 電子發燒友App
電子發燒友App


要:?阿里云在和很多企業交流的過程中發現他們在使用MaxCompute的時候往往會遇到一些成本相關的問題,而在與客戶不但交流溝通的過程中,阿里云在成本優化方面也積累了大量的經驗,因此也希望能夠將這些經驗沉淀下來分享給更多的企業和開發者,本文就將與大家分享幫助企業做好MaxCompute成本優化的“四步走”戰略。
摘要:阿里云在和很多企業交流的過程中發現他們在使用MaxCompute的時候往往會遇到一些成本相關的問題,而在與客戶不但交流溝通的過程中,阿里云在成本優化方面也積累了大量的經驗,因此也希望能夠將這些經驗沉淀下來分享給更多的企業和開發者,本文就將與大家分享幫助企業做好MaxCompute成本優化的“四步走”戰略。
以下內容根據演講視頻以及PPT整理而成。
本次演講視頻分享,請戳這里!
本次演講PPT下載,請戳這里!
關于MaxCompute更多精彩文章,請移步云棲社區MaxCompute公眾號!
對于MaxCompute的成本優化而言,它絕對不是一次性的任務,而應該是持續不斷的。其實,可以將企業MaxCompute的成本優化分為四個主要的方面:正確預估、健康度定制、成本追蹤以及成本優化。首先,需要對于企業的服務規模進行預估;其次,需要做好企業資產的健康度規范的制定,就像傳統企業在進行開發時需要制定的開發規范一樣,為了保障成本不會產生更多的開銷,因此需要制定健康度規范;再次,除了企業資產健康度的制定之外,還需要進行成本的追蹤,比如消耗的追蹤以及用量的追蹤,企業需要采用一些手段以及工具來發現異常的賬單或者異常的費用;在本文的最后,也會與大家分享在真正的企業實戰中能夠使用的一些優化技巧。
一、如何做出正確的預估?
MaxCompute的計費策略
其實MaxCompute提供了兩種計費方式,第一種是預付費,第二種是后付費。預付費的計算資源是包月或者包年的,想當于每個CU 150元每個月,它的存儲和下載是按量后付費的。而后付費的方式則是按照存儲進行階梯定價的,基礎價格是0.0192元/GB/天起步;在計算部分,對于SQL而言,需要通過IO輸入量乘以復雜度然0.3元/GB,對于MR而言,它的計費則是按照CPU計算時計算的,每個計算時是0.46元。對于下載而言,則是按照公網下行0.8元/GB計算的,內網下行流量則是不收費的。

