 電子發(fā)燒友App
電子發(fā)燒友App


本文分為兩個部分,第一部分為綜述(領(lǐng)域編譯器發(fā)展的前世今生 ? 綜述);這部分重點討論面向AI領(lǐng)域的編譯技術(shù)。
隨著人工智能時代的來臨,AI領(lǐng)域應(yīng)用的大量出現(xiàn)也促進(jìn)著領(lǐng)域編譯的發(fā)展,最突出的表現(xiàn)就是多種AI編譯器的普及和應(yīng)用。AI領(lǐng)域有幾個重要的特征使得AI編譯器面臨很多新的機遇和挑戰(zhàn):一是AI領(lǐng)域中編程框架對計算圖與算子分離的設(shè)計機制為編譯優(yōu)化提供了更多的機會和更廣闊的空間;二是AI領(lǐng)域中對張量的抽象為編譯優(yōu)化提供了具有鮮明領(lǐng)域特征的語義信息;三是以Python為主的動態(tài)解釋器語言前端為其與AI編譯器的銜接帶了挑戰(zhàn);四是面向AI的領(lǐng)域?qū)S眉軜?gòu)為應(yīng)用的可移植性帶來了挑戰(zhàn)。在這些因素的驅(qū)動下,近年來學(xué)術(shù)界和工業(yè)界在AI編譯方面提出了一系列創(chuàng)新性的方法,也為編譯這一基礎(chǔ)學(xué)科的發(fā)展注入了新的活力。
01?圖算分離與圖算融合的優(yōu)化探索
為了讓開發(fā)者使用方便,框架前端(圖層)會盡量對Tensor計算進(jìn)行抽象封裝,開發(fā)者只要關(guān)注邏輯意義上的模型和算子;而在后端算子層的性能優(yōu)化時,又可以打破算子的邊界,從更細(xì)粒度的循環(huán)調(diào)度等維度,結(jié)合不同的硬件特點完成優(yōu)化。這種圖算分離的解耦設(shè)計大大簡化了AI復(fù)雜系統(tǒng)的設(shè)計,因此,多層IR設(shè)計無疑是較好的選擇,目前的主流IR設(shè)計也是分為圖(TVM Relay,XLA HLO,MindSpore MindIR等)和算子(TVM tir,XLA LLO,MindSpore AKG等)兩層。以主流AI編譯器TVM[13]和TensorFlow XLA[14]為例。TVM 和 XLA 上層都采用了數(shù)據(jù)流圖的中間表示,用圖結(jié)點來表示計算,邊表示數(shù)據(jù)流的依賴。在下層TVM 和 XLA 都針對編譯器自動生成不同平臺的高效代碼進(jìn)行了設(shè)計。其中TVM底層針對深度學(xué)習(xí)核心的張量處理設(shè)計的中間表示tir,它借鑒了Halide的中間表示來描述結(jié)點內(nèi)的計算,可以針對不同目標(biāo)平臺定制調(diào)度策略,從而實現(xiàn)平臺相關(guān)的深度優(yōu)化。