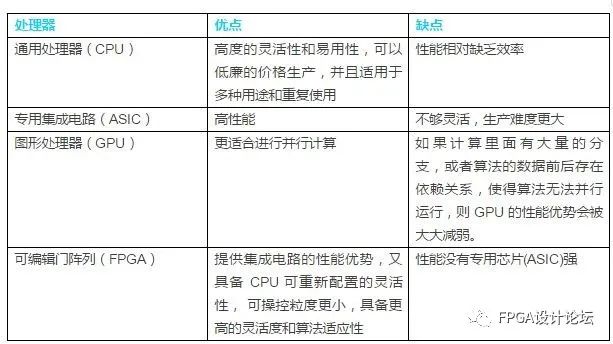
 電子發(fā)燒友App
電子發(fā)燒友App


X-Engine 是集團(tuán)數(shù)據(jù)庫(kù)事業(yè)部研發(fā)的新一代存儲(chǔ)引擎,是新一代分布式數(shù)據(jù)庫(kù)X-DB的根基。為了達(dá)到10倍MySQL性能,1/10存儲(chǔ)成本的目標(biāo),X-DB從一開(kāi)始就使用了軟硬件結(jié)合的設(shè)計(jì)思路, 以充分發(fā)揮當(dāng)前軟件和硬件領(lǐng)域最前沿的技術(shù)優(yōu)勢(shì)。而引入FPGA加速是我們?cè)诙ㄖ朴?jì)算領(lǐng)域做出的第一個(gè)嘗試。目前FPGA加速版本的X-DB已經(jīng)在線上開(kāi)始小規(guī)模灰度,在今年6.18,雙11大促中,F(xiàn)PGA將助力X-DB, 將在不增加成本的前提下,滿足阿里業(yè)務(wù)對(duì)數(shù)據(jù)庫(kù)更高的性能要求。
背景介紹
作為世界上最大的在線交易網(wǎng)站,阿里巴巴的 OLTP (online transaction processing) 數(shù)據(jù)庫(kù)系統(tǒng)需要滿足高吞吐的業(yè)務(wù)需求。根據(jù)統(tǒng)計(jì),每天 OLTP 數(shù)據(jù)庫(kù)系統(tǒng)的記錄寫(xiě)入量達(dá)到了幾十億,在2017年的雙十一,系統(tǒng)的峰值吞吐達(dá)到了千萬(wàn)級(jí)TPS (transactions per second)。阿里巴巴的業(yè)務(wù)數(shù)據(jù)庫(kù)系統(tǒng)主要有以下幾個(gè)特點(diǎn):
事務(wù)高吞吐并且讀操作和寫(xiě)操作的低延時(shí);
寫(xiě)操作占比相對(duì)較高,傳統(tǒng)的數(shù)據(jù)庫(kù)workload,讀寫(xiě)比一般在 10:1 以上,而阿里巴巴的交易系統(tǒng),在雙十一當(dāng)天讀寫(xiě)比達(dá)到了 3:1;
數(shù)據(jù)訪問(wèn)熱點(diǎn)比較集中,一條新寫(xiě)入的數(shù)據(jù),在接下來(lái)7天內(nèi)的訪問(wèn)次數(shù)占整體訪問(wèn)次數(shù)的99%,超過(guò)7天之后的被訪問(wèn)概率極低。
為了滿足阿里的業(yè)務(wù)對(duì)性能和成本近乎苛刻的要求,我們重新設(shè)計(jì)開(kāi)發(fā)了一個(gè)存儲(chǔ)引擎稱為X-Engine。在X-Engine中,我們引入了諸多數(shù)據(jù)庫(kù)領(lǐng)域的前沿技術(shù),包括高效的內(nèi)存索引結(jié)構(gòu),寫(xiě)入異步流水線處理機(jī)制,內(nèi)存數(shù)據(jù)庫(kù)中使用的樂(lè)觀并發(fā)控制等。
為了達(dá)到極致的寫(xiě)性能水平,并且方便分離冷熱數(shù)據(jù)以實(shí)現(xiàn)分層存儲(chǔ),X-Engine借鑒了LSM-Tree的設(shè)計(jì)思想。其在內(nèi)存中會(huì)維護(hù)多個(gè) memtable,所有新寫(xiě)入的數(shù)據(jù)都會(huì)追加到 memtable ,而不是直接替換掉現(xiàn)有的記錄。由于需要存儲(chǔ)的數(shù)據(jù)量較大,將所有數(shù)據(jù)存儲(chǔ)在內(nèi)存中是不可能的。
當(dāng)內(nèi)存中的數(shù)據(jù)達(dá)到一定量之后,會(huì)flush到持久化存儲(chǔ)中形成 SSTable。為了降低讀操作的延時(shí),X-Engine通過(guò)調(diào)度 compaction 任務(wù)來(lái)定期 compact持久化存儲(chǔ)中的 SSTable,merge多個(gè) SSTable 中的鍵值對(duì),對(duì)于多版本的鍵值對(duì)只保留最新的一個(gè)版本(所有當(dāng)前被事務(wù)引用的鍵值對(duì)版本也需要保留)。