MaxCompute的服務選型
而阿里云的一些客戶經常會問到他們到底是選擇包月預付費,還是應該選擇按量后付費的問題。那么,企業究竟應該如何正確地做好服務選型呢?這其實也是非常關鍵的一件事情。
阿里云為用戶提供了兩種選型工具:TCO工具和成本預估實踐。對于TCO工具而言,在阿里云官網上MaxCompute產品的首頁是有一個價格計算器的。對于預付費方式而言,用戶可通過輸入自己想要的數據規模以及想要的計算資源自動地計算所需要的月成本。對于后付費方式而言,阿里云則提供了CostSQL方法,用戶可以將自己的數據放到MaxCompute上面計算Cost,當然了這里并不是真實的計算,而是進行預估,這樣就可以大致計算出用戶所需的費用。
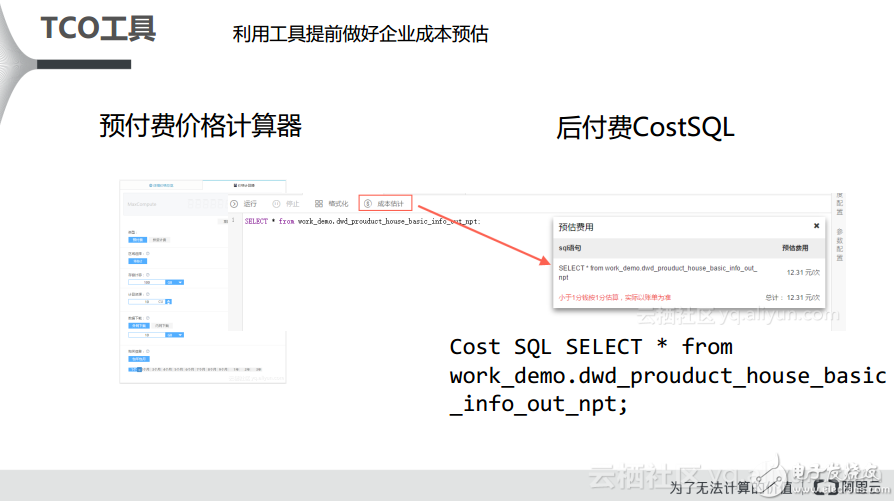
此外,阿里云還提供了一種選型工具,就是成本預估實踐。在這里也為大家分享一些成本預估的技巧,比如一個案例就是某一個企業需要處理1TB數據,到底這1TB數據應該購買后付費還是預付費。在當時,阿里云給用戶提出了兩個建議,一種是密集型計算,另外一種叫做密集型存儲,區別就是前者對于CPU資源的要求比較高。阿里云曾經自己做過相關的測試,對于預付費密集型計算而言,相當于使用160CU資源跑了1TB數據,大概能夠達到分鐘級別的相應速度,這樣一個月的資源相當于使用了2.4萬元的開銷。如果企業對于計算的響應時間要求不高,那么阿里云還是推薦用戶使用預付費密集型存儲,大概會使用到50CU左右,一個月的開銷大約在7500元左右,但是其的響應時間是小時級別的。如果用戶選擇后付費,按照基礎的復雜度也就是1來計算,對于1TB的數據的開銷大約是300元每天,那么一個月就應該是大約9000多元,當然這是單次計算,因為預付費是包年包月的,而后付費則是按照次數計費的,如果多次進行1TB數據的計算,那么其開銷也會成倍增加。以上這些可以供企業進行參考。其實,阿里云建議對于剛開始上云的企業而言,可以先開通后付費,然后將數據放到后付費里面去做POC測試,看看自己的任務大概需要消耗多少Worker,通過Worker數就能推算出CU數量,這樣就能大概估算出最終需要購買資源的數量,這也是一個經驗技巧。