TensorFlow XLA 則提出了一種基于代數(shù)表示的中間表示(XLA HLO),高層的數(shù)據(jù)流圖被轉(zhuǎn)換為XLA HLO 的中間表示,在此中間表示上可以實施支持jit的算子融合、內(nèi)存操作消除等優(yōu)化,優(yōu)化后的XLA HLO 可以被翻譯為LLVM 中間表示或直接映射到TPU 平臺。TVM和TensorFlow XLA 的圖與張量(或代數(shù))中間表示相結(jié)合的方法,一方面能夠適配人工智能領(lǐng)域用數(shù)據(jù)流圖來描述應(yīng)用的需求,另一方面又能夠兼顧應(yīng)用在不同硬件平臺之間的移植和優(yōu)化。
但圖層和算子層獨立優(yōu)化無法充分發(fā)揮芯片性能。近來面向圖算融合的優(yōu)化也日益成為學(xué)術(shù)界重要的研究方向。EasyView[15]提出了針對在網(wǎng)絡(luò)實現(xiàn)中高頻出現(xiàn)的tensor view類算子的端到端在線編譯自動融合方法,包含view lowering,內(nèi)存活動追蹤,讀寫關(guān)系一致的算子拓?fù)湫蛄蝎@取,以及計算內(nèi)存優(yōu)化策略等內(nèi)容。Apollo[16]設(shè)計了一個開放式多層規(guī)約式融合架構(gòu)以實現(xiàn)不同算子融合方式的協(xié)同組合。將不同的融合方式實現(xiàn)為不同的Layer,在各級layer分別做基于polyhedral優(yōu)化的循環(huán)融合,通過計算圖算子級別依賴和元素級別依賴的分析對訪存密集型算子盡可能融合,識別無計算依賴的算子并行化等優(yōu)化,然后通過對不同Layer進(jìn)行逐層規(guī)約合并,從而得到最終的融合算子子圖,并獲得最佳的融合性能收益。
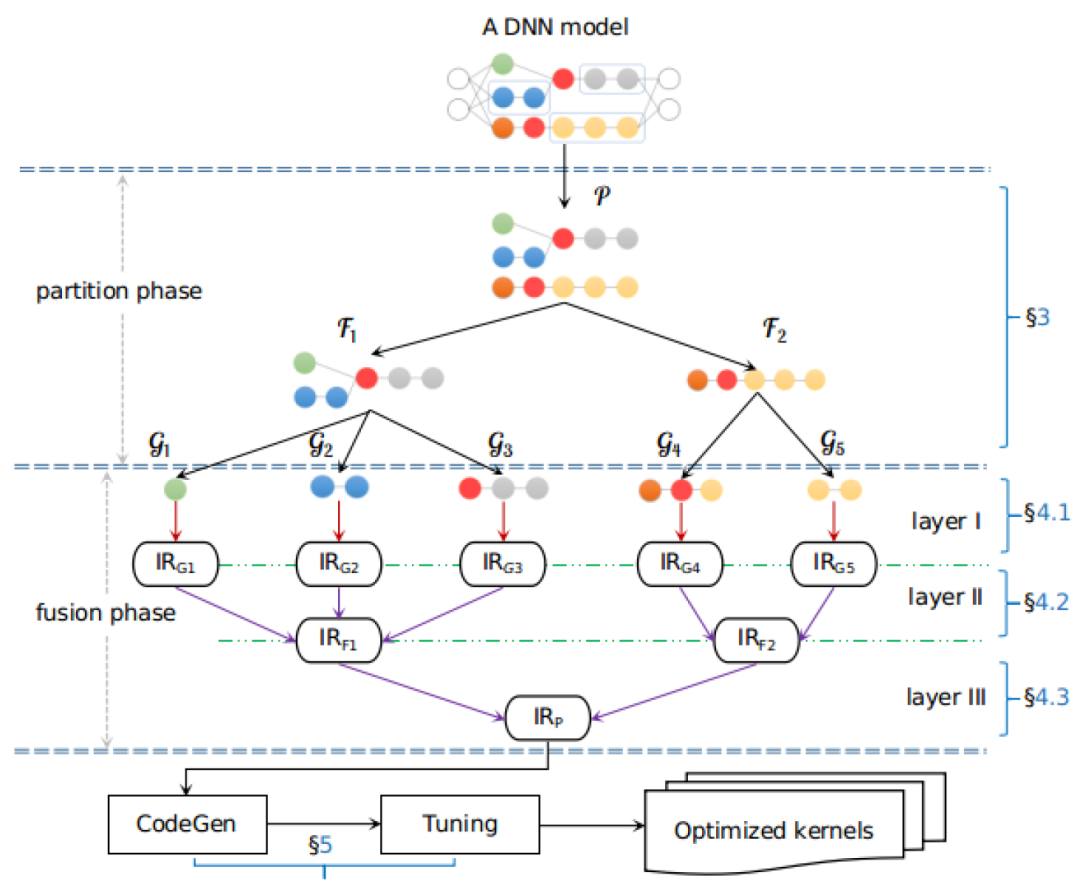
Apollo架構(gòu):子圖切分,融合,優(yōu)化[16]
02?面向張量的極致編譯優(yōu)化
AI編譯器的核心抽象是張量(矩陣的高維推廣)。在AI領(lǐng)域,各種數(shù)據(jù),如圖片,文字,視頻等,都被抽象成張量,而原本對這些數(shù)據(jù)的處理也被抽象成對張量的計算操作,如卷積,轉(zhuǎn)置,池化,歸一化等,這些對張量的操作按照順序組合就組成了張量計算的數(shù)據(jù)流圖。做這層抽象的意義在筆者看來是因為傳統(tǒng)編譯器的IR,如LLVM IR太底層了,其對數(shù)據(jù)的處理粒度在標(biāo)量至多向量級別,而編譯器針對如此底層的IR分析能力有限。畢竟通過嵌套在多層循環(huán)里的load,store和alu操作已經(jīng)很難還原出其原本的計算信息(如矩陣轉(zhuǎn)置等)。從而像是矩陣轉(zhuǎn)置再轉(zhuǎn)置這樣的pattern就基本無法在LLVM IR的粒度分析出來,而通過張量和張量計算的抽象層,這種優(yōu)化就可以很容易實現(xiàn)。