根據(jù)數(shù)據(jù)訪問(wèn)的特點(diǎn),X-Engine會(huì)將持久化數(shù)據(jù)分層,較為活躍的數(shù)據(jù)停留在較高的數(shù)據(jù)層,而相對(duì)不活躍(訪問(wèn)較少)的數(shù)據(jù)將會(huì)與底層數(shù)據(jù)進(jìn)行合并,并存放在底層數(shù)據(jù)中,這些底層數(shù)據(jù)采用高度壓縮的方式存儲(chǔ),并且會(huì)遷移到在容量較大,相對(duì)廉價(jià)的存儲(chǔ)介質(zhì) (比如SATA HDD) 中,達(dá)到使用較低成本存儲(chǔ)大量數(shù)據(jù)的目的。
如此分層存儲(chǔ)帶來(lái)一個(gè)新的問(wèn)題:即整個(gè)系統(tǒng)必須頻繁的進(jìn)行compaction,寫(xiě)入量越大,Compaction的過(guò)程越頻繁。而compaction是一個(gè)compare & merge的過(guò)程,非常消耗CPU和存儲(chǔ)IO,在高吞吐的寫(xiě)入情形下,大量的compaction操作占用大量系統(tǒng)資源,必然帶來(lái)整個(gè)系統(tǒng)性能斷崖式下跌,對(duì)應(yīng)用系統(tǒng)產(chǎn)生巨大影響。
而完全重新設(shè)計(jì)開(kāi)發(fā)的X-Engine有著非常優(yōu)越的多核擴(kuò)展性,能達(dá)到非常高的性能,僅僅前臺(tái)事務(wù)處理就幾乎能完全消耗所有的CPU資源,其對(duì)資源的使用效率對(duì)比InnoDB,如下圖所示:
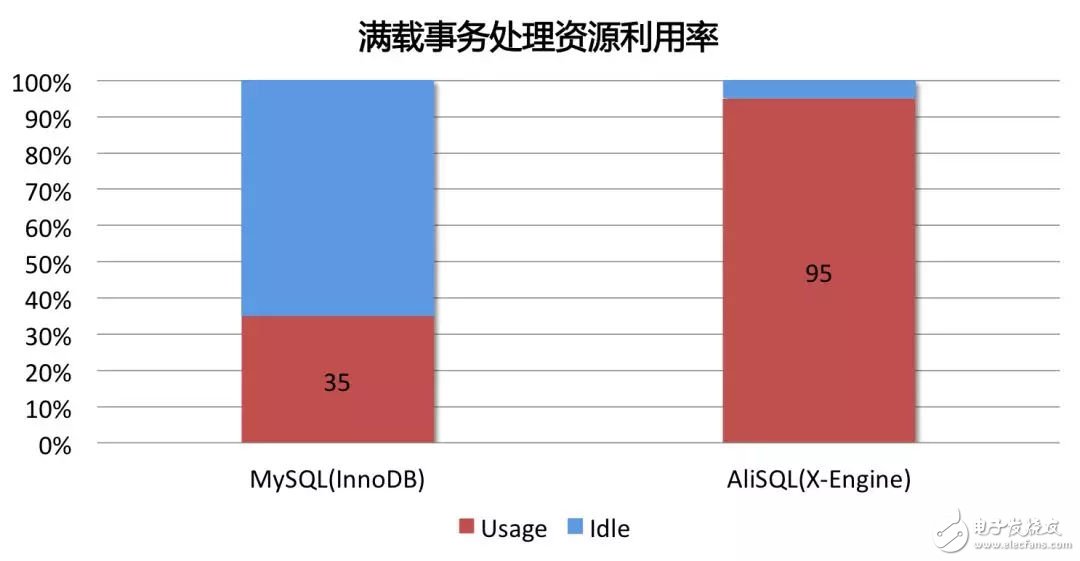
在如此性能水平下,系統(tǒng)沒(méi)有多余的計(jì)算資源進(jìn)行compaction操作,否則將承受性能下跌的代價(jià)。
經(jīng)測(cè)試,在 DbBench benchmark 的 write-only 場(chǎng)景下,系統(tǒng)會(huì)發(fā)生周期性的性能抖動(dòng),在 compaction 發(fā)生時(shí),系統(tǒng)性能下跌超過(guò)40%,當(dāng) compaction 結(jié)束時(shí),系統(tǒng)性能又恢復(fù)到正常水位。如下圖所示:
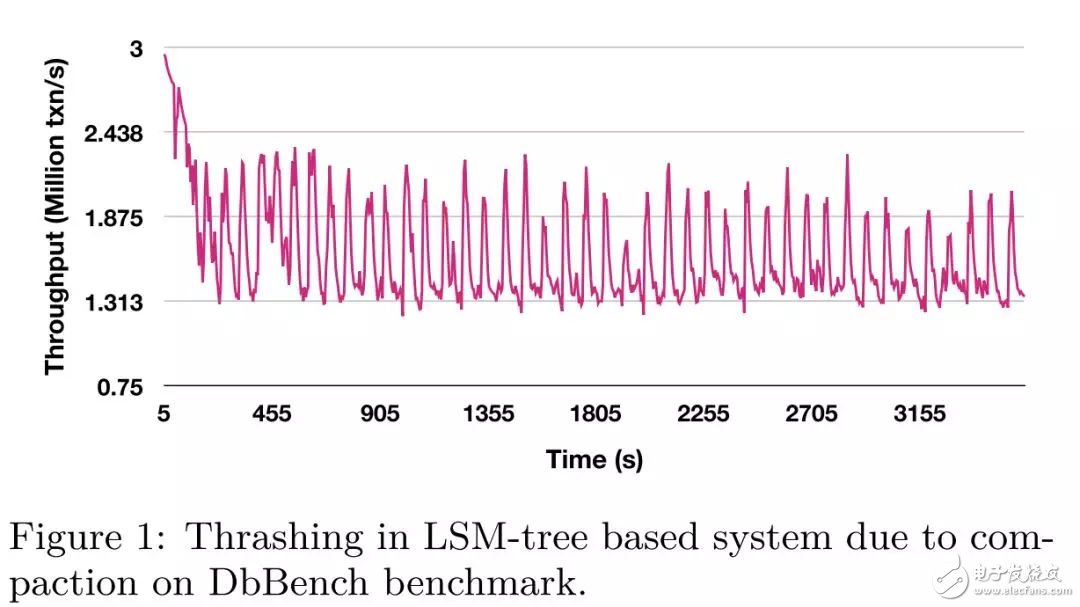
但是如果 compaction 進(jìn)行的不及時(shí),多版本數(shù)據(jù)的累積又會(huì)嚴(yán)重影響讀操作。
為了解決 compaction 的抖動(dòng)問(wèn)題,學(xué)術(shù)界提出了諸如 VT-tree、bLSM、PE、PCP、dCompaction 等結(jié)構(gòu)。盡管這些算法通過(guò)不同方法優(yōu)化了 compaction 性能,但是 compaction 本身消耗的 CPU 資源是無(wú)法避免的。據(jù)相關(guān)研究統(tǒng)計(jì),在使用SSD存儲(chǔ)設(shè)備時(shí),系統(tǒng)中compaction的計(jì)算操作占據(jù)了60%的計(jì)算資源。因此,無(wú)論在軟件層面針對(duì) compaction 做了何種優(yōu)化,對(duì)于所有基于 LSM-tree 的存儲(chǔ)引擎而言,compaction造成的性能抖動(dòng)都會(huì)是阿喀琉斯之踵。
幸運(yùn)的是,專用硬件的出現(xiàn)為解決compaction導(dǎo)致的性能抖動(dòng)提供了一個(gè)新的思路。實(shí)際上,使用專用硬件解決傳統(tǒng)數(shù)據(jù)庫(kù)的性能瓶頸已經(jīng)成為了一個(gè)趨勢(shì),目前數(shù)據(jù)庫(kù)中的select、where操作已經(jīng)offload到FPGA上,而更為復(fù)雜的 group by 等操作也進(jìn)行了相關(guān)的研究。但是目前的FPGA加速解決方案存在以下兩點(diǎn)不足:
目前的加速方案基本上都是為SQL層設(shè)計(jì),F(xiàn)PGA也通常放置在存儲(chǔ)和host之間作為一個(gè)filter。雖然在FPGA加速OLAP系統(tǒng)方面已經(jīng)有了許多嘗試,但是對(duì)于OLTP系統(tǒng)而言,F(xiàn)PGA加速的設(shè)計(jì)仍然是一個(gè)挑戰(zhàn);
