 電子發燒友App
電子發燒友App


記得我之前在講?圖論算法基礎?時說圖論相關的算法不會經常考,但最近被打臉了,因為一些讀者和我反饋近期求職面試涉及很多圖論相關的算法,可能是因為環境不好所以算法這塊更卷了吧。
常見的圖論算法我都已經寫過了,這里按難度順序列舉一下:
圖論算法基礎
二分圖判定算法及應用
環檢測/拓撲排序算法及應用
并查集算法及應用(本文)
Kruskal 最小生成樹算法及應用
Prim 最小生成樹算法及應用
Dijkstra 算法模板及應用
并查集(Union-Find)算法是一個專門針對「動態連通性」的算法,我之前寫過兩次,因為這個算法的考察頻率高,而且它也是最小生成樹算法的前置知識,所以我整合了本文,爭取一篇文章把這個算法講明白。
首先,從什么是圖的動態連通性開始講。
一、動態連通性
簡單說,動態連通性其實可以抽象成給一幅圖連線。比如下面這幅圖,總共有 10 個節點,他們互不相連,分別用 0~9 標記:
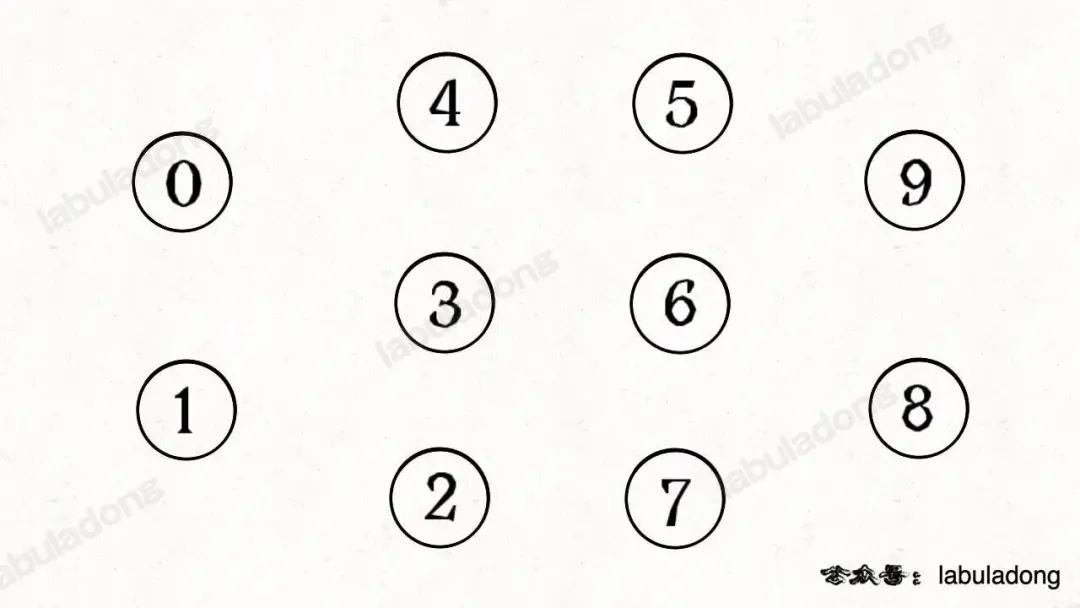
現在我們的 Union-Find 算法主要需要實現這兩個 API:
class?UF?{
????/*?將?p?和?q?連接?*/
????public?void?union(int?p,?int?q);
????/*?判斷?p?和?q?是否連通?*/
????public?boolean?connected(int?p,?int?q);
????/*?返回圖中有多少個連通分量?*/
????public?int?count();
}
?
?
這里所說的「連通」是一種等價關系,也就是說具有如下三個性質:
1、自反性:節點p和p是連通的。
2、對稱性:如果節點p和q連通,那么q和p也連通。
3、傳遞性:如果節點p和q連通,q和r連通,那么p和r也連通。
比如說之前那幅圖,0~9 任意兩個不同的點都不連通,調用connected都會返回 false,連通分量為 10 個。
如果現在調用union(0, 1),那么 0 和 1 被連通,連通分量降為 9 個。
再調用union(1, 2),這時 0,1,2 都被連通,調用connected(0, 2)也會返回 true,連通分量變為 8 個。
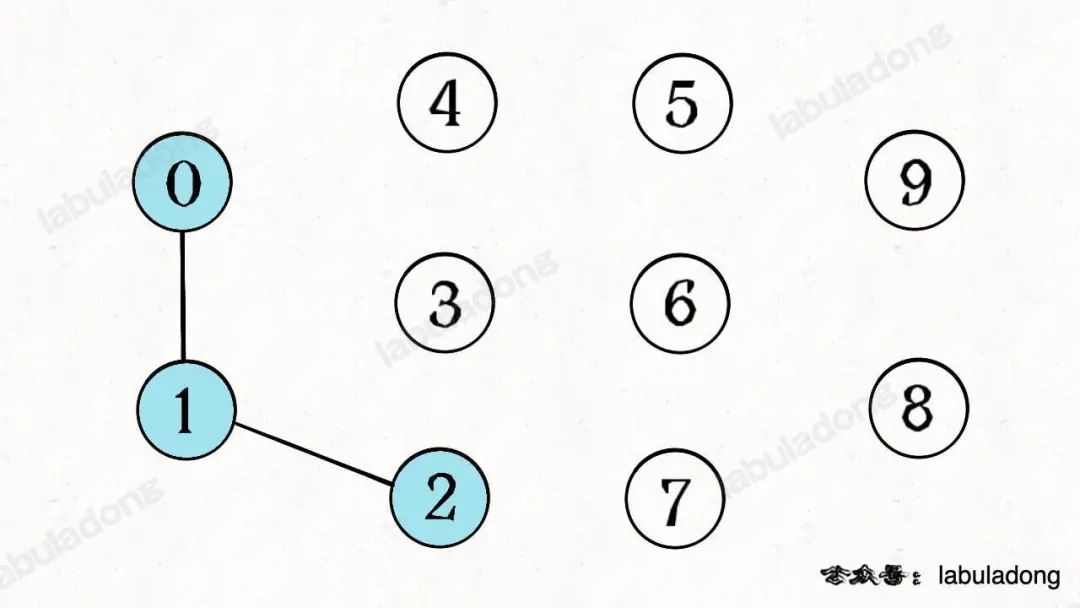
判斷這種「等價關系」非常實用,比如說編譯器判斷同一個變量的不同引用,比如社交網絡中的朋友圈計算等等。
這樣,你應該大概明白什么是動態連通性了,Union-Find 算法的關鍵就在于union和connected函數的效率。那么用什么模型來表示這幅圖的連通狀態呢?用什么數據結構來實現代碼呢?
