 電子發燒友App
電子發燒友App


塊I/O流程與 I/O調度器
- 一個塊IO的一生:從page cache到bio 到 request
- 塊設備層的數據結構
- page和bio的關系,request 和bio的關系
- O_DIRECT 和O_SYNC
- blktrace , ftrace
- IO調度和CFQ調度算法
- CFQ和ionice
- cgroup與IO
- io性能測試: iotop, iostat
主要內容:從應用程序發起一次IO行為,最終怎么到磁盤,以及在這個路徑上有什么trace的方法和 配置。每次應用程序寫磁盤,都是到pagecache 。三進三出 講解 bio的一生,都是在pagecache以下。
首先,在一次普通的sys_write過程中,會觸發以下的函數調用。
sys_write -> vfs_write -> generic_file_write_iter
PageCache: Linux通過局部性原理,使用頁面緩存提高性能。
1) generic_perform_write -> write_begin -> copy_data ->write_end
generic_perform_write: 開始pagecache的寫入過程
write_begin: 在內存空間中準備對應index需要的page。
例如: ext4_write_begin 中包含
grab_cache_page_write_begin : 查獲取一個緩存頁或者創建一個緩存頁。
-> page_cache_get_page: 從mapping的radix tree中查找緩存頁,假如不存在,則從伙伴系統中申請一個新頁插入,并添加到LRU鏈表中。
ext4_write_end 首先調用__block_commit_write提交寫入的數據,
通過set_buffer_uptodate :
-> mark_buffer_dirty -> set_buffer_dirty/ set_page_dirty/ set_inode_dirty 將該頁設臟,
通過wb_wakeup_delayed把writeback任務提交到bdi_writeback隊列中。
DirectIO:
2) generic_file_direct_write -> filemap_write_and_write_range -> mapping-> a_ops-> direct_IO
如果是buffer IO , 臟頁回寫是異步的,并且由塊設備層負責。
對于新版本的內核,ext4注冊的方法是new_sync_write