隨著FPGA的芯片尺寸越來(lái)越小,F(xiàn)PGA內(nèi)部的錯(cuò)誤諸如單粒子翻轉(zhuǎn)(SEU)正在成為FPGA可靠性的越來(lái)越大的威脅,對(duì)于單一芯片而言,發(fā)生內(nèi)部錯(cuò)誤的概率大概是3-5年,對(duì)于大規(guī)模的可用性系統(tǒng),容錯(cuò)機(jī)制的設(shè)計(jì)顯得尤為重要。
為了緩解compaction對(duì)X-Engine系統(tǒng)性能的影響,我們引入了異構(gòu)硬件設(shè)備FPGA來(lái)代替CPU完成compaction操作,使系統(tǒng)整體性能維持在高水位并避免抖動(dòng),是存儲(chǔ)引擎得以服務(wù)業(yè)務(wù)苛刻要求的關(guān)鍵。本文的貢獻(xiàn)如下:
FPGA compaction 的高效設(shè)計(jì)和實(shí)現(xiàn)。通過(guò)流水化compaction操作,F(xiàn)PGA compaction取得了十倍于CPU單線程的處理性能;
混合存儲(chǔ)引擎的異步調(diào)度邏輯設(shè)計(jì)。由于一次FPGA compaction的鏈路請(qǐng)求在ms級(jí)別,使用傳統(tǒng)的同步調(diào)度方式會(huì)阻塞大量的compaction線程并且?guī)?lái)很多線程切換的代價(jià)。通過(guò)異步調(diào)度,我們減少了線程切換的代價(jià),提高了系統(tǒng)在工程方面的可用性。
容錯(cuò)機(jī)制的設(shè)計(jì)。由于輸入數(shù)據(jù)的限制和FPGA內(nèi)部錯(cuò)誤,都會(huì)造成某個(gè)compaction 任務(wù)的回滾,為了保證數(shù)據(jù)的完整性,所有被FPGA回滾的任務(wù)都會(huì)由同等的CPU compaction線程再次執(zhí)行。本文設(shè)計(jì)的容錯(cuò)機(jī)制達(dá)到了阿里實(shí)際的業(yè)務(wù)需求并且同時(shí)規(guī)避了FPGA內(nèi)部的不穩(wěn)定性。
問(wèn)題背景
X-Engine的Compaction
X-Engine的存儲(chǔ)結(jié)構(gòu)包含了一個(gè)或多個(gè)內(nèi)存緩沖區(qū) (memtable)以及多層持久化存儲(chǔ) L0, L1, ... ,每一層由多個(gè)SSTable組成。
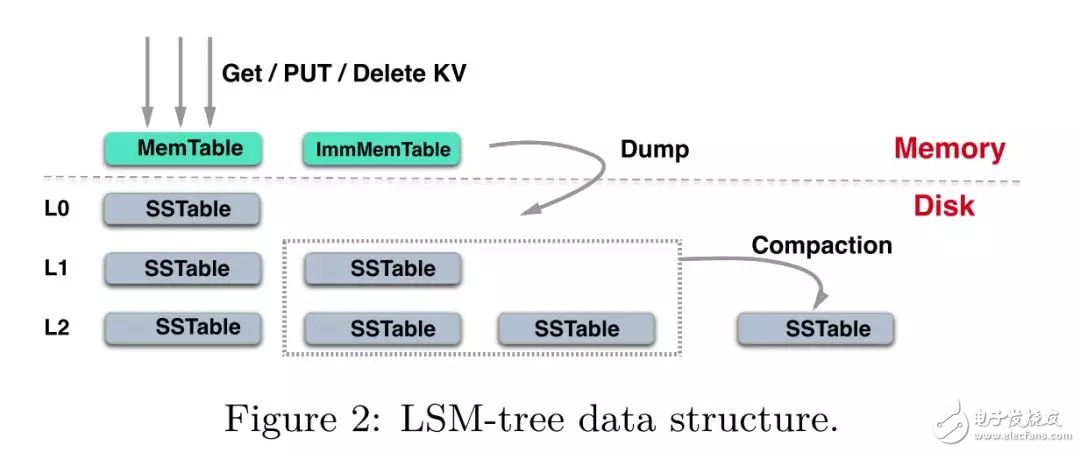
當(dāng)memtable寫(xiě)滿后,會(huì)轉(zhuǎn)化為 immutable memtable,然后轉(zhuǎn)化為SSTable flush到L0層。每一個(gè)SSTable包含多個(gè)data block和一個(gè)用來(lái)索引data block的index block。當(dāng)L0層文件個(gè)數(shù)超過(guò)了限制,就會(huì)觸發(fā)和L1層有重疊key range的SSTable的合并,這個(gè)過(guò)程就叫做compaction。類似的,當(dāng)一層的SSTable個(gè)數(shù)超過(guò)了閾值都會(huì)觸發(fā)和下層數(shù)據(jù)的合并,通過(guò)這種方式,冷數(shù)據(jù)不斷向下流動(dòng),而熱數(shù)據(jù)則駐留在較高層上。
一個(gè)compaction過(guò)程merge一個(gè)指定范圍的鍵值對(duì),這個(gè)范圍可能包含多個(gè)data block。一般來(lái)說(shuō),一個(gè)compaction過(guò)程會(huì)處理兩個(gè)相鄰層的data block合并,但是對(duì)于L0層和L1層的compaction需要特殊考慮,由于L0層的SSTable是直接從內(nèi)存中flush下來(lái),因此層間的SSTable的Key可能會(huì)有重疊,因此L0層和L1層的compaction可能存在多路data block的合并。