AI編譯器的優(yōu)化目標(biāo)主要是為了提升AI模型的端到端性能,這個性能會受到包括計算訪存比,并行性,資源占用率等多方面因素影響,因而很難通過一個通用的策略涵蓋大量不同的后端而都能達(dá)到非常優(yōu)秀的性能。AI編譯器通常通過搜索調(diào)度空間的方式,來尋找適配后端的極致張量優(yōu)化策略。這里以TVM為例。TVM將計算和調(diào)度分離,計算通過張量表達(dá)式表示,張量表達(dá)式在設(shè)計上借鑒了 Halide、Darkroom 和 TACO。調(diào)度則是針對計算的一系列變換,為了在許多后端實現(xiàn)高性能,必須要支持足夠多的調(diào)度原語來涵蓋不同硬件后端的各種優(yōu)化而包括tile/fuse/reorder/bind/compute_at等等,通過調(diào)度可以挖掘張量計算在特定硬件后端下的極致性能。TVM陸續(xù)發(fā)展了從基于模版的AutoTVM到基于搜索的Ansor,再到通過DSL tensorIR結(jié)合二者優(yōu)點的Meta Schedule逐漸發(fā)展起來的自動調(diào)度搜索策略,可以針對不同的目標(biāo)硬件平臺來自動搜索的更優(yōu)卸載方式,從而實現(xiàn)平臺相關(guān)的深度優(yōu)化。

TVM 張量表達(dá)式優(yōu)化流程,多后端調(diào)度支持[17]
03?Python為主的動態(tài)解釋器語言前端銜接
與傳統(tǒng)編譯器不同,AI編譯器通常不需要Lexer/Parser,而是基于前端語言(主要是Python)的AST將模型解析并構(gòu)造為計算圖IR,側(cè)重于保留shape、layout等Tensor計算特征信息,當(dāng)然部分編譯器還能保留控制流的信息。這里的難點在于,Python是一種靈活度極高的解釋執(zhí)行的語言,AI編譯器需要把它轉(zhuǎn)到靜態(tài)的IR上。針對這一難點,目前一個比較突出的工作是pytorch2.0[18]提出的TorchDynamo[19]這一 JIT 編譯接口,傳統(tǒng)pytorch編程無論是trace還是eager模式都沒有辦法簡單地通過python代碼獲取模型的圖結(jié)構(gòu),導(dǎo)致模型導(dǎo)出、算子融合優(yōu)化、模型量化等工作都出現(xiàn)困難。TorchDynamo支持在運行時修改python動態(tài)執(zhí)行邏輯,修改的時機是 在CPython 解釋器的 ByteCode 執(zhí)行前,從而可以使通過在運行時設(shè)置一個自定義的 Frame,該 Frame 中的 ByteCode 支持 CallBack 到 Python 層去修改。