sys_write -> vfs_write -> __vfs_write -> new_sync_write
-> filp->f_op->write_iter -> ext4_file_write_iter
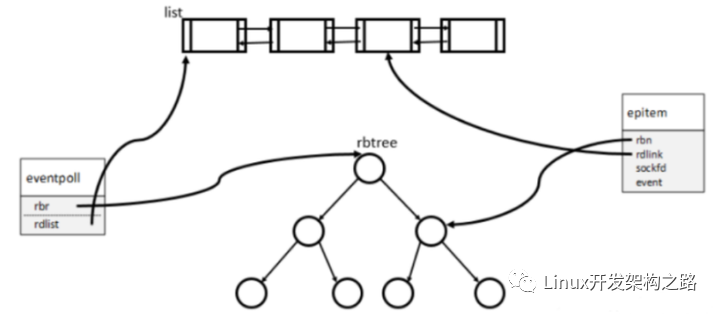
塊設備層的數據結構
struct page -> struct inode -> struct bio -> struct request
真正開始做IO之前,即操作block子系統之前,包括以下步驟:
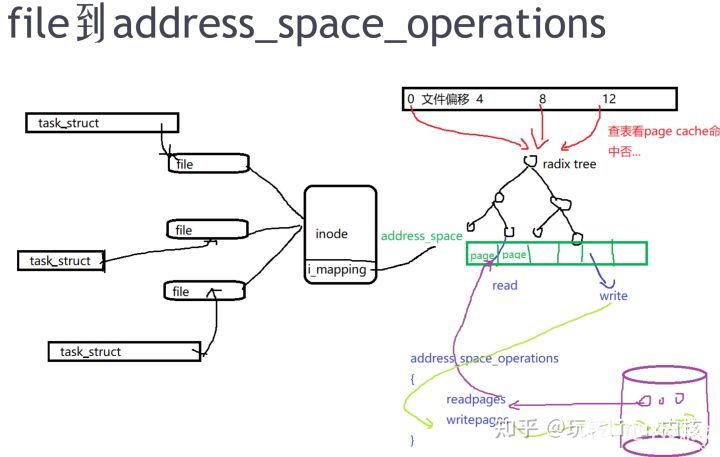
應用程序讀一個文件,首先會去查page cache是否命中,下一次再讀page cache是命中的。
應用程序去寫硬盤時,首先會去寫page cache,至于什么時候開始寫硬盤,由linux flush線程通過(pdflush->每一個設備的flush ->工作隊列)實現。當然也可以是線程本身,通過direct IO去寫硬盤。
如上圖三個task_struct進程,同時打開一個文件,在內存中生成file數據結構,記錄文件打開的實例。
inode是真實存在硬盤里,當inode結構體中的i_mapping,對應的地址空間address_space。一個4M的文件,被分成很多4K單元存在于內存,通過地址 去radix tree來查page cache是否命中。如果查到了,就從radix tree對應的page返回。 如果沒有page cache對應,就會通過 address_space_operations(文件系統實現的數據結構) 去 readpage,從硬盤里的塊讀到pagecache。
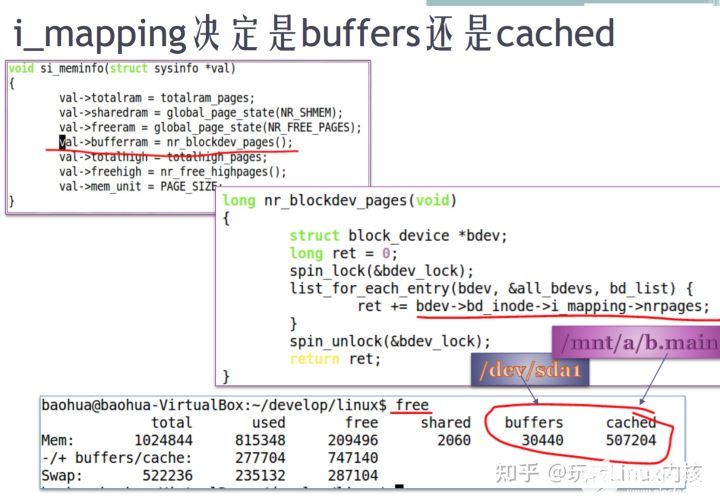
free命令看到的buffers和cache有什么區別?
答:在內核層面,全部都是pagecache。前者對應的是裸分區產生的page cache,后者對應的是掛載文件系統之后,文件系統目錄產生的page cache。如下圖內核代碼的截圖:
文件系統的管理單元是block,內存管理是以page為單位,扇區(section)是硬件讀寫的最小單元。假設你把ext4文件系統格式化成1k/block,那么一個page對應4個block,此時讀一個內存的page,文件系統要操作4個block。假設你把ext4文件系統格式化成4k/block,那么page和block可以一一對應。
/proc/meminfo中的 buffer ram如何計算出?
