 電子發燒友App
電子發燒友App


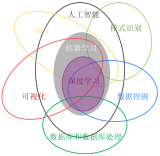
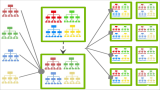
監督學習|機器學習|
集成學習|進化計算|
非監督學習| 半監督學習|
自監督學習|?無監督學習|
隨著人工智能、元宇宙、數據安全、可信隱私用計算、大數據等領域的快速發展,自監督學習脫穎而出,致力于解決數據中心、云計算、人工智能和邊緣計算等各個行業的問題,為人們帶來極大便益。
自監督學習是什么?
自監督學習與監督學習和非監督學習的關系
自我監督方法可以看作是一種特殊形式的具有監督形式的非監督學習方法,其中監督是通過自我監督任務而不是預設的先驗知識誘發的。與完全不受監督的設置相比,自監督學習利用數據集本身的信息構造偽標簽。在表達學習中,自我監督學習有很大的潛力取代完全監督學習。人類學習的本質告訴我們,大型標注數據集可能不是必需的,我們可以自發地從未標注的數據集中學習。更為現實的設置是使用少量帶注釋的數據進行自我學習。這就是所謂的Few-shot Learning。
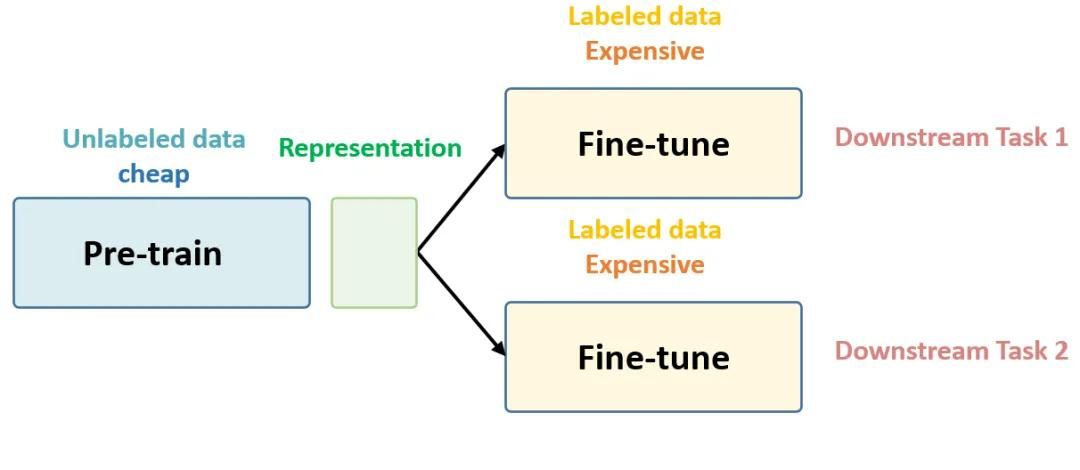
自監督學習的主要流派
在自監督學習中,如何自動獲取偽標簽非常重要。根據偽標簽的不同類型,將自監督表示學習方法分為四種類型:
基于數據生成(恢復)的任務
基于數據變換的任務
基于多模態的任務
基于輔助信息的任務
簡單介紹一下第一類任務。事實上,所有非監督方法都可以被視為第一類自監督任務。在文獻研究的過程中,非監督學習和自監督學習根本不存在界限。
所有非監督學習方法,如數據降維(PCA:在減少數據維度的同時最大化的保留原有數據的方差)和數據擬合分類(GMM:最大化高斯混合分布的似然),本質上都是為了得到一個好的數據表示,并希望能生成(恢復)原始輸入。這也是目前很多自監督學習方法賴以使用的監督信息。基本上,所有的encoder-decoder模型都將數據恢復視為訓練損失。
圖片上色與視頻預測
什么是基于數據恢復的自監督任務?