二、基本思路
注意我剛才把「模型」和具體的「數據結構」分開說,這么做是有原因的。因為我們使用森林(若干棵樹)來表示圖的動態連通性,用數組來具體實現這個森林。
怎么用森林來表示連通性呢?我們設定樹的每個節點有一個指針指向其父節點,如果是根節點的話,這個指針指向自己。比如說剛才那幅 10 個節點的圖,一開始的時候沒有相互連通,就是這樣:
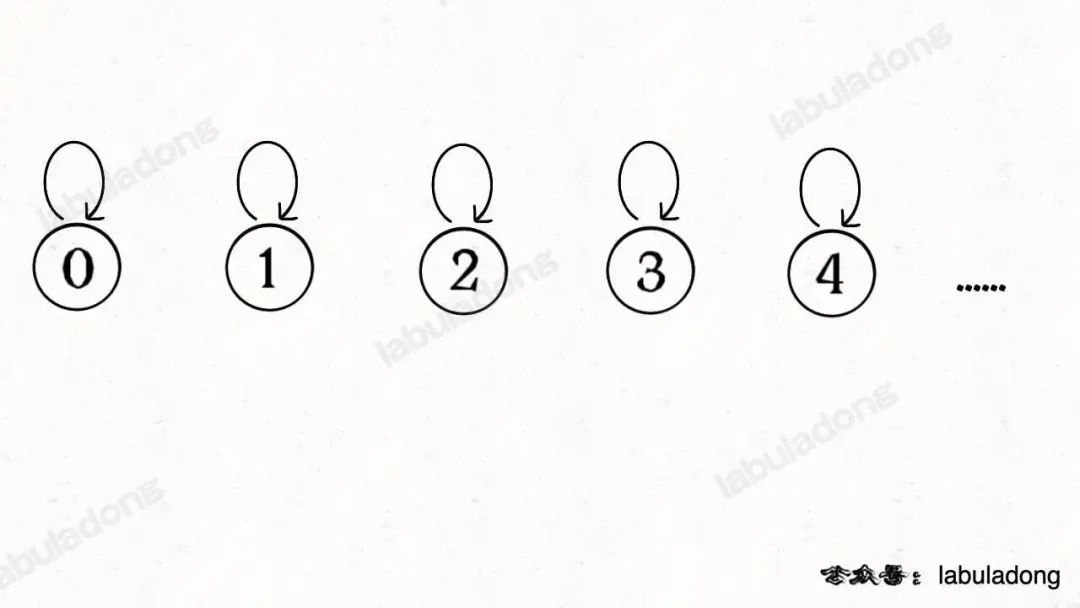
?
class?UF?{
????//?記錄連通分量
????private?int?count;
????//?節點?x?的父節點是?parent[x]
????private?int[]?parent;
????/*?構造函數,n?為圖的節點總數?*/
????public?UF(int?n)?{
????????//?一開始互不連通
????????this.count?=?n;
????????//?父節點指針初始指向自己
????????parent?=?new?int[n];
????????for?(int?i?=?0;?i?
如果某兩個節點被連通,則讓其中的(任意)一個節點的根節點接到另一個節點的根節點上:
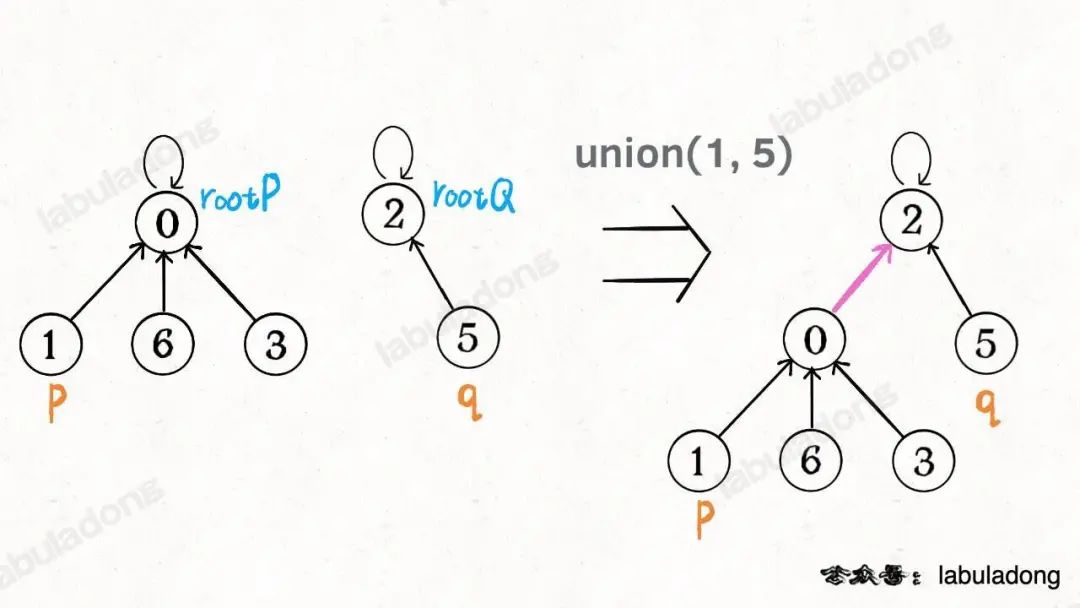
?
public?void?union(int?p,?int?q)?{
????int?rootP?=?find(p);
????int?rootQ?=?find(q);
????if?(rootP?==?rootQ)
????????return;
????//?將兩棵樹合并為一棵
????parent[rootP]?=?rootQ;
????//?parent[rootQ]?=?rootP?也一樣
????count--;?//?兩個分量合二為一
}
/*?返回某個節點?x?的根節點?*/
private?int?find(int?x)?{
????//?根節點的?parent[x]?==?x
????while?(parent[x]?!=?x)
????????x?=?parent[x];
????return?x;
}
/*?返回當前的連通分量個數?*/
public?int?count()?{?