供用戶自定義計算圖。利用這一機制TorchDynamo支持了動態(tài)圖的特性,即只需要通過python的執(zhí)行機制即可自動調(diào)用后方對應(yīng)的靜態(tài)子模型。以下圖為例,TorchDynamo方式寫的bar模塊具有一個動態(tài)信息的條件分支(對b.sum()<0的判斷),這是傳統(tǒng)trace和eager模式都無法支持的描述,但通過TorchDynamo方式,python執(zhí)行到條件分支時可以根據(jù)動態(tài)信息自動根據(jù)條件調(diào)用有if語句的子圖或沒有if語句的子圖,從而完成了對python if語句描述的動態(tài)圖信息的支持。

通過TorchDynamo支持動態(tài)的控制依賴計算圖[19]
04?DSA芯片架構(gòu)的支持
隨著AI應(yīng)用的算力需求日益增長,以CPU為主的通用計算算力越來越難以滿足大規(guī)模AI模型的性能和時延需求,因此AI應(yīng)用往往需要通過高性能的針對AI的DSA架構(gòu)的加速器后端來加速算子性能。這不僅包括對基于FPGA、ASIC、類腦計算等專用加速器的,也有在GPGPU上擴展的tensor core等專用加速核心。這些加速器在計算通用性,可配置性,功耗,性能,性價比,易用性等方面各有千秋,同時在實現(xiàn)架構(gòu)上差異巨大,根據(jù)這些架構(gòu)約定的軟硬件接口層次的不同,如是否將內(nèi)部cache操作暴露給編譯器,是否硬件自動內(nèi)存管理等,編譯器能做的優(yōu)化層次也不同。這也導(dǎo)致AI應(yīng)用部署在不同的后端架構(gòu)時需要生成出各種粒度的最終計算負(fù)載,這種粒度對應(yīng)硬件/runtime規(guī)定的接口。如在GPU后端下,一個或多個圖上的算子,在經(jīng)過算子融合等優(yōu)化步驟后,最終匹配上了cudnn/miopen等GPU算子庫的一個庫函數(shù)實現(xiàn),最終編譯器通過codegen生成以cuMalloc,cuMemcpy,cuLaunchKernel等cuda driver級別的api調(diào)用,借助CUDA runtime軟件棧分別完成GPU內(nèi)存空間管理,CPU到GPU的數(shù)據(jù)傳輸,算子的底層庫函數(shù)調(diào)用,GPU數(shù)據(jù)回傳等操作,最終完成了計算步驟。由于DSA架構(gòu)的差異性和多樣性,每一種架構(gòu)都可能對應(yīng)一種codegen方式和runtime支持。因而如何設(shè)計擴展DSA架構(gòu)以實現(xiàn)對新的DSA架構(gòu)的快速支持也是AI編譯器的難點。
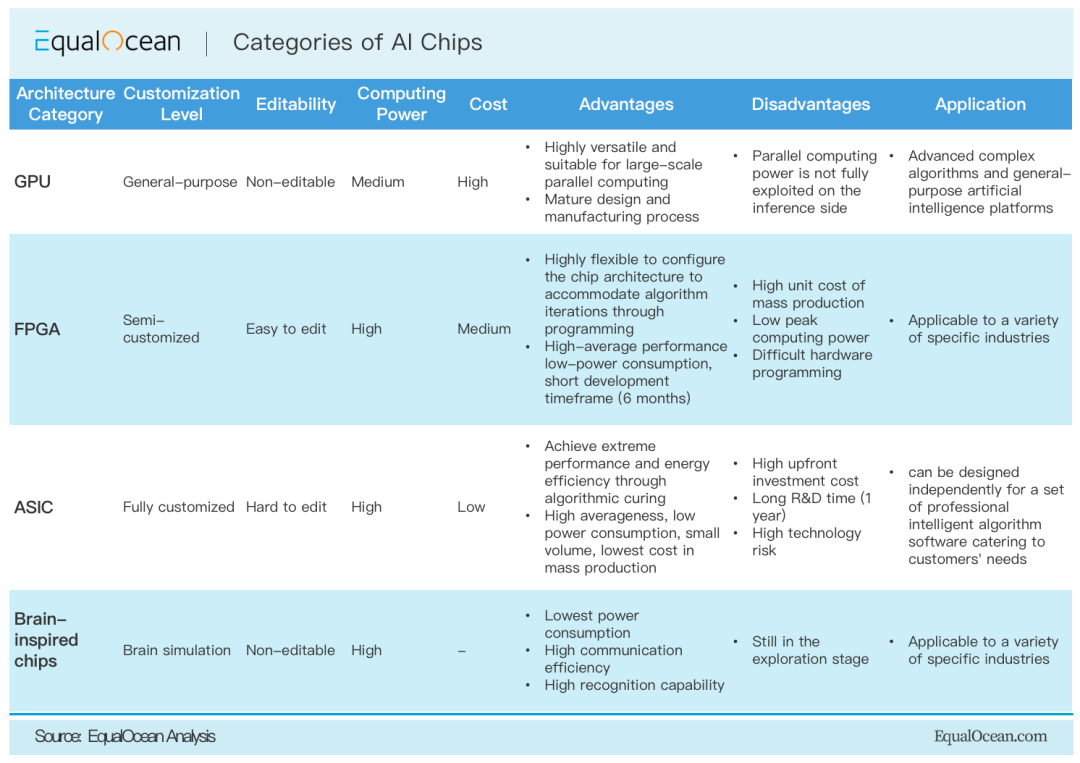