一. 數據生成任務
自監督學習的出發點是考慮在缺少標簽或者完全沒有標簽的情況下,我們仍然可以學習到能夠表示原始圖片的良好意義的特征。那么什么樣的特質是良好有意義的呢?在第一類自監督任務——數據恢復任務中,能夠通過學習到的特征來還原生成原始數據的特征是有良好意義的。看到這里,大家都能聯想到自動編碼器類的模型,甚至更簡單的PCA。事實上,幾乎所有的非監督學習方法都是基于這個原理。VAE現在非常流行的深代模式,甚至更熱的GAN都可以歸為這種方法。
GAN的核心是通過Discriminator去縮小Generator distribution和real distribution之間的距離。GAN的學習過程不需要人為進行數據標注,其監督信號也即是優化目標就是使得上述對抗過程趨向平穩。
以兩篇具體的paper為例,介紹數據恢復類的自監督任務如何操作實現。我們的重點依然是視覺問題,這里分別介紹一篇圖片上色的文章和一篇視頻預測的文章。其余的領域比如NLP,其本質是類似的,在弄清楚了數據本身的特點之后,可以先做一些低級的照貓畫虎的工作。
?
圖片顏色恢復
設計自監督任務時,需要一些巧妙的思考。比如圖片的色彩恢復任務,我們現有的數據集是一張張的彩色圖片。如果去掉顏色,作為感性思考者的我們,能否從黑白圖片所顯示的內容中猜測出原始圖片的真實顏色?對于一個嬰兒來說可能很難,但是對于我們來說,生活的經驗告訴我們瓢蟲應該是紅色的。我們如何做預測?事實上,通過觀察大量的瓢蟲,已經在大腦中建立了一個從“瓢蟲”到“紅色”的映射。

這個學習過程擴展到模型。給定黑白輸入,使用正確顏色的原始圖像作為學習標簽,模型將嘗試理解原始黑白圖像中的每個區域是什么,然后建立從什么到不同顏色的映射。

當我們完成訓練,模型的中間層feature map就得到以向量形式的類似人腦對于“瓢蟲”以及其他物體的記憶。
視頻預測
一般來說,視覺問題可以分為兩類:圖片和視頻。圖片數據可以認為具有i.i.d特征,而視頻由多個圖片幀組成,可以認為具有一定的Markov dependency。時序關系是他們最大的區別。比如,最簡單的思路是利用CNN提取單個圖片的特征進行圖像分類,然后加入一個RNN或LSTM刻畫Markov Dependency,便可以應用到視頻中。
視頻中幀與幀之間有時空連續性。同樣,利用幀與幀之間的連續性,當看電影的時突然按下暫停,接下來幾秒鐘會發生什么,其實是可以預見的。
同樣,這個學習過程也擴展到了模型中。給定前一幀或前幾幀的情況下,使用后續的視頻幀作為學習標簽,從而模型會試著理解給定視頻幀中的語義信息(發生了啥?)進而去建立從當前到未來的映射關系。

二. 基于數據變換的任務
事實上,人們現在常常提到的自監督學習通常指的是:這一類自監督任務是比較狹義的概念。
用一句話說明這一類任務,事實上原理很簡單。對于樣本? ??,我們對其做任意變換,則自監督任務的目標是能夠對生成的? ??估計出其變換的參數。
下面介紹一種原理十分簡單但是目前看來非常有效的自監督任務——Rotation Prediction。
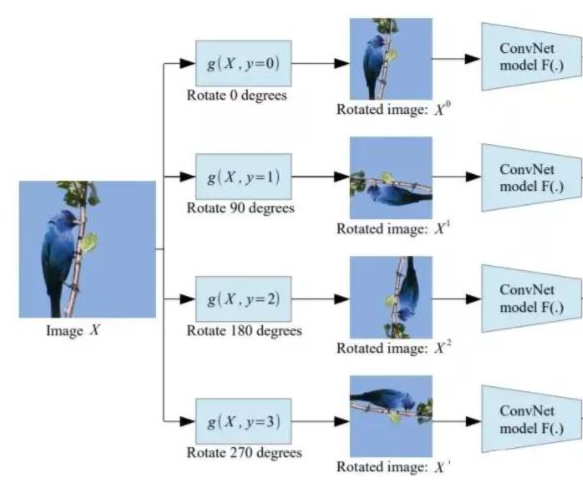