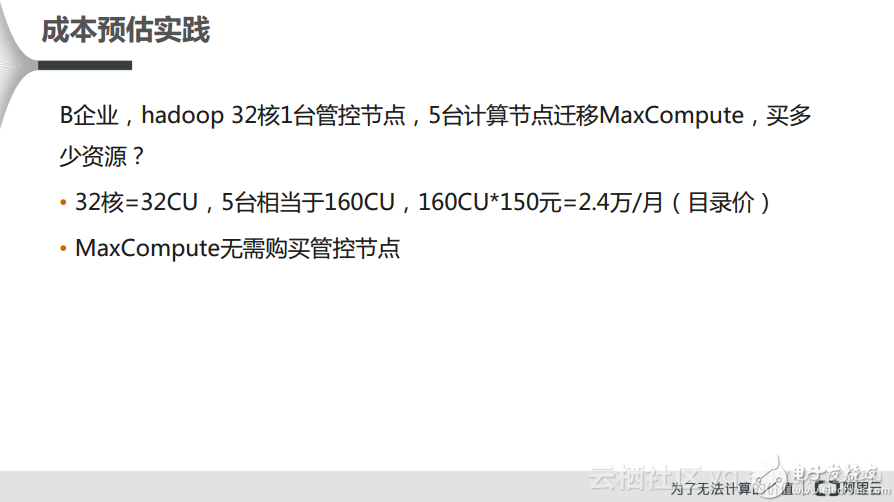
此外,一些Hadoop用戶也希望做上云遷移,那么他們到底需要購買多少資源呢?舉例而言,某個Hadoop集群可能有1個管控節點以及5臺計算節點,每臺機器32核,也就相當于是32個CPU,那么5臺計算節點就是160個CPU,這樣計算下來就相當于是每個月2.4萬的這樣的目錄價,也就是標準的官方報價,也就是沒有計算任何折扣或者優惠的價格,而實際上對于MaxCompute而言,在阿里云上定期會有一些折扣活動。
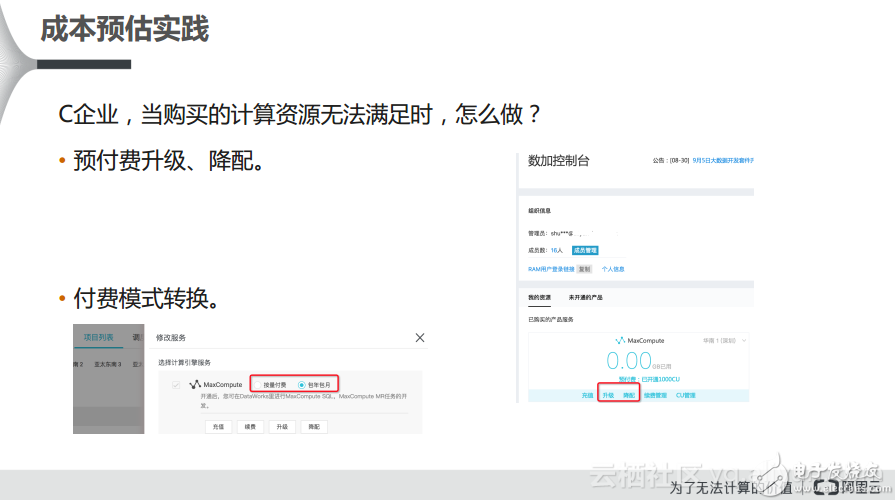
另外一點,就是當用戶選擇了MaxCompute之后,無需考慮管控節點,這樣一來就節省了管控節點的費用。還有MaxCompute比Hive性能快80%,且免運維,又節省了至少一倍的成本。此外,一旦企業選擇了預付費的服務,發現購買了50CU,但是不夠使用,比如因為業務突然增長導致數據量也突然變大了,而此時企業可以非常方便地選擇MaxCompute提供的數加服務,用戶可以非常容易地進行升配或者降配的工作,此外還可以進行付費方式的轉換,可以從預付費轉成后付費,也可以從后付費轉換成預付費,這些都是非常方便的,能夠幫助用戶靈活地選擇和轉變付費方式。
二、健康度制定
在本文的第一節中,為大家分享了企業如何做好上云的預估。在上云之后,企業要做的就需要制定相應的規范了,但是這樣的規范并不能與傳統的開發規范混為一談。在這一節里面,主要與大家分享成本企業資產的健康度規范,當有了這套規范之后,企業中的開發小組就能夠更好地約束ETL工程師以及數據分析師等的開銷,這樣只有在團隊中每個人身上都培養起節約成本的文化,企業的資產才能做好優化。對于資產健康度而言,主要分為兩部分:計算和存儲,MaxCompute的主要資源消耗也就是產生在計算和存儲兩部分上。
