 電子發燒友App
電子發燒友App


摘要:鍵值(KV)緩存已成為加快大語言模型(LLM)推理生成速度的事實。然而,隨著序列長度的增加,緩存需求也在不斷增長,這使得 LLM 推理變成了一個內存約束問題,極大地限制了系統的吞吐量。現有的方法依賴于放棄不重要的標記或均勻量化所有條目。然而,這些方法在表示壓縮矩陣時往往會產生較高的近似誤差。自回歸解碼過程進一步加劇了每一步的誤差,導致模型生成出現嚴重偏差,性能下降。為了應對這一挑戰,我們提出了一種高效的 KV 緩存壓縮框架--GEAR,它能實現近乎無損的高比率壓縮。GEAR 首先對大部分大小相似的條目進行超低精度量化。然后,它采用低秩矩陣來近似量化誤差,并采用稀疏矩陣來彌補離群條目的個別誤差。通過巧妙地整合三種技術,GEAR 能夠充分發揮它們的協同潛力。我們的實驗證明,與其他技術相比,GEAR 實現了近乎無損的 4 位 KV 高速緩存壓縮,吞吐量提高了 2.38 倍,同時內存峰值大小減少了 2.29 倍。
Q1: 這篇論文試圖解決什么問題?
A:這篇論文提出了一個名為GEAR(GEnerative Inference with Approximation Error Reduction)的高效鍵值(KV)緩存壓縮框架,旨在解決大型語言模型(LLM)推理過程中的內存瓶頸問題。隨著模型大小和序列長度的增加,KV緩存的內存消耗迅速增長,這限制了系統吞吐量。現有的方法依賴于丟棄不重要的標記或對所有條目進行統一量化,但這些方法通常會引入較高的近似誤差,導致壓縮矩陣的表示不準確。特別是在自回歸解碼過程中,每一步的誤差累積可能導致模型生成性能的關鍵偏差。
GEAR框架通過結合三種互補的技術來解決這一挑戰:首先對大多數相似幅度的條目應用超低精度量化;然后使用低秩矩陣來近似量化誤差;最后,引入稀疏矩陣來糾正異常值條目的個別誤差。通過巧妙地整合這三種技術,GEAR能夠在保持近乎無損的壓縮比的同時,顯著提高系統吞吐量和減少峰值內存使用。實驗結果表明,與現有替代方案相比,GEAR在保持近乎無損性能的同時,實現了高達2.38倍的吞吐量提升和高達2.29倍的峰值內存減少。
Q2: 有哪些相關研究?
A:在這篇論文中,作者提到了以下幾類相關研究:
LLM權重壓縮:這類研究關注于如何有效地壓縮大型語言模型的權重,以減少內存占用和數據傳輸成本。例如,GPTQ(Frantar et al., 2023) 和SqueezeLLM(Kim et al., 2023) 通過量化方法顯著減少了模型權重的內存占用。
LLM激活和KV緩存壓縮:與權重壓縮相比,激活和KV緩存的壓縮更具挑戰性,因為它們與模型輸入更相關且更敏感。SmoothQuant (Xiao et al., 2023) 和 Atom (Zhao et al., 2023) 等研究通過調整量化方案來減少異常值誤差,實現了在簡單生成任務上的近乎無損壓縮。
KV緩存剪枝:基于注意力分數分析,一些研究提出了通過丟棄KV緩存中的標記來減少緩存大小的方法。例如,H2O (Zhang et al., 2023) 和 FastGen (Ge et al., 2023) 提出了基于注意力分數的KV剪枝方法。
KV緩存量化:除了剪枝方法,還有研究探索了KV緩存的量化方法。例如,SparQ (Ribar et al., 2023) 通過結合剪枝和量化來減少KV緩存的大小。
模型權重和激活的低精度量化:一些研究專注于將模型權重和激活轉換為低精度表示,以提高推理效率。例如,Q8bert (Zafrir et al., 2019) 和 ZeroQuant (Yao et al., 2022) 提出了針對BERT等模型的8位和4位量化方案。
這些相關研究為GEAR框架提供了背景和動機,同時也展示了在大型語言模型壓縮領域內的不同研究方向和技術進展。GEAR框架在這些研究的基礎上,通過創新的方法實現了KV緩存的高效壓縮,以提高LLM推理的性能和效率。
Q3: 論文如何解決這個問題?