不同類型AI芯片后端體系結(jié)構(gòu)的比較[20]
05?面向神經(jīng)網(wǎng)絡(luò)的全局優(yōu)化
AI應(yīng)用的優(yōu)化主要是為了提升端到端的模型性能,其受到包括計算訪存比,并行性,資源占用率等多方面因素影響。在通用的編譯器優(yōu)化(如LLVM的優(yōu)化pass)以外,AI編譯器引入的面向神經(jīng)網(wǎng)絡(luò)應(yīng)用的特定優(yōu)化主要包括三類:張量優(yōu)化,自動微分,自動并行。在AI領(lǐng)域,計算被抽象成張量的計算,基于張量的計算原語和計算優(yōu)化是AI編譯器的重要關(guān)注點。自動微分是支持AI網(wǎng)絡(luò)訓(xùn)練的重要基礎(chǔ),因為模型訓(xùn)練的基礎(chǔ)就是梯度下降和誤差反向傳播,都需要自動微分技術(shù)的支持。目前主要有基于計算圖的自動微分、基于Tape和運算符重載的自動微分、基于source2source的自動微分等主流方案。自動并行技術(shù)則主要包括:數(shù)據(jù)并行、算子級模型并行、Pipeline模型并行、優(yōu)化器模型并行和重計算等,以提高整體并行度的方式優(yōu)化網(wǎng)絡(luò)性能。 ?
06?領(lǐng)域定制架構(gòu)下的編譯基礎(chǔ)設(shè)施
隨著傳統(tǒng)通用處理器的性能提升越來越困難,近年來領(lǐng)域定制硬件(DSA)成為體系結(jié)構(gòu)設(shè)計中新的增長點,也是計算機體系結(jié)構(gòu)黃金時代重要的發(fā)展。多種類型的加速器不斷涌現(xiàn)。例如GPU、NPU、FGPA、ASIC 等。而為了適配大量新生的DSA,領(lǐng)域編譯開發(fā)需要通過共用來降低開發(fā)成本,并重點關(guān)注于核心商業(yè)邏輯的實現(xiàn),這使得領(lǐng)域編譯也像電力,網(wǎng)絡(luò),公共云等技術(shù)一樣,走向了技術(shù)演進(jìn)的自然終點:基礎(chǔ)設(shè)施化。其中最有代表性的基礎(chǔ)設(shè)施是MLIR[21,24]。
MLIR是由Google 提出的一個能夠快速構(gòu)建領(lǐng)域編譯器的基礎(chǔ)設(shè)施,提出了一種構(gòu)建可重用、可擴展編譯器基礎(chǔ)結(jié)構(gòu)的新方法。其核心思想是利用多層次中間表示來解決軟件的碎片化問題,減少構(gòu)建Domain Specific Compiler的開銷。MLIR雖然目前主要用于機器學(xué)習(xí)領(lǐng)域,但在設(shè)計上是通用的編譯器框架,比如也有FLANG(llvm中的FORTRAN編譯器)[22],CIRCT(用于硬件設(shè)計)[23]等與ML無關(guān)的項目。MLIR 提供一系列可復(fù)用的易擴展的基礎(chǔ)組件,從而使得不同領(lǐng)域的編譯開發(fā)人員能夠快速的搭建領(lǐng)域?qū)S镁幾g器,而且不同領(lǐng)域的編譯分析及優(yōu)化可以被復(fù)用。