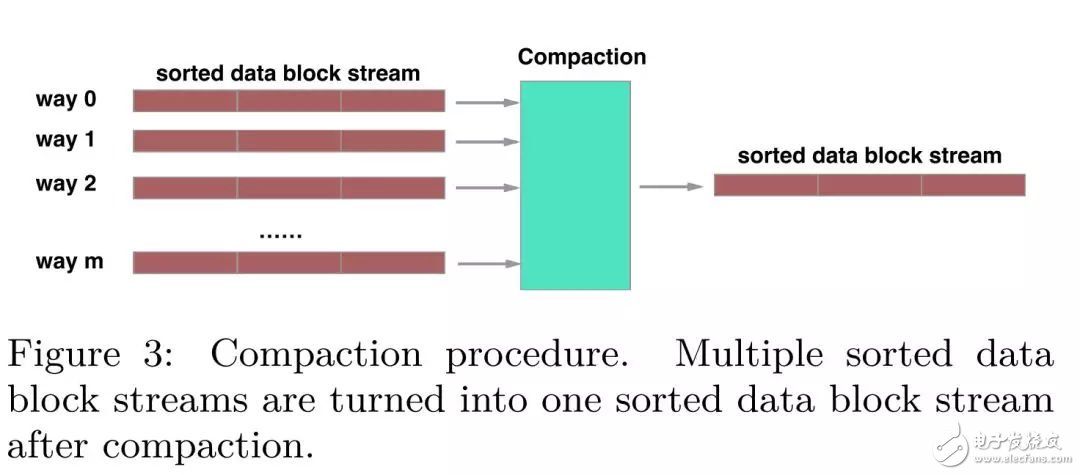
對(duì)于讀操作而言,X-Engine需要從所有的memtable中查找,如果沒(méi)有找到,則需要在持久化存儲(chǔ)中從高層向底層查找。因此,及時(shí)的compaction操作不僅會(huì)縮短讀路徑,也會(huì)節(jié)省存儲(chǔ)空間,但是會(huì)搶奪系統(tǒng)的計(jì)算資源,造成性能抖動(dòng),這是X-Engien亟待解決的困境。
FPGA加速數(shù)據(jù)庫(kù)
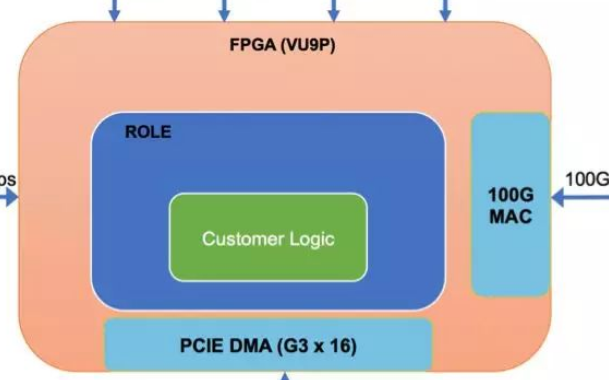
從現(xiàn)在的FPGA加速數(shù)據(jù)庫(kù)現(xiàn)狀分析,我們可以將FPGA加速數(shù)據(jù)庫(kù)的架構(gòu)分為兩種,"bump-in-the-wire" 設(shè)計(jì)和混合設(shè)計(jì)架構(gòu)。前期由于FPGA板卡的內(nèi)存資源不夠,前一種架構(gòu)方式比較流行,F(xiàn)PGA被放置在存儲(chǔ)和host的數(shù)據(jù)路徑上,充當(dāng)一個(gè)filter,這樣設(shè)計(jì)的好處是數(shù)據(jù)的零拷貝,但是要求加速的操作是流式處理的一部分,設(shè)計(jì)方式不夠靈活;
后一種設(shè)計(jì)方案則將FPGA當(dāng)做一個(gè)協(xié)處理器,F(xiàn)PGA通過(guò)PCIe和host連接,數(shù)據(jù)通過(guò)DMA的方式進(jìn)行傳輸,只要offload的操作計(jì)算足夠密集,數(shù)據(jù)傳輸?shù)拇鷥r(jià)是可以接受的。混合架構(gòu)的設(shè)計(jì)允許更為靈活的offload方式,對(duì)于compaction這一復(fù)雜操作而言,F(xiàn)PGA和host之間數(shù)據(jù)的傳輸是必須的,所以在X-Engine中,我們的硬件加速采用了混合設(shè)計(jì)的架構(gòu)。
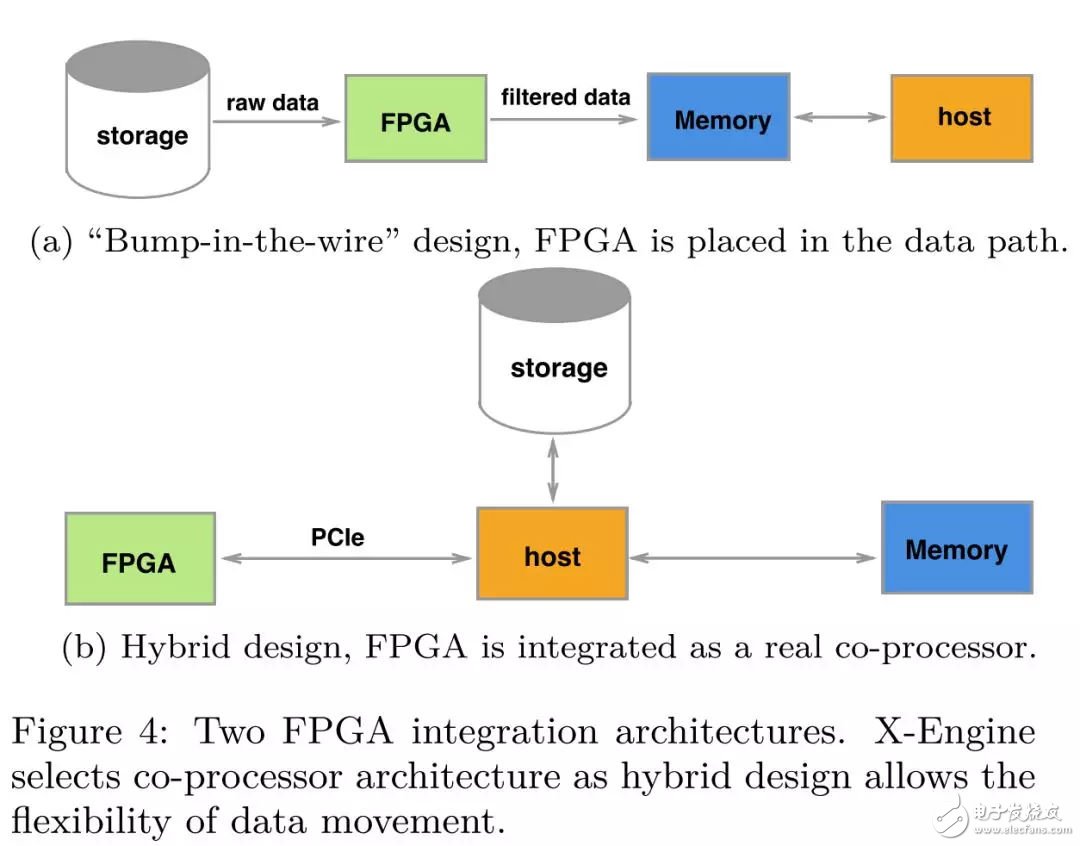
系統(tǒng)設(shè)計(jì)
在傳統(tǒng)的基于LSM-tree的存儲(chǔ)引擎中,CPU不僅要處理正常的用戶請(qǐng)求,還要負(fù)責(zé)compaction任務(wù)的調(diào)度和執(zhí)行,即對(duì)于compaction任務(wù)而言,CPU既是生產(chǎn)者,也是消費(fèi)者,對(duì)于CPU-FPGA混合存儲(chǔ)引擎而言,CPU只負(fù)責(zé)compaction任務(wù)的生產(chǎn)和調(diào)度,而compaction任務(wù)的實(shí)際執(zhí)行,則被offload到專用硬件(FPGA)上。
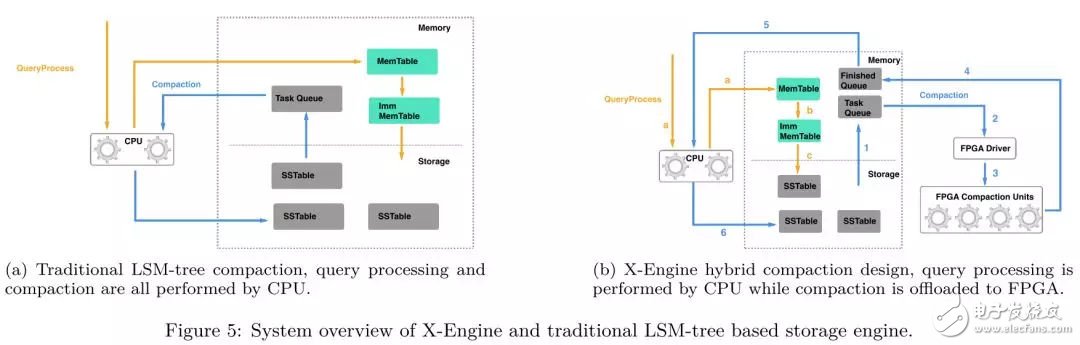
對(duì)于X-Engine,正常用戶請(qǐng)求的處理和其他基于LSM-tree的存儲(chǔ)引擎類似:
用戶提交一個(gè)操作指定KV pair(Get/Insert/Update/Delete)的請(qǐng)求,如果是寫(xiě)操作,一個(gè)新的記錄會(huì)被append到memtable上;
當(dāng)memtable的大小達(dá)到閾值時(shí)會(huì)被轉(zhuǎn)化為immutable memtable;
immutable memtable轉(zhuǎn)化為SSTable并且被flush到持久化存儲(chǔ)上。
當(dāng)L0層的SSTable數(shù)量達(dá)到閾值時(shí),compaction任務(wù)會(huì)被觸發(fā),compaction的offload分為以下幾個(gè)步驟:
從持久化存儲(chǔ)中l(wèi)oad需要compaction的SSTable,CPU通過(guò)meta信息按照data block的粒度拆分成多個(gè)compaction任務(wù),并且為每個(gè)compaction任務(wù)的計(jì)算結(jié)果預(yù)分配內(nèi)存空間,每一個(gè)構(gòu)建好的compaction任務(wù)都會(huì)被壓入到Task Queue隊(duì)列中,等待FPGA執(zhí)行;
