發展歷程,可以看到:從源頭上掌控核心芯片架構取得先發優勢,對于取得一個新計算時代主導權有多么重要。
英特爾X86 處理器芯片壟斷PC 時代
計算機指令集架構可以分為復雜指令集(CISC)和精簡指令集(RISC)兩種。PC 時代處于壟斷地位的X86 架構就是屬于復雜指令集。復雜指令集在處理復雜指令上具備先天優勢,但同時也存在設計復雜、難以流水作業、高功耗的問題。實質上精簡指令集正是上世紀80 年代 針對復雜指令集缺點設計出來的,學術界當時一致認為精簡指令集更為領先。
但是PC 時代的芯片霸主英特爾早在精簡指令集發明之前的處理器芯片8086 就采用了復雜指令集的X86架構,在后續的80286、80386 等系列處理器芯片繼續采用兼容的X86 架構,同時加強每一代處理器對上層軟件的兼容,并與微軟建立了 Wintel 聯盟牢牢支撐整個PC 的應用生態。
習慣了使用英特爾X86 處理器的軟件公司不再愿意使用其他架構的處理器,即使它們的性能更好。其結果就是:上世紀90 年代幾乎只有英特爾一家公司堅持開發X86 架構的處理器,卻戰勝了MIPS、PowerPC、IBM、HP、DEC 等及其他各家精簡指令集的處理器,X86 架構牢牢掌控了PC 時代的主導權。
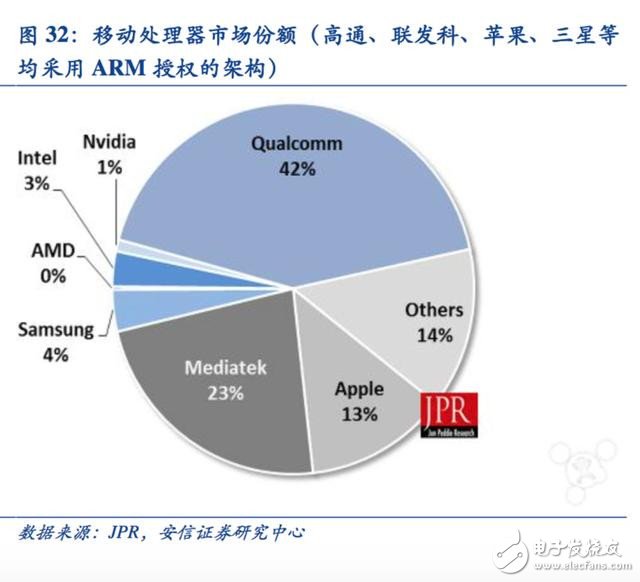
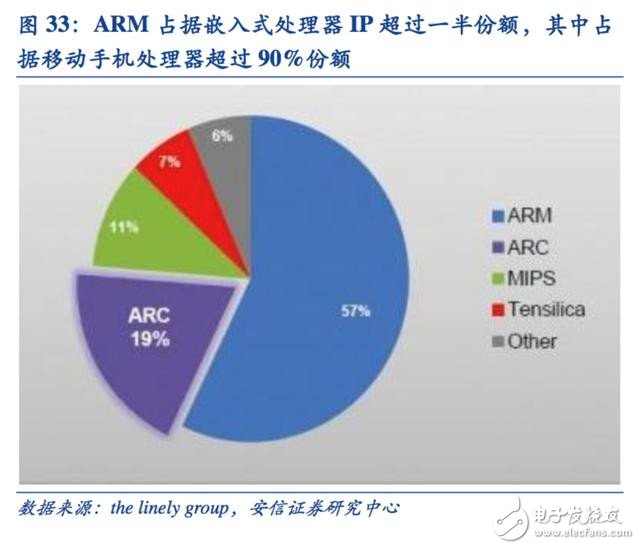
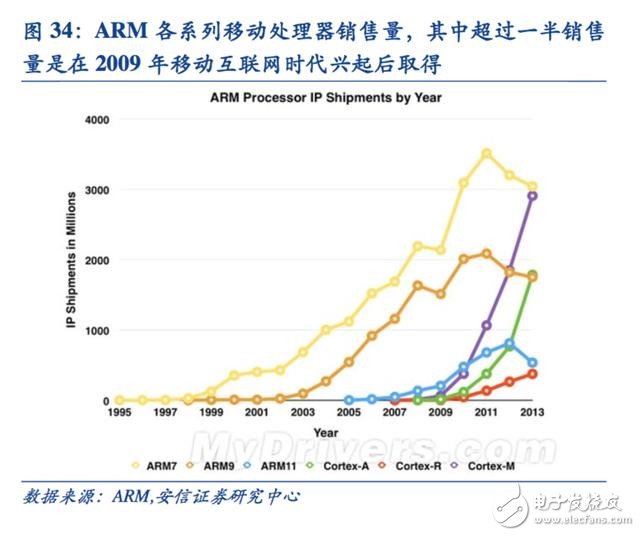
ARM 成為移動互聯網時代的霸主
移動互聯網時代,英特爾并沒有延續其在PC 時代的優勢,而是一家此前名不見經傳的英國芯片設計公司ARM 成為壟斷移動處理器芯片的新霸主。
ARM 的成功有三方面的原因:
第一, ARM 在20 世紀90 年代初為蘋果公司設計CPU 起家(ARM 是由 Acorn、蘋果和VLSI Technology 聯合出資成立),因而其在智能手機革命開啟之初就進入了這個快速成長的市場,與蘋果的關系奠定了其架構在移動處理器市場先發優勢。
第二, ARM 處理器隸屬于精簡指令架構,相對于復雜指令架構的X86 處理器天然具備低功耗優勢,而這在移動市場極為重要。
第三, ARM 創造了只授權核心設計IP 不生產芯片的商業模式,迅速拉攏各大芯片巨頭建立自己的生態聯盟。
ARM 的成功給我們的啟示是:
一、新的計算時代來臨之時往往是新興企業彎道超車的絕佳機遇,再強勢的傳統巨頭也難免面臨重新洗牌的局面。
二、把握核心芯片架構的先發優勢,在此基礎上迅速建立生態體系是在一個新計算變革時代來臨時的成功關鍵。
三、目前使用的GPU、FPGA 均非人工智能定制芯片,天然存在局限性,人工智能專用芯片對于巨頭和初創企業都同一起跑線的藍海。
我們正處在從信息時代邁向智能時代的重要拐點,人工智能將推動新一輪計算革命,而芯片行業作為產業最上游,是人工智能時代的開路先鋒:
一方面具備行業先導指標的意義,另一方面也是在人工智能產業發展初期率先啟動、彈性最大的行業。信息時代產生了英特爾這樣的千億市值的芯片巨頭,擁有更大應用市場的人工智能時代必將孕育出更多的“英特爾”。







 工商網監
工商網監
評論