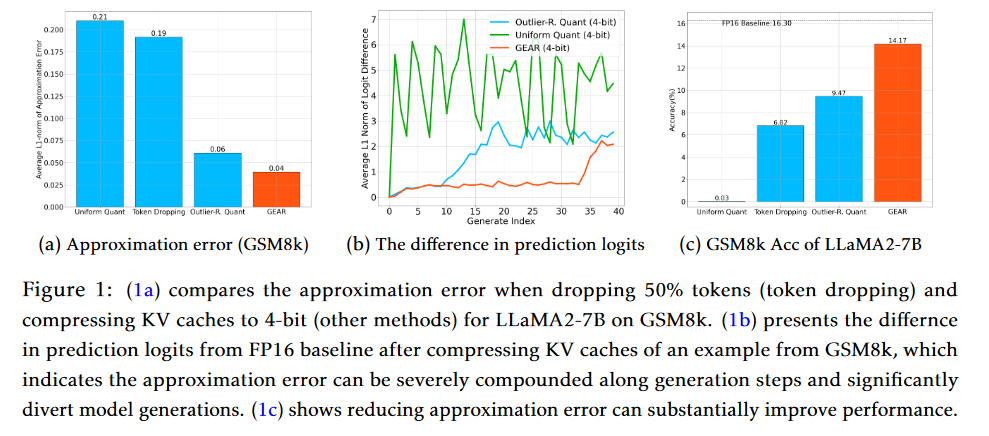
A:論文提出了GEAR框架來解決大型語言模型(LLM)推理中的KV緩存壓縮問題。GEAR框架的核心思想是通過結合三種互補的技術來最小化壓縮過程中的近似誤差,從而實現高壓縮比和近乎無損的性能。以下是GEAR框架的主要組成部分和解決方案:
量化(Quantization):GEAR首先對KV緩存中的大多數條目應用超低精度量化,例如4位量化。這種量化方法利用了KV緩存中條目的相似性,將它們壓縮到極低的精度。
低秩近似(Low-Rank Approximation):為了更有效地減少量化誤差,GEAR使用低秩矩陣來近似量化殘差。這是通過奇異值分解(SVD)實現的,它能夠捕捉到KV緩存中的共同信息,這些信息在不同的token之間是共享的。
稀疏矩陣(Sparse Matrix):GEAR引入稀疏矩陣來處理那些具有較大幅度的異常值條目。這些條目在量化過程中可能會產生較大的誤差,通過將它們存儲在稀疏矩陣中,可以單獨處理這些異常值,從而減少整體的近似誤差。
流式策略(Streaming Strategy):為了提高推理速度,GEAR采用了流式策略。在生成長序列時,GEAR會將新生成的token的KV向量存儲到一個小緩沖區中。當緩沖區達到容量時,GEAR會進行KV緩存壓縮。這種方法可以在幾乎不增加額外內存消耗的情況下顯著提高推理速度。
通過這些技術的集成,GEAR能夠在保持近乎無損的性能的同時,實現高達2.38倍的吞吐量提升和高達2.29倍的峰值內存減少。這使得GEAR在處理復雜生成任務時,如包含推理的長序列生成,能夠顯著提高系統性能。
Q4: 論文做了哪些實驗?