CPU讀取FPGA上Compaction Unit的狀態(tài),將Task Queue中的compaction任務(wù)分配到可用的Compaction Unit上;
輸入數(shù)據(jù)通過(guò)DMA傳輸?shù)紽PGA的DDR上;
Compaction Unit執(zhí)行Compaction任務(wù),計(jì)算完成后,結(jié)果通過(guò)DMA回傳給host,并且附帶return code指示此次compaction任務(wù)的狀態(tài)(失敗或者成功),執(zhí)行完的compaction結(jié)果會(huì)被壓入到Finished Queue隊(duì)列中;
CPU檢查Finished Queue中compaction任務(wù)的結(jié)果狀態(tài),如果compaction失敗,該任務(wù)會(huì)被CPU再次執(zhí)行;
compaction的結(jié)果flush到存儲(chǔ)。
詳細(xì)設(shè)計(jì)
FPGA-based Compaction
Compaction Unit (CU) 是FPGA執(zhí)行compaction任務(wù)的基本單元。一個(gè)FPGA板卡內(nèi)可以放置多個(gè)CU,單個(gè)CU由以下幾個(gè)模塊組成:
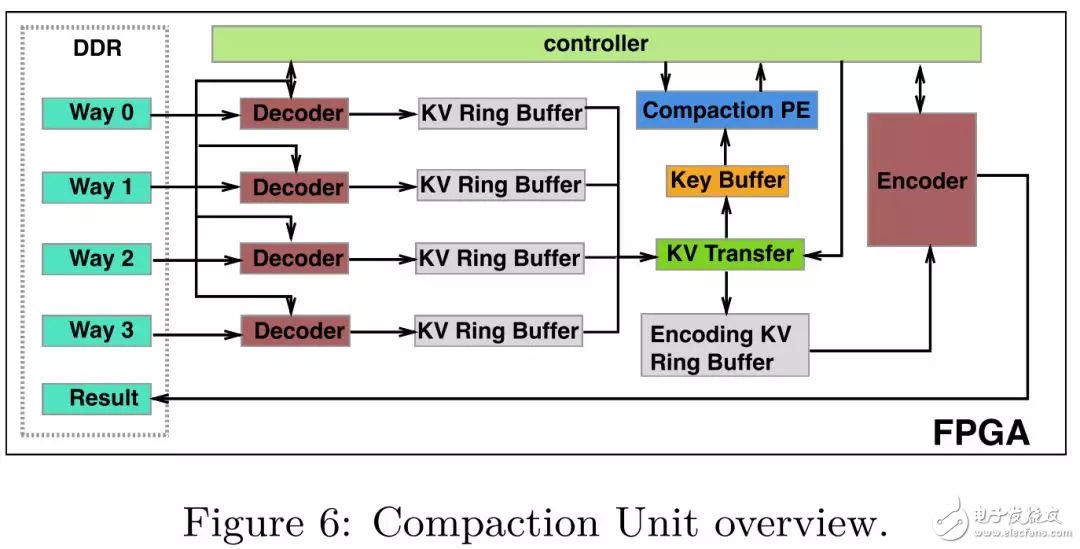
Decoder. 在X-Engine中,KV是經(jīng)過(guò)前序壓縮編碼后存儲(chǔ)在data block中的,Decoder模塊的主要作用是為了解碼鍵值對(duì)。每一個(gè)CU內(nèi)部放置了4個(gè)Decoder,CU最多支持4路的compaction,多余4路的compaction任務(wù)需要CPU進(jìn)行拆分,根據(jù)評(píng)估,大部分的compaction都在4路以下。放置4個(gè)Decoder同樣也是性能和硬件資源權(quán)衡的結(jié)果,和2個(gè)Decoder相比,我們?cè)黾恿?0%的硬件資源消耗,獲得了3倍的性能提升。
KV Ring Buffer. Decoder 模塊解碼后的KV pair都會(huì)暫存在KV Ring Buffer中。每一個(gè)KV Ring Buffer維護(hù)一個(gè)讀指針(由Controller模塊維護(hù))和一個(gè)寫(xiě)指針(由Decoder模塊維護(hù)),KV Ring Buffer 維護(hù)3個(gè)信號(hào)來(lái)指示當(dāng)前的狀態(tài):FLAG_EMPTY, FLAG_HALF_FULL, FLAG_FULL,當(dāng)FLAG_HALF_FULL為低位時(shí),Decoder模塊會(huì)持續(xù)解碼KV pair,否則Decoder會(huì)暫停解碼直到流水線的下游消耗掉已經(jīng)解碼的KV pair。
KV Transfer. 該模塊負(fù)責(zé)將key傳輸?shù)終ey Buffer中,因?yàn)镵V的merge只涉及key值的比較,因此value不需要傳輸,我們通過(guò)讀指針來(lái)追蹤當(dāng)前比較的KV pair。 Key Buffer. 該模塊會(huì)存儲(chǔ)當(dāng)前需要比較的每一路的key,當(dāng)所有需要比較的key都被傳輸?shù)終ey Buffer中,Controller會(huì)通知Compaction PE進(jìn)行比較。
Compaction PE. Compaction Processing Engine (compaction PE)負(fù)責(zé)比較Key Buffer中的key值。比較結(jié)果會(huì)發(fā)送給Controller,Controller會(huì)通知KV Transfer將對(duì)應(yīng)的KV pair傳輸?shù)紼ncoding KV Ring Buffer中,等待Encoder模塊進(jìn)行編碼。
Encoder. Encoder模塊負(fù)責(zé)將Encoding KV Ring Buffer中的KV pair編碼到data block中,如果data block的大小超過(guò)閾值,會(huì)將當(dāng)前的data block flush到DDR中。