????return?count;
}
?
?
這樣,如果節點p和q連通的話,它們一定擁有相同的根節點:
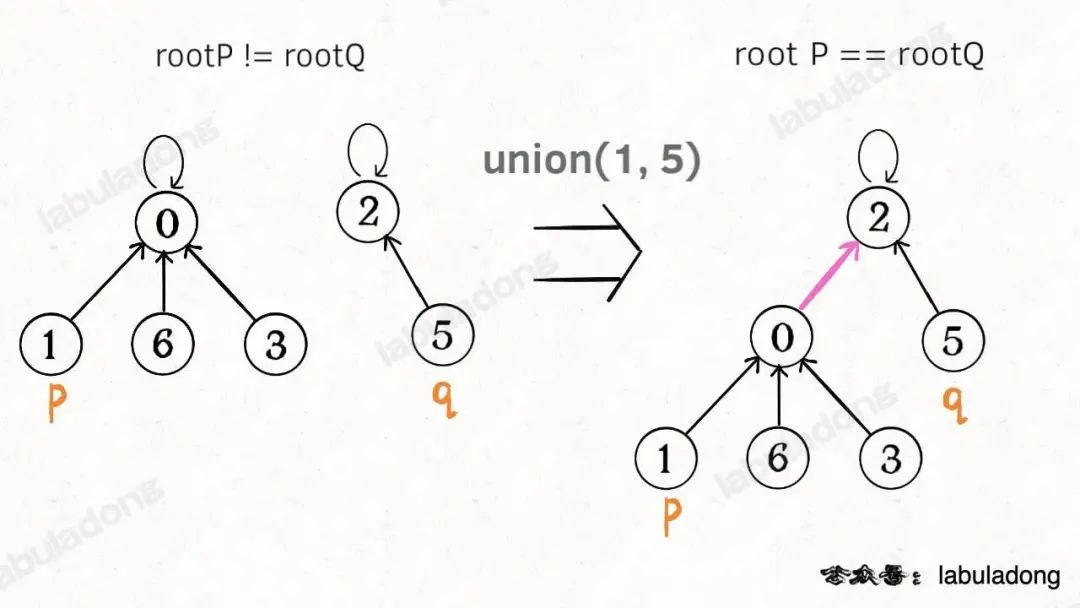
?
public?boolean?connected(int?p,?int?q)?{
????int?rootP?=?find(p);
????int?rootQ?=?find(q);
????return?rootP?==?rootQ;
}
至此,Union-Find 算法就基本完成了。是不是很神奇?竟然可以這樣使用數組來模擬出一個森林,如此巧妙的解決這個比較復雜的問題!
那么這個算法的復雜度是多少呢?我們發現,主要 APIconnected和union中的復雜度都是find函數造成的,所以說它們的復雜度和find一樣。
find主要功能就是從某個節點向上遍歷到樹根,其時間復雜度就是樹的高度。我們可能習慣性地認為樹的高度就是logN,但這并不一定。logN的高度只存在于平衡二叉樹,對于一般的樹可能出現極端不平衡的情況,使得「樹」幾乎退化成「鏈表」,樹的高度最壞情況下可能變成?N。
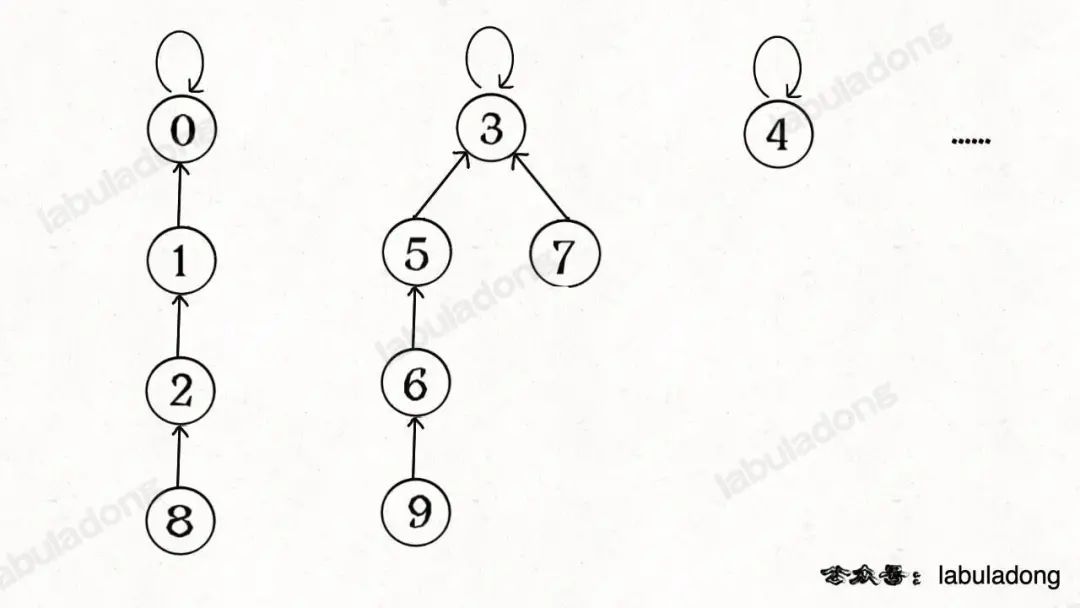
所以說上面這種解法,find,union,connected的時間復雜度都是 O(N)。這個復雜度很不理想的,你想圖論解決的都是諸如社交網絡這樣數據規模巨大的問題,對于union和connected的調用非常頻繁,每次調用需要線性時間完全不可忍受。
問題的關鍵在于,如何想辦法避免樹的不平衡呢?只需要略施小計即可。
三、平衡性優化
我們要知道哪種情況下可能出現不平衡現象,關鍵在于union過程:
public?void?union(int?p,?int?q)?{
????int?rootP?=?find(p);
????int?rootQ?=?find(q);
????if?(rootP?==?rootQ)
????????return;
????//?將兩棵樹合并為一棵
????parent[rootP]?=?rootQ;
????//?parent[rootQ]?=?rootP?也可以
????count--;
?