與 LLVM IR 唯一的中間表示不同,MLIR能通過多層方言(dialect)的設(shè)計,表示更高層次的結(jié)構(gòu)和操作,比如神經(jīng)網(wǎng)絡(luò)的圖結(jié)構(gòu),張量的計算等。MLIR將一些領(lǐng)域的特性抽象為方言并允許用戶自定義新的方言,與此同時,MLIR 提供了不同方言間的轉(zhuǎn)換機制來實現(xiàn)不同方言上編譯分析和優(yōu)化的復(fù)用。MLIR執(zhí)行過程和LLVM一樣,IR會通過由Pass組成的優(yōu)化Pipeline,不斷地方言內(nèi),方言間變換直到生成最終的IR,然后被lower到底層的通用IR上進(jìn)行代碼生成。MLIR不僅僅是一個中間表示,而是一個新的編譯器基礎(chǔ)設(shè)施。近年來,學(xué)術(shù)界和工業(yè)界也在MLIR 上開展了很多領(lǐng)域編譯優(yōu)化的工作。如下圖所示的將TensorFlow XLA 接入到了MLIR 的例子。上層的模型輸入為TF Graph,在MLIR架構(gòu)下逐層變換到HLO,LHLO,Affine,Vector等更低層次的方言上,在每級方言上都有對應(yīng)層次和粒度的優(yōu)化和調(diào)度,如在最高層的HLO適合做融合等。最終生成LLVM IR或SPIR-V等通用中間表示,再調(diào)用后端通用編譯器完成最終代碼生成。
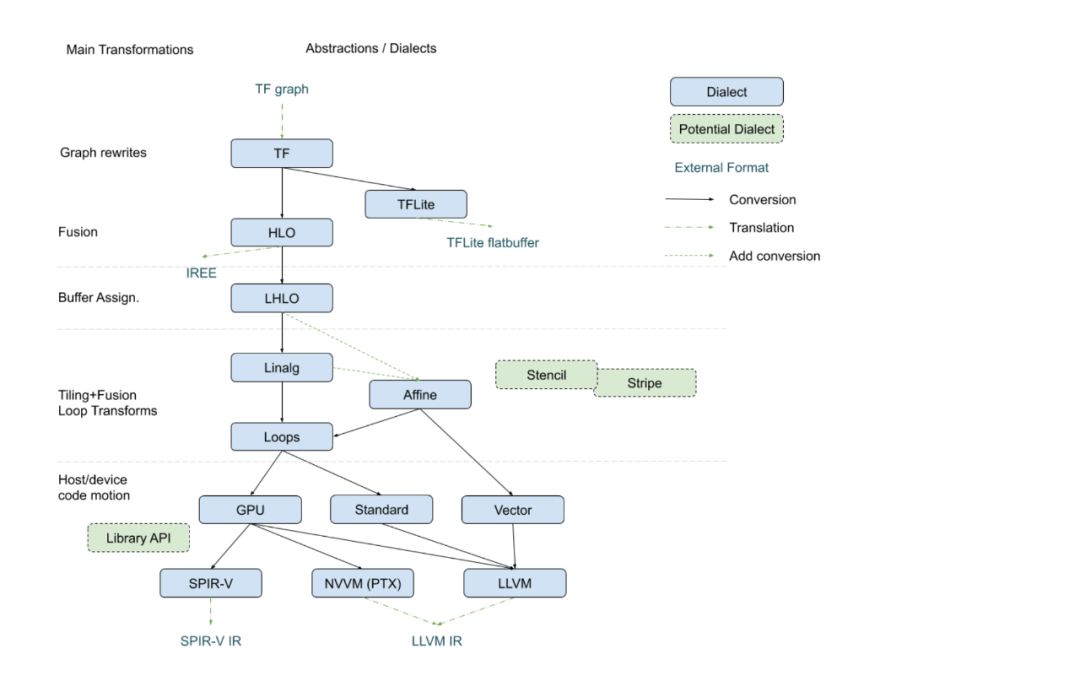
MLIR在Tensorflow XLA上的實現(xiàn)[25]
07?國內(nèi)學(xué)界和業(yè)界的工作
AI生態(tài)的火熱也促使著學(xué)術(shù)界和工業(yè)界在AI編譯系統(tǒng)和AI異構(gòu)加速器等方面全面發(fā)展。國內(nèi)在AI生態(tài)的建設(shè)方面開始較早,投入眾多,催生著大量的學(xué)術(shù)成果和工業(yè)界基礎(chǔ)設(shè)施的發(fā)展。
一方面,國內(nèi)學(xué)術(shù)界在AI編譯系統(tǒng)和AI加速器體系結(jié)構(gòu)等方面有很多研究突破,包括但不限于語言,編譯,軟硬件系統(tǒng)設(shè)計等方面。