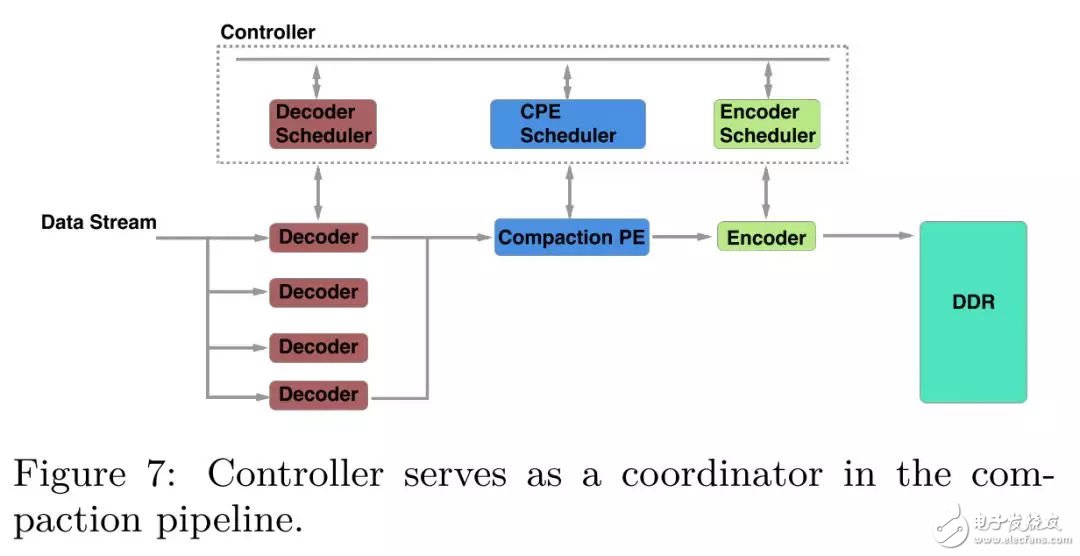
Controller. 在CU中Controller充當(dāng)了一個(gè)協(xié)調(diào)器的作用,雖然Controller不是compaction pipeline的一部分,單在compaction 流水線設(shè)計(jì)的每一個(gè)步驟都發(fā)揮著關(guān)鍵的作用。
一個(gè)compaction過(guò)程包含三個(gè)步驟:decode,merge,encode。設(shè)計(jì)一個(gè)合適的compaction 流水線的最大挑戰(zhàn)在于每一個(gè)步驟的執(zhí)行時(shí)間差距很大。比如說(shuō)由于并行化的原因,decode模塊的吞吐遠(yuǎn)高于encoder模塊,因此,我們需要暫停某些執(zhí)行較快的模塊,等待流水線的下游模塊。為了匹配流水線中各個(gè)模塊的吞吐差異,我們?cè)O(shè)計(jì)了controller模塊去協(xié)調(diào)流水線中的不同步驟,這樣設(shè)計(jì)帶來(lái)的一個(gè)額外好處是解耦了流水線設(shè)計(jì)的各個(gè)模塊,在工程實(shí)現(xiàn)中實(shí)現(xiàn)更敏捷的開(kāi)發(fā)和維護(hù)。
在將FPGA compaction集成到X-Engine中,我們希望可以得到獨(dú)立的CU的吞吐性能,實(shí)驗(yàn)的baseline是CPU單核的compaction線程 (Intel(R) Xeon(R) E5-2682 v4 CPU with 2.5 GHz)
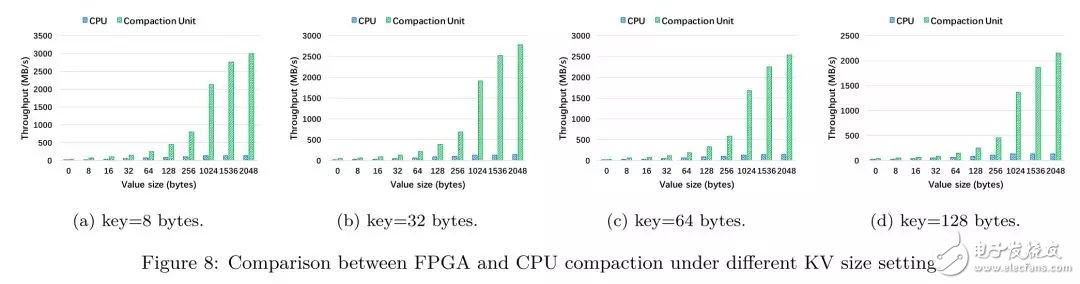
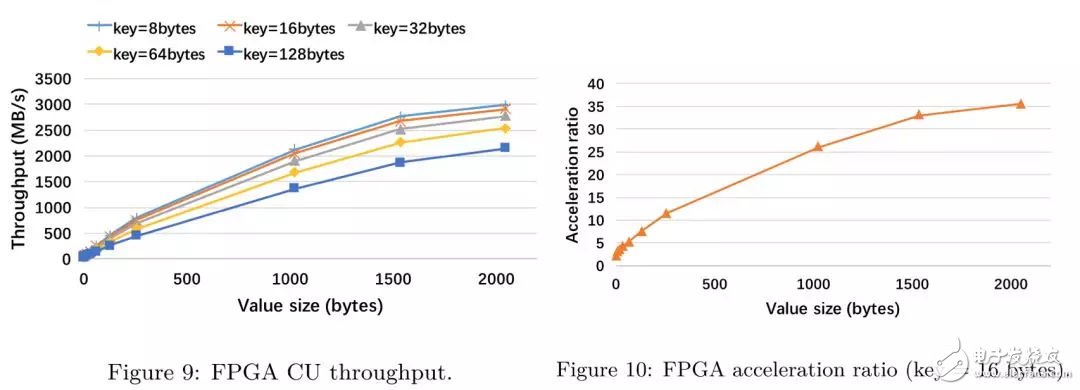
從實(shí)驗(yàn)中我們可以得到以下三個(gè)結(jié)論:
在所有的KV長(zhǎng)度下,F(xiàn)PGA compaction的吞吐都要優(yōu)于CPU單線程的處理能力,這印證了compaction offload的可行性;
隨著key長(zhǎng)度的增長(zhǎng),F(xiàn)PGA compaction的吞吐降低,這是由于需要比較的字節(jié)長(zhǎng)度增加,增加了比較的代價(jià);
加速比(FPGA throughput / CPU throughput)隨著value長(zhǎng)度的增加而增加,這是由于在KV長(zhǎng)度較短時(shí),各個(gè)模塊之間需要頻繁進(jìn)行通信和狀態(tài)檢查,而這種開(kāi)銷和普通的流水線操作相比是非常昂貴的。
異步調(diào)度邏輯設(shè)計(jì)
由于FPGA的一次鏈路請(qǐng)求在ms級(jí)別,因此使用傳統(tǒng)的同步調(diào)度方式會(huì)造成較頻繁的線程切換代價(jià),針對(duì)FPGA的特點(diǎn),我們重新設(shè)計(jì)了異步調(diào)度compaction的方式:CPU負(fù)責(zé)構(gòu)建compaction task并將其壓入Task Queue隊(duì)列,通過(guò)維護(hù)一個(gè)線程池來(lái)分配compaction task到指定的CU上,當(dāng)compaction結(jié)束后,compaction任務(wù)會(huì)被壓入到Finished Queue隊(duì)列,CPU會(huì)檢查任務(wù)執(zhí)行的狀態(tài),對(duì)于執(zhí)行失敗的任務(wù)會(huì)調(diào)度CPU的compaction線程再次執(zhí)行。通過(guò)異步調(diào)度,CPU的線程切換代價(jià)大大減少。
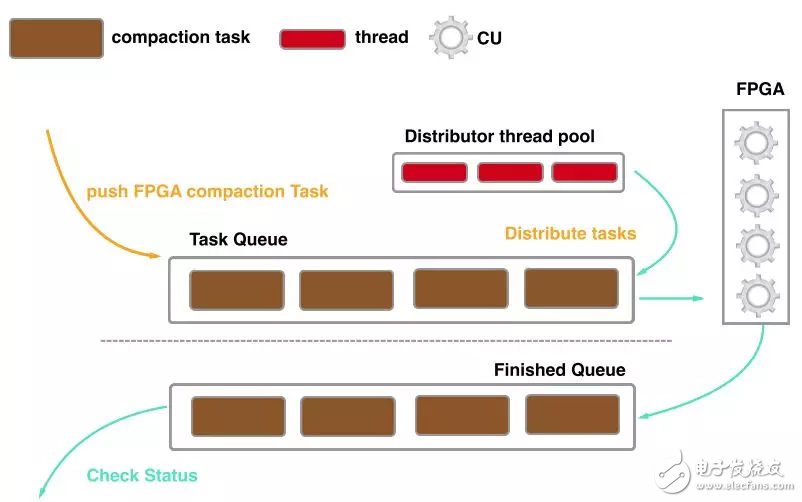
容錯(cuò)機(jī)制的設(shè)計(jì)
對(duì)于FPGA compaction而言,有以下三種原因可能會(huì)導(dǎo)致compaction 任務(wù)出錯(cuò)
數(shù)據(jù)在傳輸過(guò)程中被損壞,通過(guò)在傳輸前和傳輸后分別計(jì)算數(shù)據(jù)的CRC值,然后進(jìn)行比對(duì),如果兩個(gè)CRC值不一致,則表明數(shù)據(jù)被損壞;