?
我們一開始就是簡單粗暴的把p所在的樹接到q所在的樹的根節點下面,那么這里就可能出現「頭重腳輕」的不平衡狀況,比如下面這種局面:
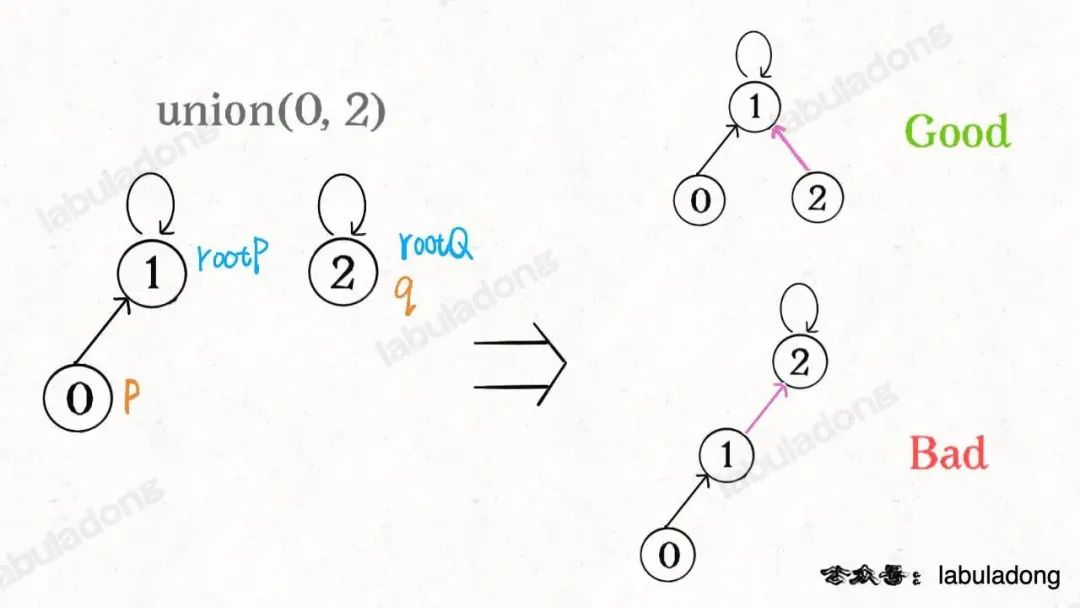
長此以往,樹可能生長得很不平衡。我們其實是希望,小一些的樹接到大一些的樹下面,這樣就能避免頭重腳輕,更平衡一些。解決方法是額外使用一個size數組,記錄每棵樹包含的節點數,我們不妨稱為「重量」:
class?UF?{
????private?int?count;
????private?int[]?parent;
????//?新增一個數組記錄樹的“重量”
????private?int[]?size;
????public?UF(int?n)?{
????????this.count?=?n;
????????parent?=?new?int[n];
????????//?最初每棵樹只有一個節點
????????//?重量應該初始化?1
????????size?=?new?int[n];
????????for?(int?i?=?0;?i?
?
?
比如說size[3] = 5表示,以節點3為根的那棵樹,總共有5個節點。這樣我們可以修改一下union方法:
?
?
public?void?union(int?p,?int?q)?{
????int?rootP?=?find(p);
????int?rootQ?=?find(q);
????if?(rootP?==?rootQ)
????????return;
????//?小樹接到大樹下面,較平衡
????if?(size[rootP]?>?size[rootQ])?{
????????parent[rootQ]?=?rootP;
????????size[rootP]?+=?size[rootQ];
????}?else?{
????????parent[rootP]?=?rootQ;
????????size[rootQ]?+=?size[rootP];
????}
????count--;
}
?
?
這樣,通過比較樹的重量,就可以保證樹的生長相對平衡,樹的高度大致在logN這個數量級,極大提升執行效率。
此時,find,union,connected的時間復雜度都下降為 O(logN),即便數據規模上億,所需時間也非常少。
四、路徑壓縮
這步優化雖然代碼很簡單,但原理非常巧妙。
其實我們并不在乎每棵樹的結構長什么樣,只在乎根節點。
因為無論樹長啥樣,樹上的每個節點的根節點都是相同的,所以能不能進一步壓縮每棵樹的高度,使樹高始終保持為常數?

這樣每個節點的父節點就是整棵樹的根節點,find就能以 O(1) 的時間找到某一節點的根節點,相應的,connected和union復雜度都下降為 O(1)。
要做到這一點主要是修改find函數邏輯,非常簡單,但你可能會看到兩種不同的寫法。
第一種是在find中加一行代碼:
?
?
private?int?find(int?x)?{
????while?(parent[x]?!=?x)?{
????????//?這行代碼進行路徑壓縮
????????parent[x]?=?parent[parent[x]];
????????x?=?parent[x];
????}
????return?x;
}
?
?