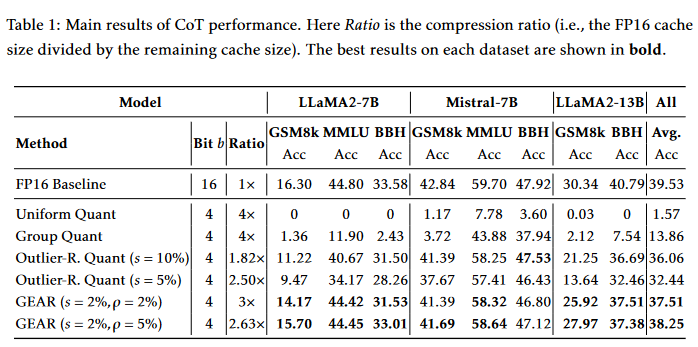
A:論文中進行了一系列實驗來驗證GEAR框架的有效性和性能。以下是主要的實驗內容:
CoT(Chain-of-Thought)推理性能:使用LLaMA2-7B、LLaMA2-13B和Mistral-7B模型在多個具有挑戰性的生成任務上評估GEAR的性能,包括數學推理(GSM8k)、多任務語言理解(MMLU)和符號推理(BigBench Hard)。實驗結果表明,GEAR在保持高壓縮比的同時,能夠實現與FP16基線相近的準確性。
Zero-shot生成性能:在GSM8k和MMLU數據集上,對LLaMA2-7B、LLaMA2-7B-chat和Mistral-7B模型進行zero-shot評估。實驗結果顯示,GEAR在不同壓縮比下均優于或至少與基線方法相當。
系統性能分析:分析了GEAR在實際推理系統中的內存占用和系統吞吐量。實驗結果表明,GEAR能夠顯著降低峰值內存使用,允許更大的批量大小或更長的生成長度。此外,GEAR在有限GPU內存的系統中,通過減少內存帶寬使用,提高了系統吞吐量。
不同壓縮比的性能:展示了在不同壓縮比下,GEAR在GSM8k和MMLU數據集上的性能。結果表明,即使在高壓縮比下,GEAR仍然能夠保持近乎無損的性能。
與token dropping方法的比較:評估了H2O方法在GSM8k數據集上的性能,結果表明H2O在保持性能的同時無法實現高壓縮比。
在微調模型上的應用:在GSM8k數據集上,對微調后的LLaMA2-7B模型應用GEAR,并評估其性能。結果表明,GEAR在微調模型上仍然優于基線方法。
超參數敏感性分析:研究了GEAR對稀疏比率(s)和低秩比率(ρ)的敏感性。實驗結果表明,GEAR不需要大量的稀疏或低秩成分,小比例的稀疏/低秩矩陣就足以實現近乎無損的準確性。
GEAR與不同KV量化方案的結合:展示了GEAR在不同KV量化方案(如均勻量化和分組量化)上的應用效果。實驗結果表明,GEAR能夠顯著提高這些量化方案的性能。
權重量化模型上的GEAR應用:在模型權重已經量化為8位的情況下,評估GEAR在KV緩存上的性能。結果表明,GEAR在權重量化模型上也能顯著提高性能。
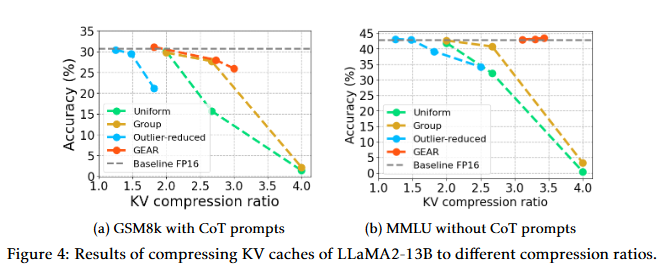
這些實驗全面地展示了GEAR在不同場景下的性能,證明了其在壓縮KV緩存時的有效性和實用性。
Q5: 有什么可以進一步探索的點?