FPGA本身的錯(cuò)誤(比特位翻轉(zhuǎn)),為了解決這個(gè)錯(cuò)誤,我們?yōu)槊恳粋€(gè)CU配置了一個(gè)附加CU,兩個(gè)CU的計(jì)算結(jié)果進(jìn)行按位比對(duì),不一致則說(shuō)明發(fā)生了比特位翻轉(zhuǎn)錯(cuò)誤;
compaction輸入數(shù)據(jù)不合法,為了方便FPGA compaction的設(shè)計(jì),我們對(duì)KV的長(zhǎng)度進(jìn)行了限制,超過(guò)限制的compaction任務(wù)都會(huì)被判定為非法任務(wù)。
對(duì)于所有出錯(cuò)的任務(wù),CPU都會(huì)進(jìn)行再次計(jì)算,確保數(shù)據(jù)的正確性。在上述的容錯(cuò)機(jī)制的下,我們解決了少量的超過(guò)限制的compaction任務(wù)并且規(guī)避了FPGA內(nèi)部錯(cuò)誤的風(fēng)險(xiǎn)。
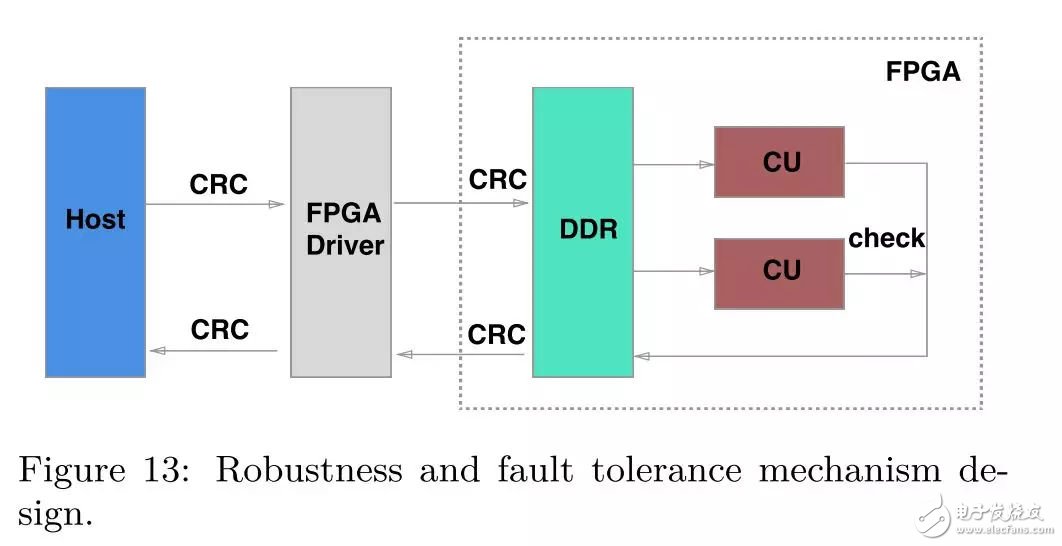
實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)環(huán)境
CPU:64-core Intel (E5-2682 v4, 2.50 GHz) processor
內(nèi)存:128GB
FPGA 板卡:Xilinx VU9P
memtable: 40 GB
block cache 40GB
我們比較兩種存儲(chǔ)引擎的性能:
X-Engine-CPU:compaction操作由CPU執(zhí)行
X-Engine-FPGA:compaction offload到FPGA執(zhí)行
DbBench
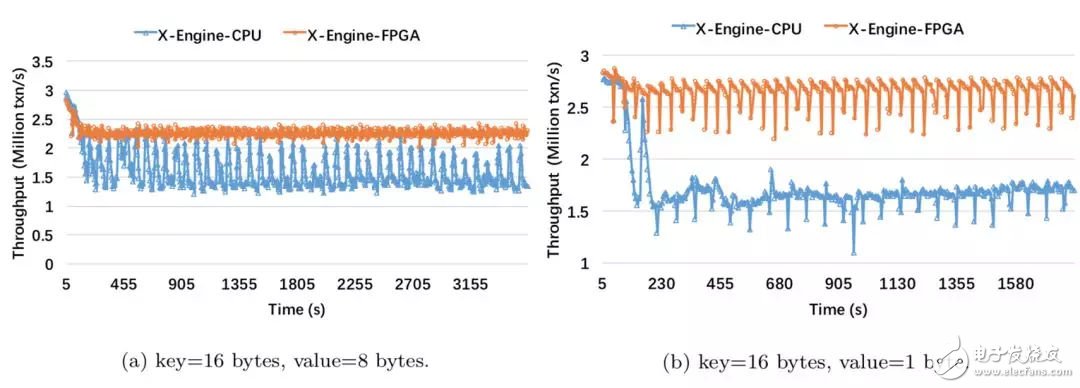
結(jié)果分析:
在write-only場(chǎng)景下,X-Engine-FPGA的吞吐提升了40%,從性能曲線我們可以看出,當(dāng)compaction開(kāi)始時(shí),X-Engine-CPU系統(tǒng)的性能下跌超過(guò)了三分之一;
由于FPGA compaction吞吐更高,更及時(shí),因此讀路徑減少的更快,因此在讀寫(xiě)混合的場(chǎng)景下X-Engine-FPGA的吞吐提高了50%;
讀寫(xiě)混合場(chǎng)景的吞吐小于純寫(xiě)場(chǎng)景,由于讀操作的存在,存儲(chǔ)在持久層的數(shù)據(jù)也會(huì)被訪問(wèn),這就帶來(lái)了I/O開(kāi)銷,從而影響了整體的吞吐性能;
兩種性能曲線代表了兩種不同的compaction狀態(tài),在左圖,系統(tǒng)性能發(fā)生周期性的抖動(dòng),這說(shuō)明compaction操作在和正常事務(wù)處理的線程競(jìng)爭(zhēng)CPU資源;對(duì)于右圖,X-Engine-CPU的性能一直穩(wěn)定在低水位,表明compaction的速度小于寫(xiě)入速度,導(dǎo)致SSTable堆積,compaction任務(wù)持續(xù)在后臺(tái)調(diào)度;
由于compaction的調(diào)度仍然由CPU執(zhí)行,這也就解釋了X-Engine-FPGA仍然存在抖動(dòng),并不是絕對(duì)的平滑。
YCSB
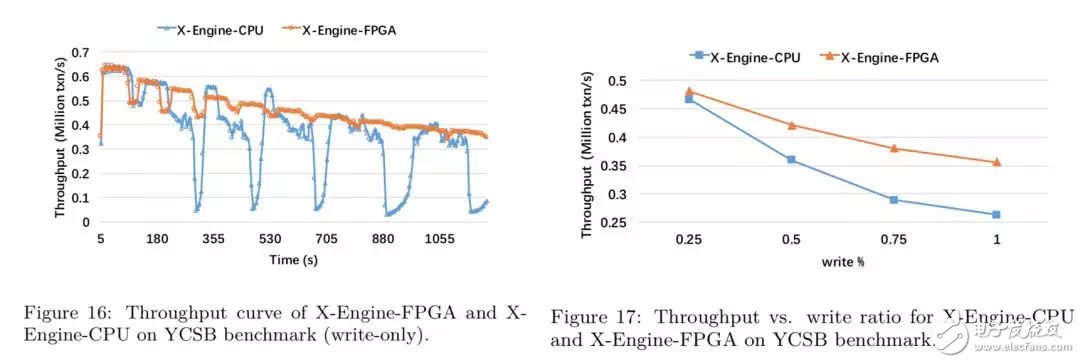
結(jié)果分析:
在YCSB benchmark上,由于compaction的影響,X-Engine-CPU的性能下降了80%左右,而對(duì)于X-Engine-FPGA而言,由于compaction調(diào)度邏輯的影響,X-Engine-FPGA的性能只有20%的浮動(dòng);
check unique的存在引入了讀操作,隨著壓測(cè)時(shí)間的增長(zhǎng),讀路徑變長(zhǎng),因此兩個(gè)存儲(chǔ)引擎的性能隨著時(shí)間下降;