調用 nr_blockdev_pages(),這個函數會遍歷所有原始塊設備(list_for_each_entry),把所有原始塊設備的inode中的i_mapping , 指向 address_space_operation。包括radix tree管理的pagecache,和 pagecache讀寫硬盤的硬件操作的接口。nr_pages: page cache中已經命中的page。
page和 bio的關系
所謂的bio,抽象的讀寫block device的請求,指文件系統的block與內存page的對應。bio要變成實際的block device access還要通過block device driver再排隊,并受到ioscheduler的控制。
有時候文件系統格式化block為1k,一次讀寫page的請求,最終轉換成操作多個block。bio為I/O請求提供了一個輕量級的表示方法,內核用一個bio的結構體來描述一次塊IO操作。
bio結構體如下:
struct bio {
sector_t bi_sector; /*我們想在塊設備的第幾個扇區上進行io操作(起始扇區),此處扇區大小是按512計算的*/
struct bio *bi_next;
struct block_device *bi_bdev; /*指向塊設備描述符的指針,該io操作是針對哪個塊設備的*/
unsigned long bi_rw; /*該io操作是讀還是寫*/
unsigned short bi_vcnt; /* bio的bio_vec數組中段的數目 */
unsigned short bi_idx; /* bio的bio_vec數組中段的當前索引值 */
unsigned short bi_phys_segments; //合并之后bio中(內存)物理段的數目
unsigned int bi_size; /* 需要傳送的字節數 */
bio_end_io_t *bi_end_io; /* bio的I/O操作結束時調用的方法 */
void *bi_private; //通用塊層和塊設備驅動程序的I/O完成方法使用的指針
unsigned int bi_max_vecs; /* bio的bio vec數組中允許的最大段數 */
atomic_t bi_cnt; /* bio的引用計數器 */
struct bio_vec *bi_io_vec; /*指向bio的bio_vec數組中的段的指針 */
struct bio_set *bi_pool;
struct bio_vec bi_inline_vecs[0];/*一般一個bio就一個段,bi_inline_vecs就可滿足,省去了再為bi_io_vec分配空間*/
}
struct bio_vec {
struct page *bv_page; //指向段的頁框對應頁描述符的指針
unsigned int bv_len; //段的字節長度,長度可以超過一個頁
unsigned int bv_offset; //頁框中段數據的偏移量
};
一個bio可能有很多個bio段,這些bio段在內存是可能不連續,位于不同的頁,但在磁盤上對應的位置是連續的。一般上層構建bio的時候都是只有一個bio段。(新的DMA支持多個不連續內存的數據傳輸)可以看到bio的段可能指向多個page,而bio也可以在沒有buffer_head的情況下構造。
request 和bio的關系
在IO調度器中,上層提交的bio被構造成request結構,每個物理設備會對應一個request_queue,里面順序存放著相關的request。每個請求包含一個或多個bio結構,bio之間用有序鏈表連接起來,按bio起始扇區的位置從小到大,而且這些bio之間在磁盤扇區是相鄰的,也就是說一個bio的結尾剛好是下一個bio的開頭。
通常,通用塊層創建一個僅包含一個bio結構的請求,可能存在新bio與請求中已存在的數據物理相鄰的情況,就把bio加入該請求,否則用該bio初始化一個新的請求。
buffer 和cache,在linux內核實現上沒有區別,在計數上有區別。最后都是 address_space ->radix tree -> read/write pages。
buffer_head: 是內核封裝的數據結構。它是內核page與磁盤上物理數據塊之間的橋梁。一方面,每個page包含多個buffer_head(一般4個),另外一方面,buffer_head中又記錄了底層設備塊號信息。這樣,通過page->buffer_head->block就能完成數據的讀寫。
【文章福利】小編推薦自己的Linux內核技術交流群:【865977150】整理了一些個人覺得比較好的學習書籍、視頻資料共享在群文件里面,有需要的可以自行添加哦!!!