A:盡管GEAR框架在LLM推理中的KV緩存壓縮方面取得了顯著的成果,但仍有一些潛在的研究方向可以進一步探索:
更精細的量化策略:研究更精細的量化策略,例如基于內容的量化,其中量化參數可以根據數據的統計特性動態調整,以進一步提高壓縮效率和保持性能。
多任務和遷移學習:探索GEAR在多任務學習和遷移學習場景中的應用,特別是在不同領域和語言模型之間的遷移。
實時壓縮和推理:研究如何將GEAR集成到實時推理系統中,以支持低延遲和高吞吐量的在線服務。
硬件加速:研究如何利用特定硬件(如FPGA、ASIC或定制加速器)來加速GEAR的壓縮和解壓縮過程,以進一步提高推理速度。
模型架構的適應性:研究GEAR在不同模型架構(如Transformer、CNN等)中的適應性和性能,以及如何針對特定架構優化壓縮策略。
長期依賴和復雜推理任務:深入研究GEAR在處理具有長期依賴和復雜推理任務的模型中的性能,例如在科學問題解答、法律案例分析等場景。
壓縮感知和稀疏表示:探索壓縮感知技術在KV緩存壓縮中的應用,以及如何結合稀疏表示來進一步減少內存占用。
跨模型和跨數據集的泛化能力:評估GEAR在不同模型大小、不同數據集和不同任務類型中的泛化能力,以及如何提高其泛化性。
安全性和隱私保護:研究在壓縮過程中如何保護模型和數據的安全性和隱私,特別是在云計算和邊緣計算環境中。
開源實現和社區貢獻:將GEAR框架開源,并鼓勵社區貢獻,以促進技術的迭代發展和廣泛應用。
這些研究方向可以幫助GEAR框架在實際應用中更加健壯和高效,同時也為大型語言模型的壓縮和推理領域帶來新的突破。
Q6: 總結一下論文的主要內容?
A:這篇論文介紹了GEAR(GEnerative Inference with Approximation Error Reduction),這是一個針對大型語言模型(LLM)推理過程中的鍵值(KV)緩存壓縮問題的高效解決方案。以下是論文的主要內容總結:
問題背景:隨著LLM模型規模的增長,KV緩存的內存需求迅速增加,成為限制系統吞吐量的主要瓶頸。現有的緩存壓縮方法,如丟棄不重要的標記或統一量化,往往會引入顯著的近似誤差,影響模型的生成性能。
GEAR框架:為了解決這一問題,作者提出了GEAR框架,它結合了三種技術:量化、低秩近似和稀疏矩陣。這種方法旨在最小化壓縮過程中的近似誤差,實現高壓縮比和近乎無損的性能。
量化策略:GEAR首先對大多數相似幅度的條目應用超低精度量化,然后使用低秩矩陣來近似量化誤差,并引入稀疏矩陣來處理異常值條目。
流式策略:為了提高推理速度,GEAR采用了流式策略,通過在小緩沖區中存儲新生成的token的KV向量,并在緩沖區滿時進行壓縮。
實驗結果:在多個復雜生成任務上,GEAR在保持高壓縮比的同時,實現了顯著的性能提升。與現有方法相比,GEAR在吞吐量和峰值內存使用上都有顯著改善。
系統性能分析:GEAR在實際推理系統中能夠顯著降低峰值內存使用,允許更大的批量大小或更長的生成長度。在有限GPU內存的系統中,GEAR還能提高系統吞吐量。
相關研究:論文討論了與GEAR相關的研究領域,包括LLM權重壓縮、KV緩存壓縮、KV剪枝和量化等。
未來工作:論文提出了一些潛在的研究方向,如更精細的量化策略、多任務和遷移學習、硬件加速等,以進一步優化GEAR框架。
總的來說,GEAR框架為LLM的高效推理提供了一種新的內存壓縮策略,通過減少KV緩存的內存占用,提高了模型的推理速度和系統吞吐量,同時保持了生成性能。
審核編輯:黃飛
?










 工商網監
工商網監
評論