計算健康度
這里為企業計算健康度提供了一些參考,當然了具體如何計算還是需要根據企業具體的規模、投入資源以及自身情況制定。對于計算健康度而言,可以將其作為百分制計算。如果出現了數據傾斜、全表暴力掃描以及相似計算等不良的SQL可以對于健康度進行扣分,而這些扣分項是最終要定位到責任人的,這樣團隊成員才會不斷地優化自己的SQL以及開發習慣,這樣一來整體的SQL計算效率會提高,成本也會相應地下降。

存儲健康度
對于存儲健康度而言,同樣可以采用百分制,企業可以對于不經常使用到數據表,比如一些廢棄表、空表以及未管理表等進行約束或者規范。

三、成本追蹤
在分享完企業資產健康度規范的制定之后,接下來為大家分享如何追蹤成本的消耗。因為很多企業在使用MaxCompute有時候會發現一些異常賬單,因此這一部分也將與大家分享一些企業自查的方法,其實自查方法也是比較簡單的,其實企業不用通過阿里云的幫助也能夠自己完成。
成本管理工具
阿里云為企業提供了三個成本管理工具:賬單明細,大家可以在阿里云的費用中心看到;使用記錄,也就是阿里內部叫做OMS的東西,它會記錄每條SQL的使用記錄,復雜度、計量時間以及一天24小時的存儲情況和下行流量等明細記錄;命令行工具,用戶可以通過命令行工具還原用戶的操作,可以還原出用戶當時使用的SQL到底是怎么樣的,如何產生了所謂的“貴SQL”。
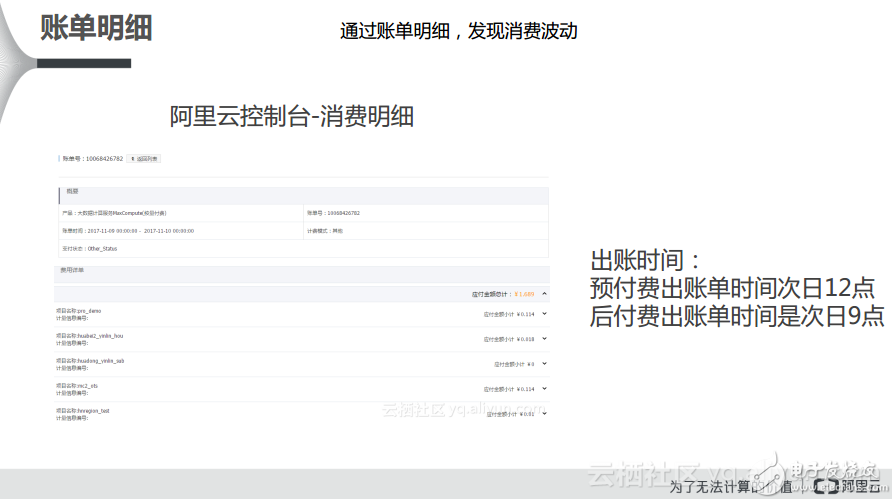
1) 賬單明細
對于賬單明細而言,預付費大概的出賬時間是在次日的12點左右,后付費的出賬時間是次日的9點左右,所以如果大家關心自己的賬單就可以等到第二天相應的時間段到阿里云的消費中心看自己的消費明細。
2) 使用記錄
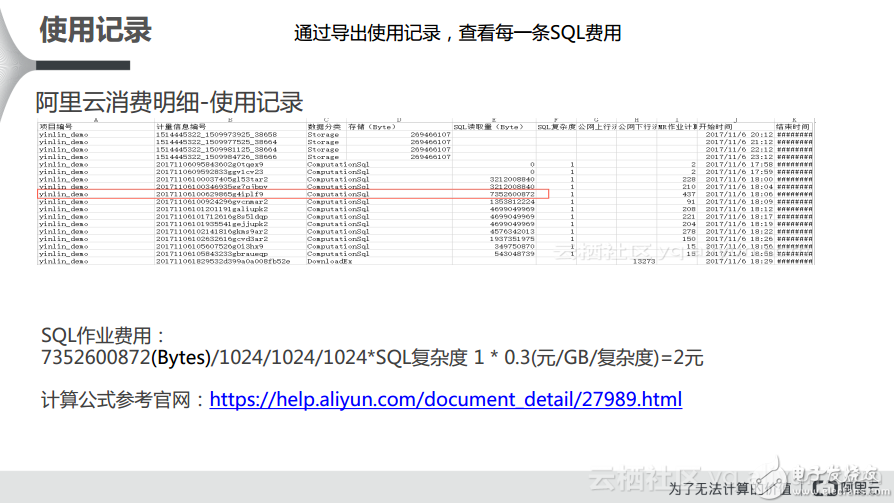
當用戶在自己的賬單里面發現某一個Project的計費可能突然在某一天達到了幾千元,可能是平常賬單的多倍,這樣的異常就需要關注,因此就需要去探查它的明細,這時候就需要去阿里云內部的使用記錄里面查看。