這個操作有點匪夷所思,看個 GIF 就明白它的作用了(為清晰起見,這棵樹比較極端):
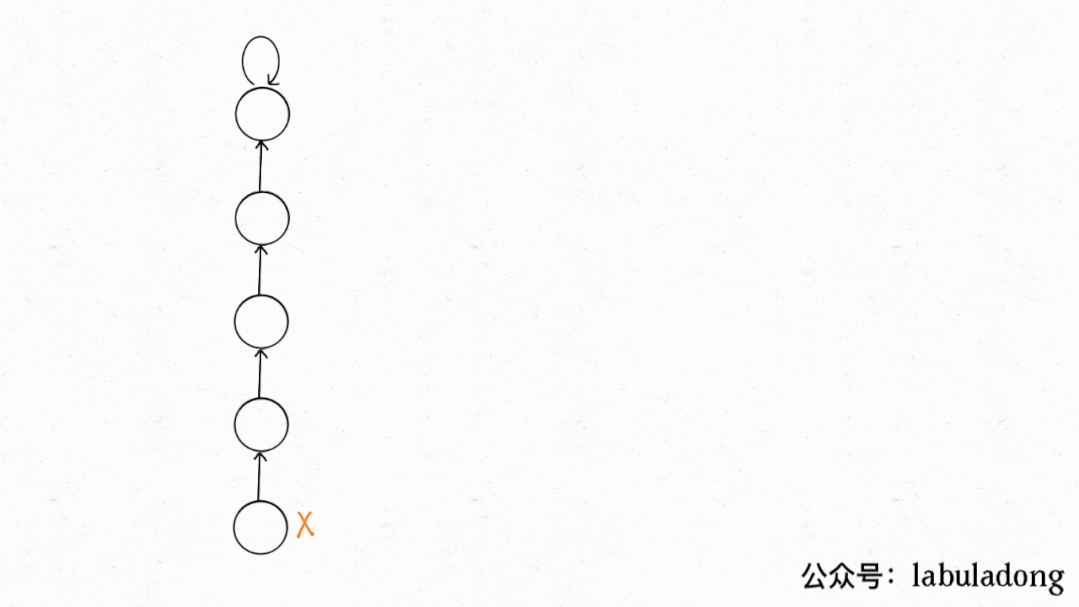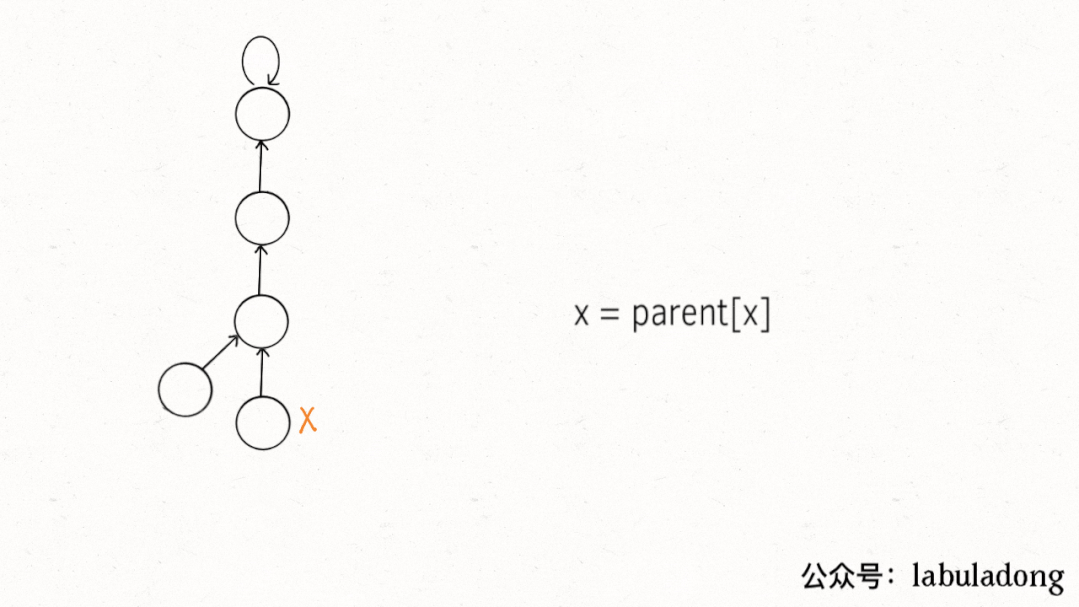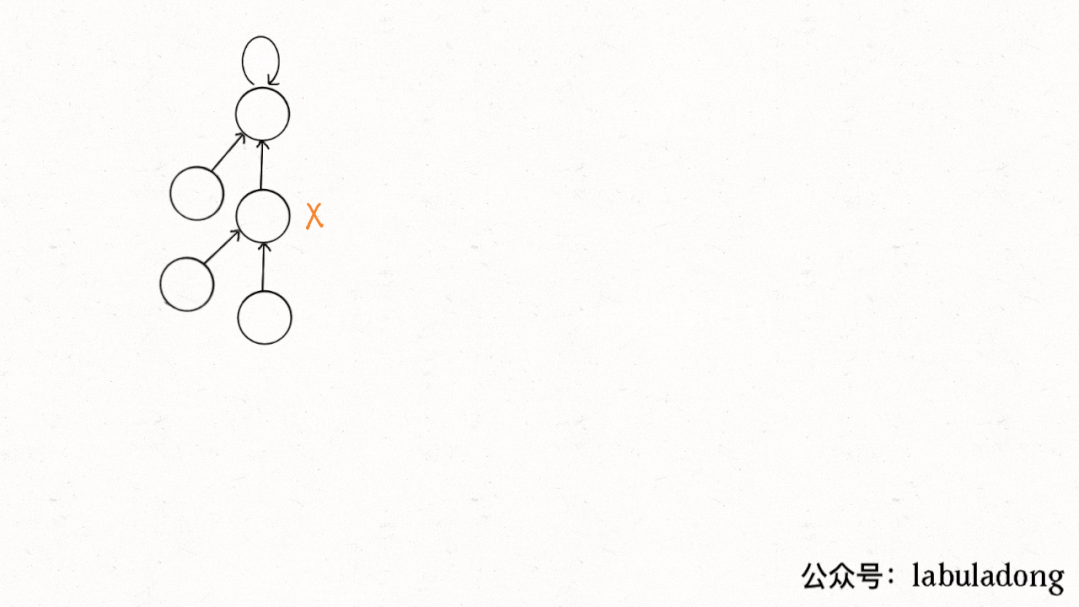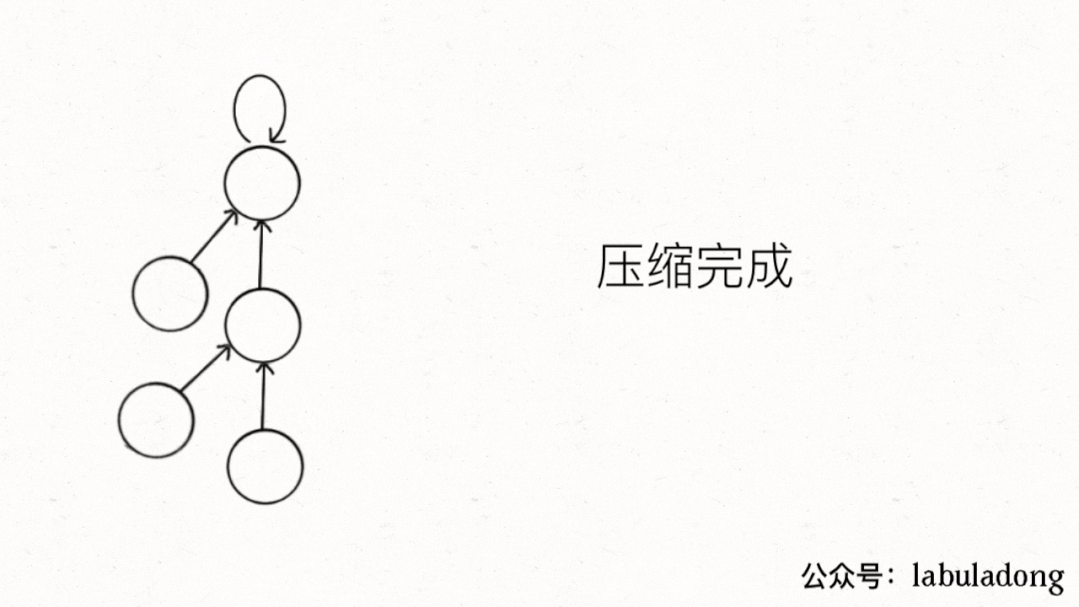
用語言描述就是,每次 while 循環都會把一對兒父子節點改到同一層,這樣每次調用find函數向樹根遍歷的同時,順手就將樹高縮短了。
路徑壓縮的第二種寫法是這樣:
?
?
//?第二種路徑壓縮的?find?方法
public?int?find(int?x)?{
????if?(parent[x]?!=?x)?{
????????parent[x]?=?find(parent[x]);
????}
????return?parent[x];
}
?
?
我一度認為這種遞歸寫法和第一種迭代寫法做的事情一樣,但實際上是我大意了,有讀者指出這種寫法進行路徑壓縮的效率是高于上一種解法的。
這個遞歸過程有點不好理解,你可以自己手畫一下遞歸過程。我把這個函數做的事情翻譯成迭代形式,方便你理解它進行路徑壓縮的原理:
?
?
//?這段迭代代碼方便你理解遞歸代碼所做的事情