提升技術跳槽漲薪;
Linux內核源碼/內存調優/文件系統/進程管理/設備驅動/網絡協議棧-學習視頻教程-騰訊課堂?ke.qq.com/course/4032547?flowToken=1040236
O_DIRECT 和 O_SYNC
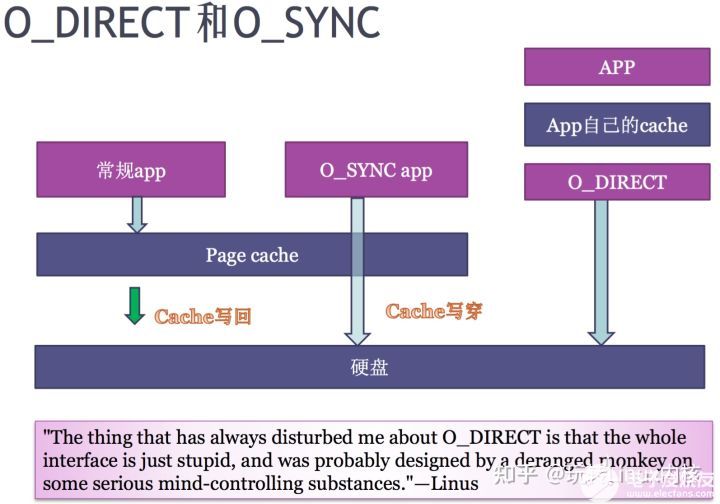
兩者區別,O_DIRECT 把一片地址配置成不帶cache的空間 , 直接導硬盤 , 而 O_SYNC 類似CPU cache的write through. 當應用程序使用O_SYNC寫page cache時,直接寫穿到硬盤。當應用程序同時使用O_SYNC和 O_DIRECT,可能會出現page cache的不一致問題。
writeback機制與bdi
write的過程,把要寫的page提交到bdi_writeback 隊列中,然后由writeback線程將其真正寫到block device上。writeback機制:一方面加快了write()的速度,另一方面便于合并和排序多個write請求。
三進三出講解bio
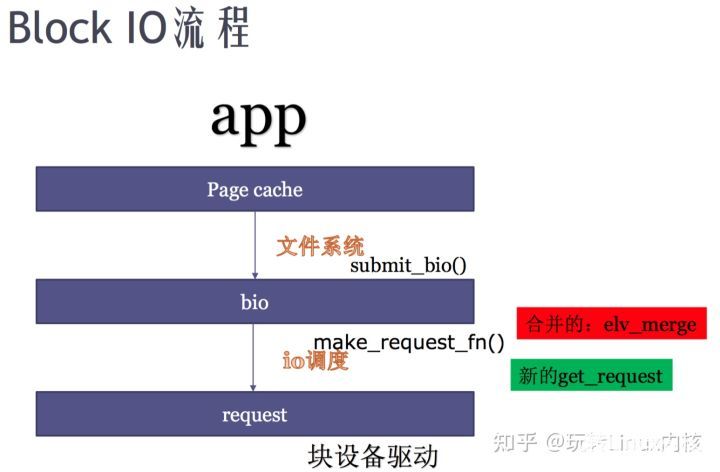
page cache只有通過 address_space_operations里的 write_pages和 read_pages,才能產生對文件系統的block產生IO行為。而不管是directIO還是writeback機制最終都會通過submit_bio方法提交bio到block層。
block io( bio ) : 講文件系統上哪些block 讀到內存哪些 page, 文件系統的 block bitmap 和 inode table,bio是從文件系統解析出來,從block到page之間的關系。
generic_make_request實現中請求構建的關鍵為 make_request_fn, 該函數的調用鏈路為:
blk_init_queue() -> blk_init_queue_node() -> blk_init_allocated_queue -> blk_queue_make_request(q, lk_queue_io), 最后被調用執行的回調函數blk_queue_bio實現如下:
page cache和 硬盤數據 通過linux readpages函數關聯時,會把文件系統的四個block,轉化成4個bio。bio里的指針指向數據在硬盤的位置,也會有把這些數據讀出來之后放置到page cache的哪些page。
當一個page對應多個block的情況,一個page 對應幾個bio:size(page) > size(block),
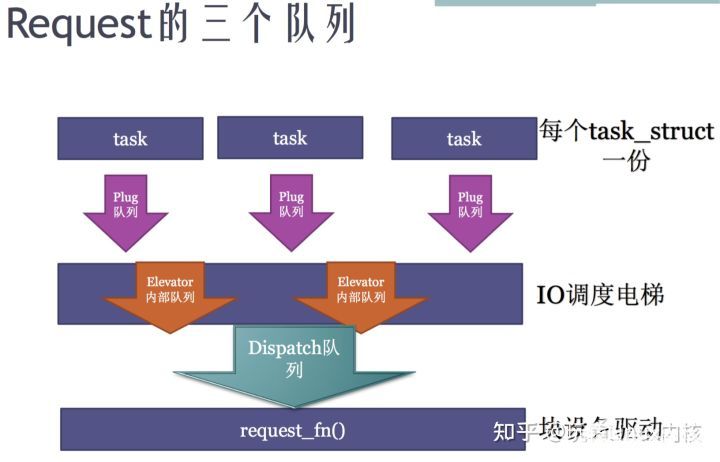
bio --> request每個進程有自己的plug隊列,先把bio先發送到plug隊列。在plug隊列里,把bio轉化成request。第一個bio一定是一個request,之后的bio就會查看多個bio是否可以merge到一個request,如果不能合并就產生一個新的request。