給定輸入圖片? ??,我們對其做4個角度的旋轉,分別得到? ??,并且我們知道其對應的變換角度分別為? ??。此時,任務目標即是對于以上4張圖片預測其對應的旋轉角度,這里每張圖片都經過同樣的卷積神經網。
自監督學習中對比學習方法
對比學習是自監督學習中的一個重要方法,其核心思想是通過樣本的相似性來構建表征。對于相似的輸入樣本,由網絡產生的表征也應當相似;而對于差異較大的輸入樣本,表征也應該存在較大區別。根據這一思想,很多基于對比學習的自監督學習方法被提出(如MoCo、SimCLR、BYOL),并對這一領域產生了深遠影響。
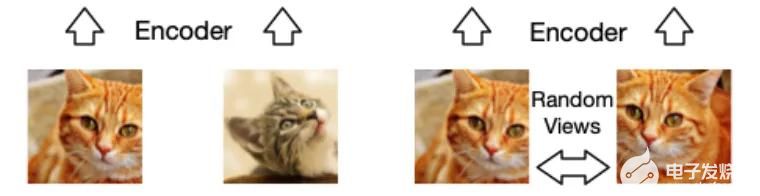
對比學習中的一個關鍵步驟是構建正負樣本集合,對于一個輸入樣本??,如何找到與其相似的正樣本??,和不相似的負樣本???在基于圖像的自監督任務中,一般通過數據增強(data augmentation)來對單張圖片構建不同視圖,這些視圖的圖像內容高度一致,被視為正樣本;而數據集中的其他圖片則直接被視為負樣本。
同一張貓咪圖片經過剪裁得到的另一視圖被視作正樣本,正樣本與原圖經過神經網絡編碼得到的表征應該相似;而數據集中的其余圖片被視為負樣本,經網絡編碼后的結果應當差異較大。
完成正負樣本的構建后,對比學習一般采用InfoNCE Loss來進行損失計算和模型更新,其形式如下:
其中??表示訓練模型對輸入樣本的編碼過程。InfoNCE Loss約束模型對當前樣本的編碼結果和對正樣本的編碼結果的內積較大,而和負樣本的編碼結果的內積較小,可以看作是從樣本集合中判別出與之匹配的正樣本。
一.?MoCo
MoCo是對比學習中一個非常有代表性的方法,其主要思想是將對比學習過程看作一個“查字典”的過程:在一個由眾多樣本構成的鍵值(key)字典中檢索到與查詢樣本的編碼結果(query)相匹配的正樣本。為了提升對比學習的效果,提出兩點假設:
一.鍵值字典的容量應該盡可能增大以提高自監督任務的難度,從而提升訓練效果;
二.鍵值字典應該在訓練過程中保持一定程度的一致性以保障自監督學習過程能夠穩定進行。
基于以上兩點假設,分析了幾種對比學習機制。
1端到端訓練
即對于所有的查詢樣本的編碼結果(query)和字典鍵值(key)同時進行梯度傳播,但這一方法中顯存大小會極大地限制鍵值字典的大小,導致自監督任務難度降低,影響訓練效果;
2.基于memory bank的訓練方法
迭代過程中將鍵值編碼存儲到一個memory bank中,每輪對比學習過程中所需要的字典鍵值直接從memory bank 里選取,而梯度計算只對查詢樣本的編碼網絡分支進行。因為MoCo不需要對鍵值字典的分支進行梯度計算,memory bank方法可以顯著提升鍵值字典的容量,但是由于每個樣本在memory bank中的鍵值在被模型重新編碼時才會被更新,鍵值字典中鍵值間的一致性較差,從而降低了訓練的穩定性。
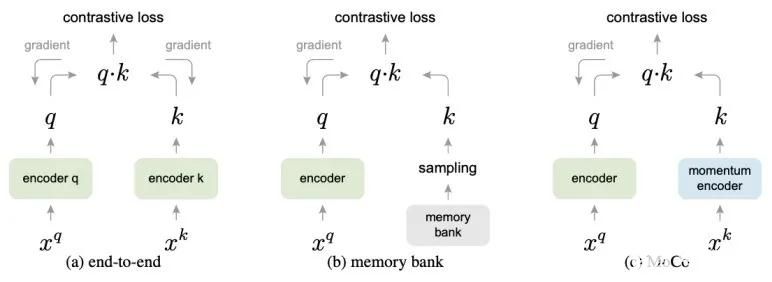
因此,提出一種momentum encoder來實現對鍵值字典的編碼。對于查詢樣本,使用普通encoder進行編碼并直接進行梯度計算;而對于鍵值字典,首先由一個動態更新的隊列維護字典的輸入樣本,再使用momentum encoder將樣本編碼為鍵值。Momentum encoder在訓練過程中不會進行梯度計算,而是采用動量更新的方法從encoder更新參數,更新方法如下:
其中,??和??分別表示query encoder和key momentum encoder的參數,??,表示動量參數以調節更新速率。這樣的方法一方面可以避免key encoder在訓練時因需要計算梯度使字典大小被限制,也可以避免memory bank方法中的鍵值低一致性問題,保障了訓練的穩定性。
值得一提的是,在實驗過程中發現傳統的batch normalization方法可能造成樣本信息的泄露,讓數據樣本意外地“看到了”其他樣本。會使模型在自監督任務中更傾向于選擇一個合適的batch normalization參數,而不是學習一個比較好的特征表示。
二.?SimCLR
SimCLR 是一個非常簡潔的自監督學習框架。沒有建立類似MoCo的鍵值字典的方式,而是直接在每個batch中的樣本之間進行比較學習。對于??個輸入數據,先使用兩種不同的數據增強方法產生??個樣本;對于每個樣本來說,從同一輸入圖片中產生另一樣本被視為正樣本,其余??個樣本被視為負樣本。構建完正負樣本后,SimCLR直接使用端到端的方法計算loss并更新模型。
網絡結構上,與MoCo相比,SimCLR在backbone網絡末端新增了一個由兩層全連接層構成的projection head。模型在訓練階段,根據projection head的輸出??計算損失函數;而在遷移到下游任務時,會將projection head移除,直接使用backbone部分網絡輸出的表征??。
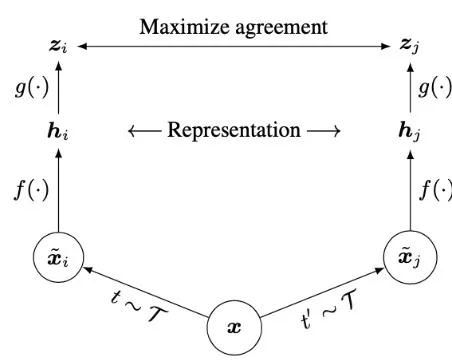
三.?BYOL
BYOL是一個非常有特點的模型,與MoCo、SimCLR相比,BYOL可以直接在正樣本對上進行自監督訓練而不需要構建負樣本集合。BYOL的構想來自于一個非常有意思的發現:在一個完全隨機初始化的網絡所輸出的特征上進行分類任務的top-1準確率只有1.4%;
但如果將這個隨機初始化網絡的輸出特征作為目標,用另一個網絡對其進行學習,使用學習之后的網絡進行特征提取再進行分類可以達到18.8%的準確度。換言之,以一個特征表示作為目標進行學習,可以獲得一個更好的表示。如此繼續迭代下去,精確度可以繼續往上提升。
基于這一發現,構建了只需要正樣本對的BYOL學習框架。如圖,一張輸入圖片經過不同數據增強后的兩個視圖分別經過online和target兩個分支的backbone和projection head后得到輸出??和??,再使用一個prediction head從??預測??。計算損失時使用了MSE loss,且只對online分支計算梯度和更新參數;對于target分支使用類似MoCo動量更新的方式從online分支更新參數。
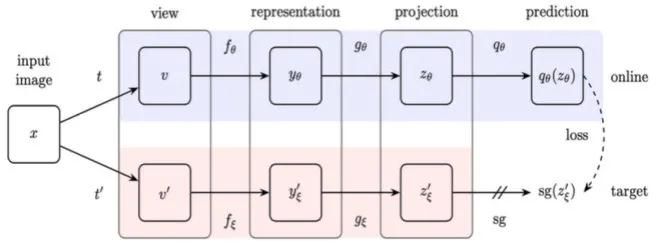
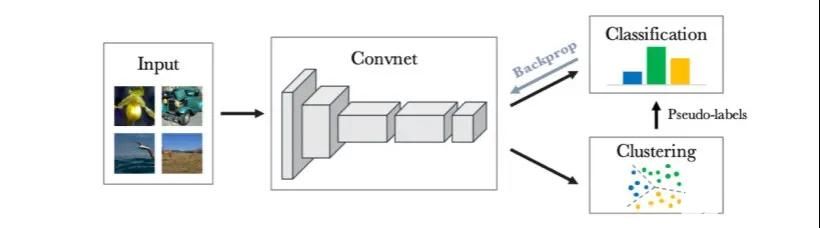
自監督學習中的聚類方法