public?int?find(int?x)?{
????//?先找到根節點
????int?root?=?x;
????while?(parent[root]?!=?root)?{
????????root?=?parent[root];
????}
????//?然后把?x?到根節點之間的所有節點直接接到根節點下面
????int?old_parent?=?parent[x];
????while?(x?!=?root)?{
????????parent[x]?=?root;
????????x?=?old_parent;
????????old_parent?=?parent[old_parent];
????}
????return?root;
}
?
?
這種路徑壓縮的效果如下:
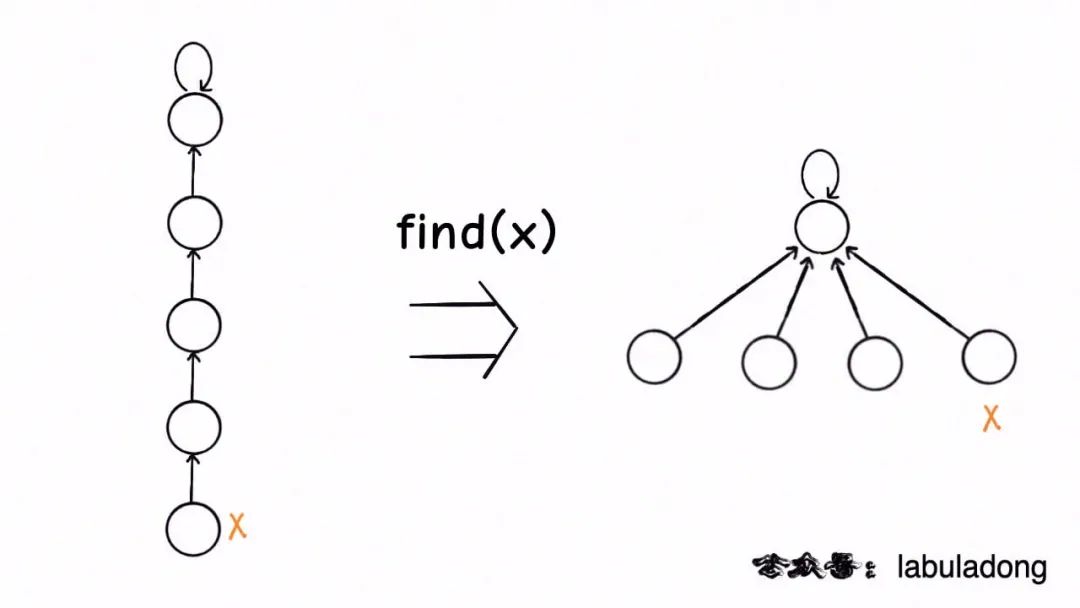
比起第一種路徑壓縮,顯然這種方法壓縮得更徹底,直接把一整條樹枝壓平,一點意外都沒有。就算一些極端情況下產生了一棵比較高的樹,只要一次路徑壓縮就能大幅降低樹高,從?攤還分析?的角度來看,所有操作的平均時間復雜度依然是 O(1),所以從效率的角度來說,推薦你使用這種路徑壓縮算法。
另外,如果使用路徑壓縮技巧,那么size數組的平衡優化就不是特別必要了。所以你一般看到的 Union Find 算法應該是如下實現:
?