如果是后付費的用戶則可以導出后付費的使用記錄,如下圖所示的就是一張阿里云消費明細的使用記錄,它是一張Excel表格的形式,這里面有每個SQL的InstanceID,也就是用戶Job任務的ID,通過這個ID可以借助一些還原工具來反查InstanceID對應的SQL到底是什么。大家可以看到,在下圖中標紅的是異常情況非常明顯的SQL量,雖然絕對數字僅有2元,但是相對而言比平常的數據高了很多,這也就是異常的賬單。那么如何看使用記錄呢?其實大家可以重點看幾項,ComputationSQL數據分類下數據的讀取量以及SQL的復雜度是比較關鍵的信息,用SQL的讀取量轉換成GB乘以復雜度,再乘以0.3就是出賬的金額。其實通過這個公式反推一下也能夠很容易地獲得消費明細。
對于存儲費用而言,相當于1天有24次,按照小時推送計量信息。計算存儲價格時需要將字節數相加并做一個24小時的平均值,取出來之后再按照階梯定價的公式進行計算最終得到存儲價格。在下圖中標紅的部分指的是結束時間,之所以標記這個區域是因為天的計量信息是以每一條任務的結束時間為準,也就是如果某條任務的結束時間是第二天凌晨,那么這條任務的計量時間就會計入第二天,不會計入第一天,這也是大家在做計量處理的時候需要注意的細節。

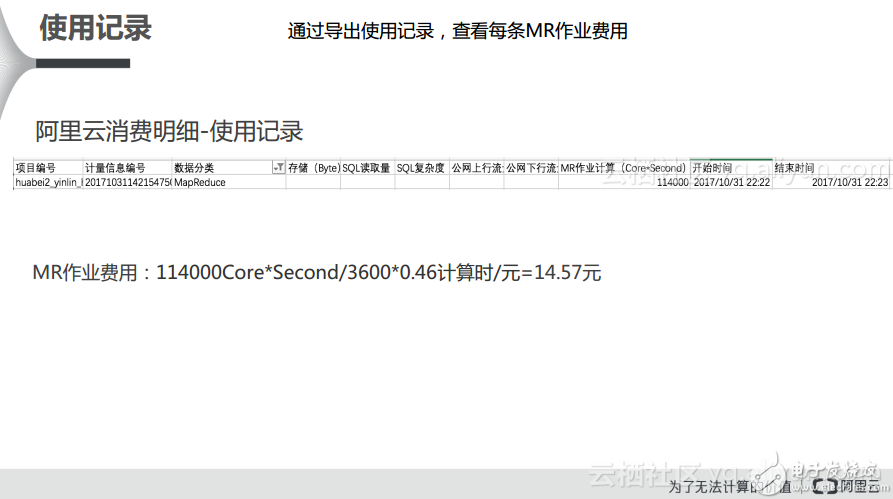
對于MR部分,首先有一個數據分類是MapReduce,其次對于MR作業的費用計算有這樣的一個Core*Second這樣的一個類,因為其精確到秒級,所以需要轉換成小時級別,因此需要除以3600并乘以標準計價0.46,這樣就能夠得到MR使用記錄的開銷。
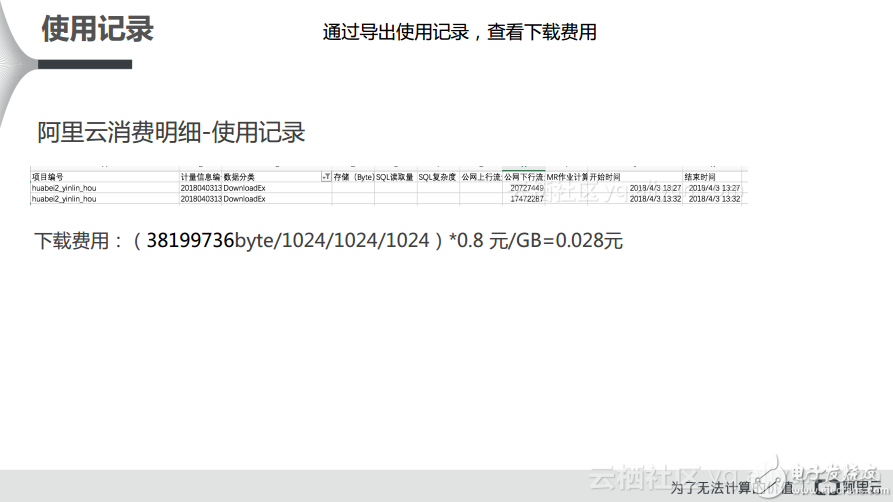
對于下載費用而言,其實它的計算比較簡單。內網也就是經典網絡的下行流量是不收費的,上行也是不收費的。只有走公網的時候,下行流量才會計費,在數據分類中有一個DownloadEx,這就對應了下行的數據量,將其轉化成GB并乘以0.8元/GB,這樣就可以得到下載明細了。
3) 命令行