bio邊發plug隊列,邊轉成request。而這些request 先放到 elevator電梯隊列,IO調度電梯做的類似路由器中QoS的功能->限制端口的流量。
deadline調度算法:優先考慮讀,認為寫不重要。應用程序寫到pagecache以后,就已經寫完了。
I/O寫入流程圖
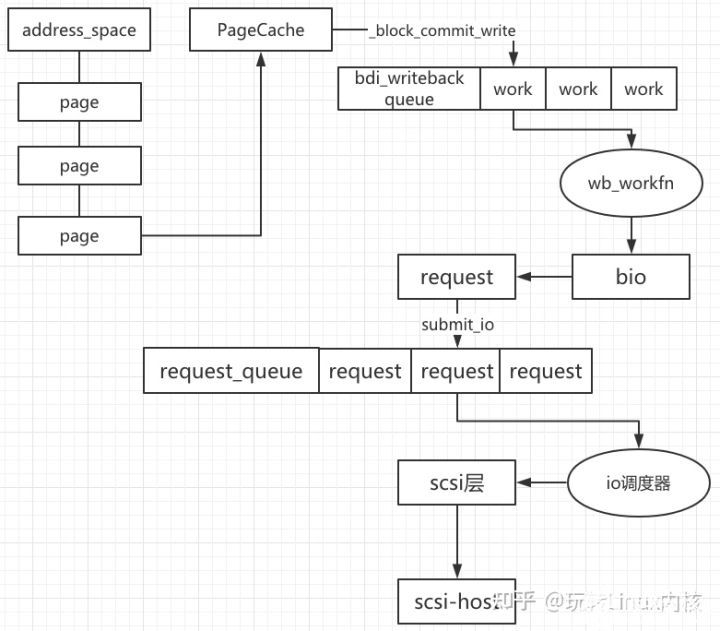
ftrace
vfs_read/vfs_write 慢,到底層操作磁盤差十萬八千里。要用ftrace分析,才能知道具體原因。

對于文件讀寫這種非常復雜的流程,在工程里面可以使用的調試方式是 ftrace。
除了用ftrace工具進行函數級的分析之外,使用blktrace去跟蹤整個block io 生命周期,比如什么時候進入plug隊列,unplug,什么時候進入電梯調度,什么時候進到驅動隊列。
blktrace
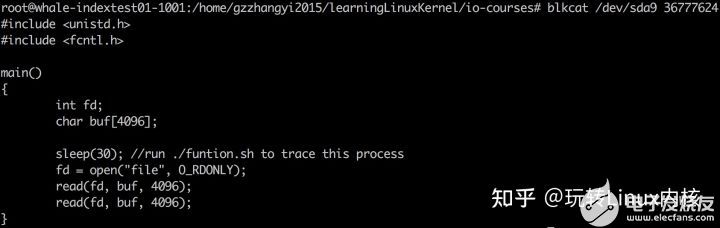
apt-get install sleuthkit blktrace
#1:
blktrace -d /dev/sda -o - | blkparse -i - > 1.trace
#2:
root@whale-indextest01-1001:/home/gzzhangyi2015/learningLinuxKernel/io-courses/bio-flow# dd if=read.c of=barry oflag=sync
0+1 records in
0+1 records out
219 bytes (219 B) copied, 0.000854041 s, 256 kB/s
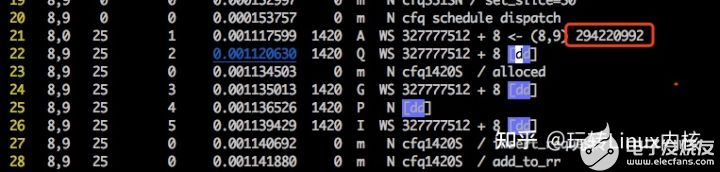
扇區號(294220992)/8 = block號(36777624)
再用debugfs -R 'icheck 塊號' /dev/sda9

再用debugfs -R 'ncheck inode' /dev/sda9

再用 blkcat /dev/sda9 塊號
總結:
blktrace 是在內核里關鍵函數點上加了一些記錄,再把記錄抓下來。主要是看操作的流程。
ftrace 看 函數的流程。
IO調度 和 CFQ調度算法

主要從 進程優先級 , 流量控制 方面考慮,在通用塊層和 I/O調度層 進行限速,限制帶寬和 IOPS。
Noop:空操作調度算法,也就是沒有任何調度操作,并不對io請求進行排序,僅僅做適當的io合并的一個fifo隊列。合并的技術,不太適用于排序。適用于固態硬盤,因為固態硬盤基本上可以隨機訪問。
CFQ:完全公平隊列調度類似進程調度里的CFS,指定進程的nice值。它試圖給所有進程提供一個完全公平的IO操作環境。它為每個進程創建一個同步IO調度隊列,并默認以時間片和請求數限定的方式分配IO資源,以此保證每個進程的IO資源占用是公平的,cfq還實現了針對進程級別的優先級調度。
CFQ對于IO密集型場景不適用,尤其是IO壓力集中在某些進程上的場景。該場景下需要更多滿足某個或某幾個進程的IO響應速度,而不是讓所有的進程公平的使用IO。