?
class?UF?{
????//?連通分量個數
????private?int?count;
????//?存儲每個節點的父節點
????private?int[]?parent;
????//?n?為圖中節點的個數
????public?UF(int?n)?{
????????this.count?=?n;
????????parent?=?new?int[n];
????????for?(int?i?=?0;?i?
?
?
Union-Find 算法的復雜度可以這樣分析:構造函數初始化數據結構需要 O(N) 的時間和空間復雜度;連通兩個節點union、判斷兩個節點的連通性connected、計算連通分量count所需的時間復雜度均為 O(1)。
到這里,相信你已經掌握了 Union-Find 算法的核心邏輯,總結一下我們優化算法的過程:
1、用parent數組記錄每個節點的父節點,相當于指向父節點的指針,所以parent數組內實際存儲著一個森林(若干棵多叉樹)。
2、用size數組記錄著每棵樹的重量,目的是讓union后樹依然擁有平衡性,保證各個 API 時間復雜度為 O(logN),而不會退化成鏈表影響操作效率。
3、在find函數中進行路徑壓縮,保證任意樹的高度保持在常數,使得各個 API 時間復雜度為 O(1)。使用了路徑壓縮之后,可以不使用size數組的平衡優化。
下面我們看一些具體的并查集題目。
題目實踐
力扣第 323 題「無向圖中連通分量的數目」就是最基本的連通分量題目:
給你輸入一個包含n個節點的圖,用一個整數n和一個數組edges表示,其中edges[i] = [ai, bi]表示圖中節點ai和bi之間有一條邊。請你計算這幅圖的連通分量個數。
函數簽名如下:
?
?
int?countComponents(int?n,?int[][]?edges)
?
?
這道題我們可以直接套用UF類來解決:
?
?
public?int?countComponents(int?n,?int[][]?edges)?{
????UF?uf?=?new?UF(n);
????//?將每個節點進行連通
????for?(int[]?e?:?edges)?{
????????uf.union(e[0],?e[1]);
????}
????//?返回連通分量的個數
????return?uf.count();
}
class?UF?{
????//?見上文
}
?
?
另外,一些使用 DFS 深度優先算法解決的問題,也可以用 Union-Find 算法解決。
比如力扣第 130 題「被圍繞的區域」:
給你一個 M×N 的二維矩陣,其中包含字符X和O,讓你找到矩陣中四面被X圍住的O,并且把它們替換成X。
?
?
void?solve(char[][]?board);
?
?
注意哦,必須是四面被圍的O才能被換成X,也就是說邊角上的O一定不會被圍,進一步,與邊角上的O相連的O也不會被X圍四面,也不會被替換。
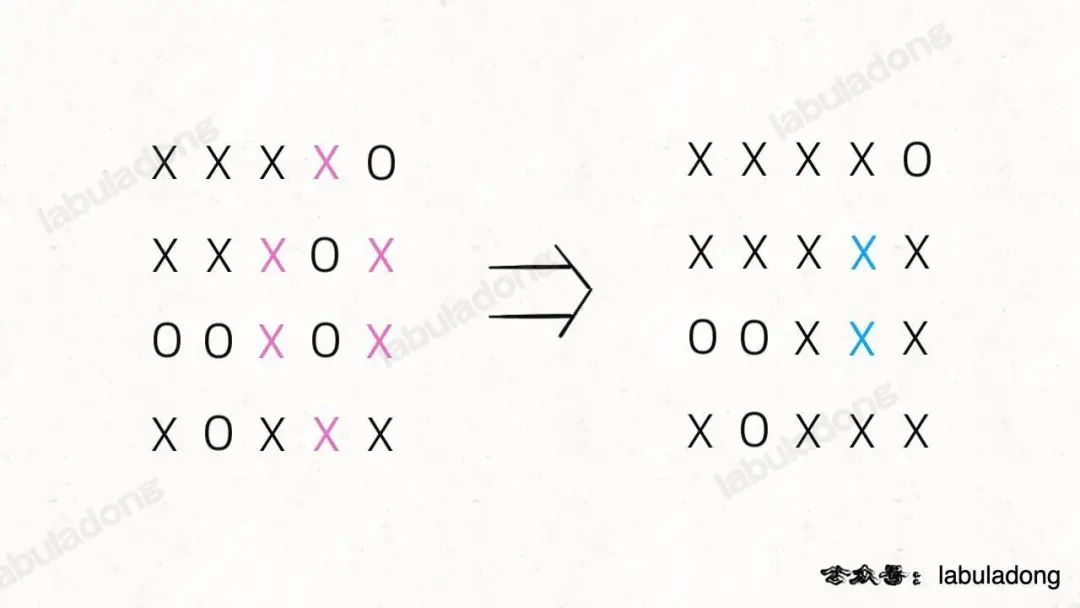
PS:這讓我想起小時候玩的棋類游戲「黑白棋」,只要你用兩個棋子把對方的棋子夾在中間,對方的子就被替換成你的子。可見,占據四角的棋子是無敵的,與其相連的邊棋子也是無敵的(無法被夾掉)。
其實這個問題應該歸為?島嶼系列問題?使用 DFS 算法解決:
先用 for 循環遍歷棋盤的四邊,用 DFS 算法把那些與邊界相連的O換成一個特殊字符,比如#;然后再遍歷整個棋盤,把剩下的O換成X,把#恢復成O。這樣就能完成題目的要求,時間復雜度 O(MN)。
但這個問題也可以用 Union-Find 算法解決,雖然實現復雜一些,甚至效率也略低,但這是使用 Union-Find 算法的通用思想,值得一學。
你可以把那些不需要被替換的O看成一個擁有獨門絕技的門派,它們有一個共同「祖師爺」叫dummy,這些O和dummy互相連通,而那些需要被替換的O與dummy不連通。
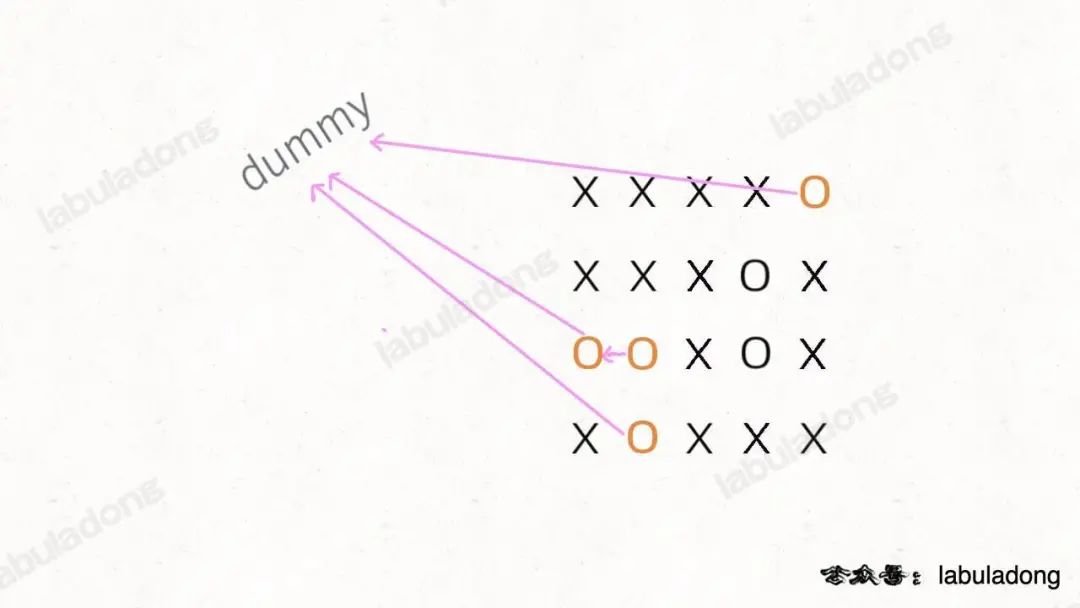
這就是 Union-Find 的核心思路,明白這個圖,就很容易看懂代碼了。
首先要解決的是,根據我們的實現,Union-Find 底層用的是一維數組,構造函數需要傳入這個數組的大小,而題目給的是一個二維棋盤。