當發現所謂的“貴SQL”的時候,應該如何還原它呢?因為當我們看到instid以及jobid并不能具有太多的感知和感覺,因此需要一些工具來介入進行SQL還原。這里有幾個常用的方法,第一個就是當拿到instid的時候直接使用wait命令來獲取logview,也就是獲取SQL的詳細日志,并將logview打印出來看一下當時究竟進行了什么樣的SQL處理。還有一種方法就是“desc instance instid”,這種方法更為直接,可以直接將SQL顯示在控制臺里面,這兩種方法都可以幫助用戶更好地還原SQL信息。而第一種獲取logview需要注意目前存在一個關于時間周期的問題,可能目前只能獲取大約1周7天之內的logview信息,更早的信息或許是無法獲得的。
四、成本優化
分享完成本追溯或者說是開銷的查看之后,接下來和大家分享在公共云上針對于企業所遇到的一些“貴SQL”或者“貴存儲”問題的優化技巧。
計算作業
對于計算作業而言,遇到最多的問題可能就是全表掃描,大部分企業公有云的“貴SQL”都是由全表掃描引起的。還有一個比較典型的問題就是新手因為頻繁調度引起“貴SQL”,因為調度頻繁就可能會產生任務的堆積,在后付費的情況下會造成排隊現象,如果任務多又出現了排隊,那么異常賬單會出現在第二天,所以可能令人感覺當天沒有問題,然而第二天就發現問題很大。
1)?? ?控制全表掃描
在控制全表掃描部分的優化策略將重點論述幾個關鍵點。第一點就是養成加分區列的習慣,這樣可以幫助我們降低數據規模。預付費的模式可能不需要太多考慮IO問題和計算資源以及成本問題,但是預付費同樣也會遇到另外一個問題,就是如果開發習慣不夠好,那么就會引起性能的問題,這就可能會導致預付費大排隊,其他的資源都在等待,同樣會影響到企業的開發效率。第二點就是在進行Join的時候,一定要先做分區裁剪在做Join,不然的話就可能會先做全表掃描。最后還有一種方法來控制全表掃描,就是阿里云最近推出的對于全表掃描的開關,其可以做到Session級別也可以做到Project級別,阿里云更加推薦使用Project級別的開關,運維的同學可以將這個開關打開來禁止全表掃描,如此就能有效地幫助企業控制成本。

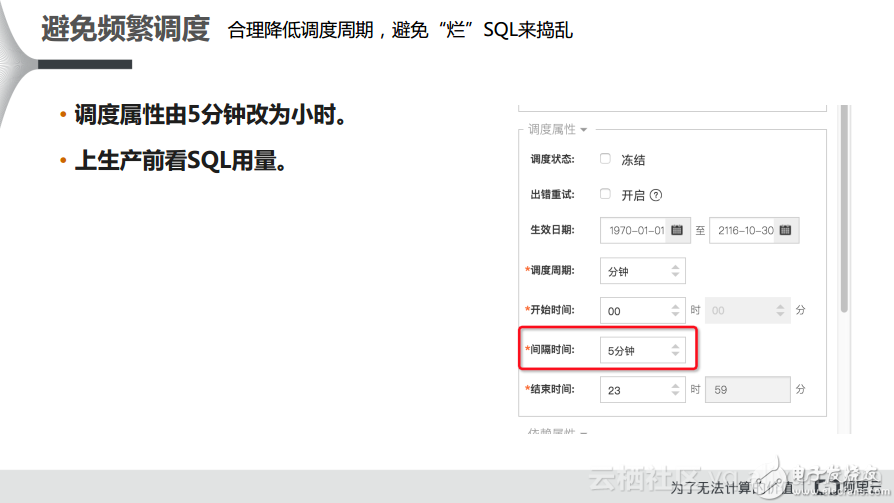
2)?? ?避免頻繁調度