此時,deadline調度(最終期限調度)就更適應這樣的場景。deadline實現了四個隊列,其中兩個分別處理正常read和write,按扇區號排序,進行正常io的合并處理以提高吞吐量.因為IO請求可能會集中在某些磁盤位置,這樣會導致新來的請求一直被合并,于是可能會有其他磁盤位置的io請求被餓死。
于是,實現了另外兩個處理超時read和write的隊列,按請求創建時間排序,如果有超時的請求出現,就放進這兩個隊列,調度算法保證超時(達到最終期限時間)的隊列中的請求會優先被處理,防止請求被餓死。由于deadline的特點,無疑在這里無法區分進程,也就不能實現針對進程的io資源控制。
從原理上看,cfq是一種比較通用的調度算法,是一種以進程為出發點考慮的調度算法,保證大家盡量公平。
deadline是一種以提高機械硬盤吞吐量為思考出發點的調度算法,只有當有io請求達到最終期限的時候才進行調度,非常適合業務比較單一并且IO壓力比較重的業務,比如數據庫。
而noop呢?其實如果我們把我們的思考對象拓展到固態硬盤,那么你就會發現,無論cfq還是deadline,都是針對機械硬盤的結構進行的隊列算法調整,而這種調整對于固態硬盤來說,完全沒有意義。對于固態硬盤來說,IO調度算法越復雜,效率就越低,因為額外要處理的邏輯越多。
所以,固態硬盤這種場景下,使用noop是最好的,deadline次之,而cfq由于復雜度的原因,無疑效率最低。
CFQ 和 ionice

demo
把linux的IO調度算法改成CFQ,并且運行兩個不同IO nice值的進程:
目前的調度算法是 deadline
root@whale-indextest01-1001:/sys/block/sda/queue# cat scheduler
noop [deadline] cfq
root@whale-indextest01-1001:/sys/block/sda/queue# echo cfq > scheduler
root@whale-indextest01-1001:/sys/block/sda/queue# cat scheduler
noop deadline [cfq]
root@whale-indextest01-1001:/sys/block/sda/queue# ionice -c 2 -n 0 cat /dev/sda9 > /dev/null&
[1] 6755
root@whale-indextest01-1001:/sys/block/sda/queue# ionice -c 2 -n 7 cat /dev/sda9 > /dev/null&
[2] 6757
root@whale-indextest01-1001:/sys/block/sda/queue# iotop
cgroup與IO

root@whale-indextest01-1001:/sys/fs/cgroup/blkio# cgexec -g blkio:A dd if=/dev/sda9 of=/dev/null iflag=direct &
[3] 7550