這個很簡單,二維坐標(x,y)可以轉換成x * n + y這個數(m是棋盤的行數,n是棋盤的列數),敲黑板,這是將二維坐標映射到一維的常用技巧。
其次,我們之前描述的「祖師爺」是虛構的,需要給他老人家留個位置。索引[0.. m*n-1]都是棋盤內坐標的一維映射,那就讓這個虛擬的dummy節點占據索引m * n好了。
看解法代碼:
?
?
void?solve(char[][]?board)?{
????if?(board.length?==?0)?return;
????int?m?=?board.length;
????int?n?=?board[0].length;
????//?給?dummy?留一個額外位置
????UF?uf?=?new?UF(m?*?n?+?1);
????int?dummy?=?m?*?n;
????//?將首列和末列的?O?與?dummy?連通
????for?(int?i?=?0;?i?
?
?
這段代碼很長,其實就是剛才的思路實現,只有和邊界O相連的O才具有和dummy的連通性,他們不會被替換。
其實用 Union-Find 算法解決這個簡單的問題有點殺雞用牛刀,它可以解決更復雜,更具有技巧性的問題,主要思路是適時增加虛擬節點,想辦法讓元素「分門別類」,建立動態連通關系。
力扣第 990 題「等式方程的可滿足性」用 Union-Find 算法就顯得十分優美了,題目是這樣:
給你一個數組equations,裝著若干字符串表示的算式。每個算式equations[i]長度都是 4,而且只有這兩種情況:a==b或者a!=b,其中a,b可以是任意小寫字母。你寫一個算法,如果equations中所有算式都不會互相沖突,返回 true,否則返回 false。
比如說,輸入["a==b","b!=c","c==a"],算法返回 false,因為這三個算式不可能同時正確。
再比如,輸入["c==c","b==d","x!=z"],算法返回 true,因為這三個算式并不會造成邏輯沖突。
我們前文說過,動態連通性其實就是一種等價關系,具有「自反性」「傳遞性」和「對稱性」,其實==關系也是一種等價關系,具有這些性質。所以這個問題用 Union-Find 算法就很自然。
核心思想是,將equations中的算式根據==和!=分成兩部分,先處理==算式,使得他們通過相等關系各自勾結成門派(連通分量);然后處理!=算式,檢查不等關系是否破壞了相等關系的連通性。
?
?
boolean?equationsPossible(String[]?equations)?{
????//?26?個英文字母
????UF?uf?=?new?UF(26);
????//?先讓相等的字母形成連通分量
????for?(String?eq?:?equations)?{
????????if?(eq.charAt(1)?==?'=')?{
????????????char?x?=?eq.charAt(0);
????????????char?y?=?eq.charAt(3);
????????????uf.union(x?-?'a',?y?-?'a');
????????}
????}
????//?檢查不等關系是否打破相等關系的連通性
????for?(String?eq?:?equations)?{
????????if?(eq.charAt(1)?==?'!')?{
????????????char?x?=?eq.charAt(0);
????????????char?y?=?eq.charAt(3);
????????????//?如果相等關系成立,就是邏輯沖突
????????????if?(uf.connected(x?-?'a',?y?-?'a'))
????????????????return?false;
????????}
????}
????return?true;
}
class?UF?{
????//?見上文
}
?
?
至此,這道判斷算式合法性的問題就解決了,借助 Union-Find 算法,是不是很簡單呢?
最后,Union-Find 算法也會在一些其他經典圖論算法中用到,比如判斷「圖」和「樹」,以及最小生成樹的計算,詳情見?Kruskal 最小生成樹算法。
編輯:黃飛
?











 工商網監
工商網監
評論