與對比學習或者人工設置的前置任務(pretext task)的學習方式不同,基于聚類的自監督方法將訓練樣本按照某種相似度量進行劃分,劃歸到不同聚類中心的樣本被賦予不同的類別標簽,之后使用標準的全監督學習交叉熵損失進行訓練。用數學語言形式化的展示了全監督學習與自監督聚類之間的聯系與區別:考慮深度模型??將圖像映射為特征??,全監督學習使用包含完全標注的樣本-標簽數據來優化模型??。
具體來講,假設有N個樣本??,相應的類別標簽為,??,一個分類頭??將深度模型的??維輸出向量映射到??維(每一維對應一個類別的得分)并使用softmax操作將每個類別的得分轉化為類別概率值。由于交叉熵損失需要給出目標的類別標簽(標注數據集),對于無標注數據,需要首先通過某種分配方式賦予每個樣本具有一定意義的標簽然后才能進行訓練。
一般而言,我們令??為one-hot函數??,即每一個樣本我們限定其只能屬于某一類,那么上述公式可以寫成一個雙層優化問題:
第一步,根據深度模型輸出調整標簽分配方式,得到當前特征下損失函數最小的標簽;
第二步,根據更新的標簽訓練深度模型。
給所有的樣本賦予相同標簽之后優化模型參數就可以最小化平均損失函數。此時,模型將所有樣本均映射到特征空間中的同一位置附近,不同樣本之間的特征區分度變得微弱,模型性能嚴重退化,不能達到學習出有意義特征表示的目的。因此,基于聚類的自監督學習方法關鍵在于引入適當的約束條件,避免模型收斂到退化解。
自監督學習推動醫學圖像分類發展
隨著自監督學習在放射學、病理學和皮膚病學等諸多應用領域取得令人振奮的成果,人們對自監督學習在醫學成像任務中的應用越來越感興趣。盡管如此,開發醫學成像模型仍然頗具挑戰,這是由于標注醫學圖像極為耗時,高質量標記數據通常較為稀缺。
鑒于此,遷移學習 (Transfer learning) 成為構建醫學成像模型的熱門范例。這種方法首先要在大型標記數據集(如 ImageNet)中使用監督學習 (Supervised learning) 對模型進行預訓練,然后在域內醫學數據中對習得的通用表征進行微調。
近來一些新的方法在自然圖像識別任務中取得了成功,尤其是在標記示例稀少的情況下,這些方法使用自監督對比預訓練,然后進行監督微調(例如 SimCLR 和 MoCo)。在對比學習預訓練中,模型將同一圖像的不同轉換視圖間的一致性升至最高,同時將不同圖像的轉換視圖間的一致性降至最低,從而習得通用表征。盡管這些對比學習方法取得成功,但在醫學圖像分析中受到的關注有限,其功效還有待探索。
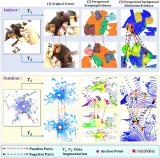
研究自監督對比學習作為醫學圖像分類領域預訓練策略的有效性。同時提出一個全新方法——多實例對比學習 (MICLe),這一方法可泛化對比學習以利用醫學圖像數據集的特性。針對兩項不同的醫學圖像分類任務進行實驗:識別數碼相機圖像中皮膚狀況分類(27 類)和對胸部 X 射線進行多標簽分類(5 類)。通過實驗可以觀察到,在 ImageNet 上進行自監督學習,隨后對未標記的特定領域醫學圖像進行額外的自監督學習,顯著提高醫學圖像分類器的準確性。具體來說,結果表明自監督預訓練優于監督預訓練,即使在完整的 ImageNet 數據集(1400 萬幅圖像和 2.18 萬個類別)用于監督預訓練時也是如此。