root@whale-indextest01-1001:/sys/fs/cgroup/blkio# cgexec -g blkio:B dd if=/dev/sda9 of=/dev/null iflag=direct &
[4] 7552
IO性能測試
1、rrqm/s & wrqm/s 看io合并: 和/sys/block/sdb/queue/scheduler 設置的io調度算法有關。
2、%util與硬盤設備飽和度: iostat 無法看硬盤設備的飽和度。
3、即使%util高達100%,硬盤也仍然有可能還有余力處理更多的I/O請求,即沒有達到飽和狀態。
await 是單個I/O所消耗的時間,包括硬盤設備處理I/O的時間和I/O請求在kernel隊列中等待的時間.
實際場景根據I/O模式 隨機/順序與否進行判斷。如果磁盤陣列的寫操作不在一兩個毫秒以內就算慢的了;讀操作則未必,不在緩存中的數據仍然需要讀取物理硬盤,單個小數據塊的讀取速度跟單盤差不多。
iowait
- %iowait 表示在一個采樣周期內有百分之幾的時間屬于以下情況:CPU空閑、并且有仍未完成的I/O請求。
- %iowait 升高并不能證明等待I/O的進程數量增多了,也不能證明等待I/O的總時間增加了。
- %iowait升高有可能僅僅是cpu空閑時間增加了。
- %iowait 的高低與I/O的多少沒有必然關系,而是與I/O的并發度相關。所以,僅憑 %iowait 的上升不能得出I/O負載增加 的結論。
它是一個非常模糊的指標,如果看到 %iowait 升高,還需檢查I/O量有沒有明顯增加,avserv/avwait/avque等指標有沒有明顯增大,應用有沒有感覺變慢。
FAQ:
什么是Bufferd IO/ Direct IO? 如何解釋cgroup的blkio對buffered IO是沒有限速支持的?
答:這里面的buffer的含義跟內存中buffer cache有概念上的不同。實際上這里Buffered IO的含義,相當于內存中的buffer cache+page cache,就是IO經過緩存的意思。
cgroup針對IO的資源限制實現在了通用塊設備層,對哪些IO操作有影響呢? 原則上說都有影響,因為絕大多數數據都是要經過通用塊設備層寫入存儲的,但是對于應用程序來說感受可能不一樣。在一般IO的情況下,應用程序很可能很快的就寫完了數據(在數據量小于緩存空間的情況下),然后去做其他事情了。這時應用程序感受不到自己被限速了,而內核在處理write-back的階段,由于沒有相關page cache中的inode是屬于那個cgroup的信息記錄,所以所有的page cache的回寫只能放到cgroup的root組中進行限制,而不能在其他cgroup中進行限制,因為root組的cgroup一般是不做限制的。
而在Sync IO和Direct IO的情況下,由于應用程序寫的數據是不經過緩存層的,所以能直接感受到速度被限制,一定要等到整個數據按限制好的速度寫完或者讀完,才能返回。這就是當前cgroup的blkio限制所能起作用的環境限制。












 工商網監
工商網監
評論