在write-only場(chǎng)景下,X-Engine-FPGA的吞吐提高了40%,隨著讀寫(xiě)比的上升,F(xiàn)PGA Compaction的加速效果逐漸降低,這是因?yàn)樽x寫(xiě)比越高,寫(xiě)入壓力越小,SSTable堆積的速度越慢,因此執(zhí)行compaction的線程數(shù)減少,因此對(duì)于寫(xiě)密集的workload,X-Engine-FPGA的性能提升越明顯;
隨著讀寫(xiě)比的上升,吞吐上升,由于寫(xiě)吞吐小于KV接口,因此cache miss的比例較低,避免了頻繁的I/O操作,而隨著寫(xiě)比例的上升,執(zhí)行compaction線程數(shù)增加,因此降低了系統(tǒng)的吞吐能力。
TPC-C (100 warehouses)
ConnectionsX-Engine-CPU?X-Engine-FPGA
128
214279
240105
256
203268
230401
512
197001
219618
1024
189697
208532
結(jié)果分析:
通過(guò)FPGA加速,隨著連接數(shù)從128增加到1024,X-Engine-FPGA可以得到10%~15%的性能提升。當(dāng)連接數(shù)增加時(shí),兩個(gè)系統(tǒng)的吞吐都逐漸降低,原因在于隨著連接數(shù)增多,熱點(diǎn)行的鎖競(jìng)爭(zhēng)增加;
TPC-C的讀寫(xiě)比是1.8:1,從實(shí)驗(yàn)過(guò)程來(lái)看,在TPC-C benchmark下,80%以上的CPU都消耗在SQL解析和熱點(diǎn)行的鎖競(jìng)爭(zhēng)上,實(shí)際的寫(xiě)入壓力不會(huì)太大,通過(guò)實(shí)驗(yàn)觀測(cè),對(duì)于X-Engine-CPU系統(tǒng),執(zhí)行compaction操作的線程數(shù)不超過(guò)3個(gè) (總共64核心),因此,F(xiàn)PGA的加速效果不如前幾個(gè)實(shí)現(xiàn)明顯。
SysBench
在這個(gè)實(shí)驗(yàn)中我們包含了對(duì)于InnoDB的測(cè)試(buffer size = 80G)
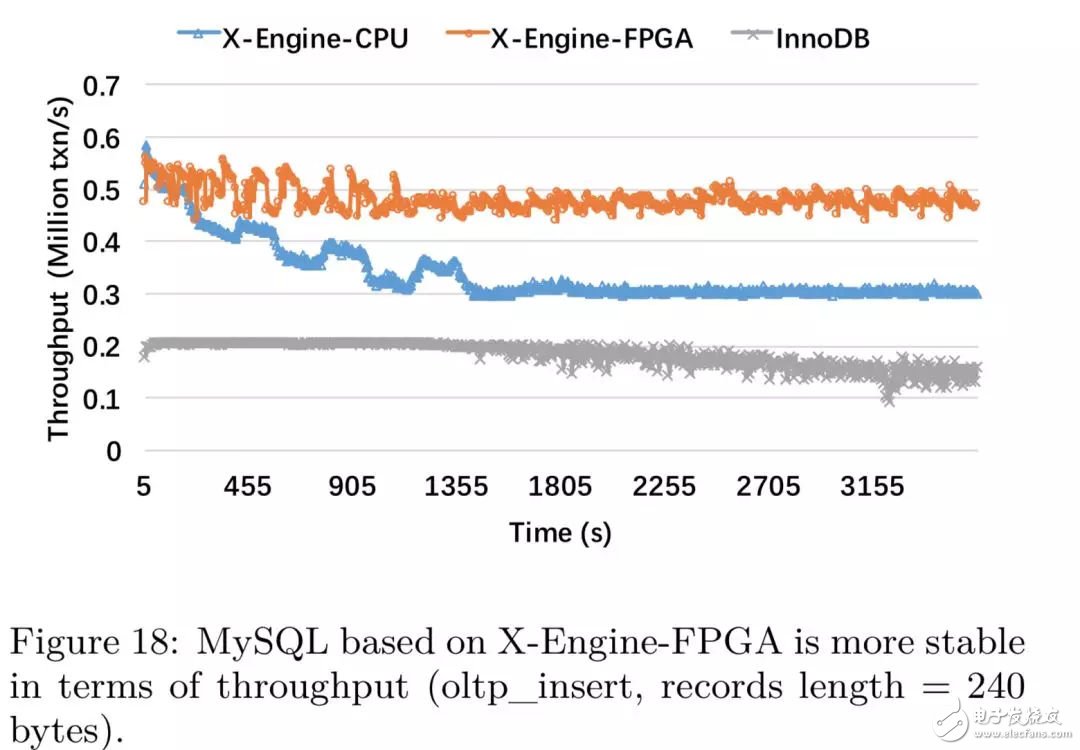
結(jié)果分析:
X-Engine-FPGA提高了40%以上的吞吐性能,由于SQL解析消耗了大量的CPU資源,DBMS的吞吐要小于KV接口;
X-Engine-CPU在低水位達(dá)到了平衡,原因在于compaction的速度小于寫(xiě)入速度,導(dǎo)致SST文件堆積,compaction持續(xù)被調(diào)度;
X-Engine-CPU的性能兩倍于InnoDB,證明了基于LSM-tree的存儲(chǔ)引擎在寫(xiě)密集場(chǎng)景下的優(yōu)勢(shì);
和TPC-C benchmark相比,Sysbench更類似阿里的實(shí)際交易場(chǎng)景,對(duì)于交易系統(tǒng)而言,查詢的類型大部分是插入和簡(jiǎn)單的點(diǎn)查詢,很少涉及范圍查詢,熱點(diǎn)行沖突的減少使得SQL層消耗的資源減少。在實(shí)驗(yàn)過(guò)程中,我們觀測(cè)到對(duì)于X-Engine-CPU而言,超過(guò)15個(gè)線程都在執(zhí)行compaction,因此FPGA加速帶來(lái)的性能提升更加明顯。
總結(jié)
在本文中,我們提出的帶有FPGA加速的X-Engine存儲(chǔ)引擎,對(duì)于KV接口有著50%的性能提升,對(duì)于SQL接口獲得了40%的性能提升。隨著讀寫(xiě)比的降低,F(xiàn)PGA加速的效果越明顯,這也說(shuō)明了FPGA compaction加速適用于寫(xiě)密集的workload,這和LSM-tree的設(shè)計(jì)初衷是一致的,另外,我們通過(guò)設(shè)計(jì)容錯(cuò)機(jī)制來(lái)規(guī)避FPGA本身的缺陷,最終形成了一個(gè)適用于阿里實(shí)際業(yè)務(wù)的高可用的CPU-FPGA混合存儲(chǔ)引擎。






















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論