分別使用域內未標記和標記數據對各項任務進行預訓練和微調,還使用在不同臨床環境中獲得的另一個數據集作為偏移數據集,以進一步評估我們的方法對域外數據的穩健性。對于胸部 X 射線任務,使用 ImageNet 或 CheXpert 數據進行自監督預訓練可以提高泛化能力,同時使用兩者還可以進一步提高此能力。正如預期的那樣,當僅使用 ImageNet 進行自監督預訓練時,與僅使用域內數據進行預訓練相比,該模型的表現更差。
為測試分布偏移下的表現,對于各項任務,額外提供在不同臨床環境下收集的標記數據集以進行測試。發現使用自監督預訓練(同時使用 ImageNet 和 CheXpert 數據)時,分布偏移數據集 (ChestX-ray14) 的表現有所提升,比 CheXpert 數據集的原始提升更為明顯。這一發現頗具價值,因為分布偏移下的泛化能力對于臨床應用至關重要。在皮膚病學任務中,我們觀察到某一單獨的偏移數據集具有類似趨勢,該數據集收集自皮膚癌診所,具有較高的惡性疾病發病率。這表明自監督表征對分布偏移的穩健性在不同任務間具有一致性。
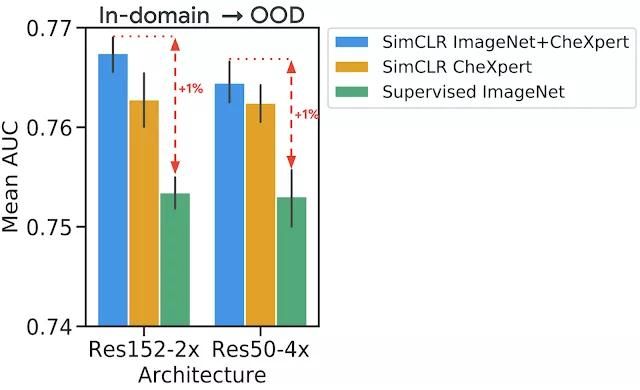
用于胸部 X 射線解讀任務的分布偏移數據集模型評估。我們在沒有進一步微調(零樣本遷移學習)的情況下,使用在域內數據上訓練的模型對額外的偏移數據集進行預測。我們觀察到,自監督預訓練會產生更好的表征,對分布偏移更穩健
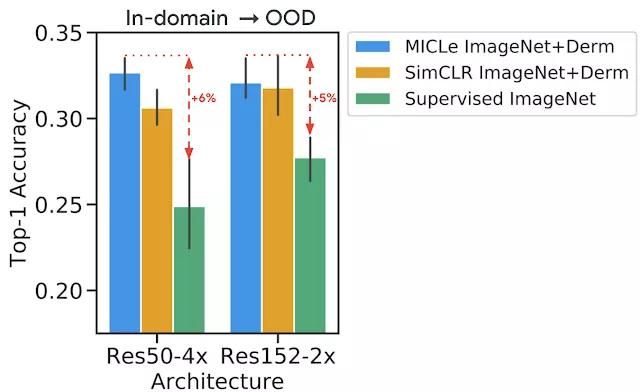
用于皮膚病學任務的分布偏移數據集模型評估。結果普遍表明,自監督預訓練模型可以在分布偏移中得到更好的泛化,其中 MICLe 預訓練對泛化能力的提升最為明顯
通過在不同分數的標記訓練數據上對模型進行微調,進一步研究了用于醫學圖像分類的自監督模型的標記效率。我們對 Derm 和 CheXpert 訓練數據集使用 10% 到 90% 的標簽分數,并使用皮膚病學任務的不同可用標簽分數研究性能如何變化。使用自監督模型進行預訓練可以彌補醫學圖像分類標簽效率低下的情況,并且在采樣的標簽分數中,自監督模型表現始終優于監督基線。結果還表明,使用較少的標記示例進行微調時,MICLe 會按比例提升標簽效率。事實上,MICLe 僅使用 20% 的 ResNet-50(4 倍)訓練數據和 30% 的 ResNet152(2 倍)訓練數據就能夠與基線持平。
自動駕駛Corner Case終結者自監督學習
當自動駕駛汽車在行駛過程中,需要實時理解各種交通參與者的運動,這些運動狀態信息對于各個技術模塊來說都非常重要,涉及檢測、跟蹤、預測、規劃等等。
自動駕駛汽車通常配有多個傳感器,其中最常用的是激光雷達。因此,如何從點云中獲得其他交通參與者的運動信息是一個重要課題,并且存在如下挑戰:交通參與者的類別不一樣,每個類別都表現出特定的運動行為:
激光雷達點云的稀疏性導致兩次激光雷達掃描的情況不能精確地對應起來;
需要在很短的時間限制內和有限的車載算力下完成計算。
傳統做法是通過識別場景中其它交通參與者
根據所觀測到的歷史信息,來預測交通場景會如何變化,從而實現預測。但是,大多數識別模型都是為檢測若干已知類別的物體而訓練的。在實際情況中,經常會遇上沒出現過的物體類別。這肯定不是長久之計。