例如:針對目前的張量優(yōu)化只考慮了完全等價變換,為張量程序優(yōu)化引入了部分等價變換的優(yōu)化和對應(yīng)的糾正機制的PET[26];通過語言層面引入對tensor的細(xì)粒度控制,包括tensor的不規(guī)則索引等,避免了大量冗余計算的FreeTensor[27];通過特定于GNN網(wǎng)絡(luò)的圖運算符抽象做優(yōu)化的uGrapher[28];將硬件抽象設(shè)計為IR以支持更多intrinsic 原語的AMOS[29];通過基于殘差的精度細(xì)化技術(shù),控制量化誤差,在性能和精度之間進(jìn)行權(quán)衡的QUANTENSOR[30];根據(jù)優(yōu)化目標(biāo)配置實現(xiàn)云-移動部署的性能功耗綜合優(yōu)化的DNNTune[31];面向任意精度計算(Arbitrary Precision Computing:APC)的Cambricon-P[32]體系結(jié)構(gòu),等等。
另一方面,工業(yè)界結(jié)合各廠家自身業(yè)務(wù)的需求,在AI基礎(chǔ)設(shè)施和系統(tǒng)技術(shù)上不斷優(yōu)化和探索,在不同的維度持續(xù)發(fā)力,也貢獻(xiàn)了很多開源項目。在AI編譯基礎(chǔ)設(shè)施方面,華為的MindSpore社區(qū)[33]提供了一個主要面向華為的昇騰處理器后端的云邊端全場景開放AI推理和訓(xùn)練框架。其在包括圖算聯(lián)合優(yōu)化,大規(guī)模分布式自動并行,自動算子生成等多項技術(shù)上做出了探索和貢獻(xiàn)。阿里巴巴的PAI團隊也專注于編譯優(yōu)化,探索了XLA,TVM,MLIR等多條技術(shù)路線,目前在大顆粒算子融合技術(shù),以及GPU上訪存密集型算子的融合優(yōu)化上也取得不錯的效果,并在MLIR這條技術(shù)路線上擴充了框架應(yīng)對動態(tài)輸入shape上的能力[34]。此外,國內(nèi)的大型互聯(lián)網(wǎng)公司,AI技術(shù)和芯片公司等都在面向AI的編譯技術(shù)上有越來越多的投入,極大推進(jìn)了相關(guān)技術(shù)的發(fā)展。
領(lǐng)域編譯器作為通用編譯器的重要補充,在發(fā)揮極致性能和提升開發(fā)效率方面一直發(fā)揮著重要的作用,近年來在AI領(lǐng)域更是備受關(guān)注。隨著AI技術(shù)的快速發(fā)展,DSA硬件在AI計算中的大量使用,AI軟件棧也相應(yīng)的日趨復(fù)雜,對編譯技術(shù)提出更高的要求,這也大大促進(jìn)了編譯學(xué)科的快速發(fā)展。我們相信,在強烈的需求驅(qū)動下,通過學(xué)界和業(yè)界的共同努力,領(lǐng)域編譯技術(shù)在各種類型的計算系統(tǒng)中將扮演越來越重要的角色。
編輯:黃飛
?

























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論