大家經常會遇到調度周期修改得比較頻繁的情況,因為MaxCompute是批量計算的服務,雖然MaxCompute一直在向實時計算的方向上不斷演進,但是其距離實時的計算服務還是存在一定距離的。因此間隔時間變短,計算頻率的增加,再加上SQL的不良習慣或者較差的健康度就會導致計算費用飆升,也就會產生異常的貴賬單。所以在企業做頻繁調度之前一定要通過CostSQL等方式預估一下SQL的開銷到底有多大,當大家心里真正有底才能上到生產環境運行,不然會造成較大的開銷。
存儲
對于存儲而言,這里有三個主要的關鍵點。第一個關鍵點就是要合理地進行數據分區;其次,要合理地設置表的生命周期;最后要定期地刪除廢表。
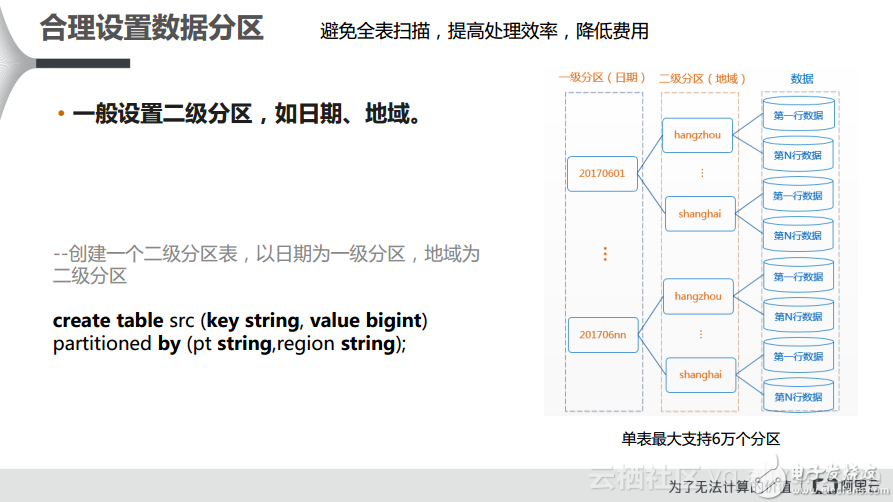
1)?? ?合理設置數據分區
對于MaxCompute而言,首先要設置數據分區,讓數據更好地分組。其實每個分區都可以認為是一個目錄,那么就可以按照目錄進行數據分組就好了。一般而言,推薦使用二級分區。因為最大的單表也就支持6萬個分區,分區過多也會影響分區數。所以,對于企業而言,首先需要學會做分區,其次一般而言做二級分區就可以了。可以通過日期,比如天和小時,或者地域和城市實現二級分區,這樣基本上就可以滿足業務需求。
2)?? ?設置合理的生命周期
很多時候,大家會發現在自己的數倉里面,很多的表都是臨時表。對于臨時表而言,如果最初不加生命周期,那么管理起來就會很困難,所以建議對于臨時表加上生命周期,比如一個月。當過了設定的生命周期之后,系統就會自動地將臨時表刪除掉,同時也實現了企業存儲空間的節省以及費用的下降。

3)?? ?刪除訪問跨度大的廢表
最后一點就是定期地刪除訪問跨度大的廢表,所謂訪問跨度大就是長期不會訪問的表,對于這些表需要作出定期的清理,因為這些表的意義并不大,因此一定要做好資產的管理和表的管理。

以上就是關于企業MaxCompute成本優化的實踐的分享,更多精彩的分享也會在云棲社區不斷更新,希望大家持續關注。
本文為云棲社區原創內容,未經允許不得轉載。


























 工商網監
工商網監
評論