通過估計激光雷達點云每個點的3D運動來從點云中估計場景流
但這樣做對計算的要求太高了,自動駕駛車又特別需要達到實時性,所以根本無法進行實際應用。
基于BEV(bird’s eye view)的方式
把激光雷達的點云畫成一個個小網格,每個網格單元被稱為體柱,點云的運動信息可以通過所有體柱的位移向量來描述,該位移向量描述了每個體柱在地面上的移動大小和方向。
這種表征方法成功簡化了場景運動,反正只需要考慮在水平方向上的運動情況,而不用特別考慮垂直方向上的運動。這種方式的所有關鍵操作都可以通過2D卷積進行,計算速度非常快。但是,這種方式需要依靠大量帶有標注的點云數據,但點云數據的標注成本比普通圖像更高。
據統計,一輛自動駕駛汽車每天會產生超過1TB的數據,但僅有不到5%的數據被利用,若能把其他數據也充分利用起來,在沒有手工標注的數據上來進行學習,那可就太高效了。

關于自監督學習的思考
1.理論原理
盡管自監督學習取得了很好的效果,但其背后的數學原理和理論基本并沒有特別扎實,大多通過實驗結果反推模型結構和策略的效果,可能造成很多研究走了彎路,從理論基礎出發,直達最終目標的效果可能會更好。
2.替代任務的構建
當前替代任務的構建特別是視頻方向,多與下游任務為主導,沒有特定的范式或者規則。替代任務所能完成的任務,就是自監督模型能完成任務的邊界。替代任務的五花八門,導致各類任務的千差萬別,沒有辦法比較性能優劣,只能是單純的網絡在另一個任務上的應用,當前圖片領域多基于多種數據增強方法構建替代任務,而視頻領域也可以提出統一的構建方式。能夠通過“半自動”方式做出來的替代任務少之又少,在各類的圖像算法應用中,可能是影響自監督方法適應性的絆腳石。
3.能否構建直通下游任務的端到端學習
已經發現自監督中有明顯的語義分割特征,在對比模型后端加入分割分支網絡會不會對網絡學習有幫助,抑或是直接訓練得到可使用的分割網絡,都是值得研究的問題。
4.除對比的其他形式構建特征提取網絡
本質上,對比網絡是除去常規網絡之外,訓練得到特征表示的一種方式而已,與前文提到的自編碼器有異曲同工之妙。對比學習的成功在于,其訓練得到的特征提取網絡,在下游任務中表現優異,也是所提特征有效的表現。由此我們可以得到啟發,還有沒有其他的形式構建訓練網絡,也能夠提取得到有效特征。相信新模式的提出肯定也會和對比學習一樣,引領一波研究浪潮。
5.廣闊天地,大有可為
自監督學習還處于探索階段,有很多可以深入探究的部分,相信無論在學術界和工業界自監督學習都會有廣泛的應用。作為深度學習中的一種魔法,還需要更多的人來挖掘其潛能,創造更多的神跡。
藍海大腦超融合大數據一體機(融合計算、網絡、存儲、 GPU、虛擬化的一體機;?支持主流虛擬化平臺如Vmware、Redhat、Microsoft Hyper-V 等;支持在線壓縮、重復數據自動刪除 、數據保護、容災備份及雙活等)自監督學習保駕護航,為自監督學習的發展提供了重要的后勤保障工作。
審核編輯:符乾江







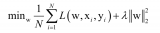














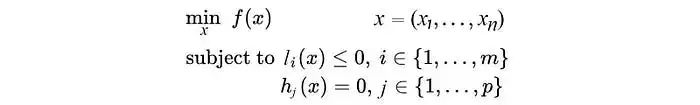











 工商網監
工商網監
評論